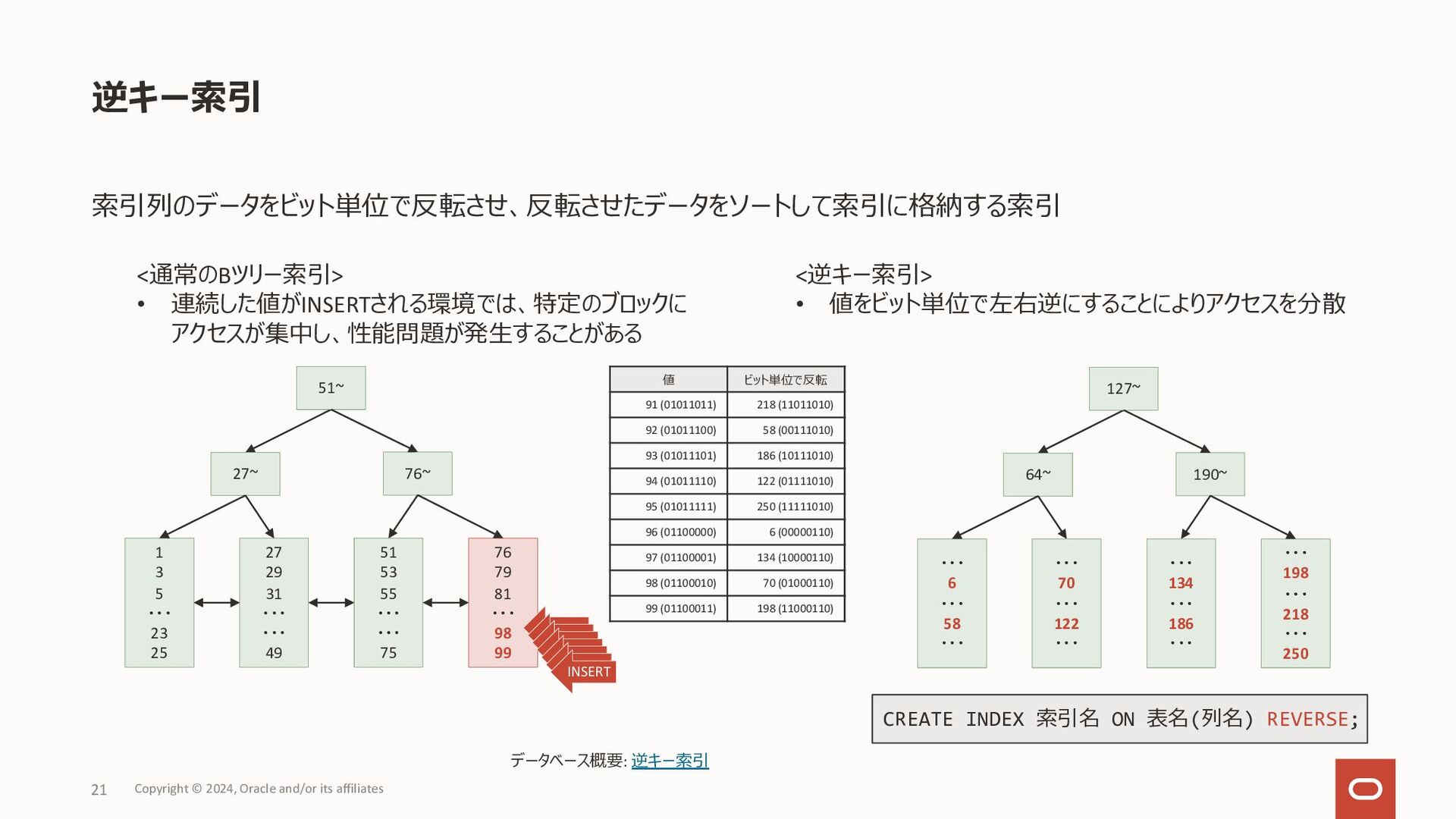
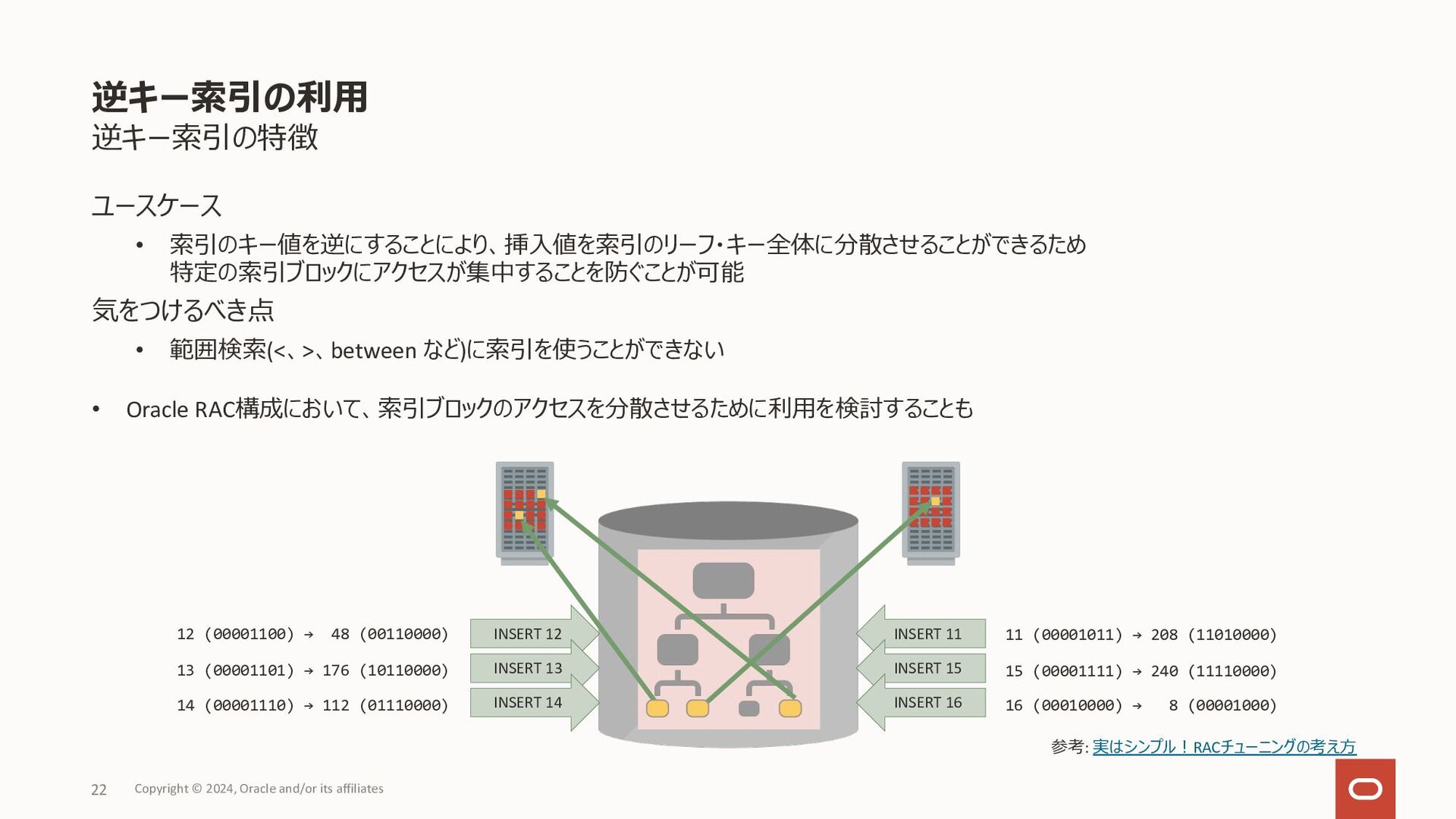
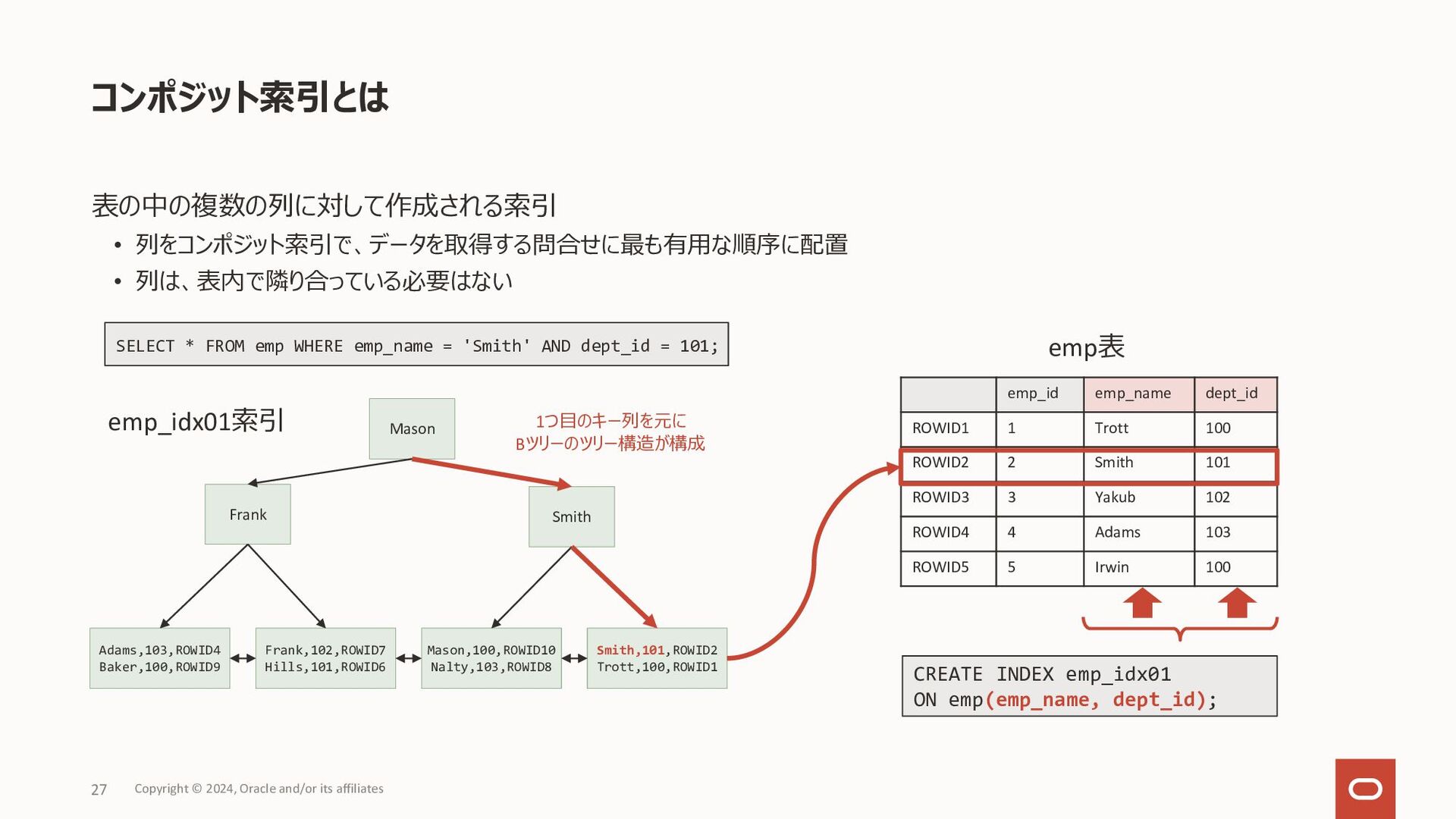
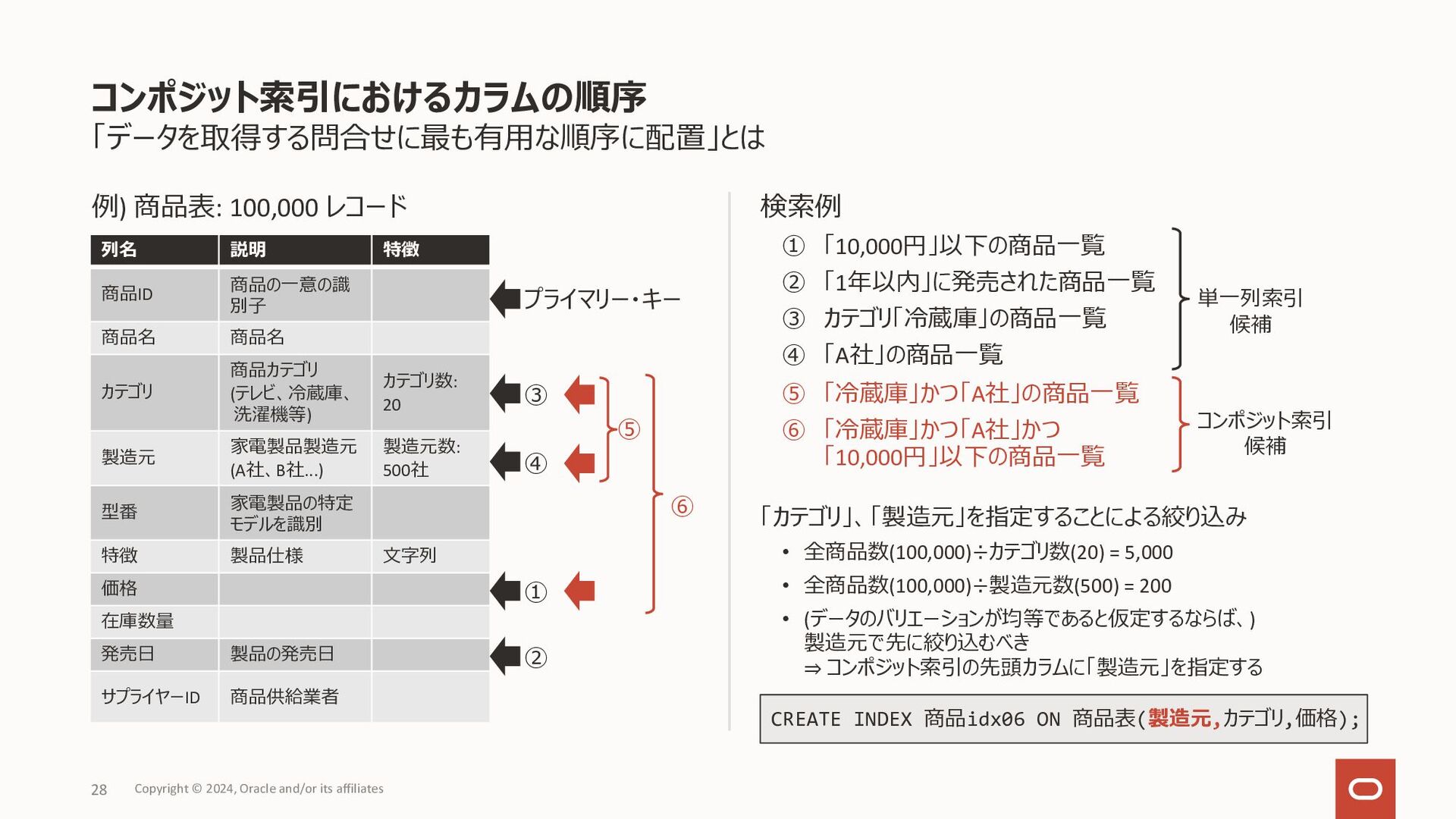
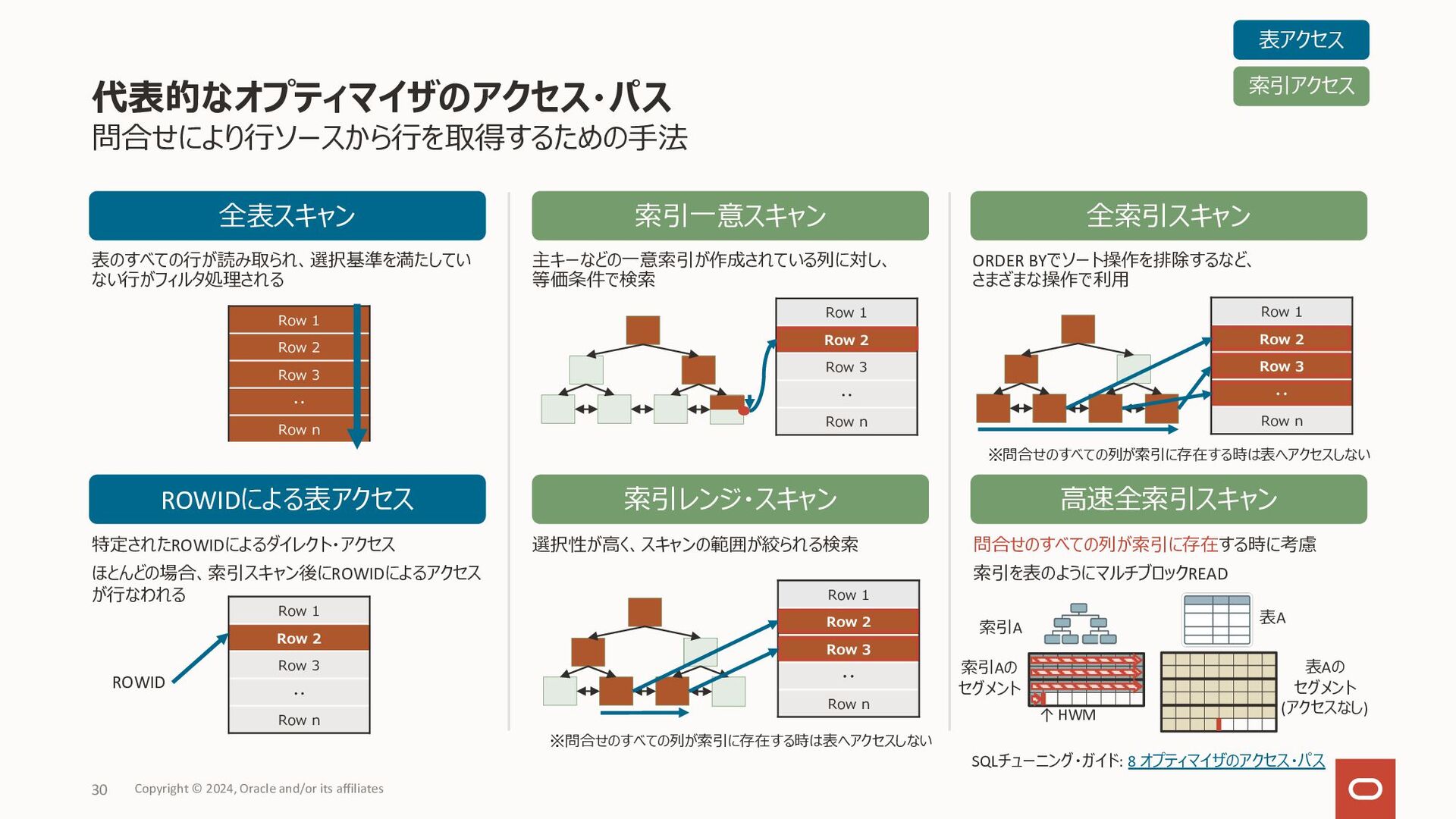
