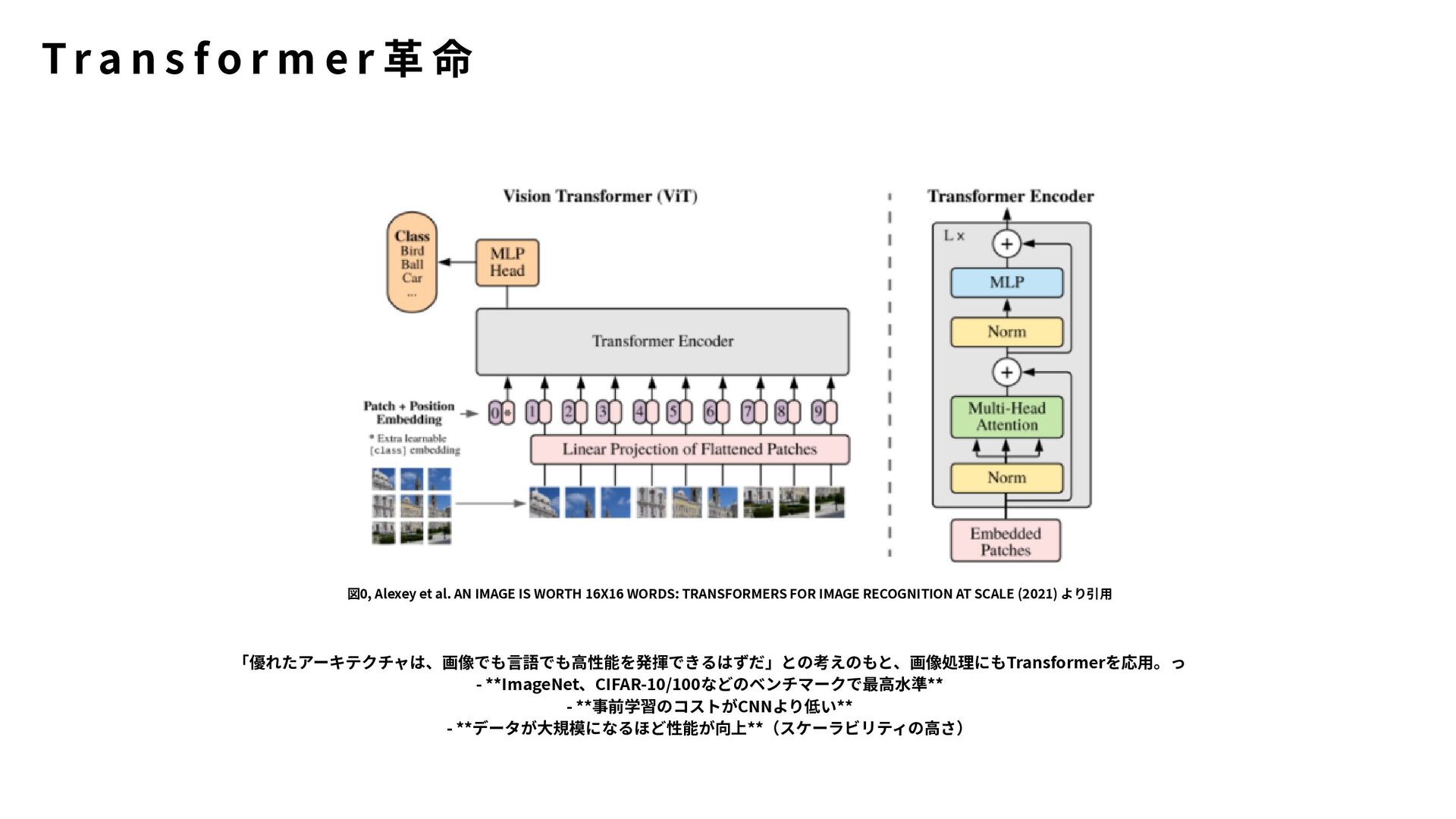
TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (2021) より引用 「優れたアーキテクチャは、画像でも言語でも高性能を発揮できるはずだ」との考えのもと、画像処理にもTransformerを応用。っ - **ImageNet、CIFAR-10/100などのベンチマークで最高水準** - **事前学習のコストがCNNより