EventQL architecture. Documentation: https://eventql.io/ Github: https://github.com/eventql/eventql 2017-02-21 Tel Aviv-Yafo; Paul Asmuth <[email protected]> EventQL The open-source database for large-scale analytics.
distributed SQL database built for large-scale analytics workloads. It combines the power of traditional SQL databases with horizontal scalability to huge datasets. Eventually Consistent EventQL does not provide full ACID guarantees. It is an eventually consistent, commutatively replicated (AP) system. Open-Source The EventQL™ codebase is available under an open-source license. Still, DeepCortex GmbH is happy to offer unparalleled access to EventQL brain power and commercial support. “Scales to Petabytes” EventQL distributes all data and queries among a cluster of servers. Given enough machines you can store and query thousands of terrabytes of data in a single table. Parallel Queries with standard SQL EventQL parallelizes queries and executes them on many machines at once. EventQL supports a large and growing subset of standard SQL, including JOINs. Automatic Replication & Failover The shared-nothing architecture of EventQL is highly fault tolerant. A cluster consists of many, equally privileged nodes and has no single point of failure. Streaming INSERTs & UPDATEs EventQL supports INSERT, UPSERT and DELETE operations. It allows to import streaming data with at-least once semantics from any data source. EventQL is designed for data analytics (OLAP) and is not a good fit for transactional workloads due to the loose consistency gurantees.
๏ Storage Engine ๏ Parallel Queries ๏ Query Caching ๏ Replication & Coordination EventQL works by distributing the data and work among a large number of servers. The remainder of this presentation will explore the individual subsystems required for this in more detail:
has a mandatory, unique primary key. The primary key is used to automatically split the table into partitions of roughly 500MB each. Each table partition is defined as an interval of primary keys[0]. A CREATE TABLE statement in EventQL. Illustration of a table’s partitioned keyspace. The partitioning is automatic and transparent to the user: The user doesn’t have to determine or configure the number of partitions. The only requirement is a good primary key. [0] Fay Chang et al. (2006) Bigtable: A Distributed Storage System for Structured Data (7th USENIX Symposium on Operating Systems Design and Implementation) — http:// static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf
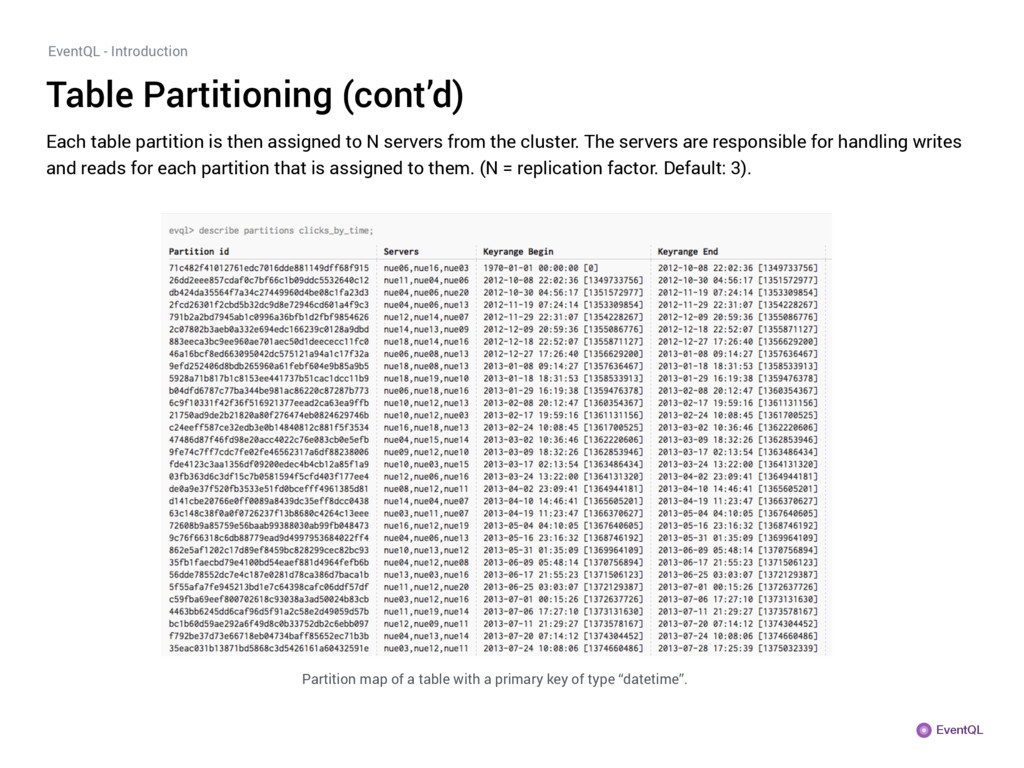
is then assigned to N servers from the cluster. The servers are responsible for handling writes and reads for each partition that is assigned to them. (N = replication factor. Default: 3). Partition map of a table with a primary key of type “datetime”.
