Distributed Systems • Founded January 2008 • 115+ employees • Headquartered in Cambridge, with regional offices in San Francisco, Washington DC, London and Tokyo • Makers of Riak- A popular distributed key- value store • Thousands of Users Worldwide including over 20% of the Fortune 50 • 30,000+ downloads per month now up from 19,500 in Dec 2011 • Strategic Partners include Citrix, IDC Frontier, Yahoo! Japan, and Microsoft
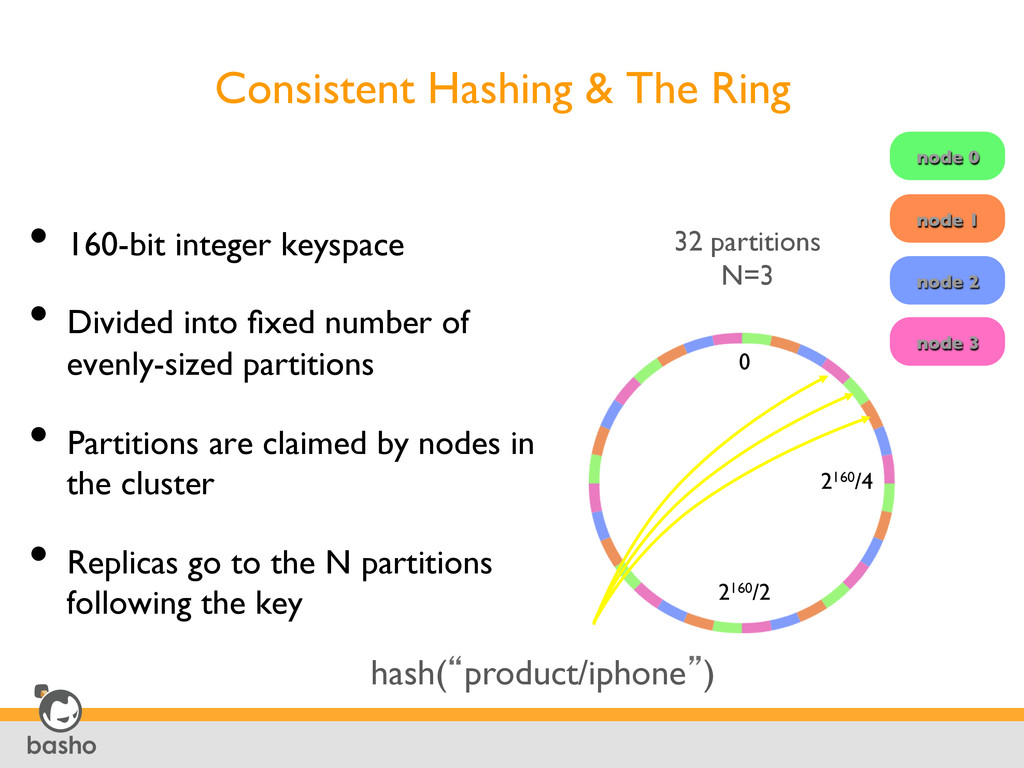
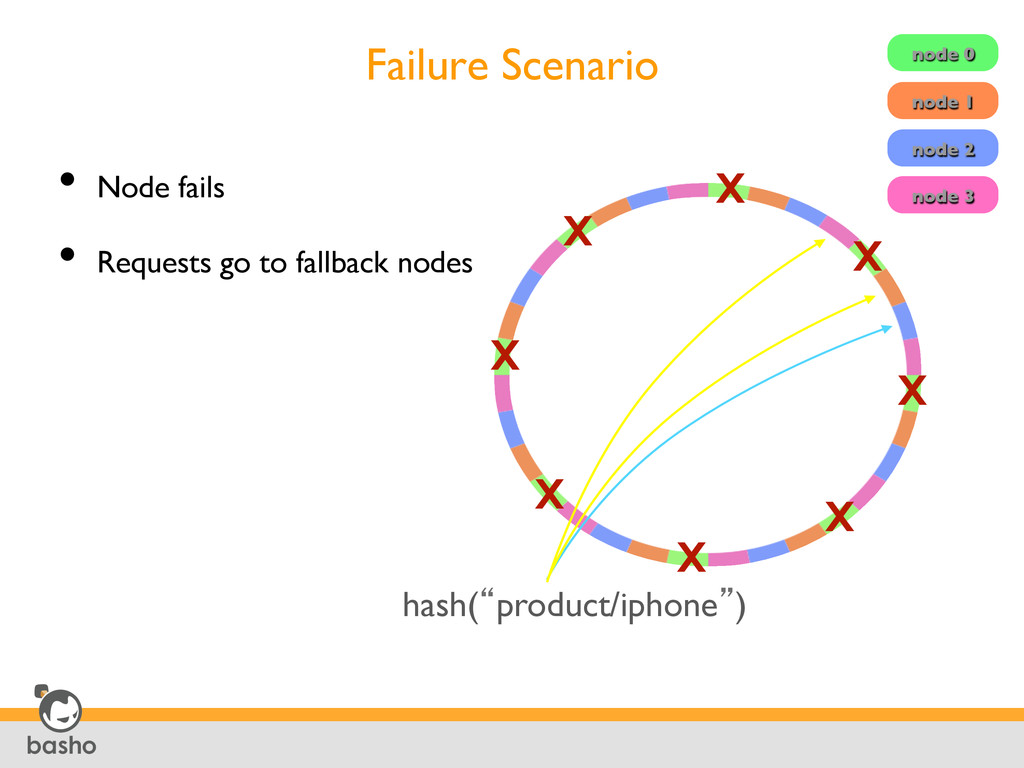
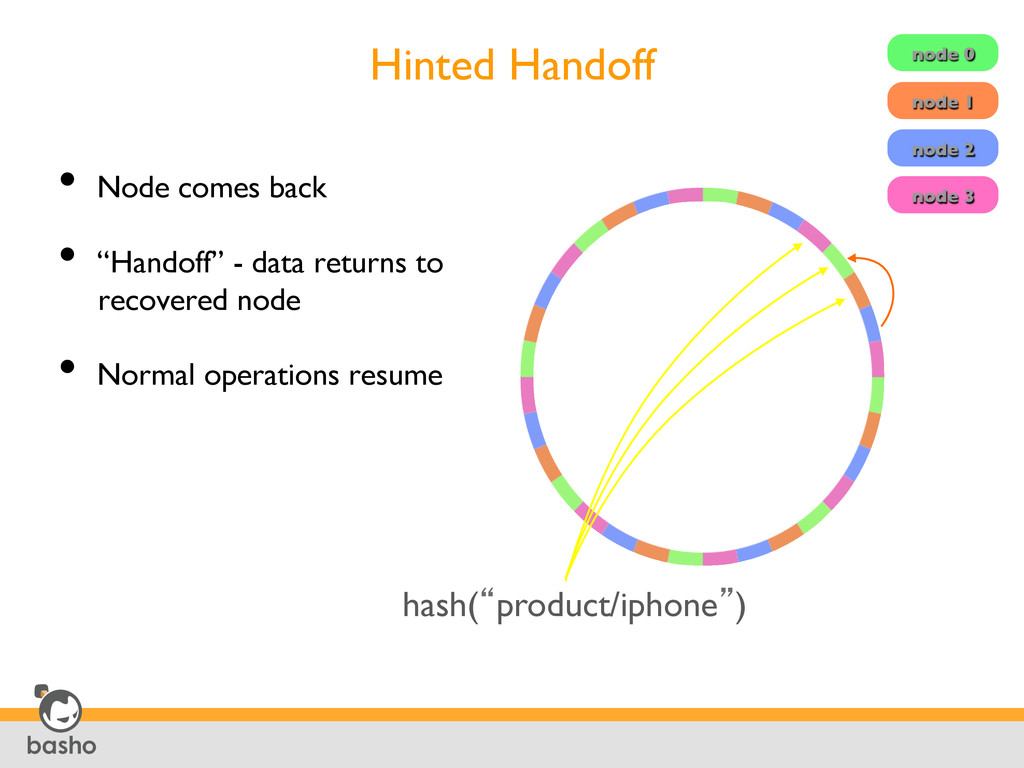
Divided into fixed number of evenly-sized partitions • Partitions are claimed by nodes in the cluster • Replicas go to the N partitions following the key 32 partitions N=3 node 0 node 1 node 2 node 3 hash(“product/iphone”) 2160/4 2160/2 0
bucket-level setting. Defaults to “3”. • w - number of replicas required for a successful write; Defaults to “2”. • r - number of replica acks required for a successful read. request-level setting. Defaults to “2”. • pr, pw & dw • Tweak consistency vs. availability
you, Google) Client Libraries Ruby, Node.js, Java, Python, Perl, Erlang, PHP, C, Scala, Haskell, Lisp,.NET, Play, and more (supported by either Basho or the community).