低い** - **データが大規模になるほど性能が向上**(スケーラビリティの高さ) T r a n s f o r m e r 革 命
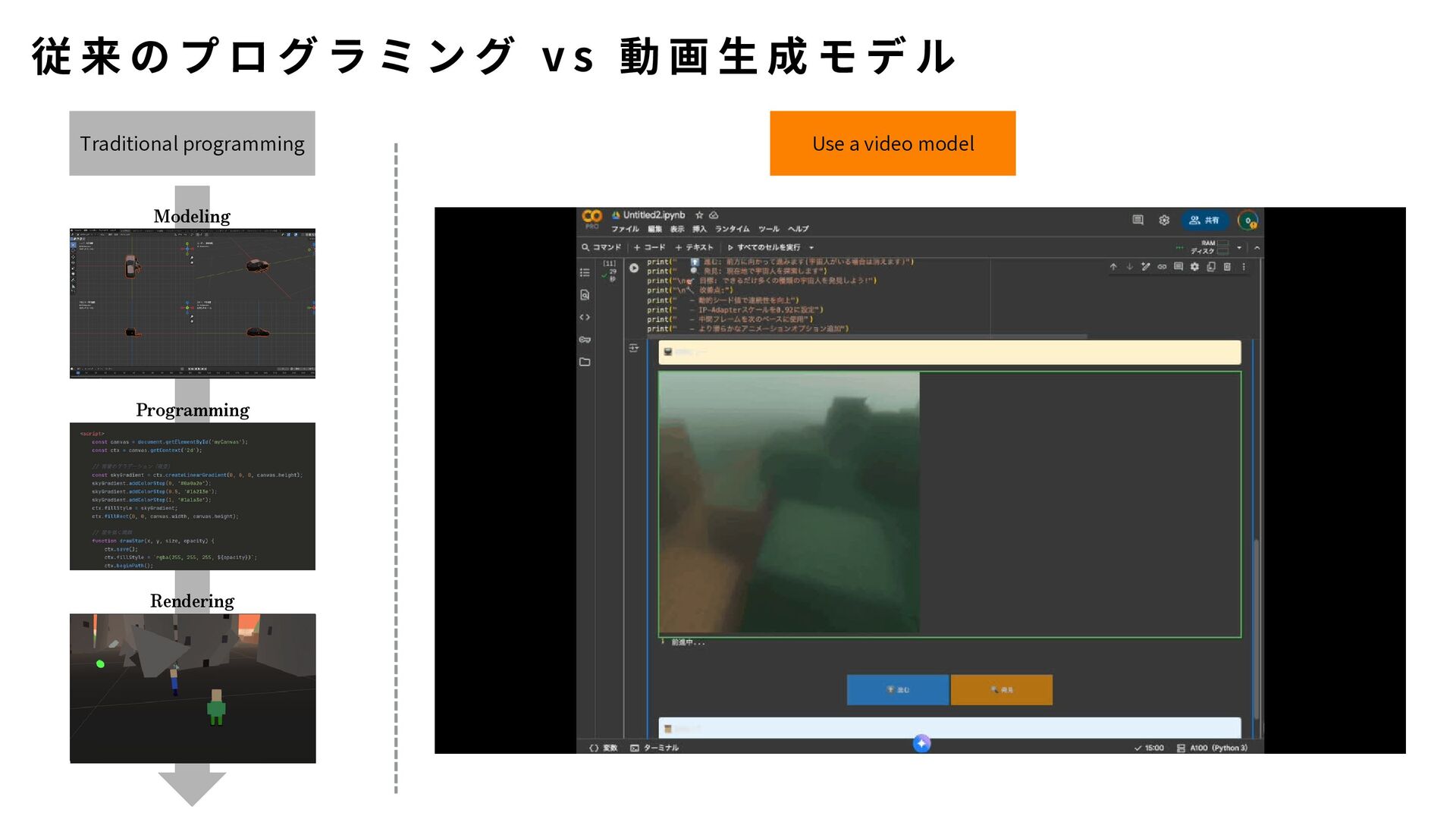
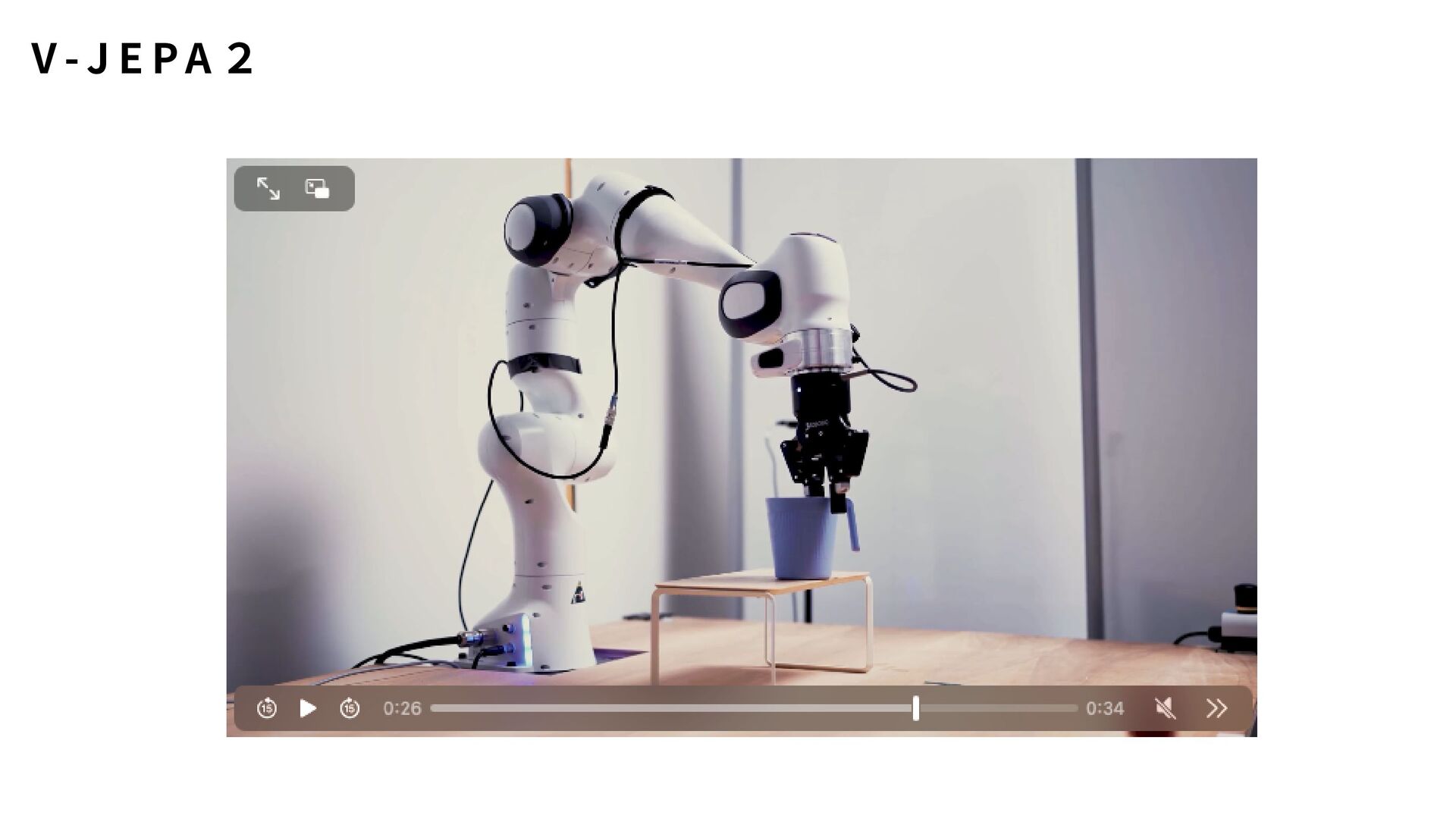
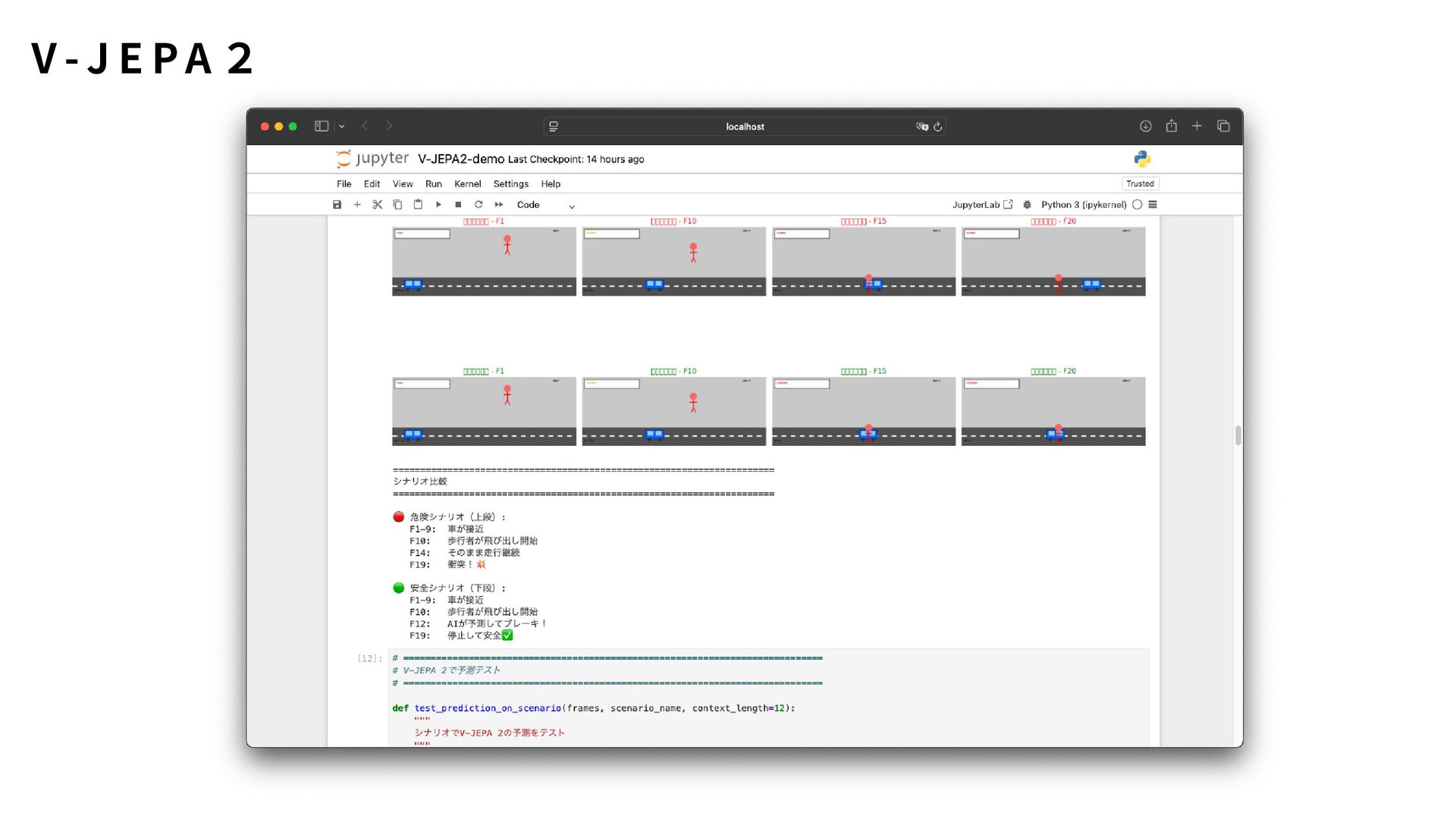
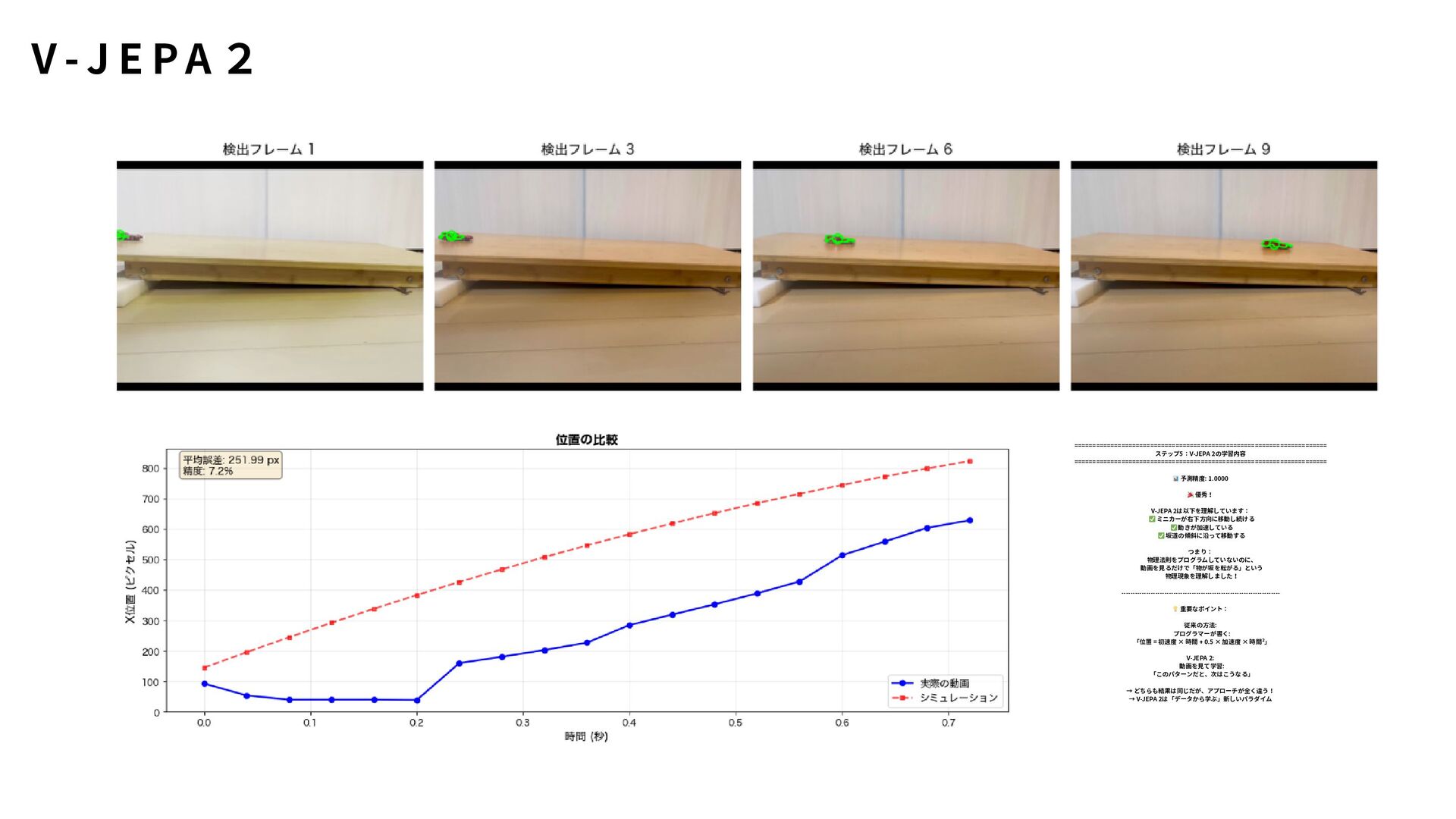