points are determined using a divide-and-conquer-like splitting approach. This scheme always yields a perfect partitioning independent of the distribution of the underlying data, even if the distribution of the data changes over time (similar to a balanced tree). The basic idea is that every table starts out with a single partition that covers the whole keyspace (neg to pos infinity). As soon as this first partition hits a size threshold, it is split into two equal sized parts. This continues recursively as more data is inserted.[0] Illustration of a partition “split” operation [0] Fay Chang et al. (2006) Bigtable: A Distributed Storage System for Structured Data (7th USENIX Symposium on Operating Systems Design and Implementation) — http:// static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf
common approach to distributing data is a DHT. This is what e.g. DynamoDB[0]/Cassandra[1] does. A quick comparison: - In contrast to DHTs, the partition map scheme allows for fast range scans. This is important since if we were only able to do full table scans, every query would be O(N) on the table size - In contrast to DHTs, we can add and remove servers without rebalancing 1/N% of the data. This is important as it allows us to continually add new servers without creating load on the cluster. - You need to store some metadata (i.e. the list of partitions). The split operation requires linearizable mutation operations on the metadata (we solve this by using ZooKeeper, more about that later) - If too many writes hit the exact same key, a partition might get overloaded (“lasering”). This is mitigated by choosing a good primary key and/or a number of optimizations in EventQL (fast splits and “insert smearing”) - Write amplification is a wash. The amplification is moved from the rebalance to the split operation The good: The bad: [0] Giuseppe DeCandia et al. (2007) Dynamo: Amazon’s Highly Available Key-value Store (21st ACM Symposium on Operating Systems Principles) — http://www.allthingsdistributed.com/ files/amazon-dynamo-sosp2007.pdf [1] Avinash Lakshman, Prashant Malik (2009) Cassandra - A Decentralized Structured Storage System (ACM SIGOPS Operating Systems Review archive Volume 44 Issue 2) — https:// www.cs.cornell.edu/projects/ladis2009/papers/lakshman-ladis2009.pdf
partitions are stored on disk using a column-oriented layout[0]. Updates to the columnar files are implemented using a log-structured-merge-tree[1] approach. Incoming writes are buffered in memory and periodically flushed to disk by writing a new segment file. The segment file is written to disk using a single sequential write. A background thread occasionally compacts the segment files (i.e. it merges all segment files into a single file). When querying a partition, each column can be read separately. This greatly reduces the I/O load for queries which only access some of the columns of a table (compared to a traditional row-oriented approach). Additionally, the columnar representation allows for efficient compression of the data, e.g. using bitpacking. This further reduces the number of bytes that actually need to be retrieved from disk to answer a query. [0] Andrew Lamb et al. (2012) The Vertica Analytic Database: C-Store 7 Years Later (The 38th International Conference on Very Large Data Bases) — http://vldb.org/pvldb/vol5/ p1790_andrewlamb_vldb2012.pdf [1] https://en.wikipedia.org/wiki/Log-structured_merge-tree
is what happens for each INSERT operation: 1. The user sends the INSERT to any server in the cluster. The server that receives the INSERT operation becomes the coordinating server for this operation 2. The coordinating server computes the primary key value for the INSERT and looks up the corresponding partition in his local copy of the partition map (this does not require a network roundtrip) 3. The coordinating server forwards the INSERT to every server that owns the corresponding partition and waits for acknowledgements. 3a. Once the servers that own the partition receive the INSERT, they write it to an in-memory segment that will asynchronously be flushed to disk and then respond with an acknowledgement. [ However the write is still immediately visible for queries ] 4. As soon as the minimum number of servers has acknowledged the write to the coordinating server, the coordinating server confirms the write to the requesting client. [ The exact number of required acknowledgements depends on the chosen consistency level ] Note that no communication with any master/zookeeper is required for the insert. There is no single point of failure, and, depending on the consistency level, inserts will succeed as long as there is a “last server standing”.