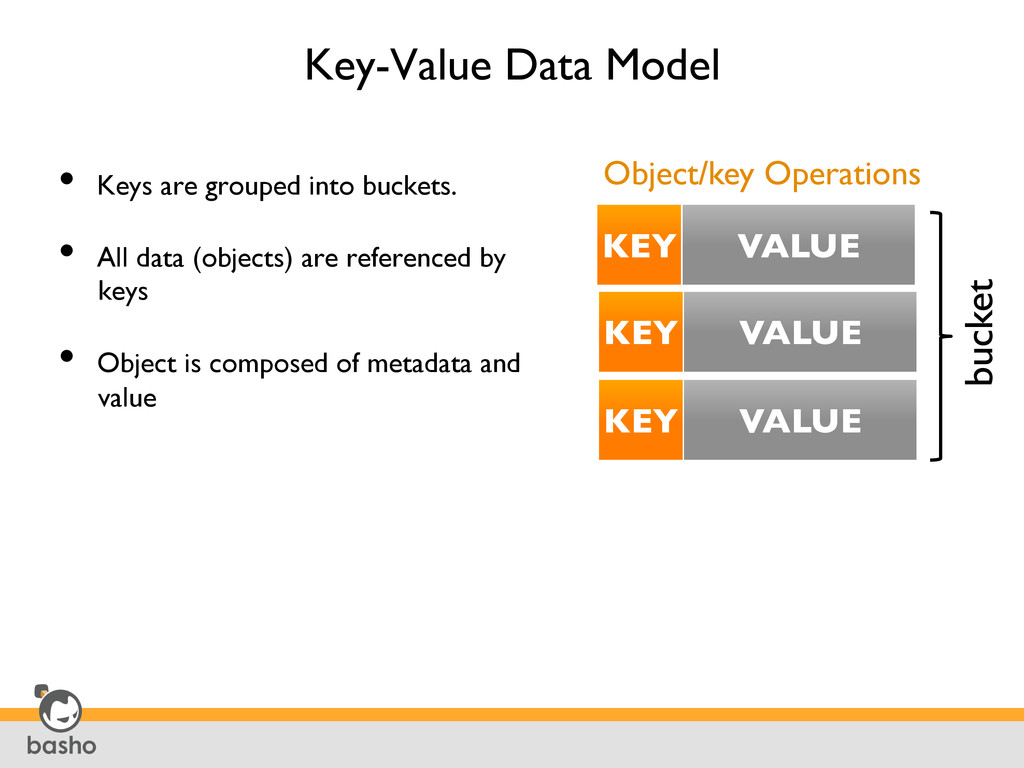
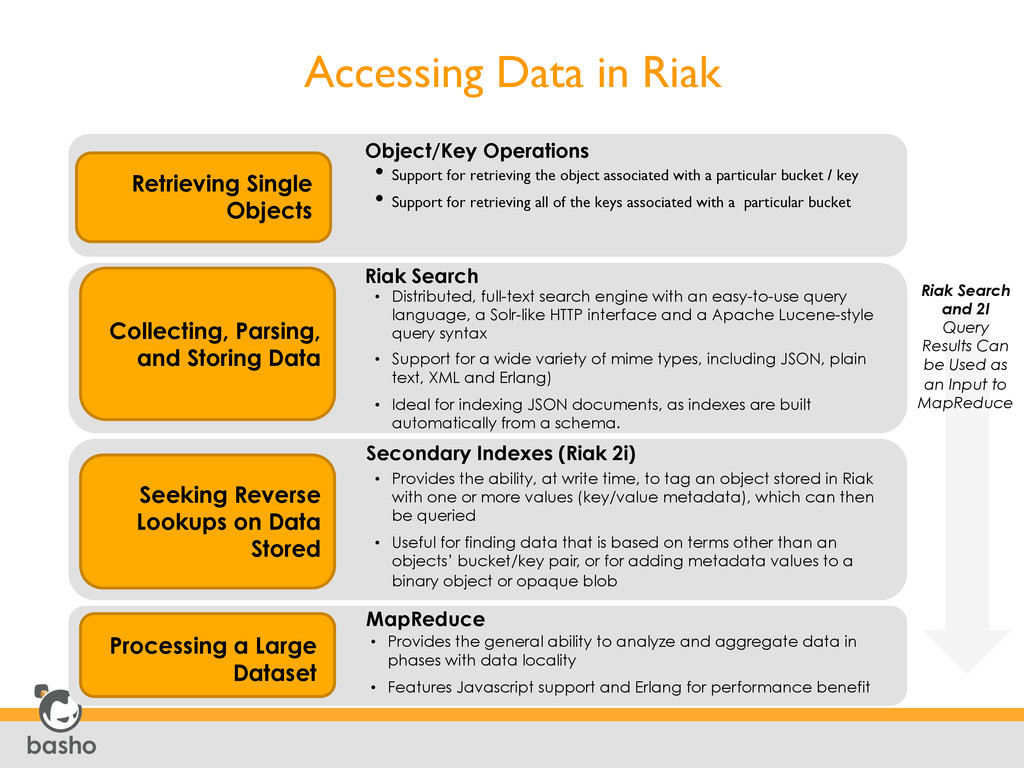
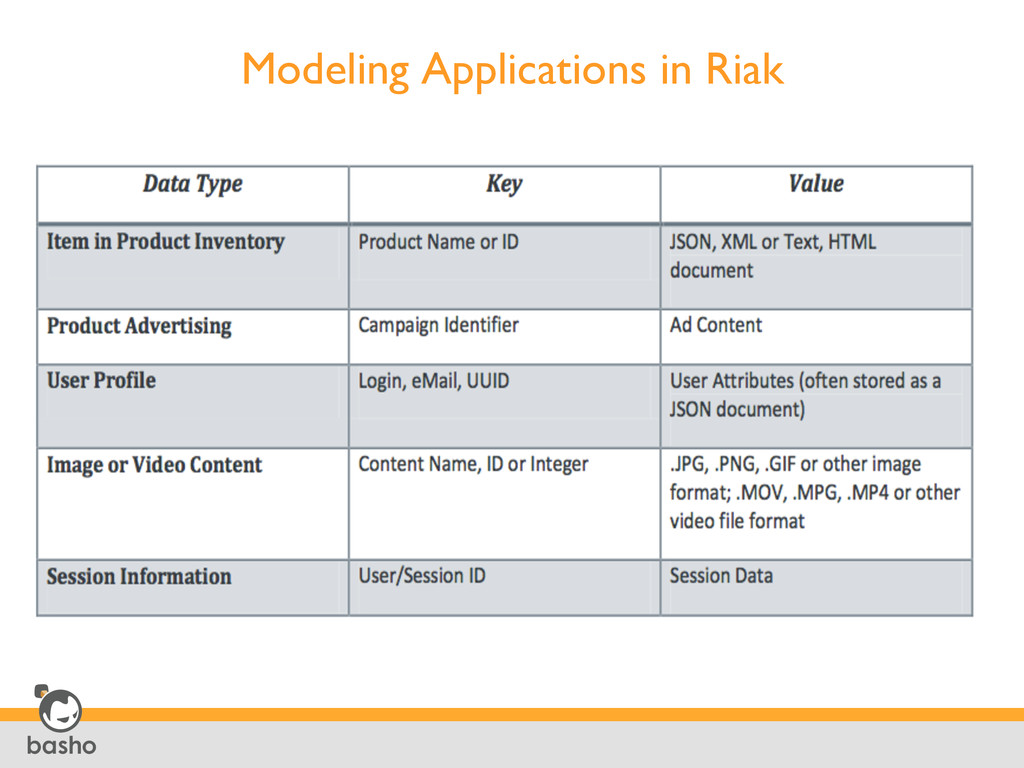
retrieving the object associated with a particular bucket / key • Support for retrieving all of the keys associated with a particular bucket Object/Key Operations Collecting, Parsing, and Storing Data • Distributed, full-text search engine with an easy-to-use query language, a Solr-like HTTP interface and a Apache Lucene-style query syntax • Support for a wide variety of mime types, including JSON, plain text, XML and Erlang) • Ideal for indexing JSON documents, as indexes are built automatically from a schema. Riak Search Seeking Reverse Lookups on Data Stored • Provides the ability, at write time, to