新しい動作ごとに再実装が必要 OpenCVでは難しいが、V-JEPA 2なら可能: 「コップを持ち上げる」vs「コップを倒す」の区別 「ドアを押す」vs「ドアを引く」の違い # V-JEPA 2だと... outputs = model(video) # それだけ! # 学習済みの知識で複雑な動作を理解 O p e n C V v s V - J E PA 2
リアルタイム性と連続的な意思決定 バランス制御は: 刻一刻と変化する状態に対して、連続的かつ即座に制御入力を調整する必要がある 単発の入力→出力のマッピングではなく、時系列の動的な制御が求められる 教師あり学習は静的なパターン認識には強いが、このような動的制御には不向き 3. 報酬の遅延性 「転倒しなかった」という結果は一連の動作の最後にしか判明しない どの時点のどの動作が成功/失敗に寄与したのか特定しにくい(credit assignment problem) 教師あり学習では各入力に対する即座の正解が必要だが、バランス制御ではこれが得られな い h t t p s : / / r o b o t s t a r t . i n f o / a r t i c l e / 2 0 2 0 / 0 4 / 0 6 / 1 9 5 0 6 6 . h t m l ロボットの転倒防止やバランス制御には教師あり学習は向いていない
大規模世界モデル(Large World Models - LWM)を開発し、3D世界の認識、生成、相 互作用を可能にする 「空間知能(Spatial Intelligence)」をAIに 