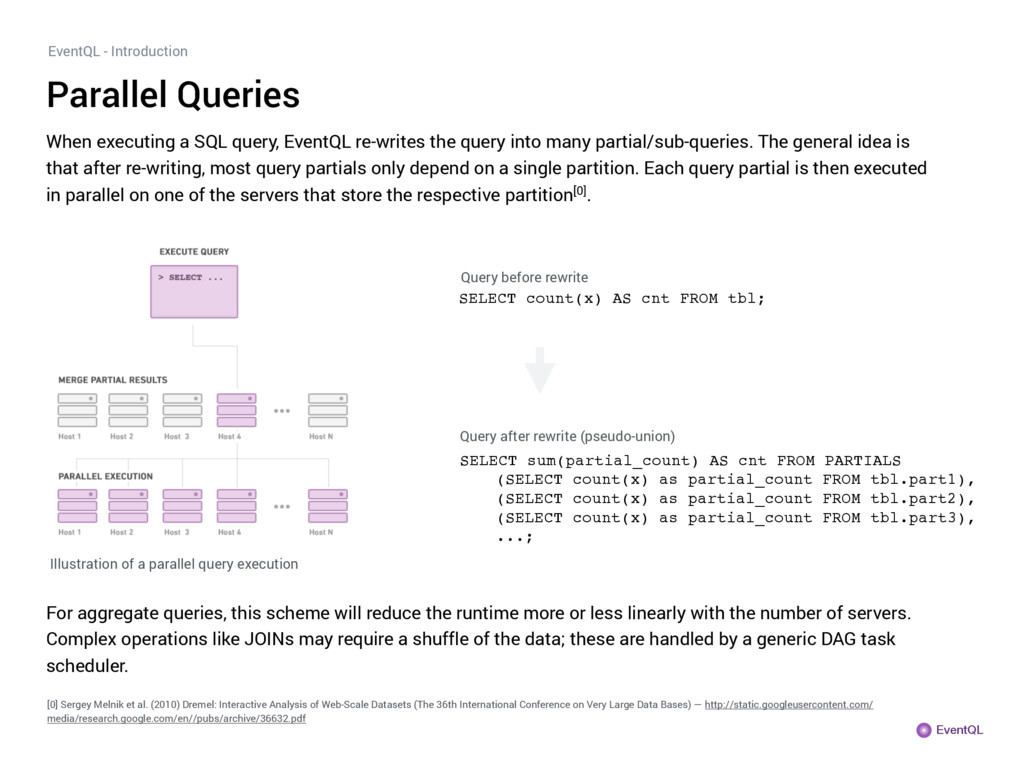
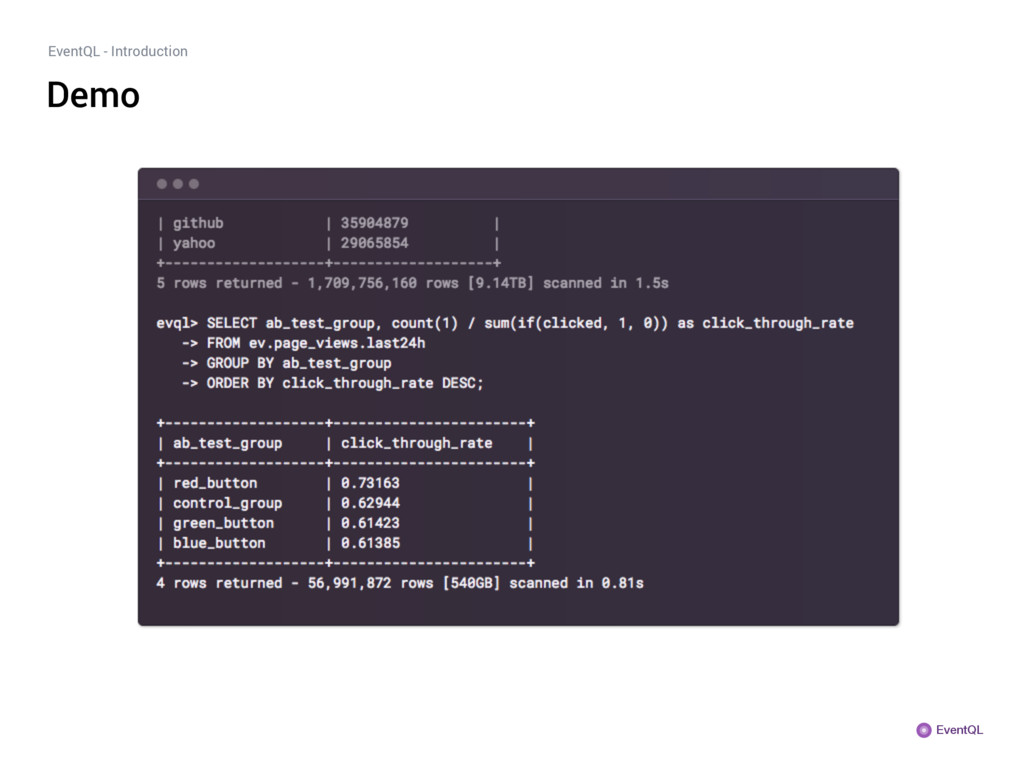
query, EventQL re-writes the query into many partial/sub-queries. The general idea is that after re-writing, most query partials only depend on a single partition. Each query partial is then executed in parallel on one of the servers that store the respective partition[0]. Illustration of a parallel query execution For aggregate queries, this scheme will reduce the runtime more or less linearly with the number of servers. Complex operations like JOINs may require a shuffle of the data; these are handled by a generic DAG task scheduler. Query before rewrite SELECT count(x) AS cnt FROM tbl; SELECT sum(partial_count) AS cnt FROM PARTIALS (SELECT count(x) as partial_count FROM tbl.part1), (SELECT count(x) as partial_count FROM tbl.part2), (SELECT count(x) as partial_count FROM tbl.part3), ...; Query after rewrite (pseudo-union) [0] Sergey Melnik et al. (2010) Dremel: Interactive Analysis of Web-Scale Datasets (The 36th International Conference on Very Large Data Bases) — http://static.googleusercontent.com/ media/research.google.com/en//pubs/archive/36632.pdf
the query into query partials is that besides parallel execution, each partial can be cached efficiently. Note that all caching is fully transparent and therefore always enabled — EventQL will never server stale cache entries. The general idea is that when executing a partial query on a single partition we store the query result on the server that also stores the partition data. We invalidate the cache once the partition is modified. So when repeatedly executing the same (or similar) query, EventQL only has to re-calculate the results for those partitions that have changed since the last execution. This is especially beneficial when you consider the case of timeseries or log-structured data where old data usually never changes.
what happens for each query operation: 1. The user sends the query to any server in the cluster. The server that receives the query operation becomes the coordinating server for this query 2. The coordinating server rewrites the query into partials. Each partial is amended with a list of candidate servers that store the required partition. 3a. The coordinating server sends a broadcast to all candidate servers that can potentially store a cached partial query result. If one of the candidate servers has a partial query result in cache, it responds accordingly. 3b. All remaining query partials (that could not be retrieved from cache) are executed in parallel on the candidate servers that store the respective data (taking into account inter-dependencies between partials). If a query partial fails on one candidate server, it is retried on the next server until all candidates are exhausted. 3c. On each server that executes a query partial, only the columns that are required to answer the partial query are read from disk, not the whole partition. Afterwards the query result is stored in the local cache and returned to the coordinating server. 4. The coordinating server merges the partial results and returns them to the client Note that again no communication with any master/zookeeper is required for the query. There is no single point of failure, the query will succeed as long as there is a “last server standing” that has the required data.
