Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ComfyUI Wan2.1による Text-to-Video 生成 技術的仕組みと実装手順の...
Search
oggata
August 19, 2025
Technology
81
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ComfyUI Wan2.1による Text-to-Video 生成 技術的仕組みと実装手順の完全解説
oggata
August 19, 2025
More Decks by oggata
See All by oggata
セルから世界へ ------Life Gameからパックマン、そしてWorld Modelまでの世界生成シミュレーション入門
oggata
0
390
MESAワールドモデルとマルチエージェントによる人間行動シミュレーション :仮想から現実世界への架け橋
oggata
0
28
ecological_niche_reward_function_v3
oggata
0
14
NextGen Chore
oggata
0
16
MESA_MINI_DINOv2_Pipeline
oggata
0
15
Self-Introduction
oggata
0
33
Gaming & PhisicalAI
oggata
0
69
savanna_sim.py
oggata
0
8
Beyond LLM:世界モデルが切り拓くフィジカルAIの時代
oggata
0
37
Other Decks in Technology
See All in Technology
Making sense of Google’s agentic dev tools
glaforge
1
290
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
2
150
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
450
GoでCコンパイラを作った話
repunit
0
140
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
1
460
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
200
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
0
650
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
150
OPENLOGI Company Profile for engineer
hr01
1
74k
SRE Next 2026 何でも屋からの脱却
bto
0
1.1k
Network Firewallやっていき!
news_it_enj
0
180
「早く出す」より「事業に効く」 ── 顧客の業務サイクルから逆算するAI時代の二重ループ開発と「変化の設計者」 / devsumi2026
rakus_dev
1
490
Featured
See All Featured
YesSQL, Process and Tooling at Scale
rocio
174
15k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
How to make the Groovebox
asonas
2
2.3k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Bash Introduction
62gerente
615
220k
Google's AI Overviews - The New Search
badams
0
1.1k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
Transcript
