PWL Mini
Matt Adereth on "The Mode Tree: A Tool for Visualization of Nonparametric Density Features"(http://adereth.github.io/oneoff/Mode%20Trees.pdf). From Matt: "We often look at summaries of univariate data using basic descriptive statistics like mean and standard deviation and visualizations like histograms and box plots. The Mode Tree is a powerful alternative visualization that reveals important details about our distributions that none of the standard approaches can show.
I particularly like this paper because it was really the by-product of some interesting algorithmic work in Computational Statistics. A lot of the techniques in this area are pretty math heavy and inaccessible, so I appreciated that they dedicated a paper to making a visualization that helps explain the inner workings. As a bonus, the visualization stands on its own as a useful tool."
Slides for Matt's talk are available here: http://adereth.github.io/oneoff/pwl-draft/scratch.html
Matt's Bio
Matt Adereth (@adereth) builds tools and infrastructure for quantitative analysis at Two Sigma. He previously worked at Microsoft on Visio, focusing on ways to connect data to shapes.
Main Talk
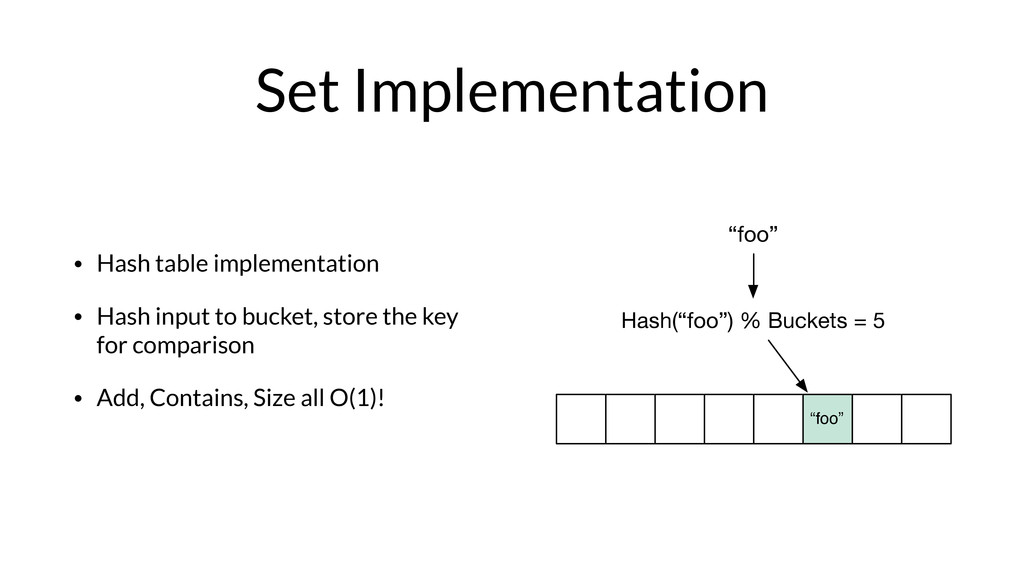
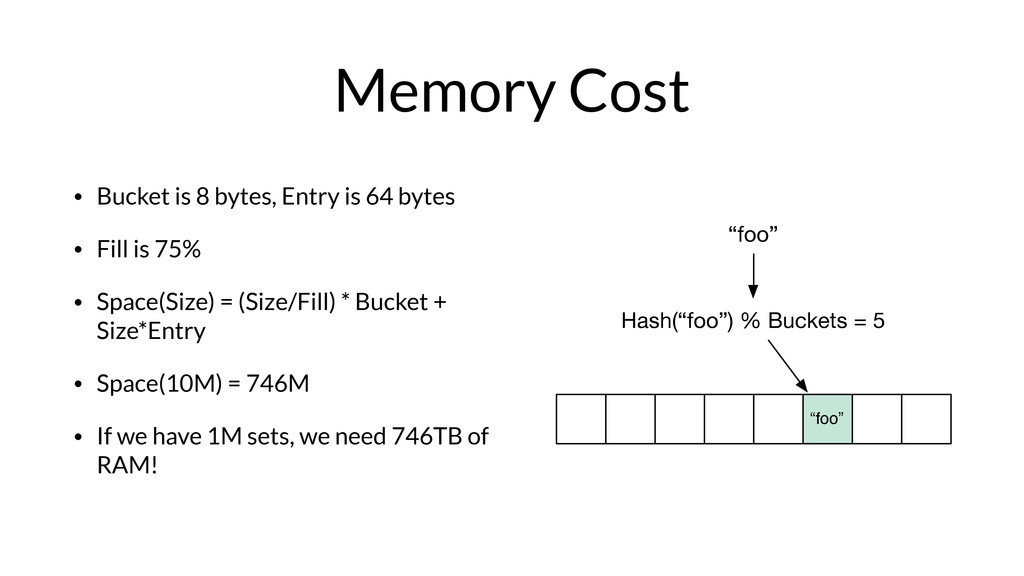
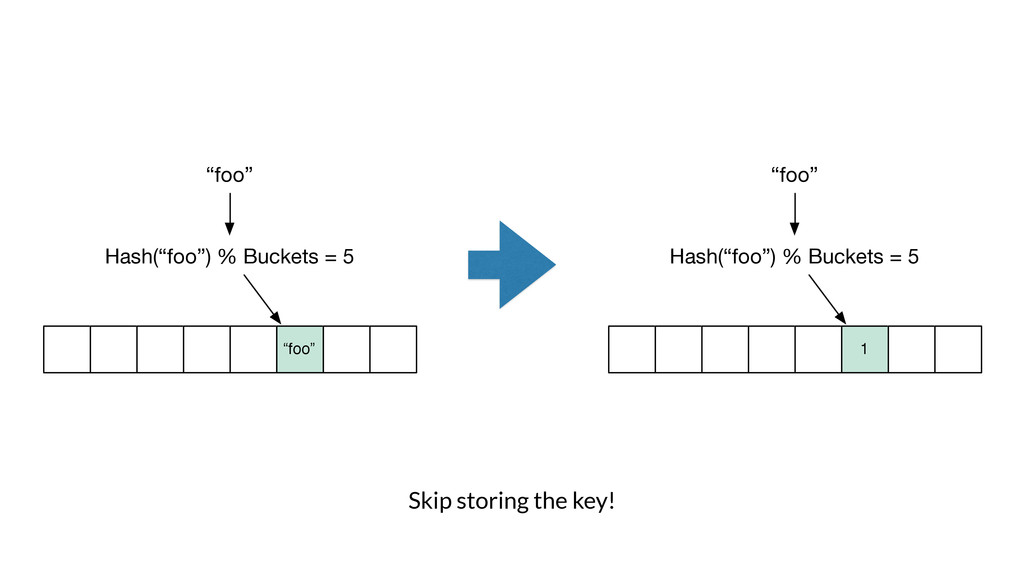
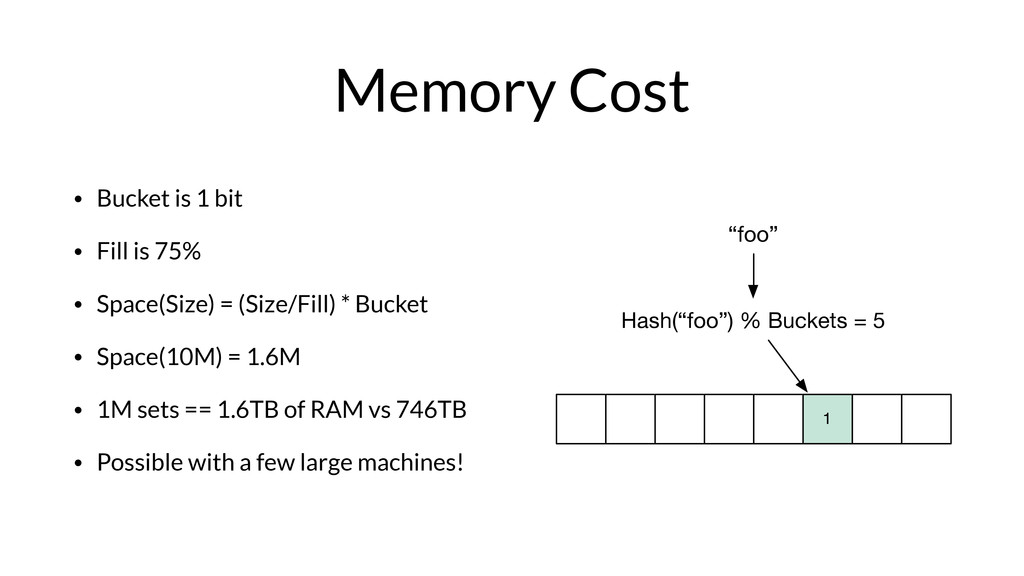
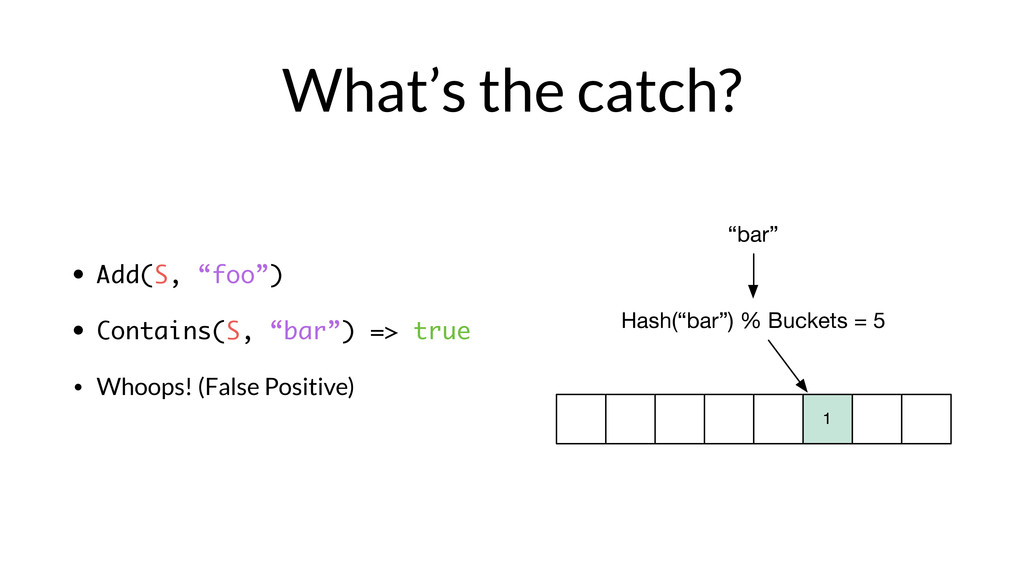
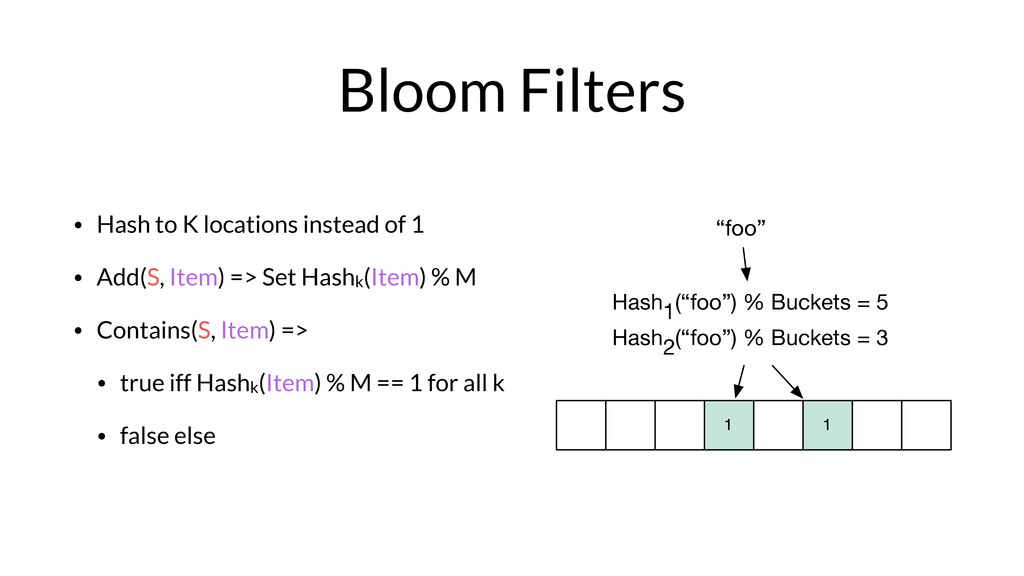
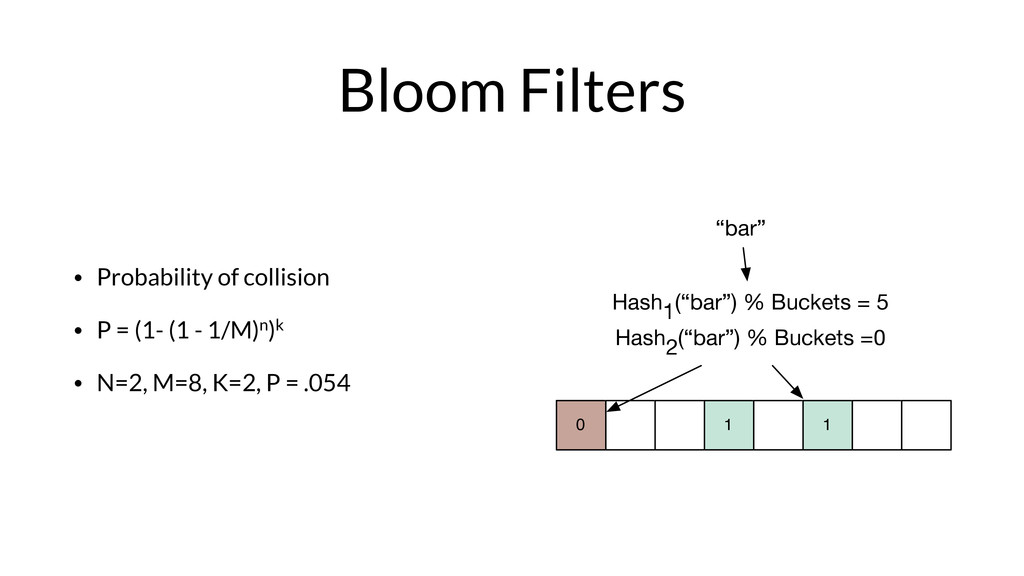
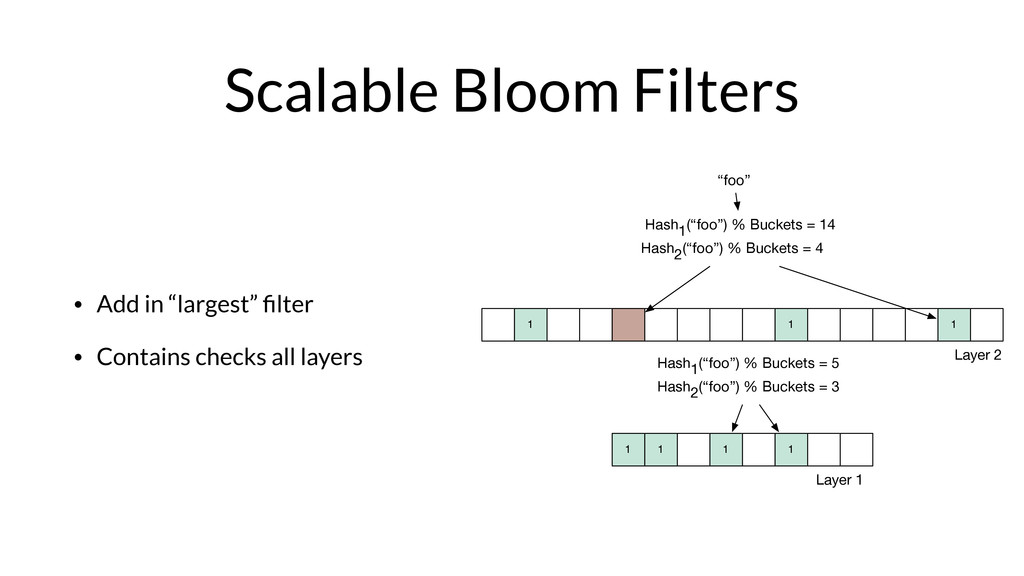
Armon Dadgar from HashiCorp takes us on a deep dive of Bloom filters and HyperLogLog.
Bloom filter papers:
* http://www.cs.upc.edu/~diaz/p422-bloom.pdf
* http://gsd.di.uminho.pt/members/cbm/ps/dbloom.pdf
* http://www.eecs.harvard.edu/%7Ekirsch/pubs/bbbf/esa06.pdf
