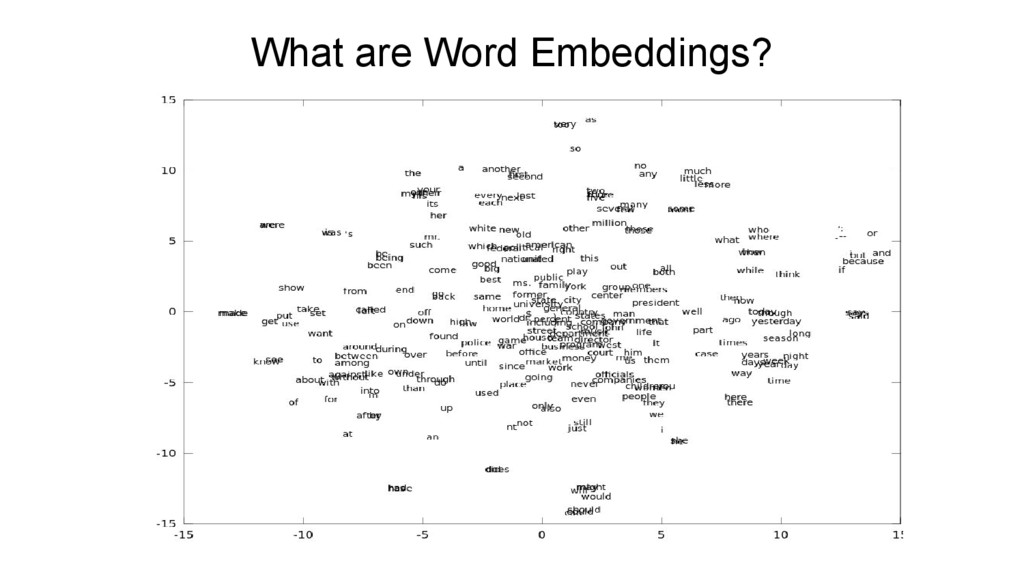
an end in itself (for computing similarities between terms), and as a representational basis for downstream NLP tasks like text classification, document clustering, part of speech tagging, named entity recognition, sentiment analysis, and so on.
a difficult task to choose one. Should you simply go with the ones widely used in NLP community such as Word2Vec, or is it possible that some other model could be more accurate for your use case? I will talk about some evaluation metrics which could help you to some extent in deciding a most favorable embedding model to use. Aim of this talk
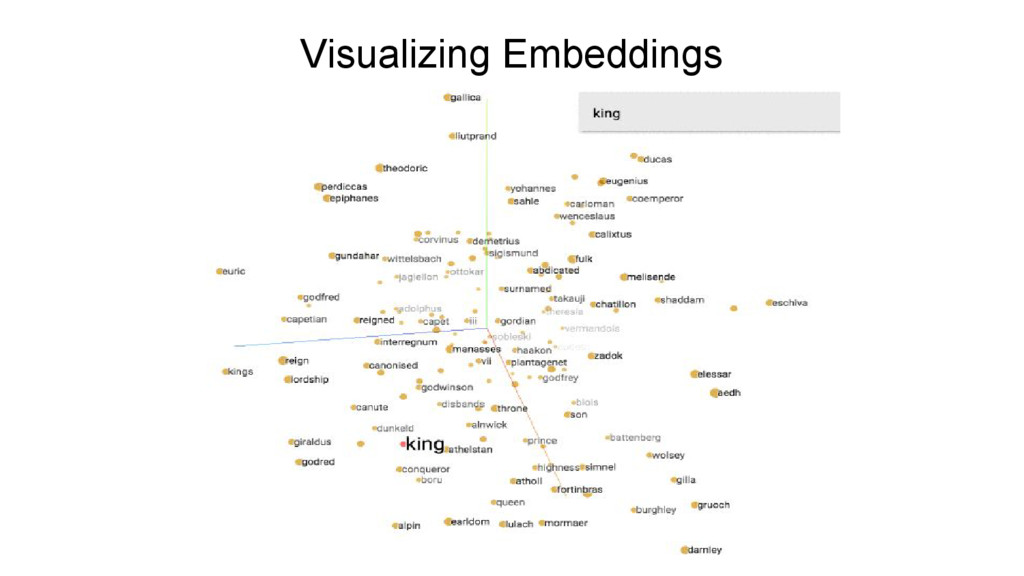
Word2Vec FastText The three results above shows how differently these embeddings think for the words to be most similar to ‘king’. The WordRank results are more inclined towards the attributes for ‘king’ or we can say the words which would co-occur the most with it, whereas Word2Vec results in words(names of few kings) that could be said to share similar contexts with each other.