ComfyUI Wan2.1による Text-to- Video 生成 技術的仕組みと実装手順の完全解説 Wan2.1アーキテクチャの理解 各コンポーネントの役割 実践的な生成フロー
従来の課題 静止画生成は成功したが、動画は困難 ❌ 悪い例(一貫性な し): Frame 1: 黒い猫 Frame 2:
白い猫 Frame 3: 茶色い猫 → 同じ猫なのに色が変わ る ✅ 良い例(一貫性あ り): Frame 1: 黒い猫(立って いる) Frame 2: 黒い猫(歩き 始め) Frame 3: 黒い猫(歩行 中) → 同じ猫が自然に動く 具体的な一貫性問題 1.アイデンティティの 保持: キャラクターの 外見維持 2.物理法則の遵守: 重 力、慣性の自然な表 現 3.背景の安定性: 環境の 不要な変化防止 4.動作の連続性: 滑らか で自然な動き テキスト → [単一フレーム] → 1枚の画像 - 1回の生成で完結 - 空間的関係のみ考慮 - 計算量: 512×512×3 = 約78万次元 動画生成の複雑性 テキスト → [複数フレーム] → 16枚の連続画像 - フレーム間の関係性が重要 - 時間軸 + 空間軸の同時処理 - 計算量: 512×512×3×16 = 約1250万次元 (16倍) 従来手法の限界 各フレームを独立生成 → 不自然なちらつき 単純な時系列拡張 → 品質劣化 メモリ制約による解像度・長さの限界 概要 - Text-to-Video生成 時間的一貫性の維持 計算資源の膨大な要求
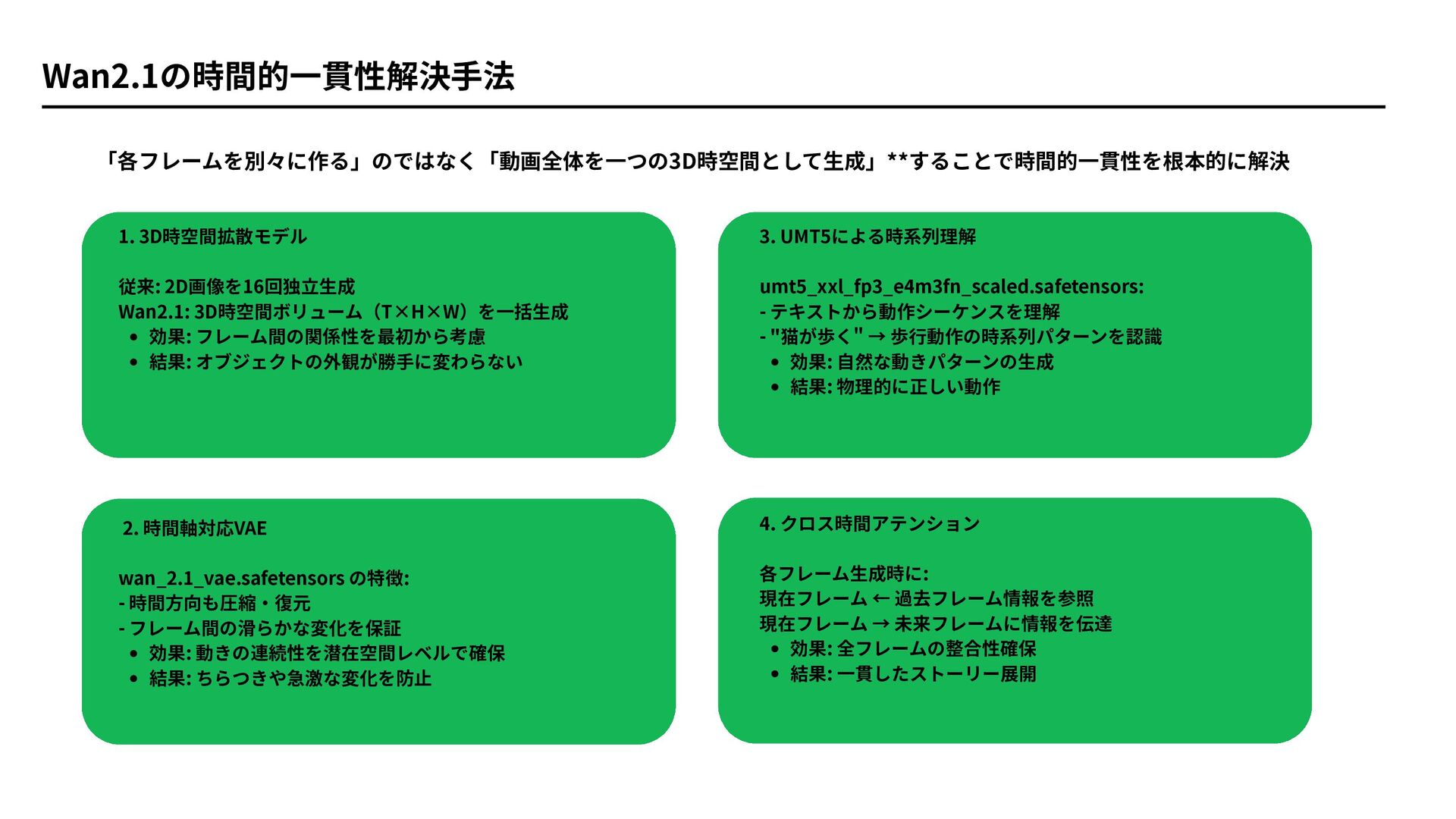
Wan2.1の時間的一貫性解決手法 1. 3D時空間拡散モデル 従来: 2D画像を16回独立生成 Wan2.1: 3D時空間ボリューム(T×H×W)を一括生成 効果: フレーム間の関係性を最初から考慮 結果:
