Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
exists?で起きるN+1問題にSetで対処する
Search
patorash
July 21, 2021
Technology
850
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
exists?で起きるN+1問題にSetで対処する
Ruby on Railsでよく発生するN+1問題の解決方法として、exists?の場合は標準ライブラリのSetを使うといいかもしれない、という話です。
patorash
July 21, 2021
More Decks by patorash
See All by patorash
中間管理職はそこそこ楽しい
patorash
0
45
情報共有戦略と戦術
patorash
1
1.3k
DBのメタデータを管理する文化を作る
patorash
0
700
Stimulusのススメ
patorash
0
95
ActiveRecordの速度改善Tips2020冬
patorash
0
93
わかった気になる!OpenID Connect
patorash
2
2.2k
Indexの種類
patorash
1
830
Start-SQLの紹介
patorash
0
780
RailsアプリにGraphQLを導入してみた話
patorash
1
700
Other Decks in Technology
See All in Technology
reFACToring
moznion
0
150
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
160
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
140
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
770
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
510
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
310
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
110
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
3
390
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
320
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
600
生成 AI 時代にいま一度「問い合わせ」について考えてみる
kazzpapa3
1
130
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.5k
Featured
See All Featured
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.7k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Automating Front-end Workflow
addyosmani
1370
210k
Git: the NoSQL Database
bkeepers
PRO
432
67k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
It's Worth the Effort
3n
188
29k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
A designer walks into a library…
pauljervisheath
211
24k
Visualization
eitanlees
152
17k
Transcript
exists?で起きるN+1問 題にSetで対処する 2021-07-21 株式会社リゾーム 社内勉強会 @patorash
稀によくあるコード # CSVファイルの行数だけUser.exists?が実行されるやーつ csv.foreach do |row| name = row['名前'] age
= row['年齢'] hobby = row['趣味'] # User.find_or_create_by!とか言わないで… unless User.exists?(name: name, age: age, hobby: hobby) User.create!(name: name, age: age, hobby: hobby) end end
何が問題か? • CSVファイルの⾏数だけexists?が実⾏される • exists?の1回の実⾏時間が仮に1msだったとしても、CSVが1,000⾏あれば1秒か かる。1万⾏あれば10秒、10万⾏あれば100秒…と増えていく • usersテーブルにデータがたくさんあると、exists?の時間は更にかかる • 1msではなく5msなら?
• 1,000⾏なら5秒、1万⾏なら50秒、10万⾏なら500秒
どうしてこんなことに… • 重複データを検知したいから
どうすれば… • とはいえ、重複しているかどうかは DBに問い合わせしなければわからな いじゃないか! • N回のクエリが発⽣するのも⽌むを 得ない!
そう考えていた頃が私にもありました