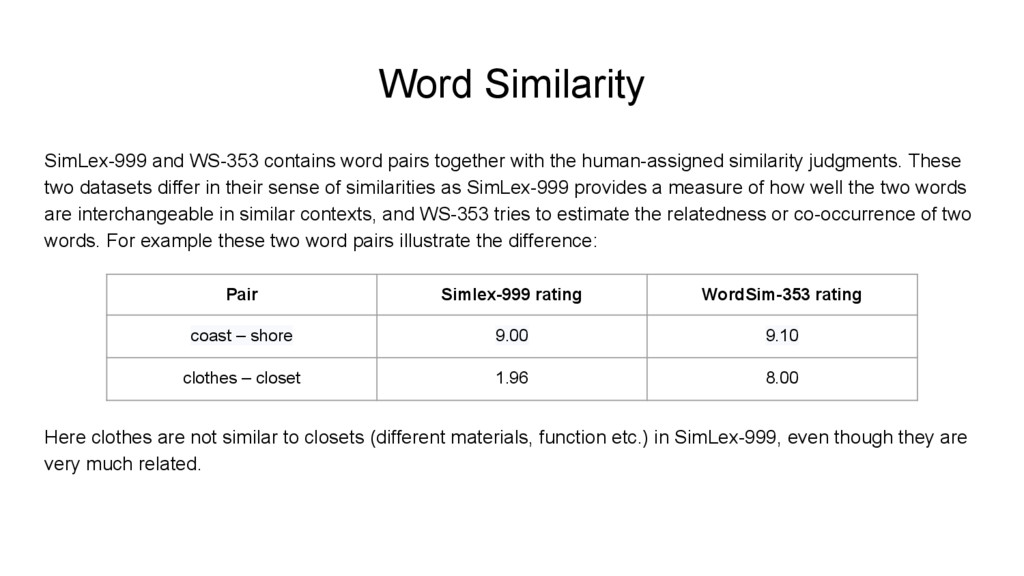
the human-assigned similarity judgments. These two datasets differ in their sense of similarities as SimLex-999 provides a measure of how well the two words are interchangeable in similar contexts, and WS-353 tries to estimate the relatedness or co-occurrence of two words. For example these two word pairs illustrate the difference: Here clothes are not similar to closets (different materials, function etc.) in SimLex-999, even though they are very much related. Pair Simlex-999 rating WordSim-353 rating coast – shore 9.00 9.10 clothes – closet 1.96 8.00
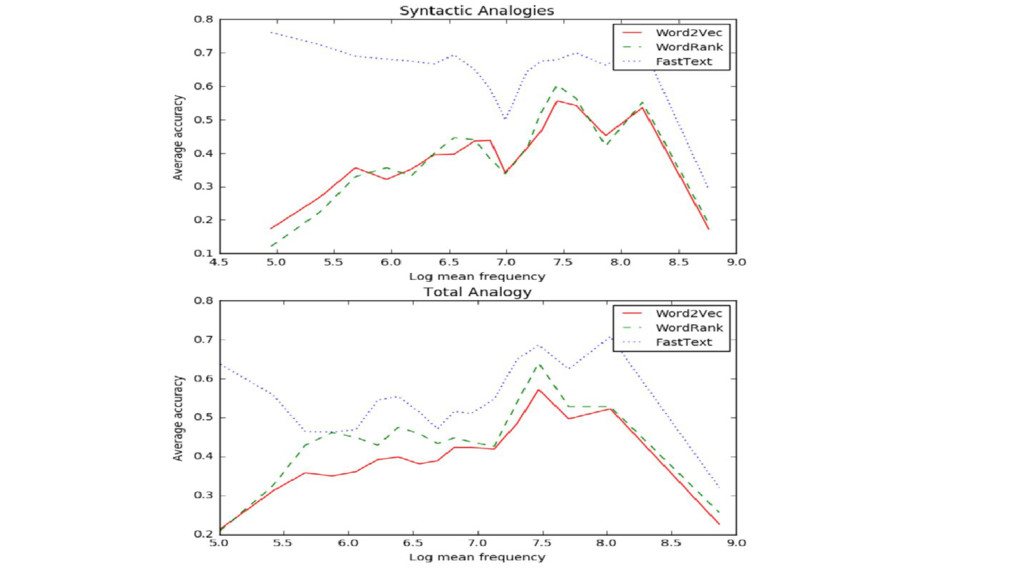
questions, partitioned into semantic and syntactic questions. The semantic questions contain five types of semantic analogies, such as capital cities(Paris:France;Tokyo:?) or family (brother:sister;dad:?). The syntactic questions contain nine types of analogies, such as plural nouns (dog:dogs;cat:?) or comparatives (bad:worse;good:?) Results: https://rare-technologies.com/wordrank-embedding-crowned-is-most-similar-to-king-not-word2vecs-canute/
dimensions for effective visualization. We basically end up with a new 2d or 3d embedding which tries to preserve information from the original multi-dimensional one. 1. Principal Component Analysis (PCA) which tries to preserve the global structure in the data, and due to this local similarities of data points may suffer in few cases. 2. t-SNE, which tries to reduce the pairwise similarity error of data points in the new space. That is, instead of focusing only on the global error as in PCA, t-SNE try to minimize the similarity error for every single pair of data points.
for interactive visualization and analysis of high-dimensional data like embeddings. It reads from the TSV files where you save your word embeddings of original dimension. http://projector.tensorflow.org/
Wordrank_comparisons.ipynb 3. Word2Vec semantic/syntactic similarity using different window size: https://gist.github.com/tmylk/14f887f8585e9f89ab5896a10308447c
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}