オブジェクトの外観が勝手に変わらない 2. 時間軸対応VAE wan_2.1_vae.safetensors の特徴: - 時間方向も圧縮・復元 - フレーム間の滑らかな変化を保証 効果: 動きの連続性を潜在空間レベルで確保 結果: ちらつきや急激な変化を防止 3. UMT5による時系列理解 umt5_xxl_fp3_e4m3fn_scaled.safetensors: - テキストから動作シーケンスを理解 - "猫が歩く" → 歩行動作の時系列パターンを認識 効果: 自然な動きパターンの生成 結果: 物理的に正しい動作 4. クロス時間アテンション 各フレーム生成時に: 現在フレーム ← 過去フレーム情報を参照 現在フレーム → 未来フレームに情報を伝達 効果: 全フレームの整合性確保 結果: 一貫したストーリー展開 「各フレームを別々に作る」のではなく「動画全体を一つの3D時空間として生成」**することで時間的一貫性を根本的に解決
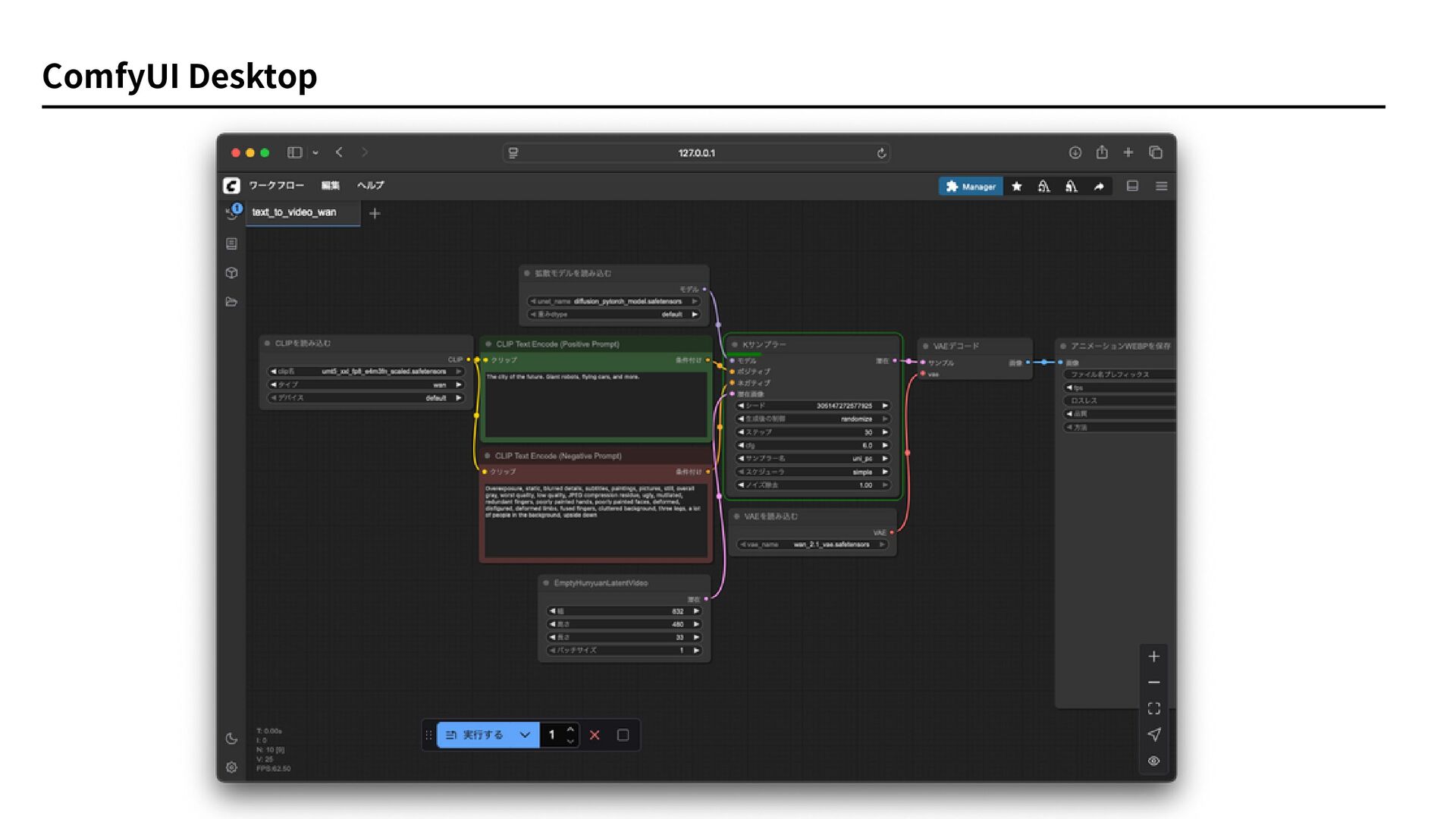
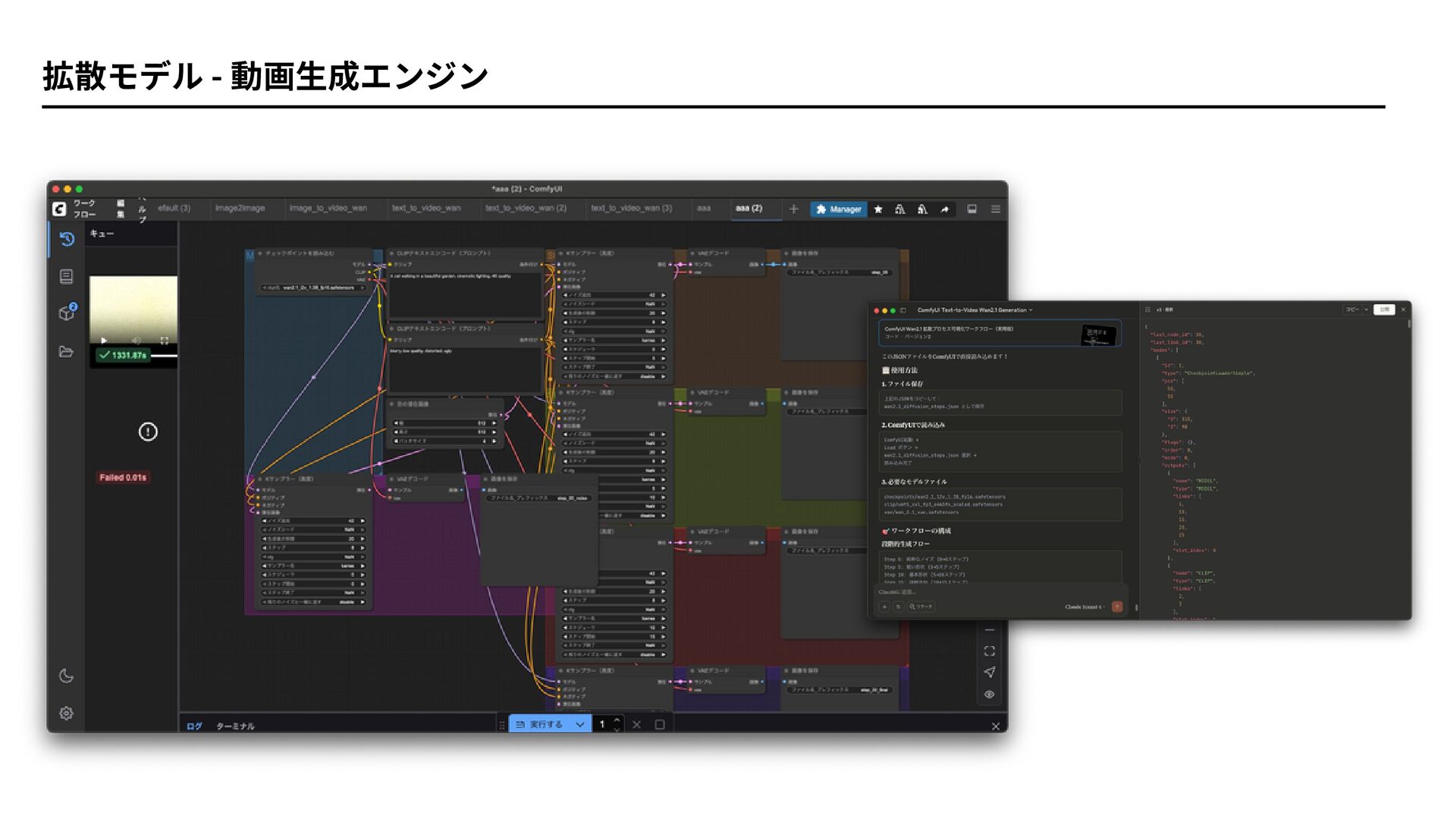
ComfyUI Desktop
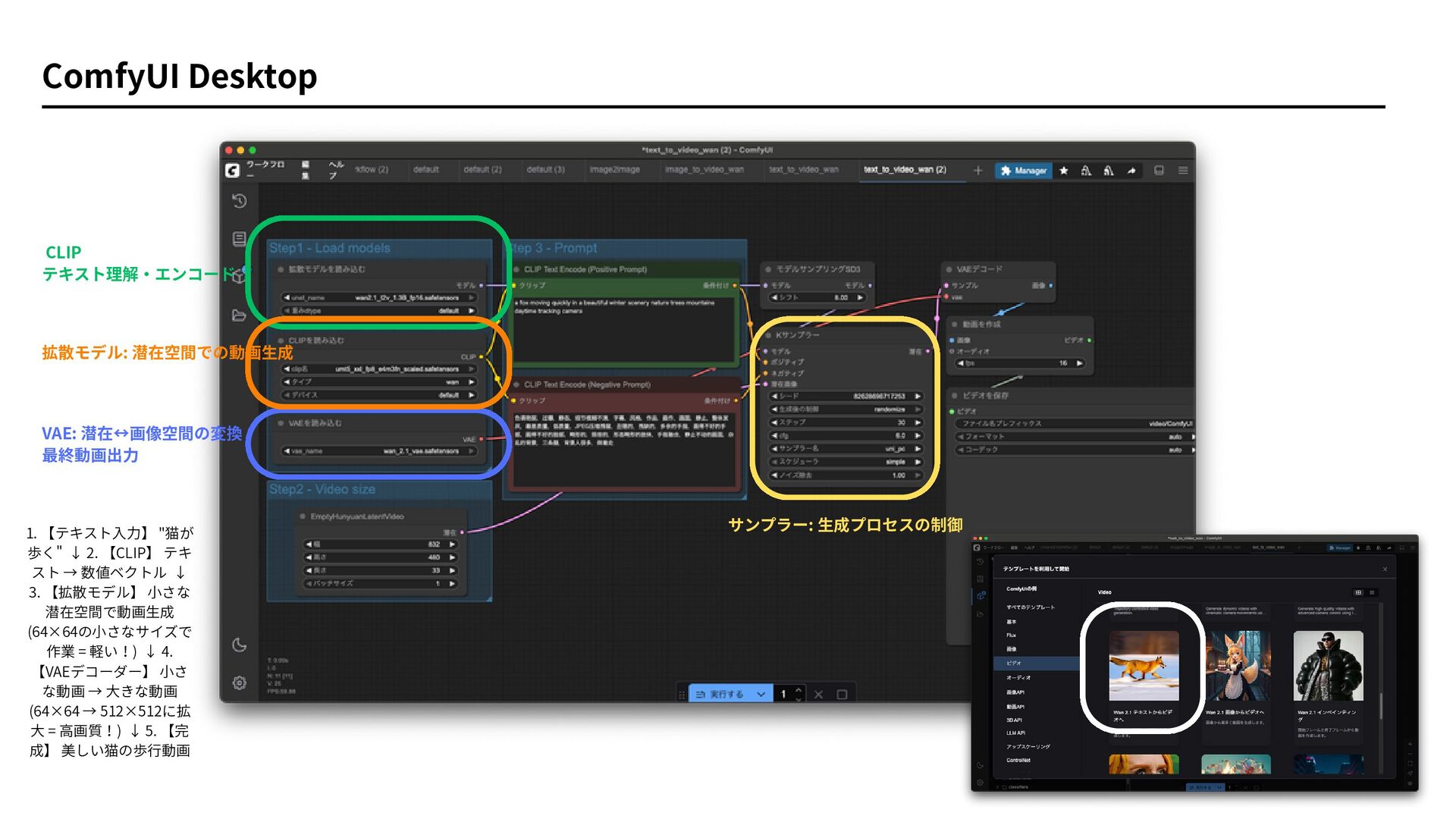
ComfyUI Desktop 拡散モデル: 潜在空間での動画生成 VAE: 潜在↔画像空間の変換 最終動画出力 CLIP テキスト理解・エンコード サンプラー:
生成プロセスの制御 1. 【テキスト入力】 "猫が 歩く" ↓ 2. 【CLIP】 テキ スト → 数値ベクトル ↓ 3. 【拡散モデル】 小さな 潜在空間で動画生成 (64×64の小さなサイズで 作業 = 軽い!) ↓ 4. 【VAEデコーダー】 小さ な動画 → 大きな動画 (64×64 → 512×512に拡 大 = 高画質!) ↓ 5. 【完 成】 美しい猫の歩行動画
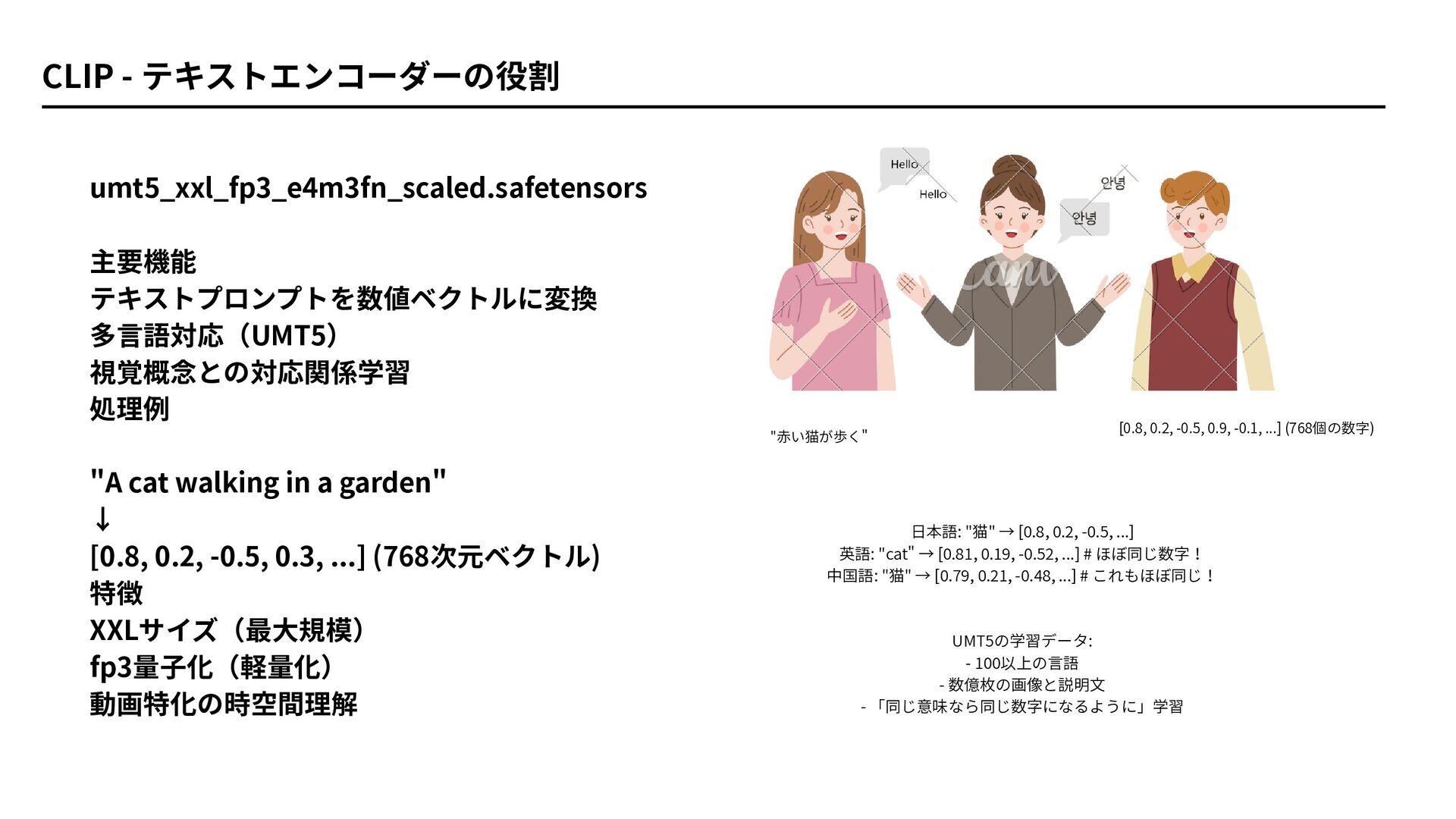
umt5_xxl_fp3_e4m3fn_scaled.safetensors 主要機能 テキストプロンプトを数値ベクトルに変換 多言語対応(UMT5) 視覚概念との対応関係学習 処理例 "A cat walking in