標準ライブラリSetを使え! • Setは、数学の集合を扱うクラス • 集合とは、重複のないオブジェクトの集まりです。Arrayの持つ演算機能とHash の⾼速な検索機能を合わせ持ちます。 Setは内部記憶としてHashを使うため、集合要素の等価性はObject.eql?と Object#hashを⽤いて判断されます。したがって、集合の各要素には、これらの メソッドが適切に定義されている必要があります。 集合の順序は保証されません。
(Ruby リファレンスマニュアルより)
どういうこと? • Setを使うと、配列の要素毎にhash関数が呼ばれて、それがkeyに設定された Hashを持つことになる。(内部的に) # これはつまり… set = Set.new(["a", "b"])
# 内部としてはこういう感じになっている hash = ["a", "b"].each_with_object({}) {|v, o| o[v.hash] = v } # => {690777552598146486=>"a", -2489798041940868951=>"b"} # これはつまり… set.include?("a") # => true # こういうこと。総当りせず、hash値がキーとヒットするかを調べるので速い hash.keys.include?("a".hash) # => true
つまり… • usersテーブルの内容を全て持ってきてSetに⼊れてしまえばN回発⾏される クエリは必要ない!(富豪的発想) • なぜ富豪的? • メモリにusersテーブルの全データを載せるから
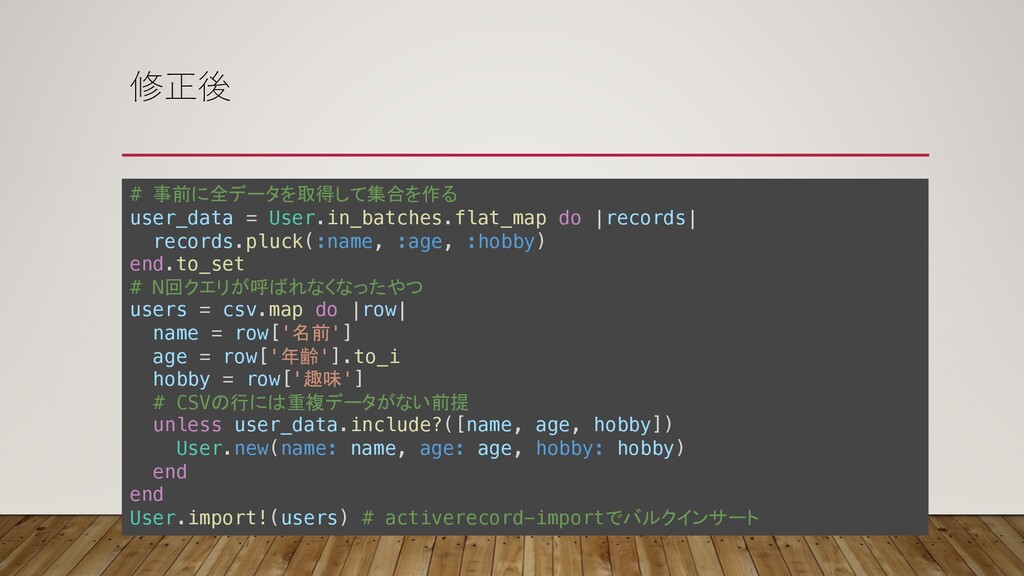
修正後 # 事前に全データを取得して集合を作る user_data = User.in_batches.flat_map do |records| records.pluck(:name, :age,
:hobby) end.to_set # N回クエリが呼ばれなくなったやつ users = csv.map do |row| name = row['名前'] age = row['年齢'].to_i hobby = row['趣味'] # CSVの行には重複データがない前提 unless user_data.include?([name, age, hobby]) User.new(name: name, age: age, hobby: hobby) end end User.import!(users) # activerecord-importでバルクインサート
推測するな、計測せよ • ⽐較対象 • exists?(1万回クエリ呼ぶ) • Array#include?(全データをロードして線形探索。つまり、O(n)) • Set#include?(全データをロードしてハッシュ探索。つまり、O(1)) •
事前準備 • rails newしてsqlite3でusersテーブルに1万件登録 • 名前1..名前10000というデータ • 1万件の配列のデータで⽐較させる • 名前10001..名前20000というデータ。exists?やinclude?は必ずfalseとなる。
推測するな、計測せよ(結果) bin/rails runner script/benchmark.rb Warming up -------------------------------------- exists? 1.000 i/100ms
Array#include? 1.000 i/100ms Set#include? 1.000 i/100ms Calculating ------------------------------------- exists? 0.085 (± 0.0%) i/s - 1.000 in 11.734614s Array#include? 0.059 (± 0.0%) i/s - 1.000 in 17.012424s Set#include? 8.503 (± 0.0%) i/s - 43.000 in 5.064850s Comparison: Set#include?: 8.5 i/s exists?: 0.1 i/s - 99.78x (± 0.00) slower Array#include?: 0.1 i/s - 144.66x (± 0.00) slower
推測するな、計測せよ 1. Set#include?(全データをロードしてハッシュ探索) 2. exists?(1万回クエリ呼ぶ) ・・・100倍遅い 3. Array#include?(全データをロードして線形探索) ・・・145倍遅い
ご清聴ありがとうございました
{kind=link}
![稀によくあるコード # CSVファイルの行数だけUser.exists?が実行されるやーつ csv.foreach do |row| name = row['名前'] age](https://files.speakerdeck.com/presentations/6bd2f9199770492ca8c187d7c842d773/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![どういうこと? • Setを使うと、配列の要素毎にhash関数が呼ばれて、それがkeyに設定された Hashを持つことになる。(内部的に) # これはつまり… set = Set.new(["a", "b"])](https://files.speakerdeck.com/presentations/6bd2f9199770492ca8c187d7c842d773/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}