Armon will mostly touch on the first paper which is the introduction of the technique. The other two are optimizations that he'll discuss briefly but there's no need to dwell on them.
HyperLogLog papers:
* http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.142.9475
* http://research.google.com/pubs/pub40671.html
Again, the first one introduces them, and the second one is some optimizations from Google. He won’t spend much time on the second one either. All of these papers are implemented as part of:
https://github.com/armon/bloomd
https://github.com/armon/hlld
These links may give some context to the work and show the real-world applicability.
From Armon on why he loves these papers: "Bloom Filters and HyperLogLog are incredible for their simplicity and the seemingly impossible behavior they have. Both of them are part of the family of “sketching” data structures, which allow for a controllable error that results in a tremendous savings of memory compared to the equivalent exact implementations.
More than just being elegant, these two data structures enable some very cool real-world use cases. In the online advertising company I previously worked for, we used them to track thousands of metrics across billions of data points comfortably in memory on a single machine. "
Armon's Bio
Armon (@armon) has a passion for distributed systems and their application to real world problems. He is currently the CTO of HashiCorp, where he brings distributed systems into the world of DevOps tooling. He has worked on Terraform, Consul, and Serf at HashiCorp, and maintains the Statsite and Bloomd OSS projects as well.
Video for both talks is available here > http://youtu.be/T3Bt9Tn6P5c
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}