a garden" ↓ [0.8, 0.2, -0.5, 0.3, ...] (768次元ベクトル) 特徴 XXLサイズ(最大規模) fp3量子化(軽量化) 動画特化の時空間理解 CLIP - テキストエンコーダーの役割 "赤い猫が歩く" [0.8, 0.2, -0.5, 0.9, -0.1, ...] (768個の数字) 日本語: "猫" → [0.8, 0.2, -0.5, ...] 英語: "cat" → [0.81, 0.19, -0.52, ...] # ほぼ同じ数字! 中国語: "猫" → [0.79, 0.21, -0.48, ...] # これもほぼ同じ! UMT5の学習データ: - 100以上の言語 - 数億枚の画像と説明文 - 「同じ意味なら同じ数字になるように」学習
共通意味空間 - CLIPと拡散モデルの連携 なぜ異なるモデルが連携できるのか? 共同学習による統一空間 "猫" → [0.8, 0.2, -0.5,
...] ← CLIP出力 ↓ 同じベクトル空間 拡散モデル → 猫の動画生成 意味的関係の学習 類似概念は近い位置にマッピング 属性の線形結合が可能 多言語・多概念の統一表現 具体例 "赤い" + "猫" = "赤い猫" [0.1,0.9] + [0.8,0.2] = [0.9,1.1] 共通意味空間 - CLIPと拡散モデルの連携
wan2.1_l2v_1.3B_fp16.safetensors 拡散プロセス ノイズ → ステップ1 → ステップ2 → ... →
動画 主要仕様 1.3B: 13億パラメータ L2V: Latent-to-Video(潜在空間動画生成) fp16: 16ビット精度(効率化) 生成プロセス ランダムノイズから開始 CLIPの条件ベクトルで方向性制御 段階的にノイズ除去 高品質動画潜在表現を生成 拡散モデル - 動画生成エンジン Wan2.1での実際のプロセス Step 0 (開始) ランダムノイズ: [完全な雑音] CLIPベクトル: "猫が歩く" → [0.8, 0.2, -0.5, ...] Step 1-5 (粗い形状) ノイズ + 条件情報 → わずかに猫らしい輪郭 [雑音多数] + [猫の方向性] = [ぼんやりした猫の形] Step 10-20 (詳細化) さらにノイズ除去 → より明確な猫の形 [少しのノイズ] + [猫の特徴] = [認識できる猫] Step 20-50 (最終調整) 最終ノイズ除去 → 高品質な猫の動画 [わずかなノイズ] + [詳細情報] = [完成した猫動画] なぜランダムから始めて成功するのか? 1. 無限の可能性 ランダムノイズは全ての可能な画像の「種」 条件ベクトルが特定の方向に導く 2. 段階的精密化 Step 1: "何かの物体がある" Step 10: "動物らしい" Step 20: "猫らしい" Step 50: "美しい猫が歩いている" 3. 多様性の確保 同じプロンプトでも毎回異なるノイズ 結果として多様な動画生成
拡散モデル - 動画生成エンジン
wan_2.1_vae.safetensors VAEの役割 高解像度動画 ←→ 圧縮された潜在表現 512×512×16frames ←→ 64×64×16frames 効率化効果 メモリ使用量:
約1/48に削減 計算速度: 大幅高速化 品質: ほぼ劣化なし 動画特化機能 時間的一貫性の保持 フレーム間の滑らかな変化 時空間圧縮の最適化 VAE - 潜在空間と画像空間の橋渡し なぜ圧縮が必要か? RAM/メモリ内での処理: [512×512×16の巨大データ] → GPU計算 → [結果] ↑ これが重 すぎて計算困難 圧縮後: [64×64×16の小さなデータ] → GPU計算 → [結果] ↑ これなら 軽々と計算可能 ❌ 悪い例: 巨大な材料(512×512×16)を丸ごと鍋に入れる → 鍋が重すぎて持ち上がら ない → コンロの火力不足で調理不可 ✅ 良い例: 材料を小さく切る(64×64×16に圧縮) → 軽い鍋でサクサク調理 → 美味しい料理(高品質動画)完成 時間的一貫性の保持って? 悪い圧縮(時間的一貫性なし): Frame 1: 黒猫を圧縮 → 復元 → 黒猫 Frame 2: 黒猫を圧縮 → 復元 → 白猫?! Frame 3: 黒猫を圧縮 → 復元 → 茶色猫?! 