EventQL is equally privileged. There is no leader or master partition. In classical RDBMS terms, EventQL performs active master<>master replication between all copies of a partition. The EventQL replication algorithm is push based. I.e. each server is responsible for sending all rows it stores to all other servers that should store them. The algorithm is so simple that it is best described in pseudocode: This scheme does not allow for strict ACID guarantees and results in some write amplification,. However, it is also very elegant and extremely fault tolerant. There is no way for a replica to become corrupt and there are no corner cases when adding or removing servers (each server assignment has a nonce). EventQL can serve both writes and reads for any partition as long as at least one of the N servers to which the partition is assigned is alive/reachable function replicate(): for each partition P: for each server assignment S in assigned_servers(P): if not all_rows_sent_to(P, S) send_rows_to(P, S)
does not provide full ACID guarantees, what does it guarantee? An informal/loose definition of EventQL’s semantics: Yes, every write operation in EventQL is atomic. But there are no transactions, so you can’t group multiple writes into one atomic commit. Atomicity — Yes, every write operation in EventQL is durable. However, writes may only become visible after some time and may temporarily become invisible in some cases (see consistency) Durability — No strict consistency (i.e. no linearizability). Only eventual consistency. EventQL gurantees that every acknowledged write will eventually become visible. However, you might not immediately see a write after it was confirmed in some cases. Conflicting writes are automatically resolved using a “latest write wins” approach with microsecond timestamps. Consistency —
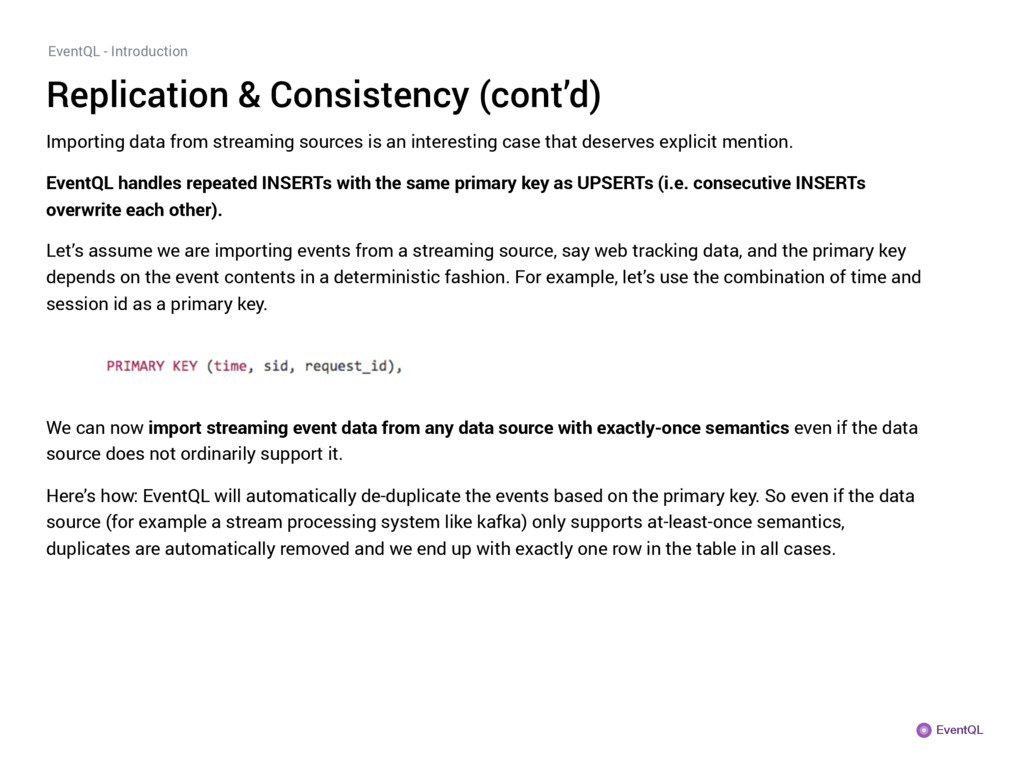
from streaming sources is an interesting case that deserves explicit mention. EventQL handles repeated INSERTs with the same primary key as UPSERTs (i.e. consecutive INSERTs overwrite each other). Let’s assume we are importing events from a streaming source, say web tracking data, and the primary key depends on the event contents in a deterministic fashion. For example, let’s use the combination of time and session id as a primary key. We can now import streaming event data from any data source with exactly-once semantics even if the data source does not ordinarily support it. Here’s how: EventQL will automatically de-duplicate the events based on the primary key. So even if the data source (for example a stream processing system like kafka) only supports at-least-once semantics, duplicates are automatically removed and we end up with exactly one row in the table in all cases.