tag an object stored in Riak with one or more values (key/value metadata), which can then be queried • Useful for finding data that is based on terms other than an objects’ bucket/key pair, or for adding metadata values to a binary object or opaque blob Secondary Indexes (Riak 2i) Processing a Large Dataset • Provides the general ability to analyze and aggregate data in phases with data locality • Features Javascript support and Erlang for performance benefit MapReduce Riak Search and 2I Query Results Can be Used as an Input to MapReduce
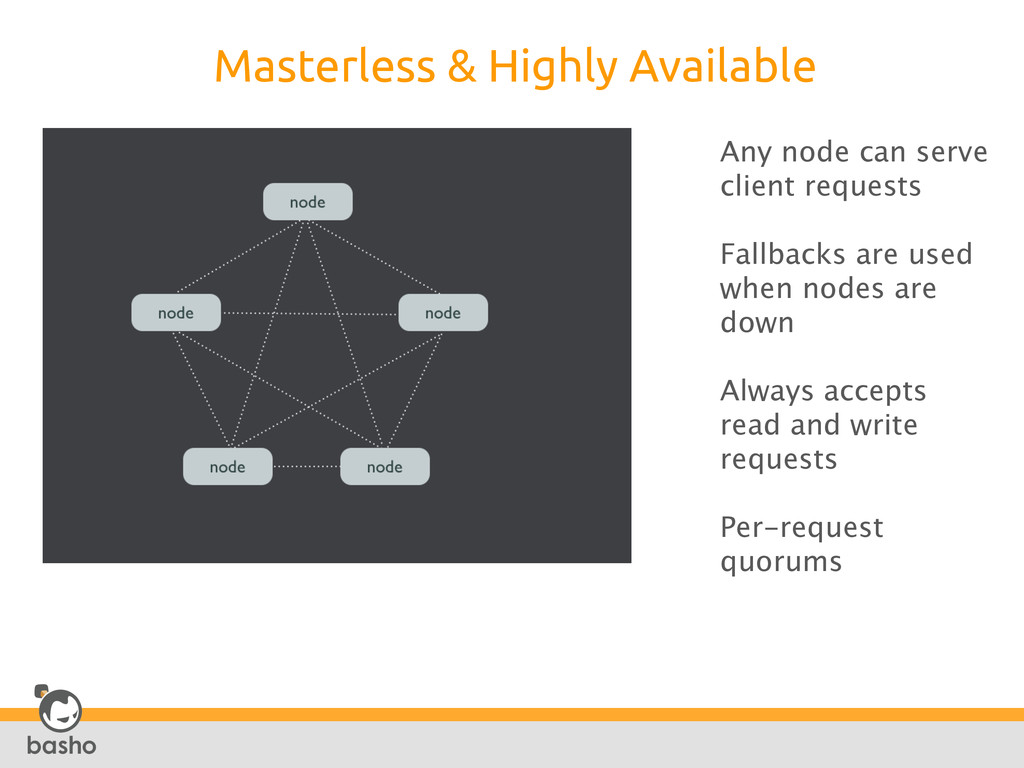
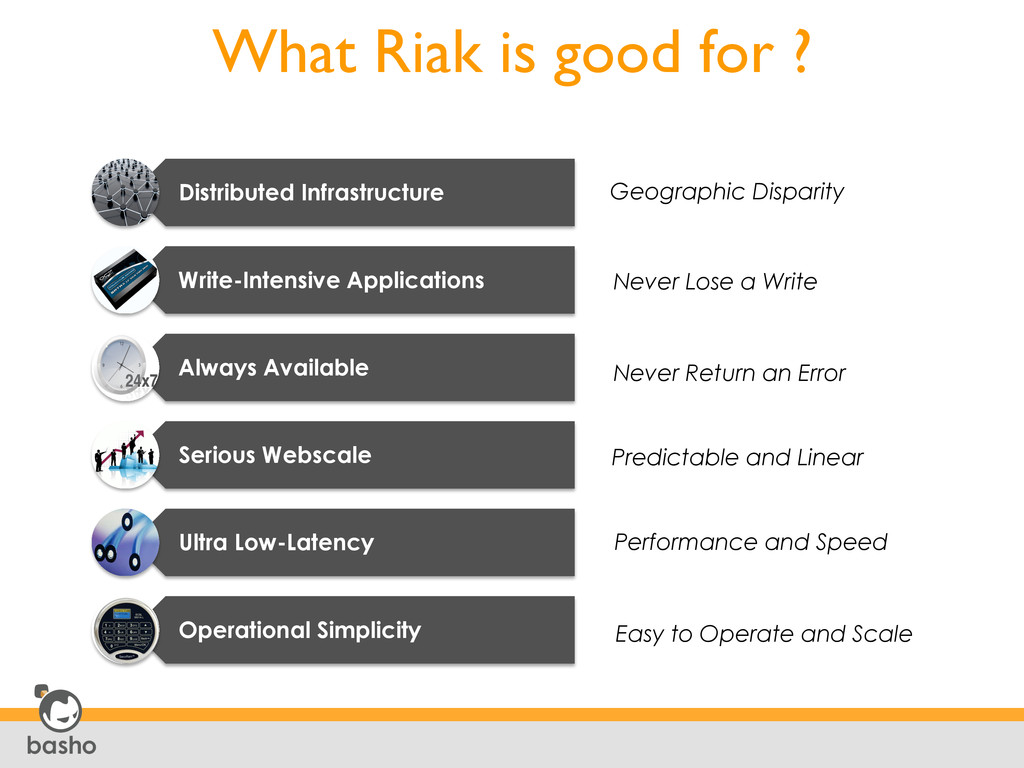
