A personal walkthrough on understanding and demystifying GraphQL and its actual purposes for web applications. This presentation touches on both the server0-side of GraphQL but also on the client-side via Apollo.
GraphQL is: ◦ Single endpoint to process all requests: host:port/graphql ◦ All requests are sent via POST ◦ Queries define what can be queried (READ) ◦ Mutations define how to do modify data (CREATE/UPDATE/DELETE) ◦ Schemas defines the data models and attributes ◦ GraphQL has its own GUI tool called GraphiQL ◦ Each component can requests only the data it required
community-driven GraphQL client library (vs Facebook Relay) • Works with React, Vue, Ember and Angular • Provides Apollo-Client and Apollo-Provider • Browser and SSR ready • Main jobs are to: ◦ Sends all requests to host:port/graphql ◦ Parse responses according GraphQL Object Types ◦ Populate the data store ⇒ The GraphQL API server requires another lib e.g. gem graphql (ruby), apollo-server or express-graphql (node.js)
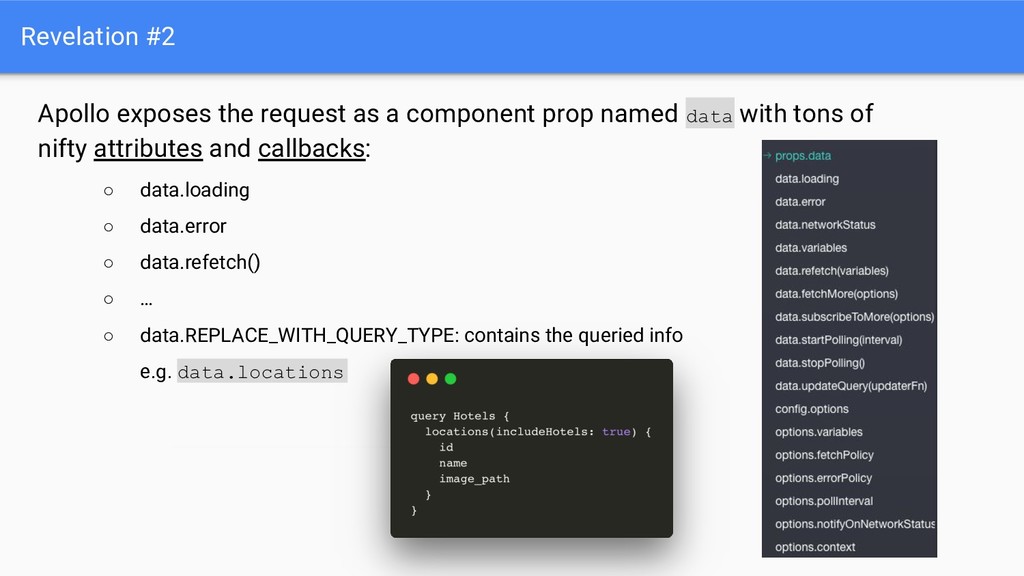
named data with tons of nifty attributes and callbacks: ◦ data.loading ◦ data.error ◦ data.refetch() ◦ … ◦ data.REPLACE_WITH_QUERY_TYPE: contains the queried info e.g. data.locations
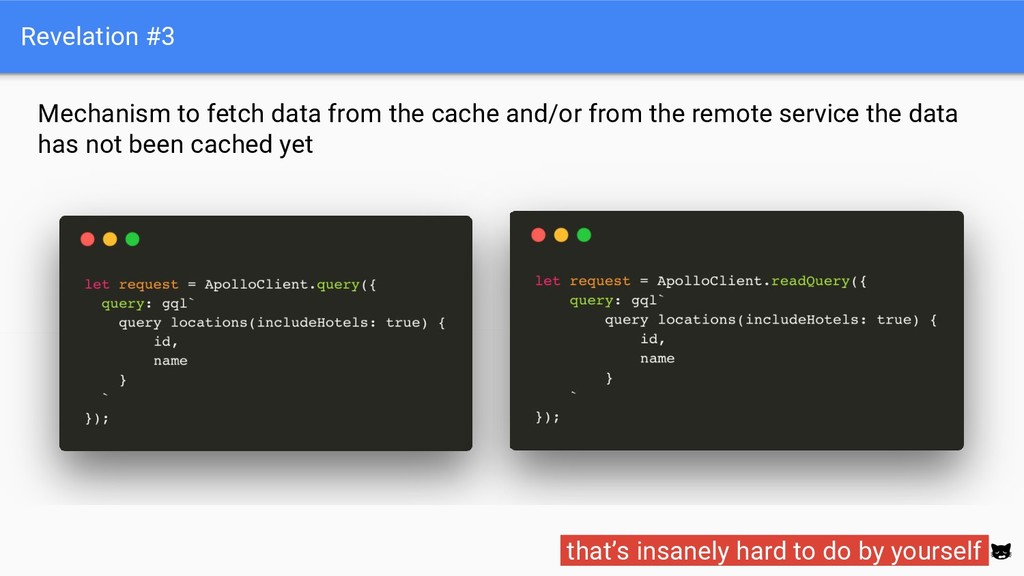
normalize all data fetched “(...)splitting the result into individual objects, creating a unique identifier for each object (using id and type), and storing those objects in a flattened data structure” ⇒ Similar libraries to ember-data that’s hard but doable by yourself
Apollo: ◦ Centralized error handling ◦ Automated splitting of large queries into multiple smaller async requests ◦ … ⇒ Check Apollo for React • Pros: ◦ Development productivity gain ◦ Solves data fetching/updates for the view layer ◦ Setup is straightforward with Apollo with a rather small footprint • BUT some concerns: ◦ Loss of visibility and control as everything happens “auto-magically” ◦ Beware not to place business logic into the view layer/components
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Contact Nimbl3 [email protected] 399 Sukhumvit Road, Interchange 21 Klongtoey](https://files.speakerdeck.com/presentations/f1d13092037f45208d8e814767adc215/slide_14.jpg){kind=link}