in Zookeeper The only significant shared state between individual EventQL servers is the partition map and configuration for each table. Some modifications on this metadata, like changing the table schema or committing a partition split required strict consistency. Rather than implementing our own coordination scheme, we use the Zookeeper[0] locking service. Still, not all of the metadata can be stored in Zookeeper due to the tight limits that Zookeeper imposes on znode size. Instead, the actual partition map (which can get up to dozens of megabytes in size for very large tables) is stored on regular EventQL servers. Zookeeper only stores a “pointer” to the latest version of the metadata for each table. Modifications on the metadata are then performed by applying them opportunistically on some servers and then compare-and-swapping the pointer in zookeeper. We plan to supprt other locking services, like etcd at some later point. [0] https://zookeeper.apache.org/
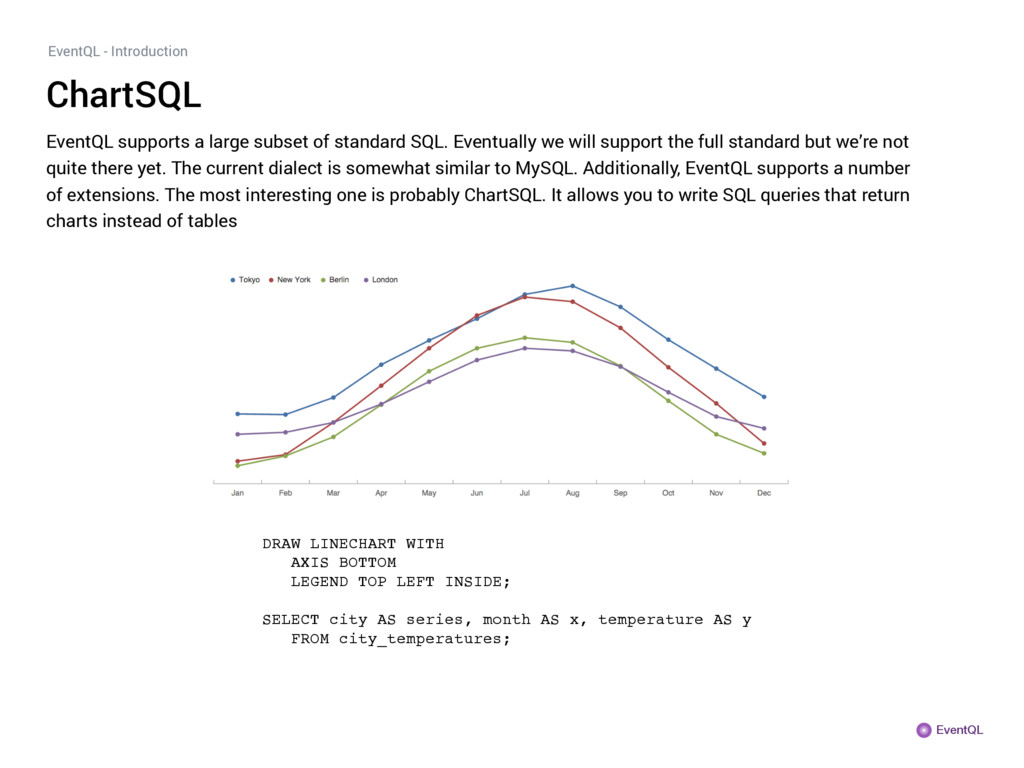
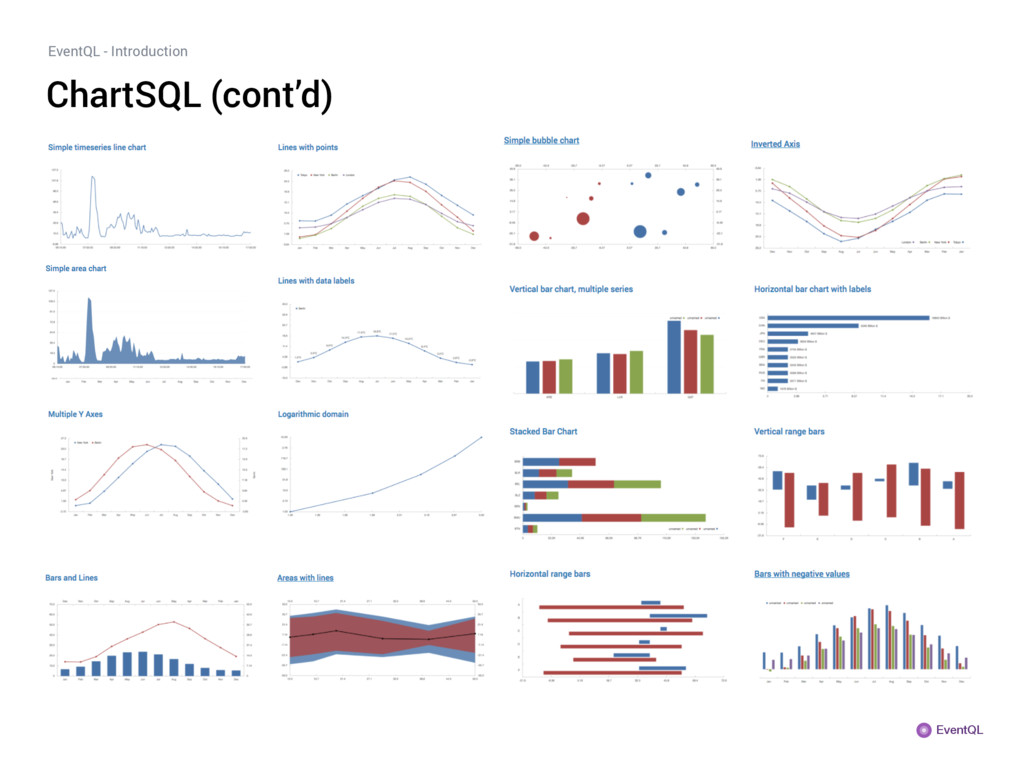
of standard SQL. Eventually we will support the full standard but we’re not quite there yet. The current dialect is somewhat similar to MySQL. Additionally, EventQL supports a number of extensions. The most interesting one is probably ChartSQL. It allows you to write SQL queries that return charts instead of tables DRAW LINECHART WITH AXIS BOTTOM LEGEND TOP LEFT INSIDE; SELECT city AS series, month AS x, temperature AS y FROM city_temperatures;
(timeseries, relational, etc) as long as there is a good primary key - Storage capacity and (most) queries scale linearly with number of servers (“…to petabytes”) - All writes are durable and eventually consistent - Supports streaming exactly-once inserts and upserts - Fast aggregate queries on huge datasets thanks to parallelization, columnar storage (reduced I/O) and caching - Highly available by design; servers are equally privileged. There is no master/leader and there is no SPOF - Servers can be added to the cluster without requiring a rebalance (adding servers is instant) - Supports range scans on tables - Supports standard SQL - Built-in HTTP API - No transactions, reads/writes are not linearizable After all of this, a quick recap of EventQL key features:
on OSX and Linux. While EventQL is a distributed database first and foremost it also implements a standalone mode so you can get it running on your development machine in seconds: Documentation: https://eventql.io/ Github: https://github.com/eventql/eventql
are always highly appreciated! Ping me at [email protected] Documentation: https://eventql.io/ Github: https://github.com/eventql/eventql EventQL The open-source database for large-scale analytics.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}