結果: チカチカして見づらい動画 良い圧縮(時間的一貫性あり): Frame 1: 黒猫を圧縮 → 復元 → 黒猫 Frame 2: 黒猫を圧縮 → 復元 → 黒猫(少し動いた) Frame 3: 黒猫を圧縮 → 復元 → 黒猫(さらに動いた) 結果: 滑らかで自然な動画 なぜ「ほぼ劣化なし」なのか? 賢い圧縮の秘密 普通の圧縮: 機械的に小さくする → 情報欠落 VAEの圧縮: 人間が見て重要な部分を優先保存 例: - 猫の輪郭 → 絶対保持 - 背景の微細なノイズ → 削除OK - 毛の流れ → 重要なので保持 - 影の微妙な変化 → 簡略化OK 学習による最適化 VAEは何千万枚もの動画で学習済み 「どこを残してどこを削るか」を熟知している まるで熟練の職人のような圧縮技術 🚀 Wan2.1 VAEの特別なところ 時空間最適化 普通のVAE: 各フレームを個別圧縮 Wan2.1 VAE: 動画全体を一つの塊として圧縮 効果: - フレーム間のちらつき防止 - 自然な動きの保持 - より効率的な圧縮
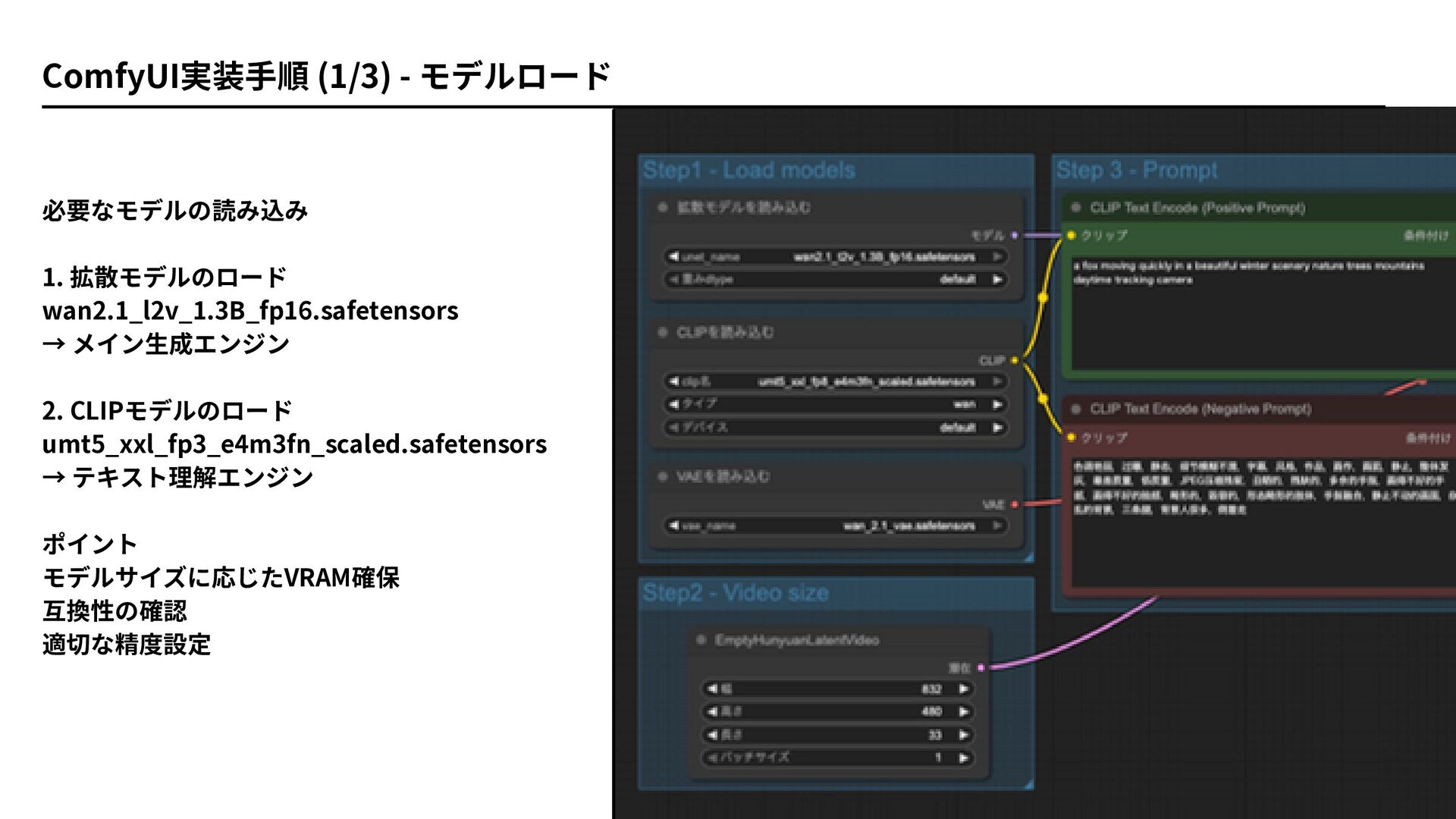
必要なモデルの読み込み 1. 拡散モデルのロード wan2.1_l2v_1.3B_fp16.safetensors → メイン生成エンジン 2. CLIPモデルのロード umt5_xxl_fp3_e4m3fn_scaled.safetensors →
テキスト理解エンジン ポイント モデルサイズに応じたVRAM確保 互換性の確認 適切な精度設定 ComfyUI実装手順 (1/3) - モデルロード
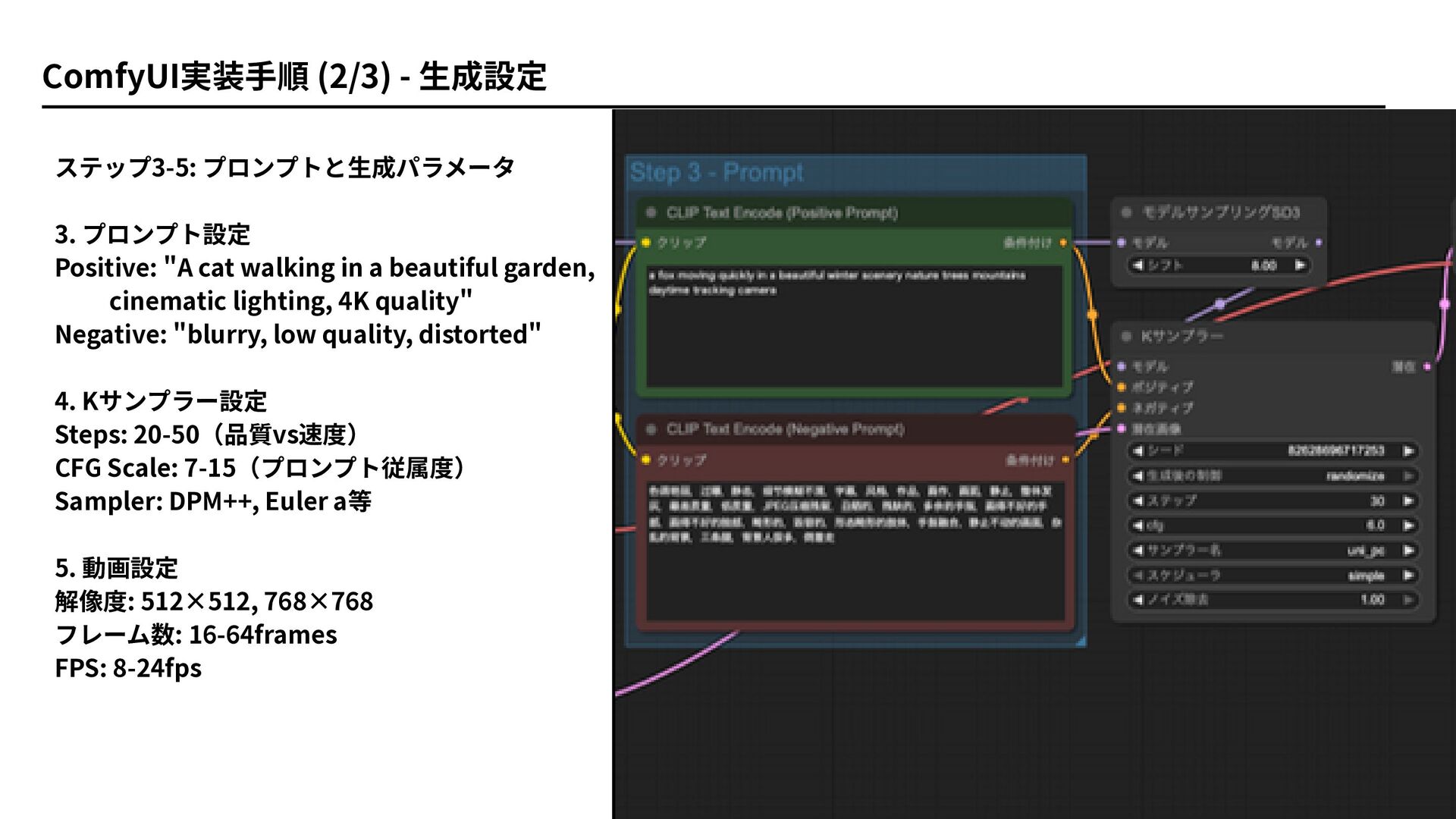
ステップ3-5: プロンプトと生成パラメータ 3. プロンプト設定 Positive: "A cat walking in a
