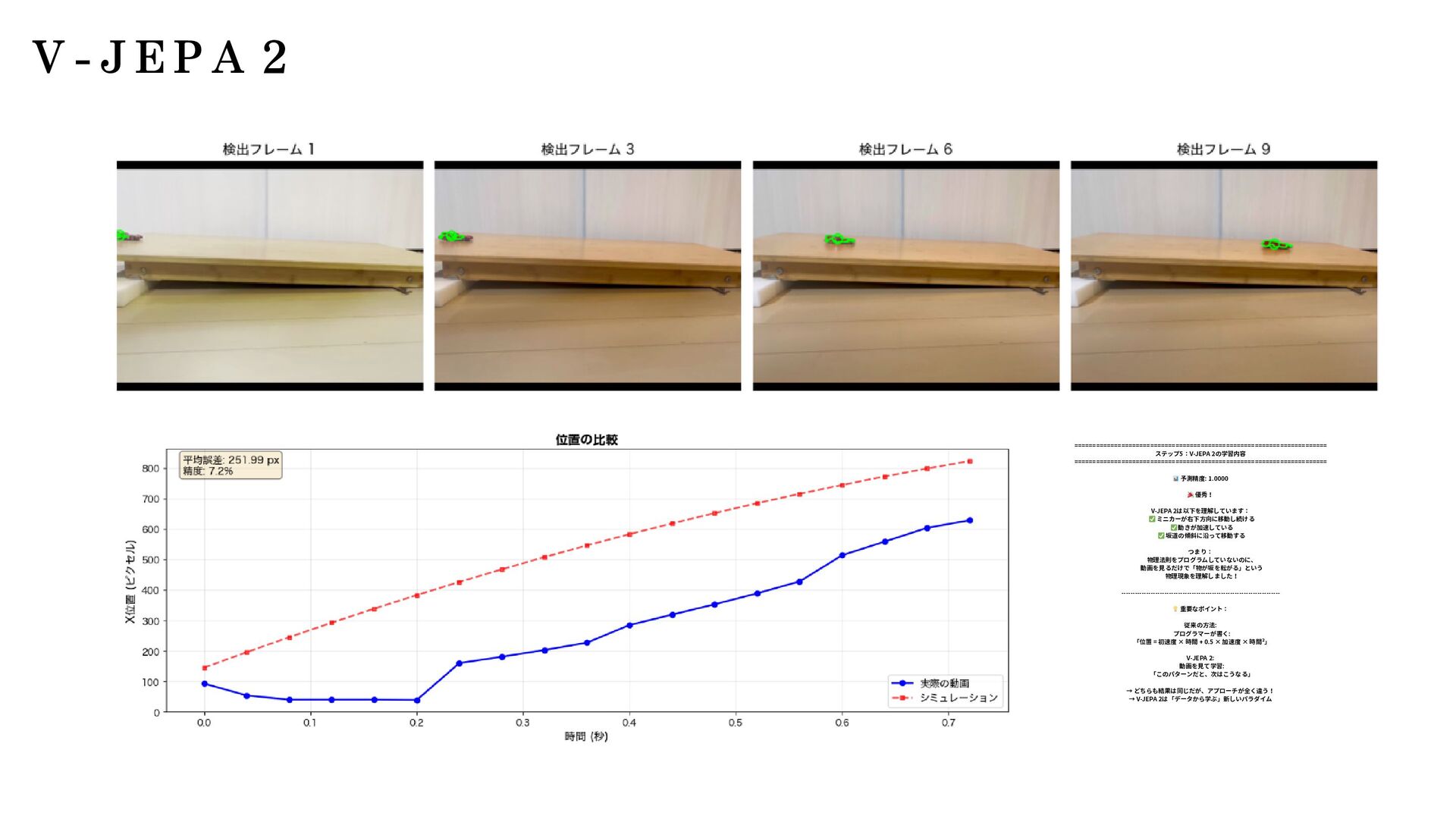
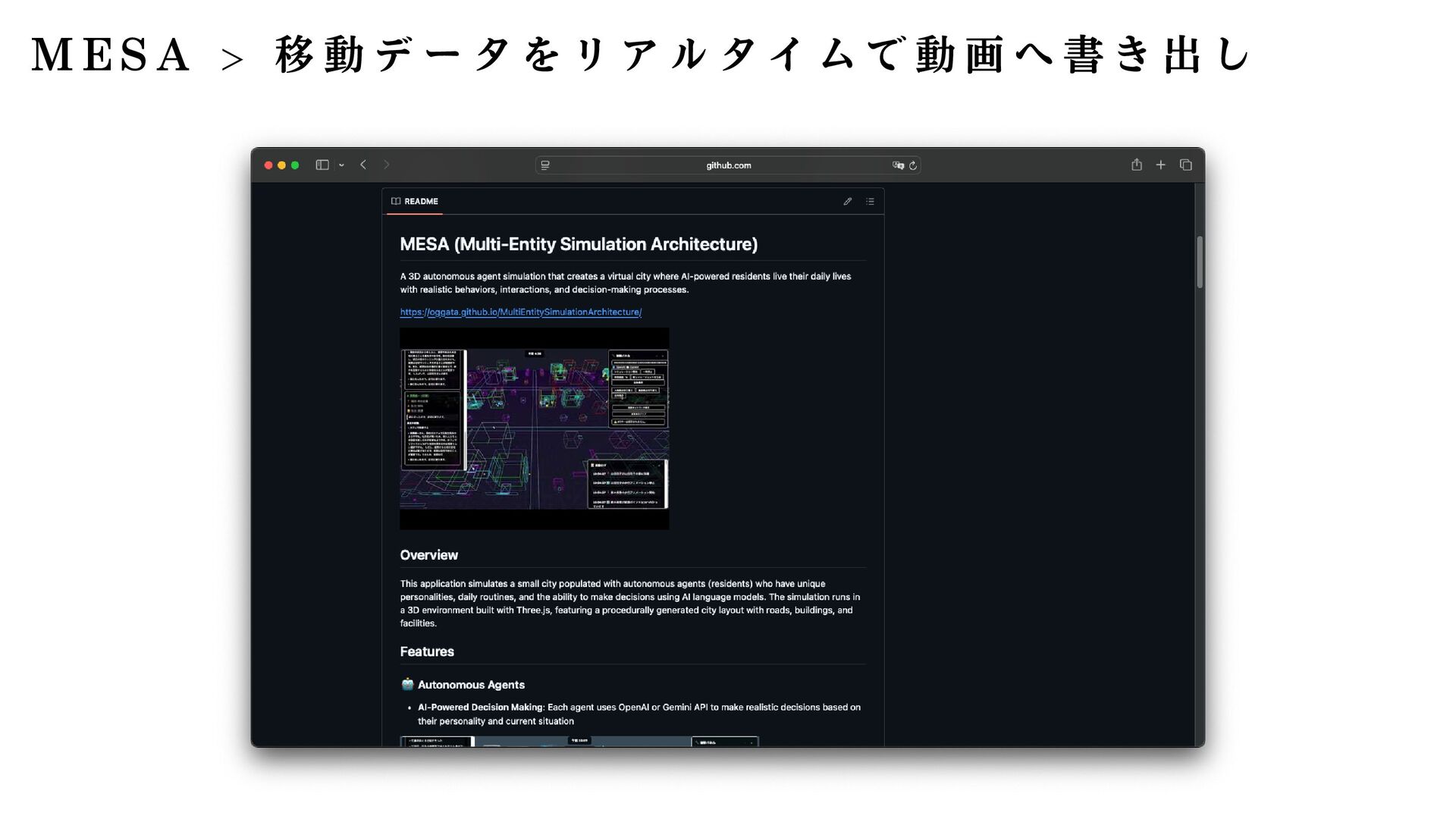
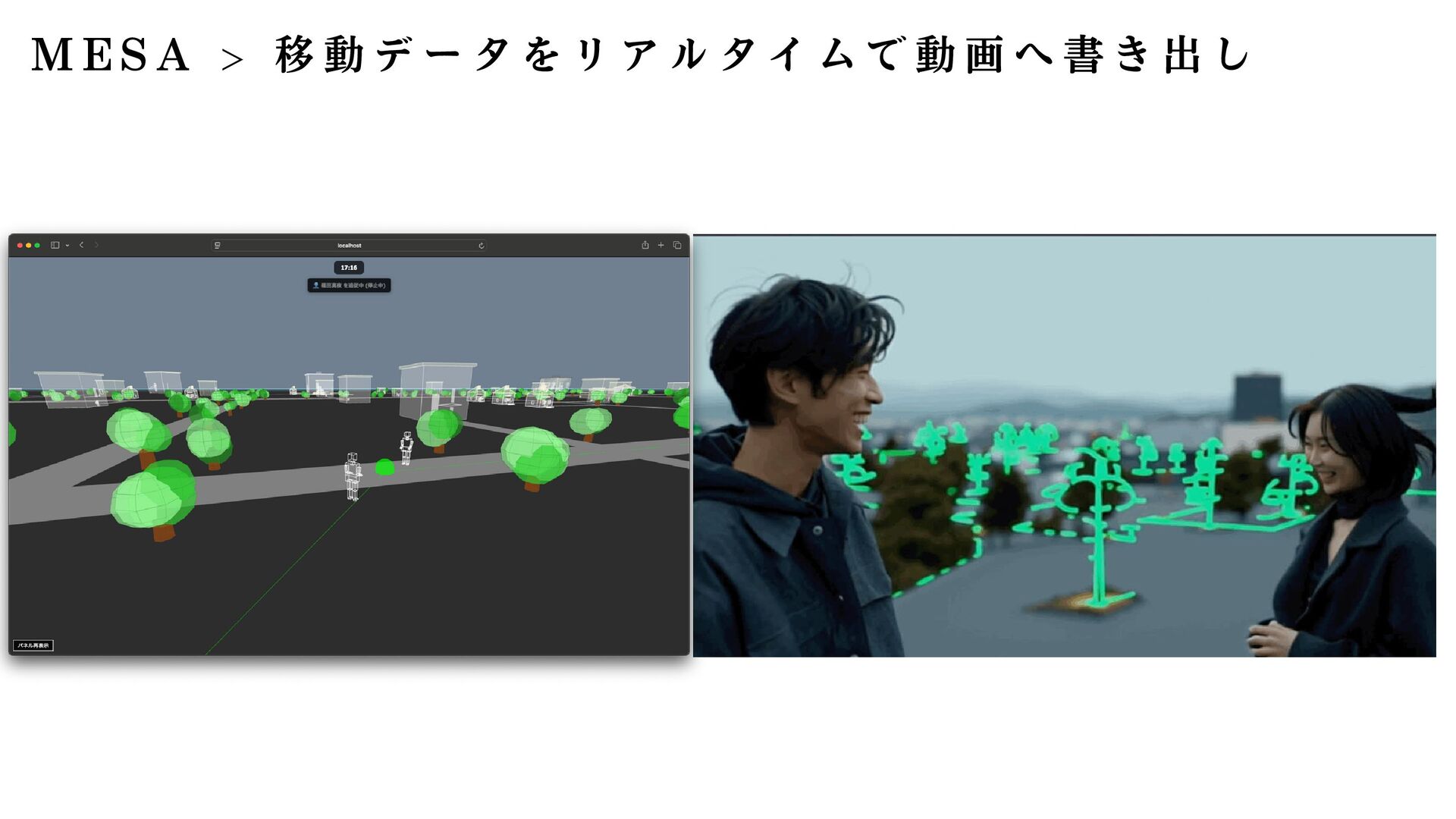
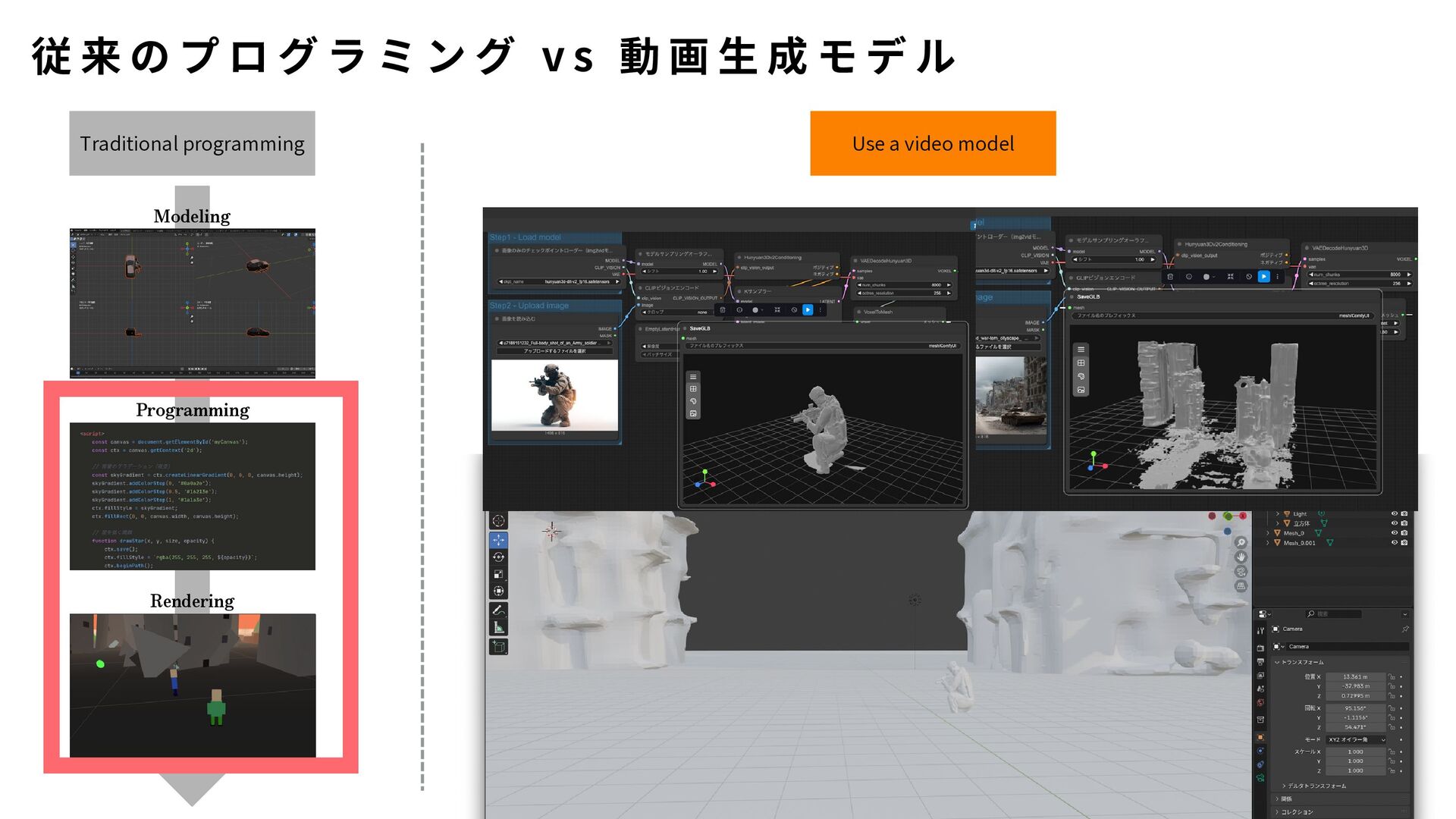
】 │ ├── プ ロ プ ラ イ エ タ リ ( 企 業 提 供 ) │ ├── GPT-4 / GPT-4 Turbo (OpenAI, 2023) │ ├── GPT-4o / GPT-4o mini (OpenAI, 2024) │ ├── o1 / o1-mini / o1-pro (OpenAI, 2024/2025) ← 推 論 特 化 │ ├── Claude 