listener za neki path • Konfiguracija nudi odabir tipa listenera (child/value/sync_path) te načina obrade primljenih podataka • Default implementacija sprema podatke u C* ◦ Nadogradnje default implementacije ▪ Kafka sink ▪ ElasticSearch indeksiranje ▪ Postavljanje drugog procesora na child node ▪ Custom procesori • Jednostavno je implementirati svoje obrade primljenih podataka, ali je ideja da se Fsync odnosi agnostički prema podacima. Same obrade se odrađuju u narednim mikroservisima ili u data flow-u [ { "syncPath":"/v0/data/meditation/completedExercises/:us erId", "listenerType":"CHILD", "lazyDataSpel":null, "processorType":"SPRING_BEAN", "processorName":"fSyncProcessServiceMeditation", "childSyncProcessorName":null }, { "syncPath":"/v0/data/leaf/sync/:userId", "listenerType":"SYNC_PATH", "lazyDataSpel":"data['rawDataReference']", "processorType":"SPRING_BEAN", “targets”:[“leaf-api”,”step-agg”], "processorName":"fSyncProcessServiceChildListenerRegis trator", "childSyncProcessorName":"fSyncProcessServiceKafka" } ]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
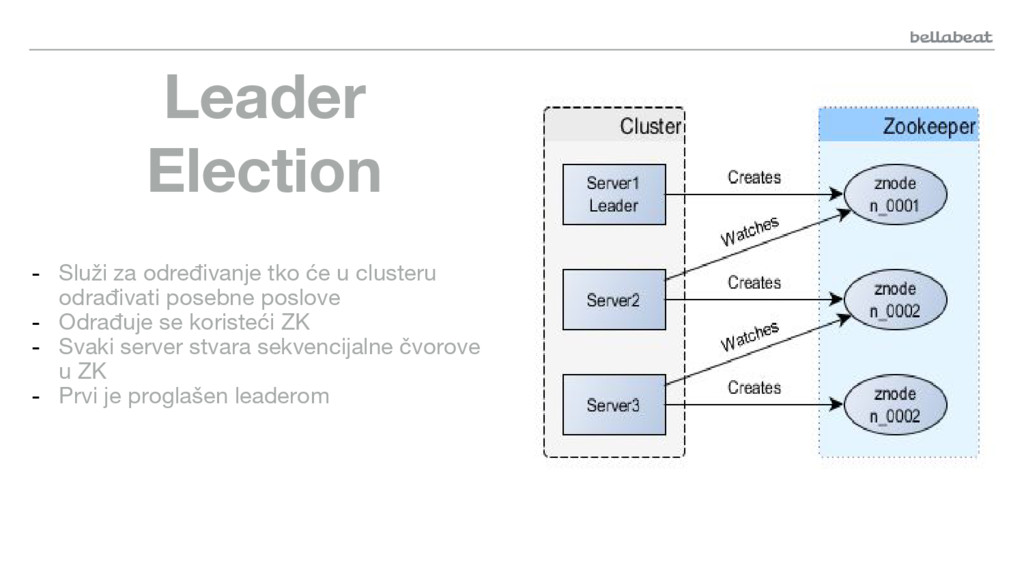{kind=link}
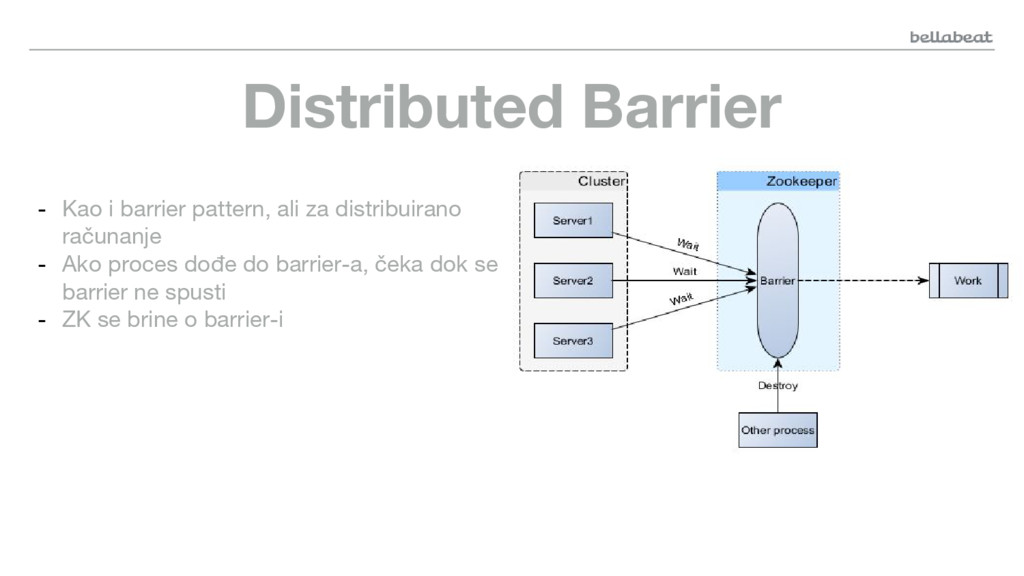{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
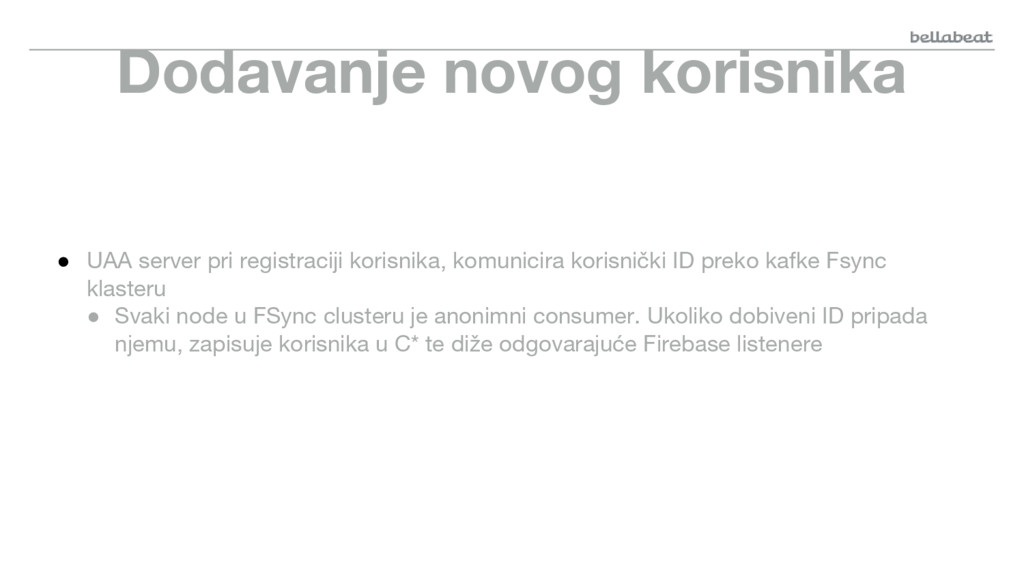{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
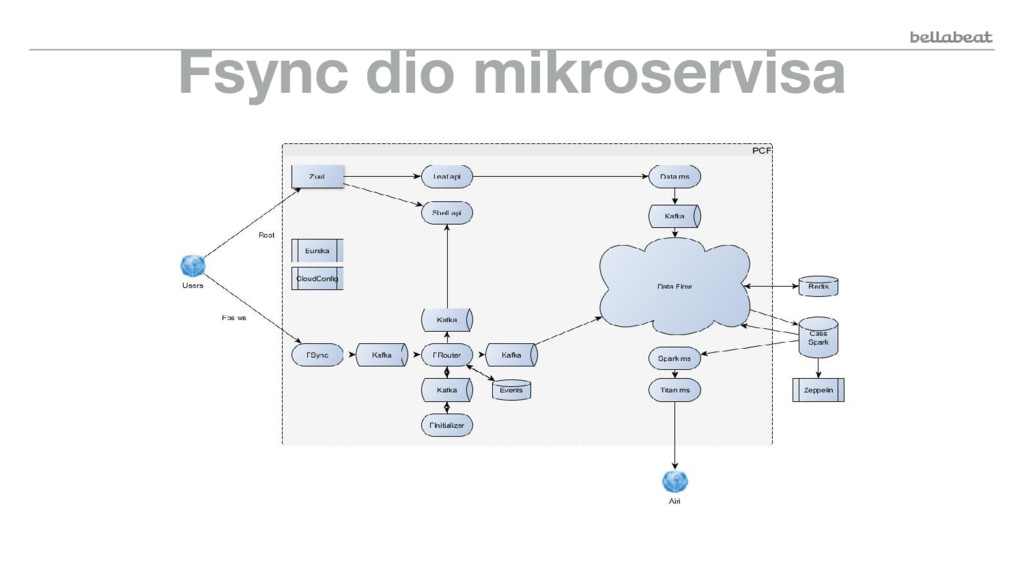{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}