beautiful garden, cinematic lighting, 4K quality" Negative: "blurry, low quality, distorted" 4. Kサンプラー設定 Steps: 20-50(品質vs速度) CFG Scale: 7-15(プロンプト従属度) Sampler: DPM++, Euler a等 5. 動画設定 解像度: 512×512, 768×768 フレーム数: 16-64frames FPS: 8-24fps ComfyUI実装手順 (2/3) - 生成設定
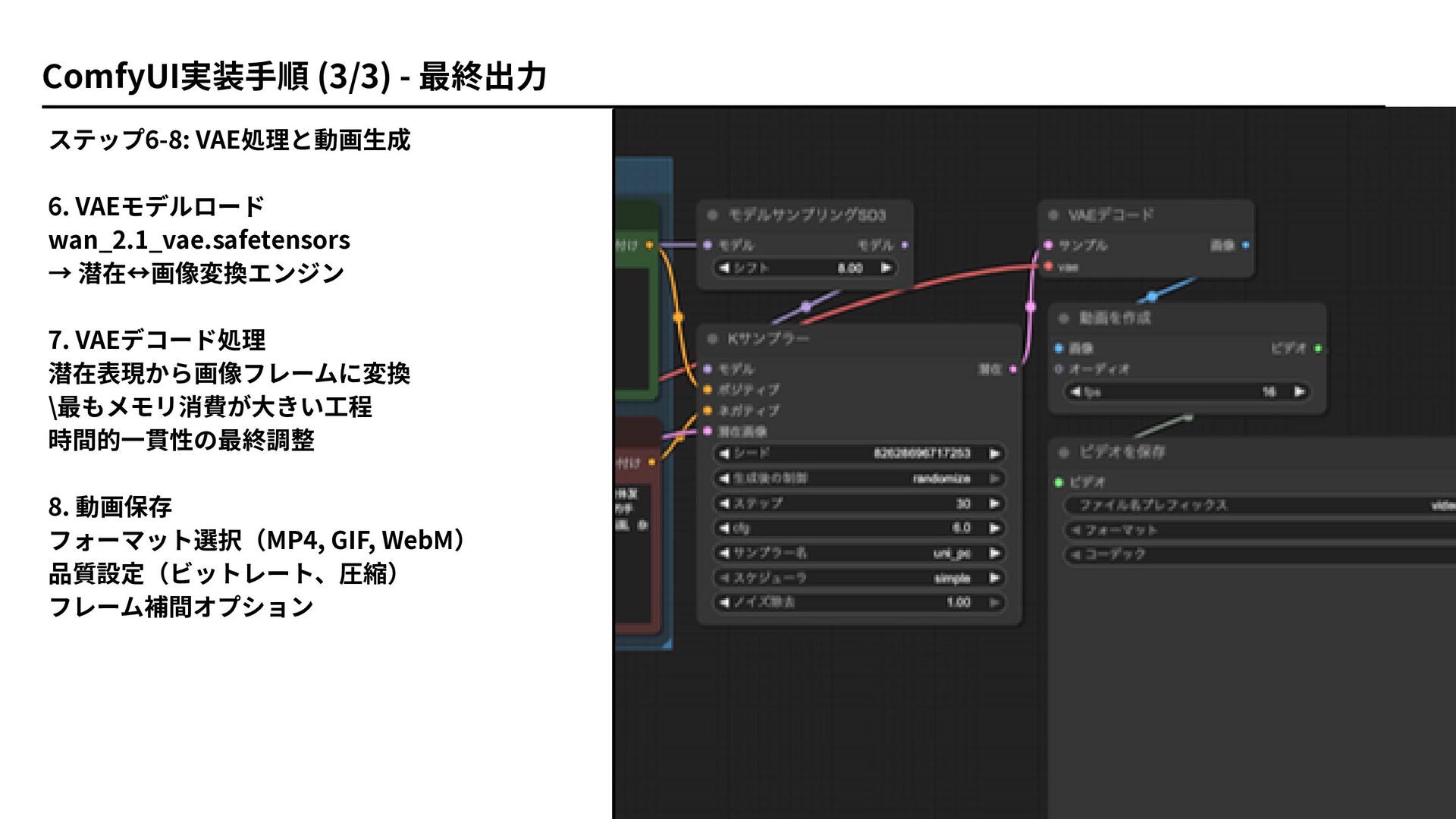
ステップ6-8: VAE処理と動画生成 6. VAEモデルロード wan_2.1_vae.safetensors → 潜在↔画像変換エンジン 7. VAEデコード処理 潜在表現から画像フレームに変換
\最もメモリ消費が大きい工程 時間的一貫性の最終調整 8. 動画保存 フォーマット選択(MP4, GIF, WebM) 品質設定(ビットレート、圧縮) フレーム補間オプション ComfyUI実装手順 (3/3) - 最終出力
品質向上のための実践的ガイダンス プロンプト最適化 具体的で明確な記述 視覚的要素の詳細指定 ネガティブプロンプトの効果的活用 サンプラー調整 高品質重視: Steps↑, CFG Scale
7-10 速度重視: Steps↓, CFG Scale 5-7 実験的: 異なるSampler試行 リソース管理 VRAM不足時は解像度/フレーム数削減 バッチサイズの調整 精度設定の最適化 パラメータ最適化のコツ
よくある問題と解決策 メモリ不足エラー 解像度を下げる(768→512) フレーム数を減らす(64→32) 他のアプリケーション終了 品質問題 ぼやけた動画 → Steps数増加、VAE確認 不自然な動き
→ CFG Scale調整 色彩異常 → VAEモデル再確認 生成速度 モデル精度設定見直し ハードウェア最適化 不要なノード削除 トラブルシューティング
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}