3 Opus / Sonnet / Haiku (Anthropic, 2024) │ ├── Claude 3.5 Sonnet / Haiku (Anthropic, 2024) │ ├── Claude 4 Opus / Sonnet 4.5 (Anthropic, 2025) │ ├── Gemini 1.5 Pro / Flash (Google, 2024) │ ├── Gemini 2.0 Flash (Google, 2024) │ ├── Gemini 2.5 Pro (Google, 2025) │ └── Grok 2 / Grok 3 (xAI) │ ├── オ ー プ ン ソ ー ス - 大 規 模 (70B 以 上 ) │ ├── LLaMA 3 (8B, 70B, 405B) (Meta, 2024) │ ├── LLaMA 3.1 (8B, 70B, 405B) (Meta, 2024) │ ├── LLaMA 3.3 (70B) (Meta, 2024) │ ├── Qwen2.5 (0.5B 〜 72B) (Alibaba, 2024) │ ├── Qwen3 (Alibaba, 2025) │ ├── DeepSeek-V2 / V3 (DeepSeek, 2024/2025) │ ├── Mistral Large (Mistral AI) │ └── Yi-Large (01.AI) │ ├── オ ー プ ン ソ ー ス - 中 規 模 (7B 〜 70B) │ ├── Mistral 7B / 8x7B / 8x22B (Mistral AI) │ ├── Mixtral 8x7B / 8x22B (Mistral AI) ←MoE │ ├── Command R / R+ (Cohere) │ ├── Gemma 2 (9B, 27B) (Google) │ ├── Gemma 3 (4B, 27B) (Google, 2025) │ └── Nemotron (NVIDIA) │ ├── オ ー プ ン ソ ー ス - 小 規 模 (7B 以 下 ) │ ├── Phi-3 / Phi-3.5 / Phi-4 (Microsoft) │ ├── Gemma (2B, 7B) (Google) │ ├── SmolLM (135M, 360M, 1.7B) (Hugging Face) │ ├── Qwen2.5 (0.5B, 1.5B, 3B, 7B) (Alibaba) │ └── OpenELM (Apple) │ ├── 推 論 特 化 LLM │ ├── o1 / o1-mini / o1-pro (OpenAI) │ ├── QwQ-32B-Preview (Qwen) │ ├── DeepSeek-R1 (DeepSeek, 2025) │ └── Gemini 2.0 Flash Thinking (Google, 2025) │ ├── 日 本 語 特 化 LLM │ ├── Sarashina (Stability AI Japan) │ ├── PLaMo (Preferred Networks) │ ├── Japanese StableLM (Stability AI) │ ├── Swallow ( 東 京 工 業 大 学 ) │ ├── KARAKURI LM ( カ ラ ク リ ) │ └── Llama 3 Swallow ( 東 京 工 業 大 学 ) │ └── 長 文 脈 特 化 ├── Claude 3/3.5/4 (200K tokens) (Anthropic) ├── Gemini 1.5 Pro ( 最 大 2M tokens) (Google) ├── GPT-4 Turbo (128K tokens) (OpenAI) └── Command R+ (128K tokens) (Cohere)
{kind=link}
{kind=link}
{kind=link}
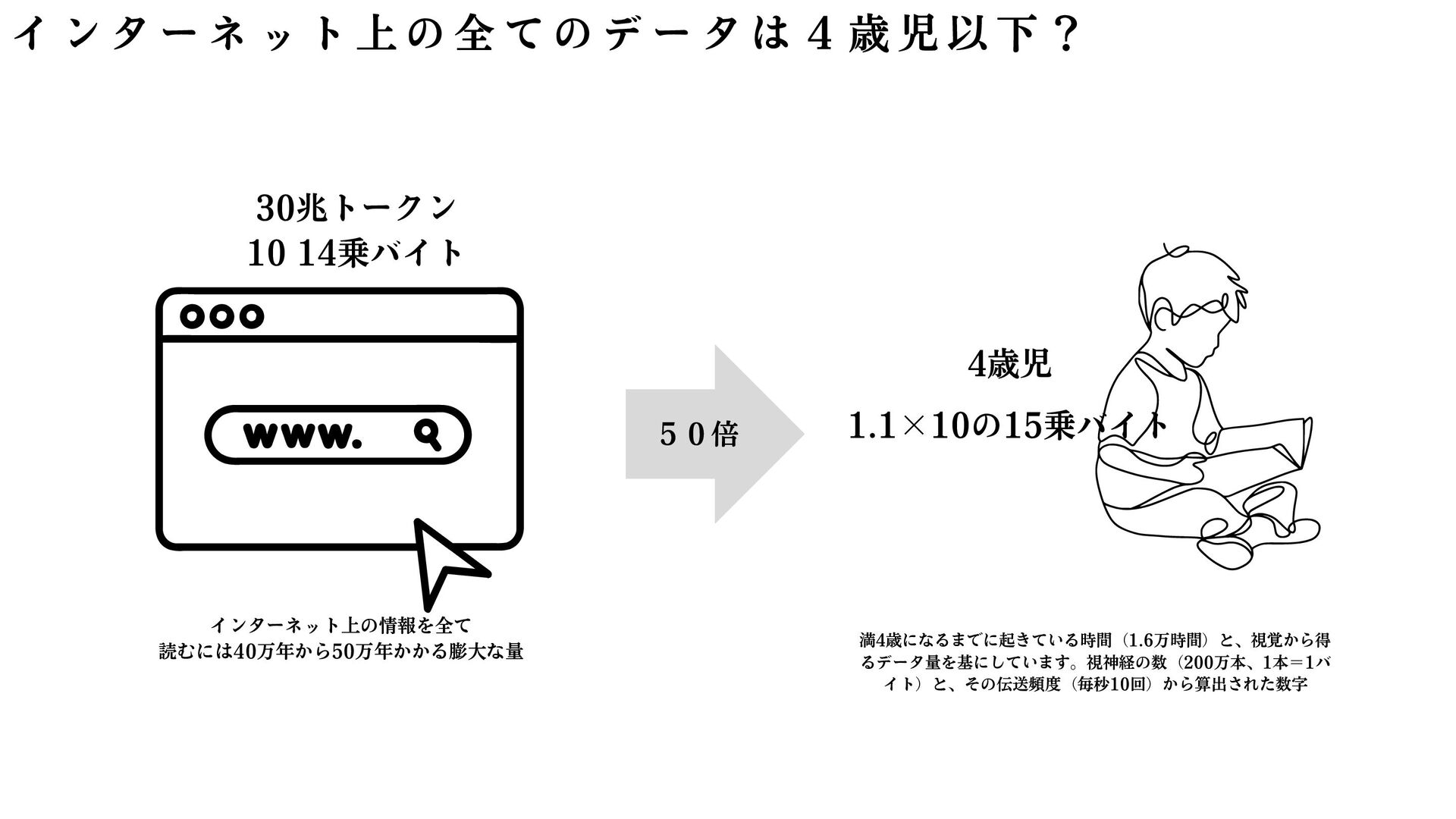{kind=link}