与えることに焦点 単一画像からインタラクティブな3D環境を 生成可能 ゲームのようなシーンをブラウザ内で探 索・修正可能 生成されたシーンは物理法則に従い、堅実 性と深度の感覚を持つ ゲーム会社、映画スタジオ、建築家、デザ イナーなどのプロフェッショナル向け W o r l d L a b s b y F e i - F e i L i
H100 GPU使用) フレームごとに自己回帰的に生成 Oasis 2.0: Minecraftのリアルタイムモッド 版 プレイ中に世界をリアルタイムで変換(ベネ チア、インド、ニューヨーク、中世など) ビデオtoビデオモデル「MirageLSD」を使 用 D e c a r t - O a s i s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
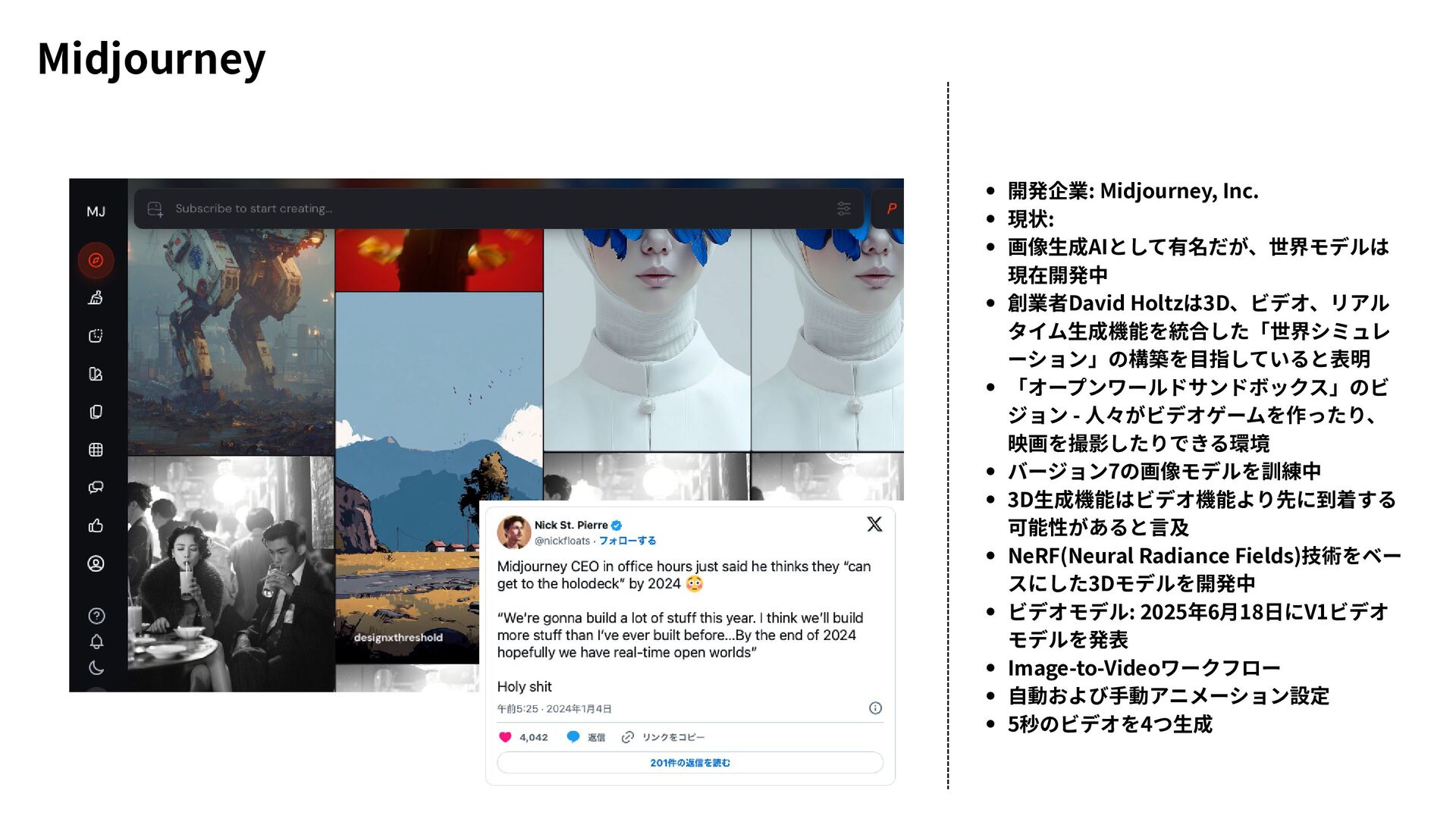{kind=link}
{kind=link}