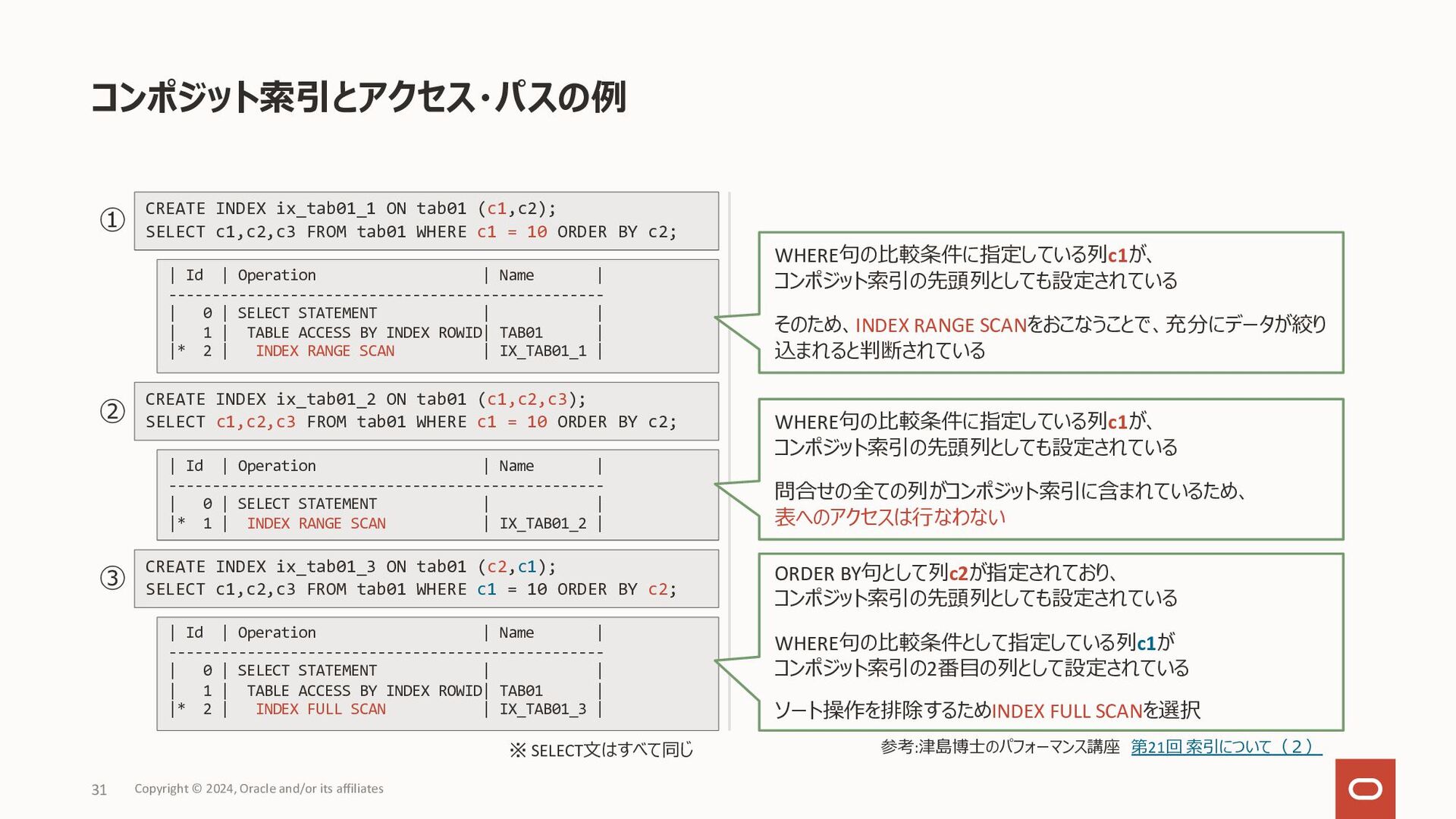
数値データ: 最⼩の数から最⼤の数へ • ⽇付データ: 古い値から新しい値へ • DESCキーワードを指定することで上記デフォルトの逆順に索 引データを格納 降順索引の作成例 ユースケース • order by句の指定に昇順(ASC)、降順(DESC)指定が 混在している場合に、コンポジット索引を活⽤することで