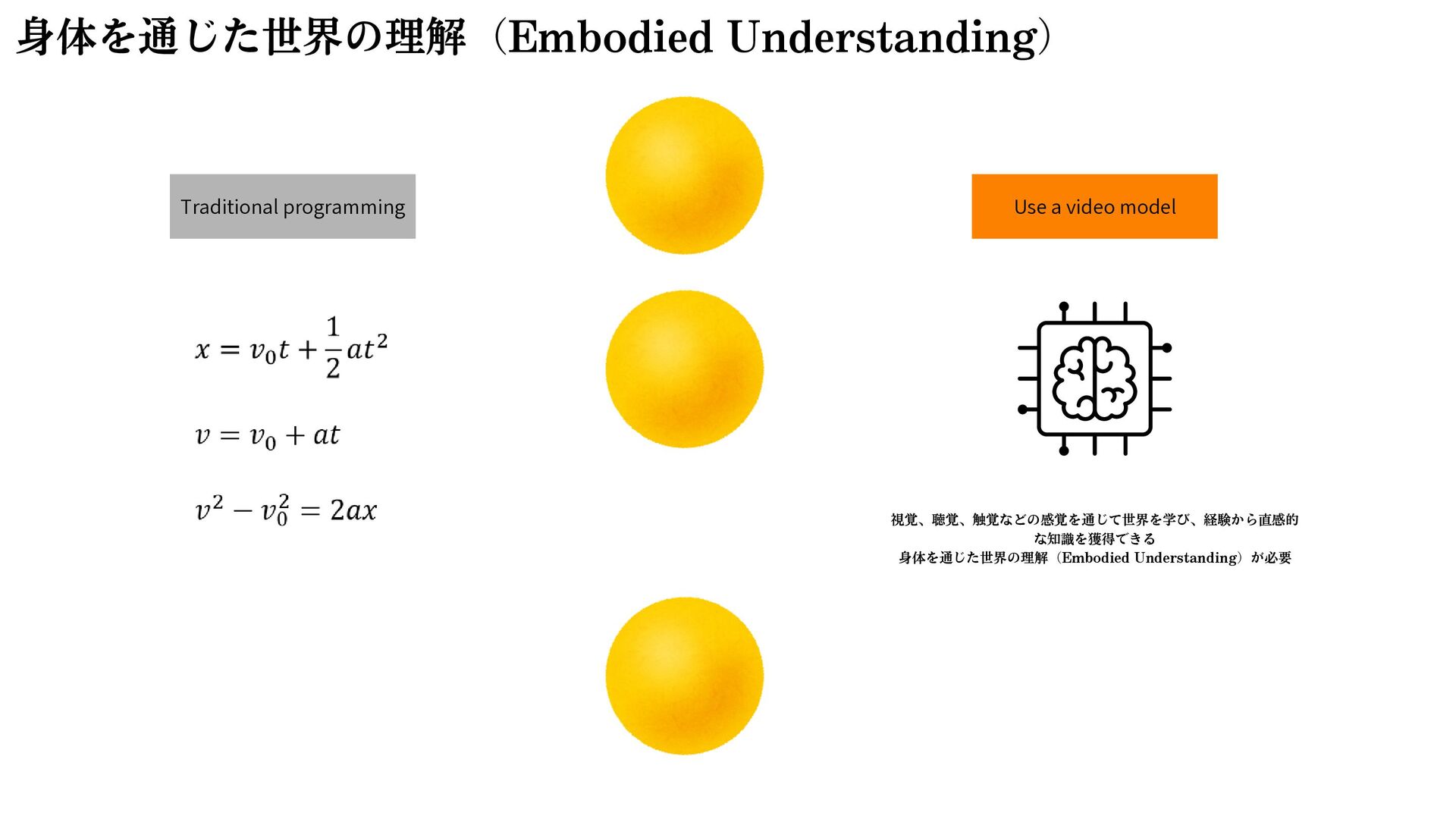{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
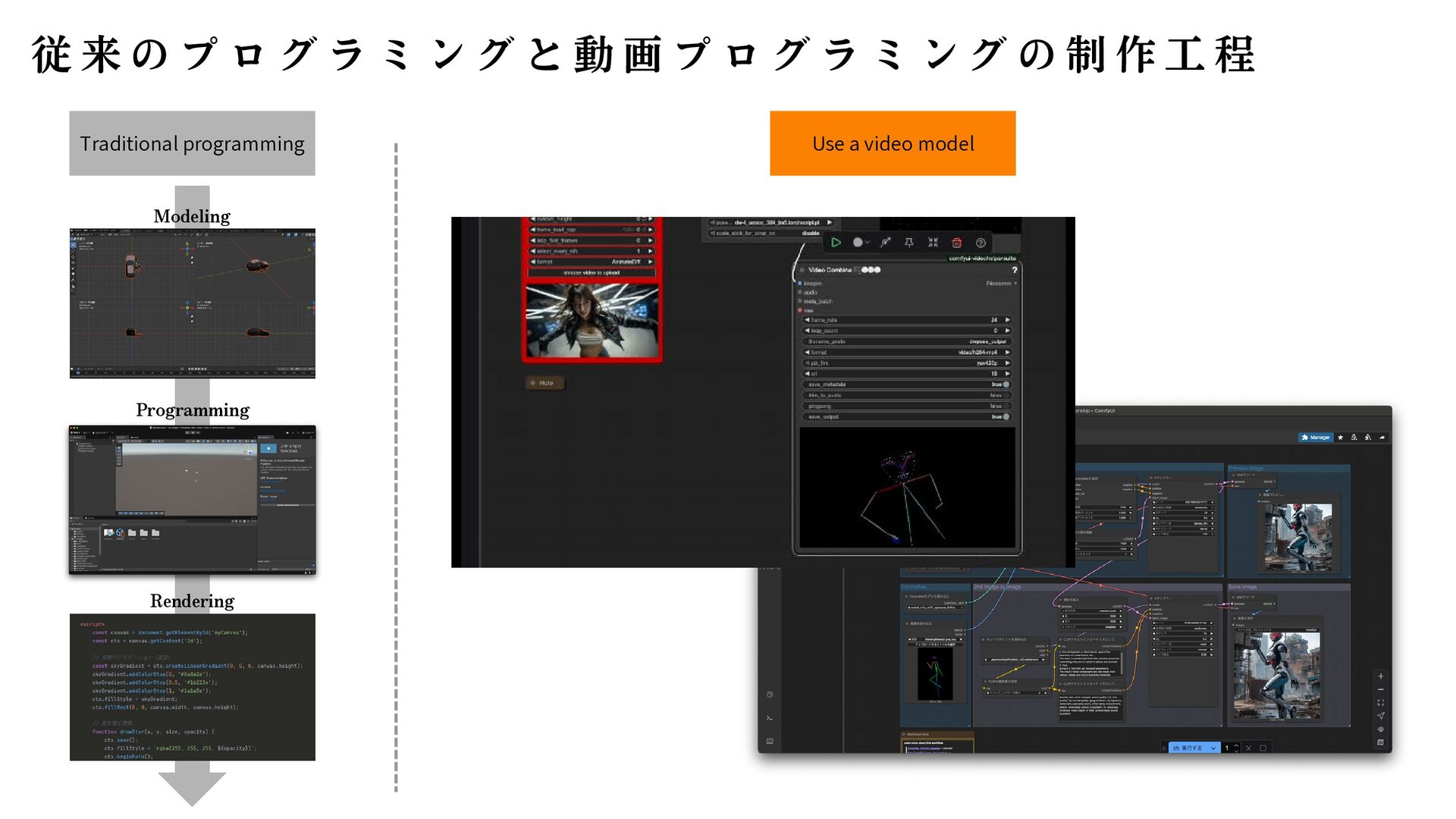{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Link: [2103.00020] Learning Transferable Visual Models From Natural Language Supervision](https://files.speakerdeck.com/presentations/8