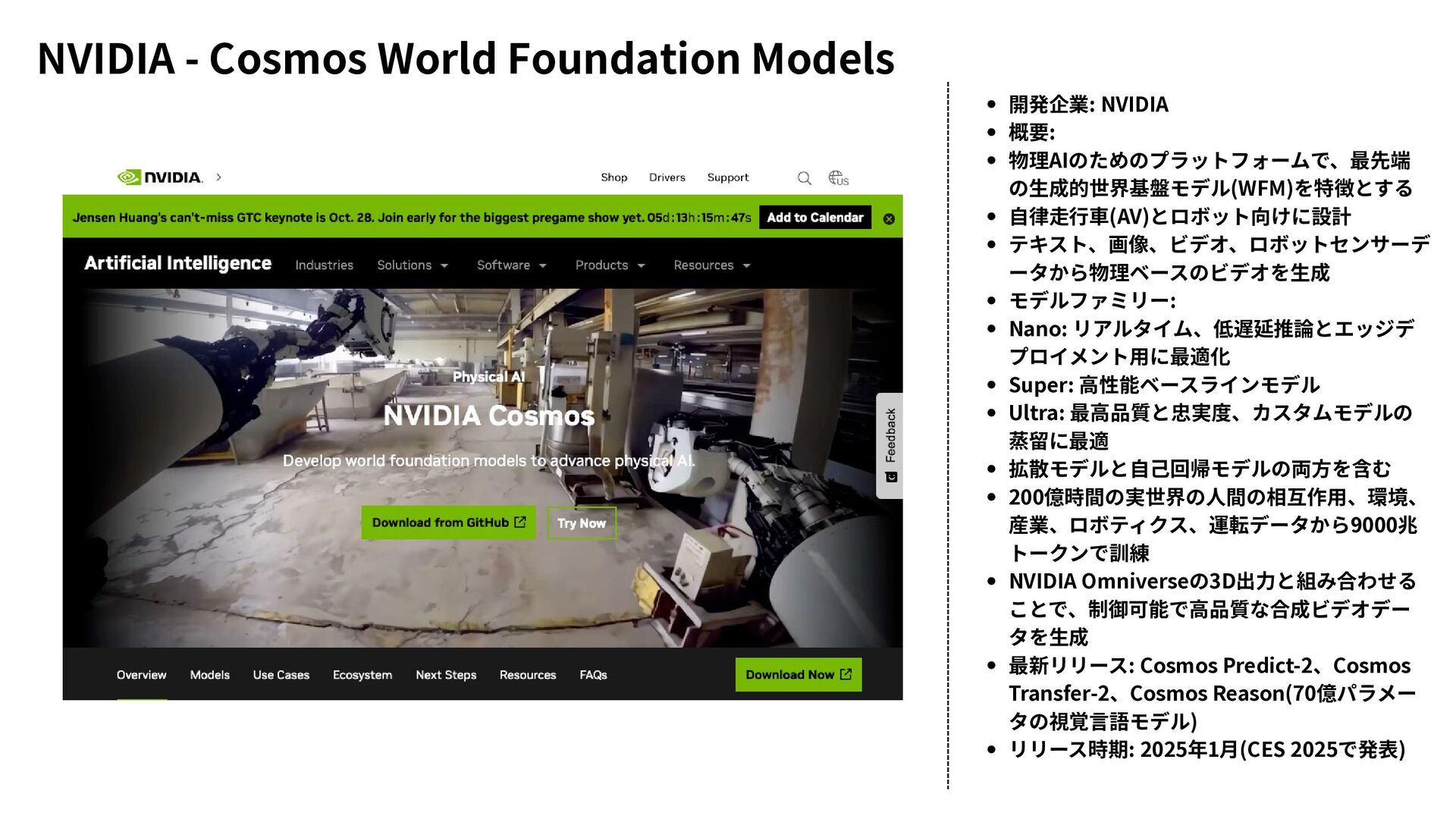{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
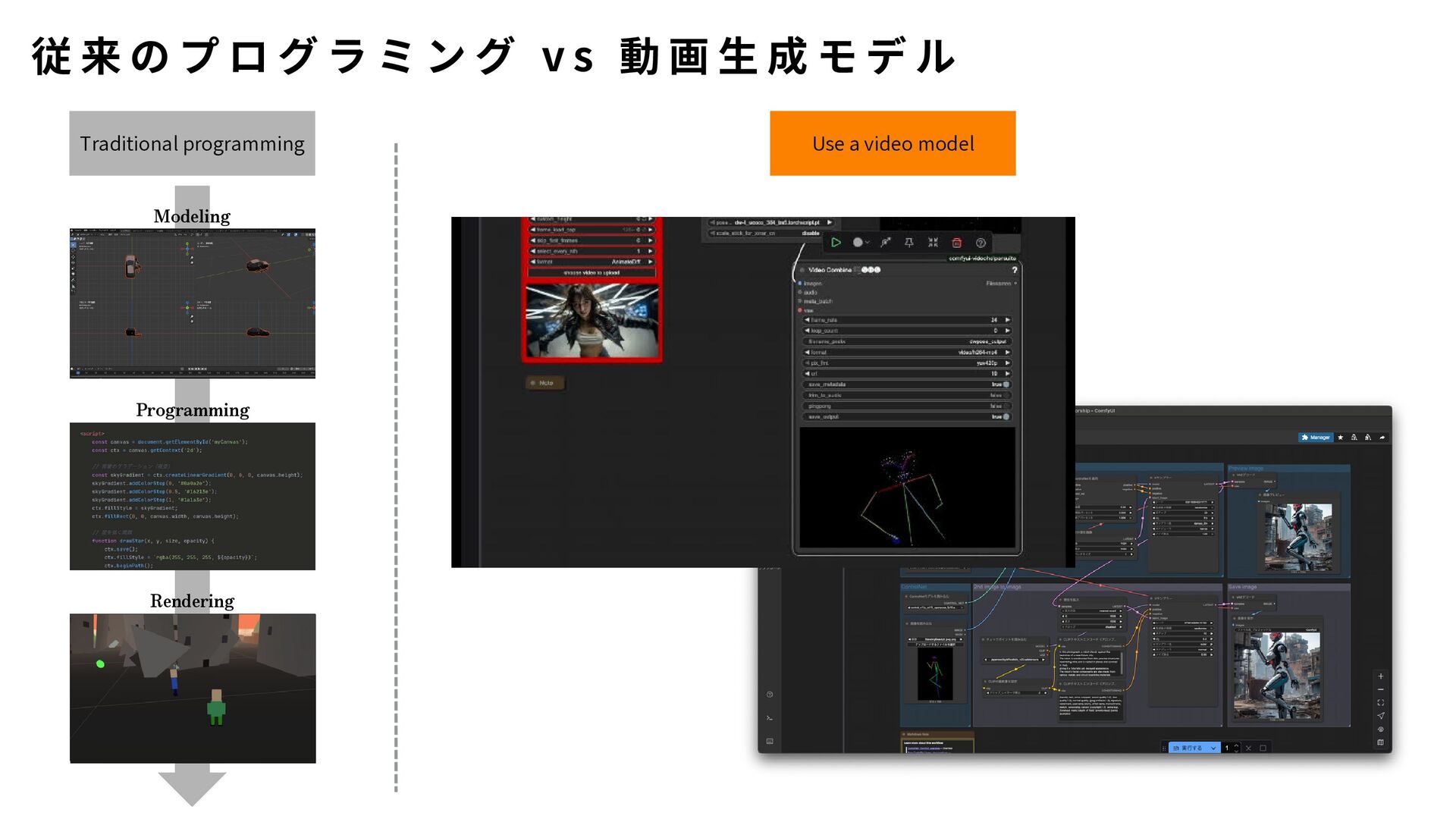{kind=link}
{kind=link}
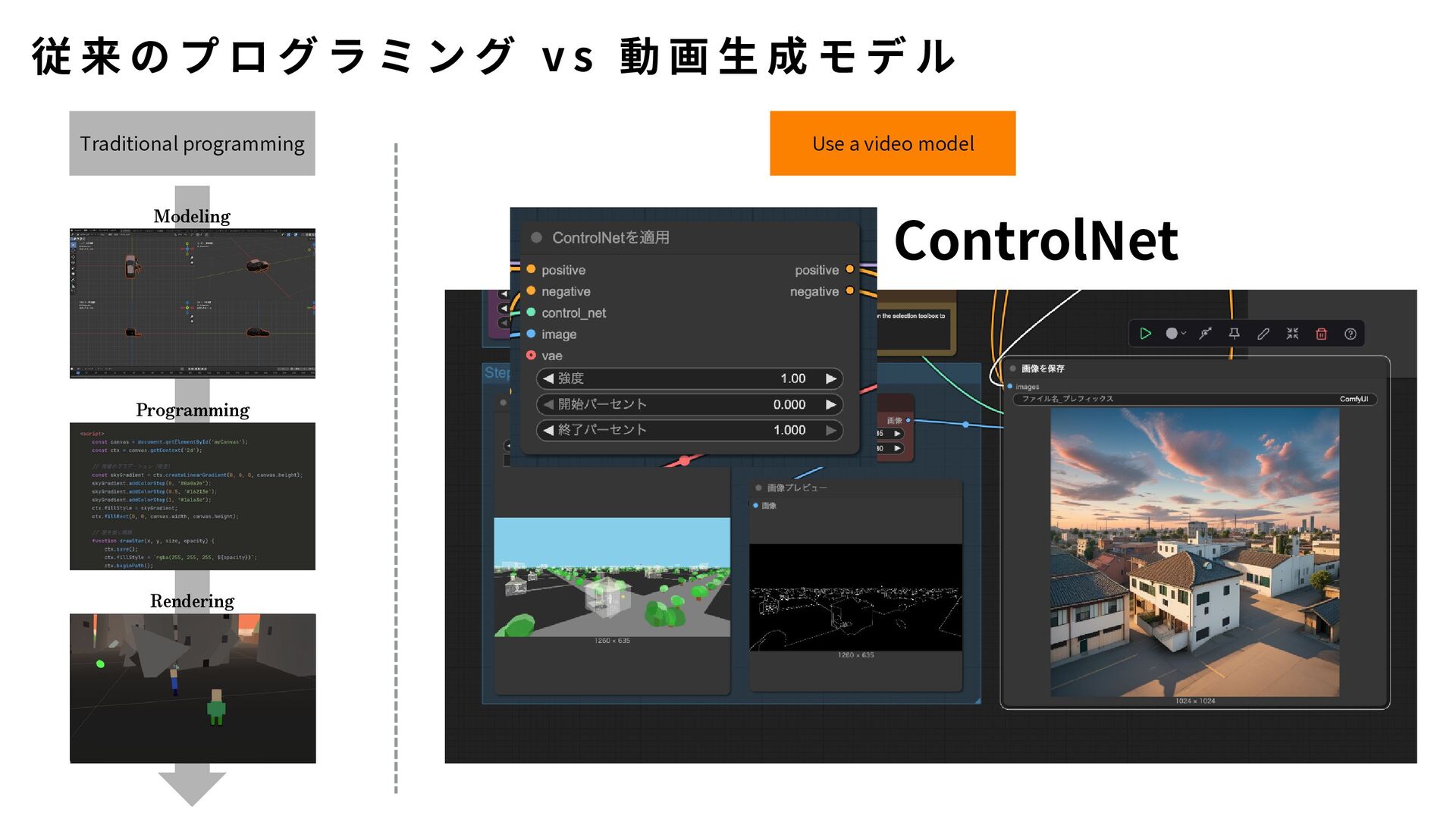{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}