ソート処理を減らしたい • デフォルトの昇順索引においても、Bツリー 索引のリーフ・ブロックは双⽅向のリンクを 持っているため、ソート対象となる全ての 列が降順指定ならば、そのまま降順ソート で利⽤ 降順索引 Copyright © 2024, Oracle and/or its affiliates 20 CREATE INDEX sales_idx ON sales(sale_date ASC, product_id DESC); SELECT sale_date, product_id, quantity FROM sales WHERE sales_date > TO_DATE('20240101','YYYYMMDD') ORDER BY sales_date DESC, product_id DESC; 2024/01/01, 15, rowid 2024/01/01, 21, rowid 2024/01/01, 33, rowid 2024/01/02, 16, rowid 2024/01/02, 21, rowid SELECT sale_date, product_id, quantity FROM sales WHERE sales_date > TO_DATE('20240101','YYYYMMDD') ORDER BY sales_date ASC, product_id DESC; 2024/01/01, 33, rowid 2024/01/01, 21, rowid 2024/01/01, 15, rowid 2024/01/02, 21, rowid 2024/01/02, 16, rowid • 問合せのソート指定に含まれる列の昇順、降順が混在していると、 デフォルトの索引では条件絞り込みのみで使⽤され、別途ソート処 理が必要となる • 左の降順索引の作成例の索引があれば、索引をソート処理で使⽤ リーフ・ブロック (デフォルト)のイメージ リーフ・ブロック (⼀部降順)のイメージ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
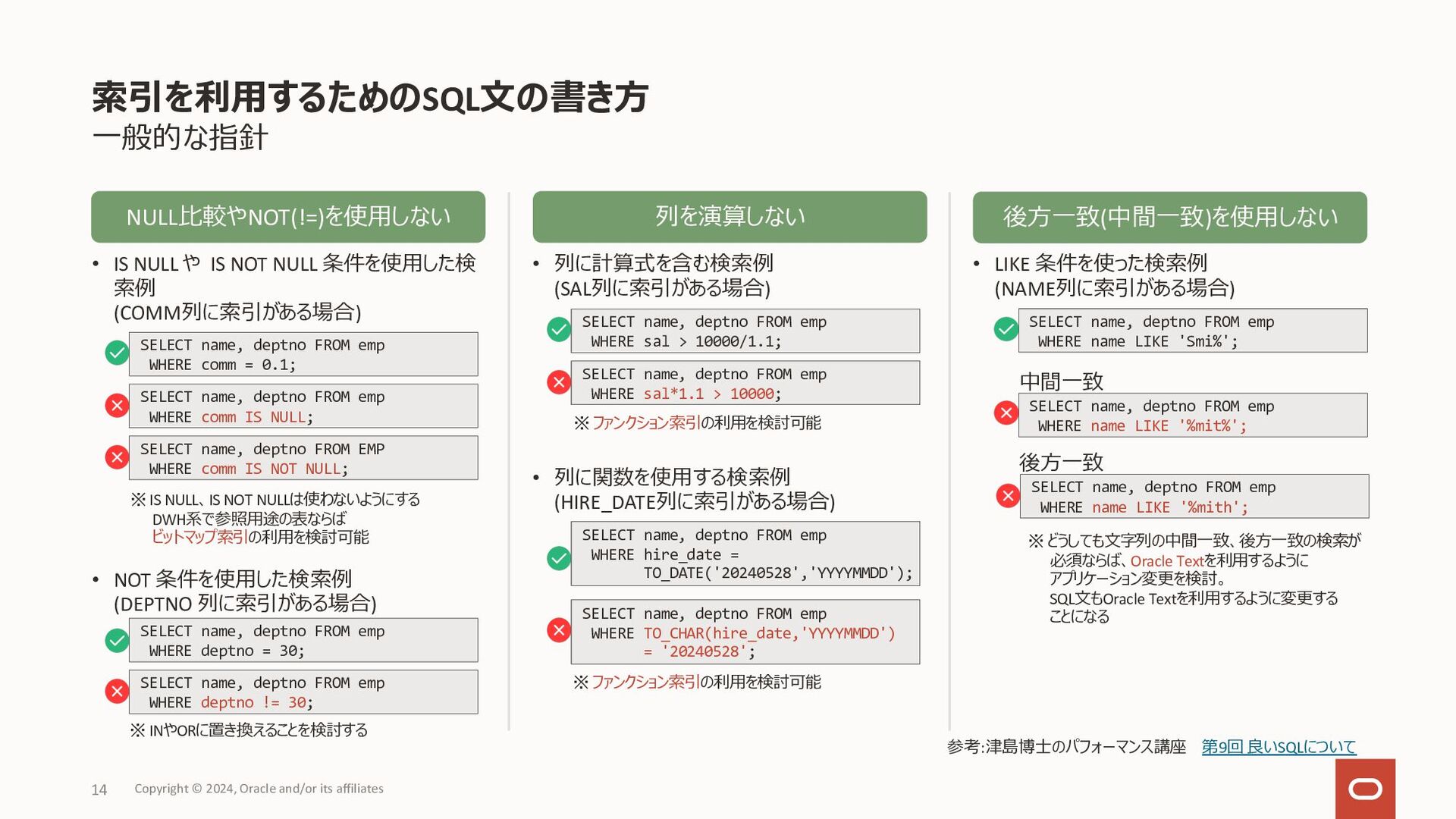{kind=link}
{kind=link}