e9f1e542b3f4ba285a2dc5ea7911f92/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
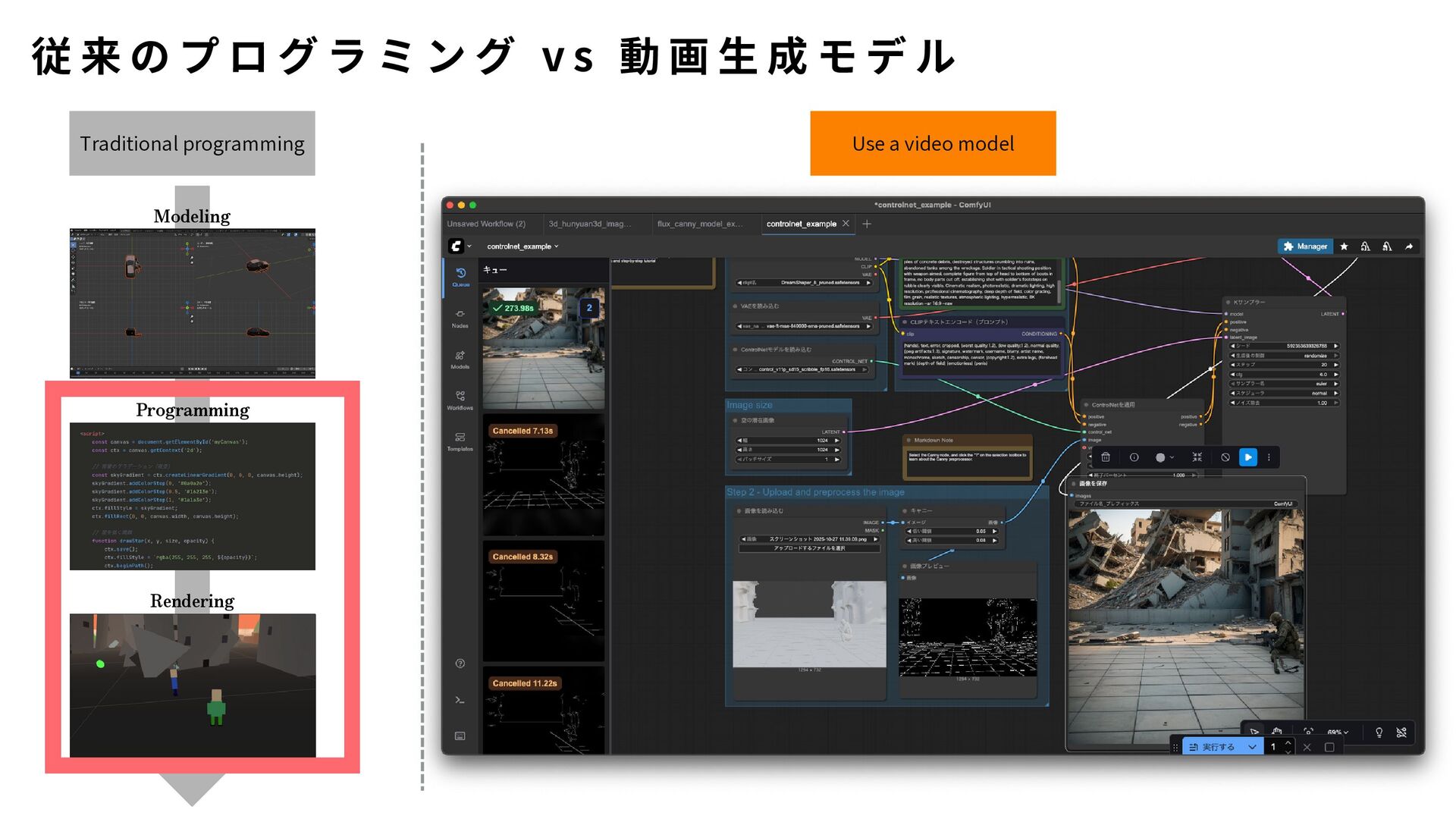{kind=link}
{kind=link}
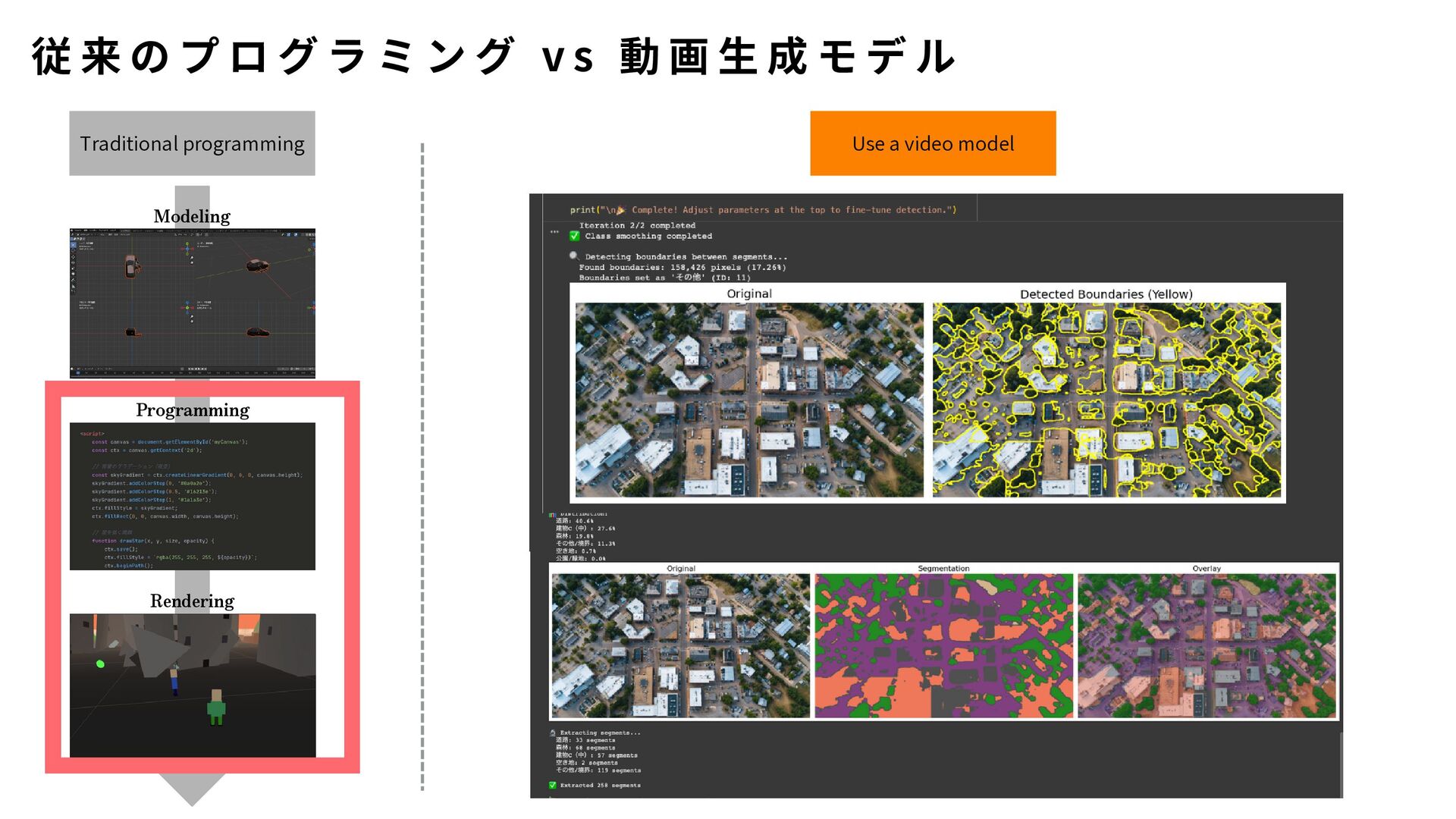{kind=link}
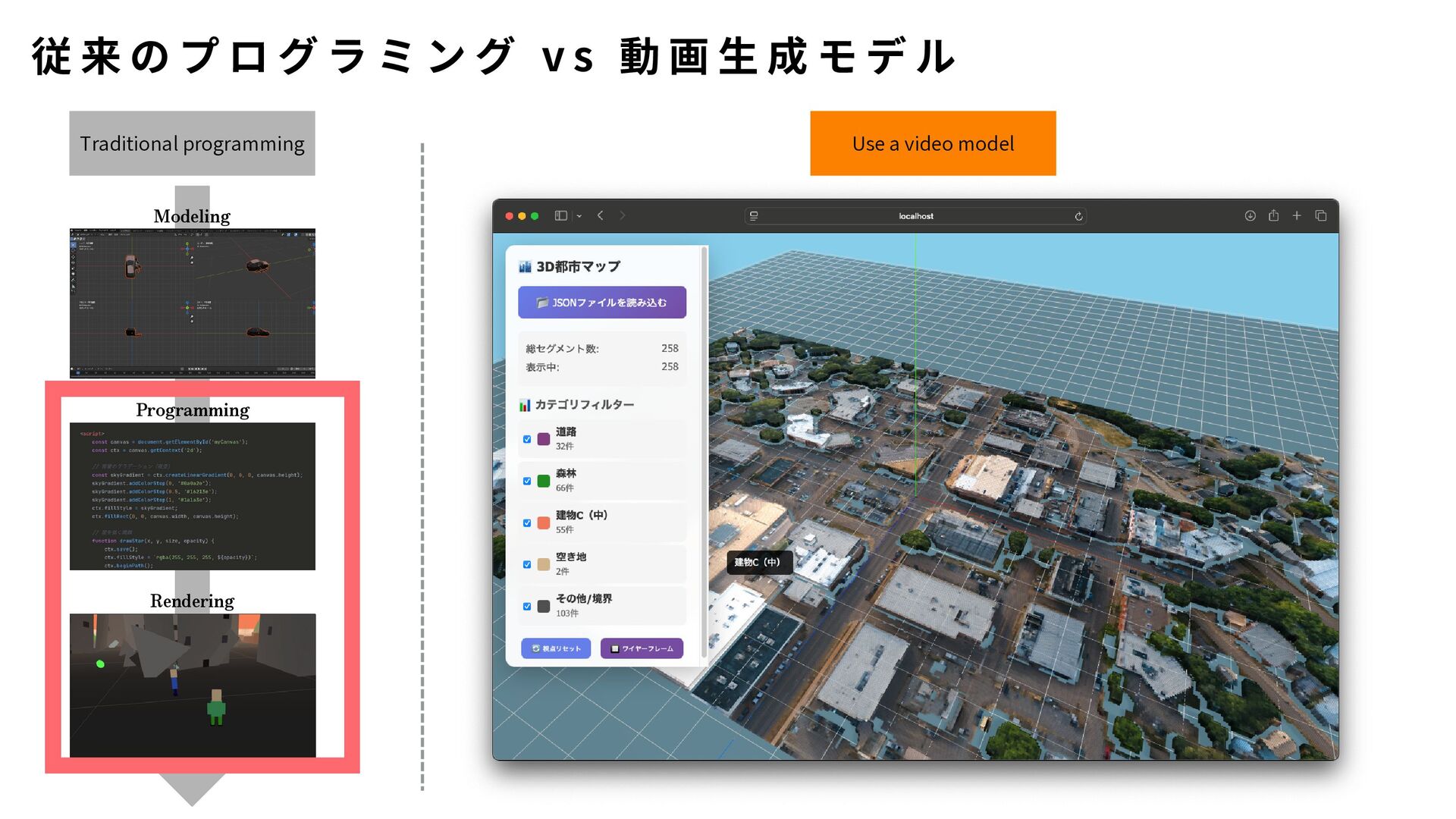{kind=link}
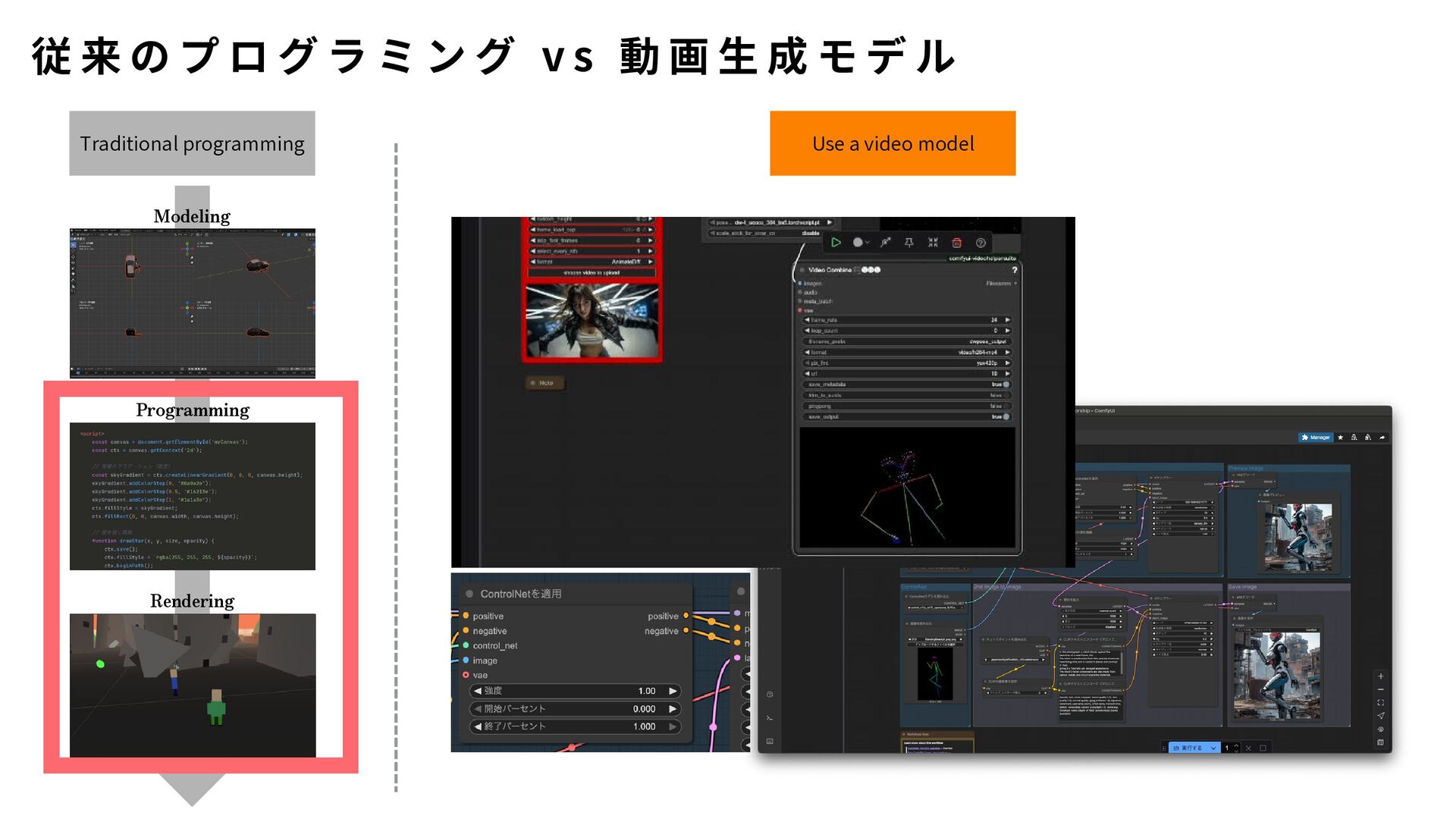{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}