Share
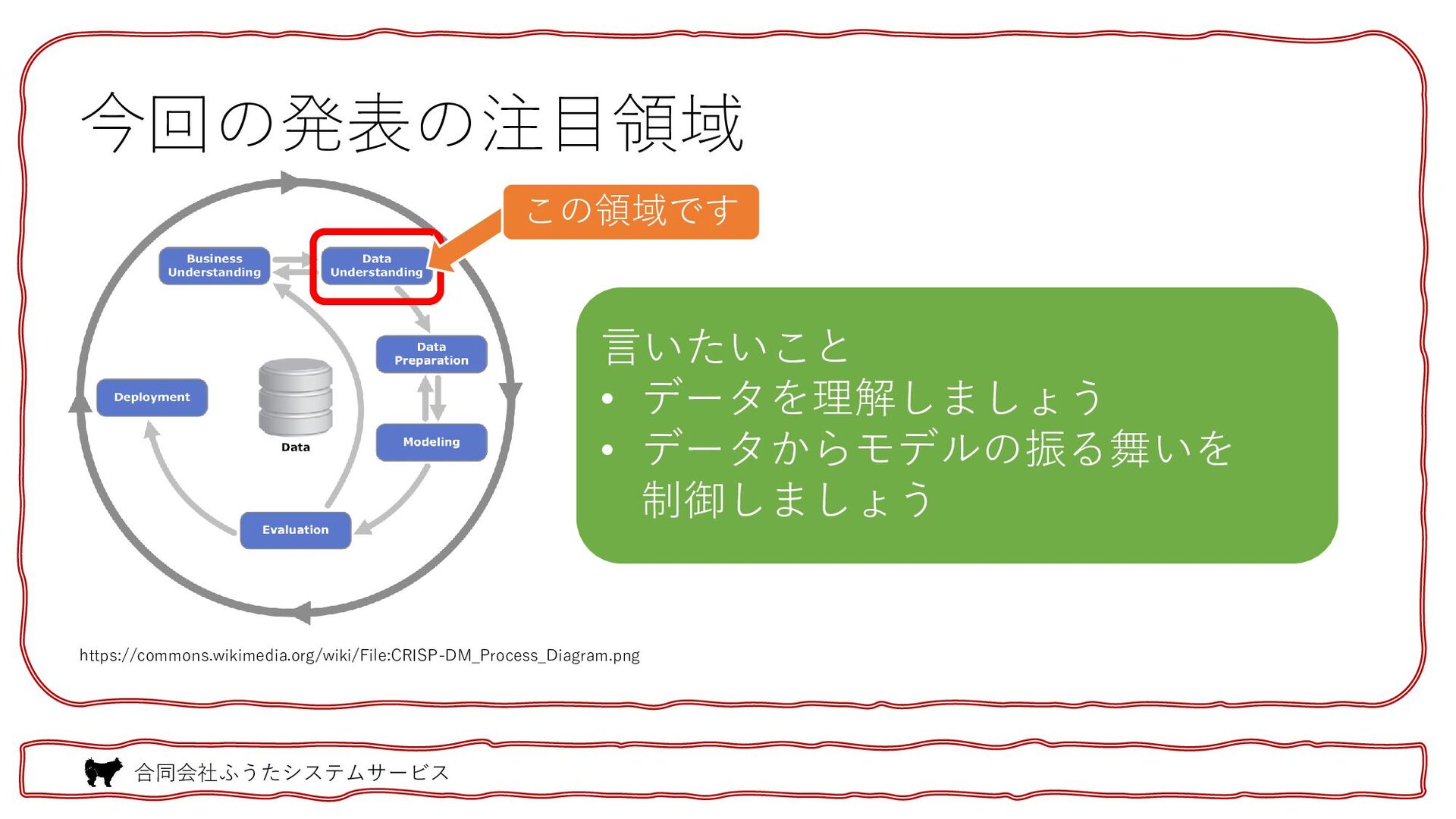
2023.06.01 に開催された Data-Centric AI勉強会のライトニングトークにて使用した資料。データに着目することでモデルの品質を向上させる手法の考え方とその応用例の簡単な紹介。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}