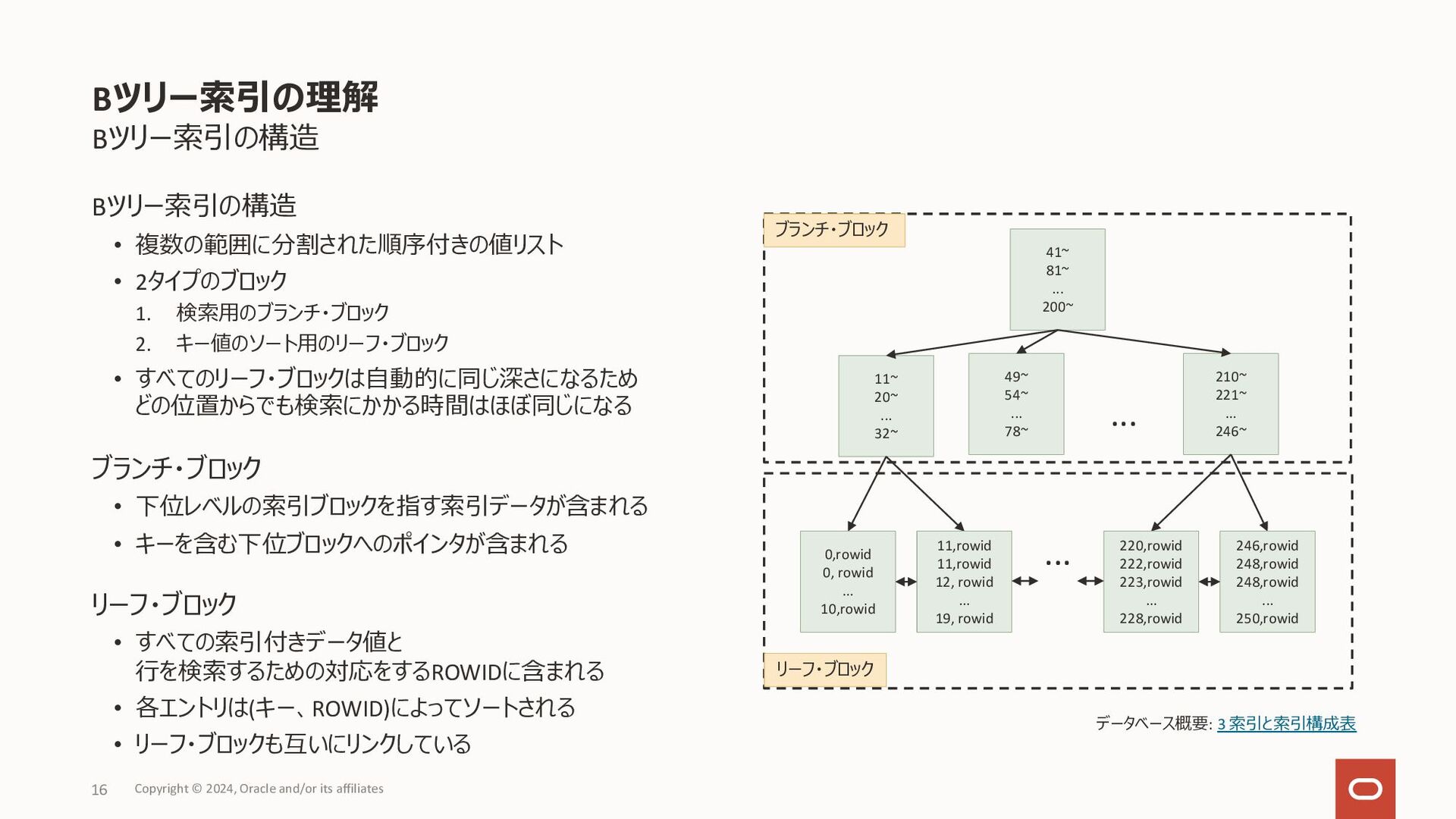{kind=link}
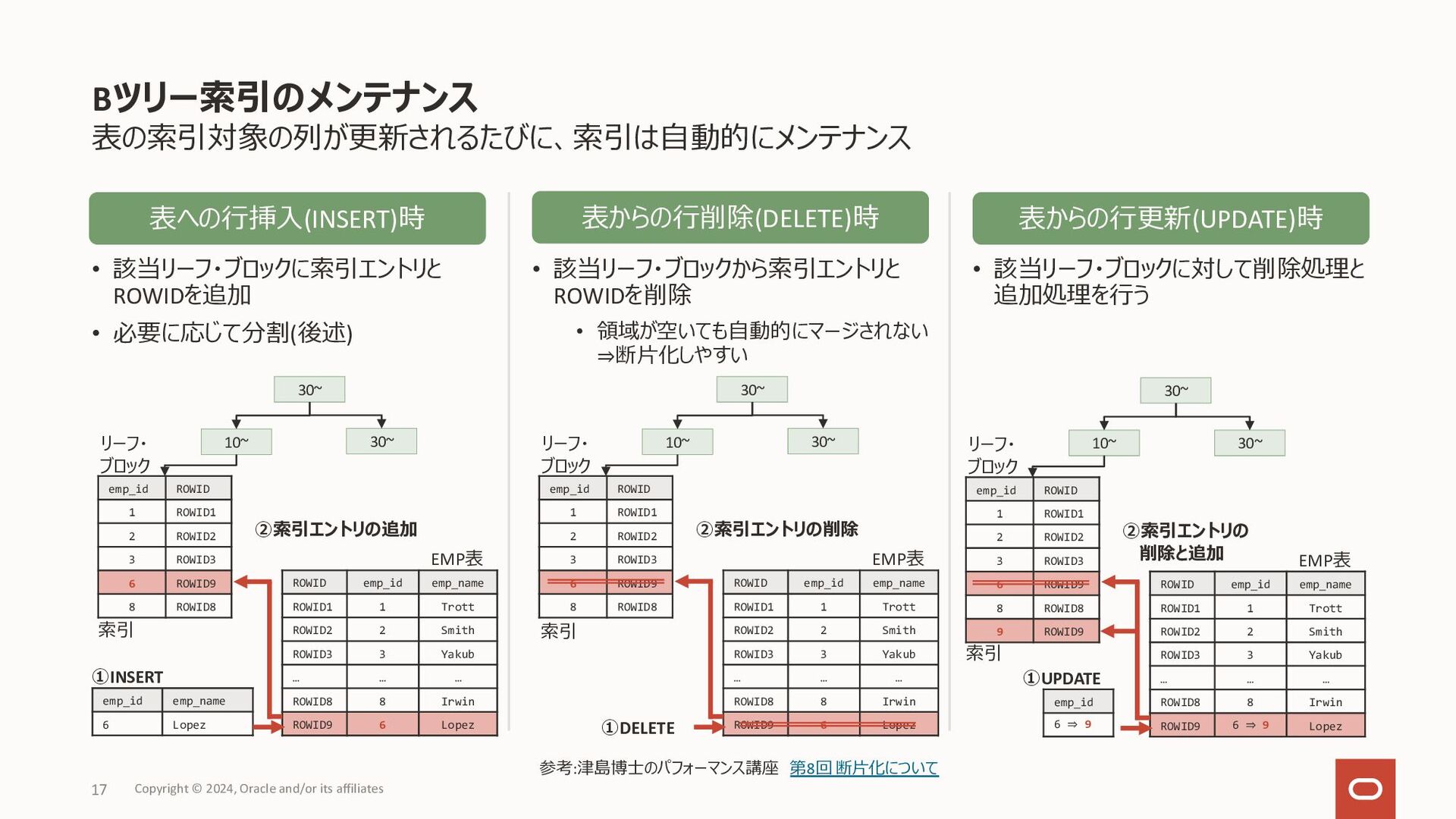{kind=link}
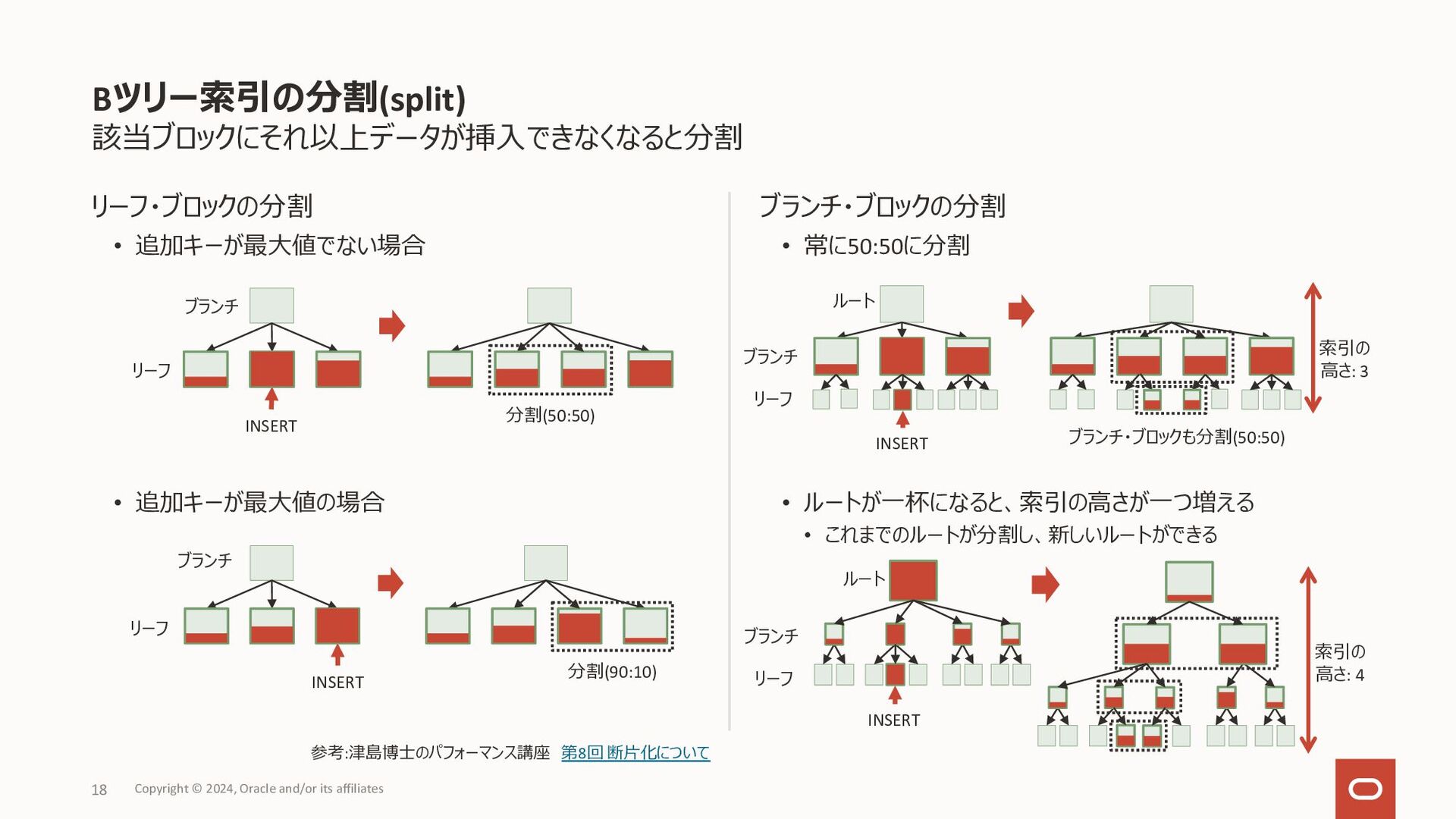{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}