require >1 physical machine (preferably > 4) • When availability is the top requirement • When your data can be modeled as keys and values When to Use Popular Use Cases • Ad Networks • Digital Media • On-Line Games • Social Networks • Social Analysis • Cloud Operators • Messaging Services • Product Catalogs • Document Management • Health Care Information Management
Apple App Store App • #4 most popular Apple App Store Social Networking App at EOY behind Facebook, Skype and Twitter • Truly Viral Growth: Scaled 10x between Thanksgiving and New Years Day • Required scaling across multiple IaaS / hosting providers • Surpassed one billion operations per day
• 800 million pieces of structural data in Riak, including Photos, Chats, and Contact Cards. • 10 million active users • 77 million downloads to date • Switched to Riak in August 2011 • #7 Most Downloaded iPhone App
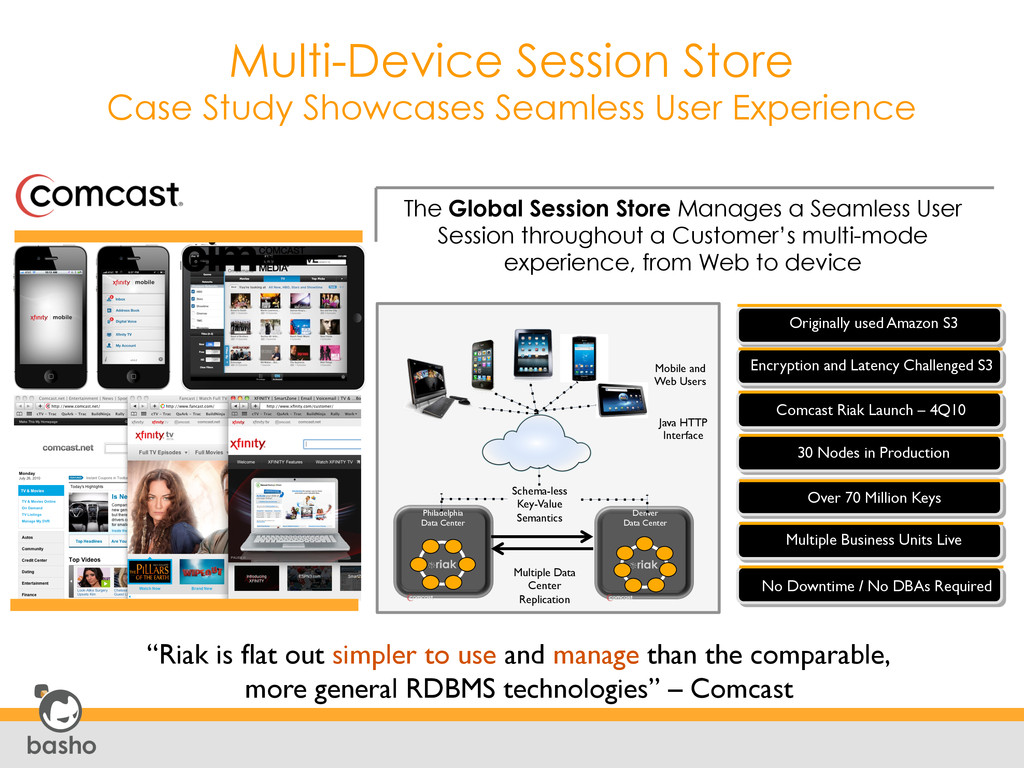
deploying and managing enterprise-class applications • Moved from MySQL to Riak. Reasons- • Write Scalability • Resilience to failure across multiple datacenters • Stores machine and state information, and data supporting analytics and audit control. • George Reese gave an excellent talk during Ricon last year, link below http://vimeo.com/54887751 “As I’ve looked at a number of problem domains from customers and our own systems, you see this pattern where a relational database has been used just because it’s the default… and the reality is that more of the world is eventually consistent than not”, said George Reese, CTO of enStratus
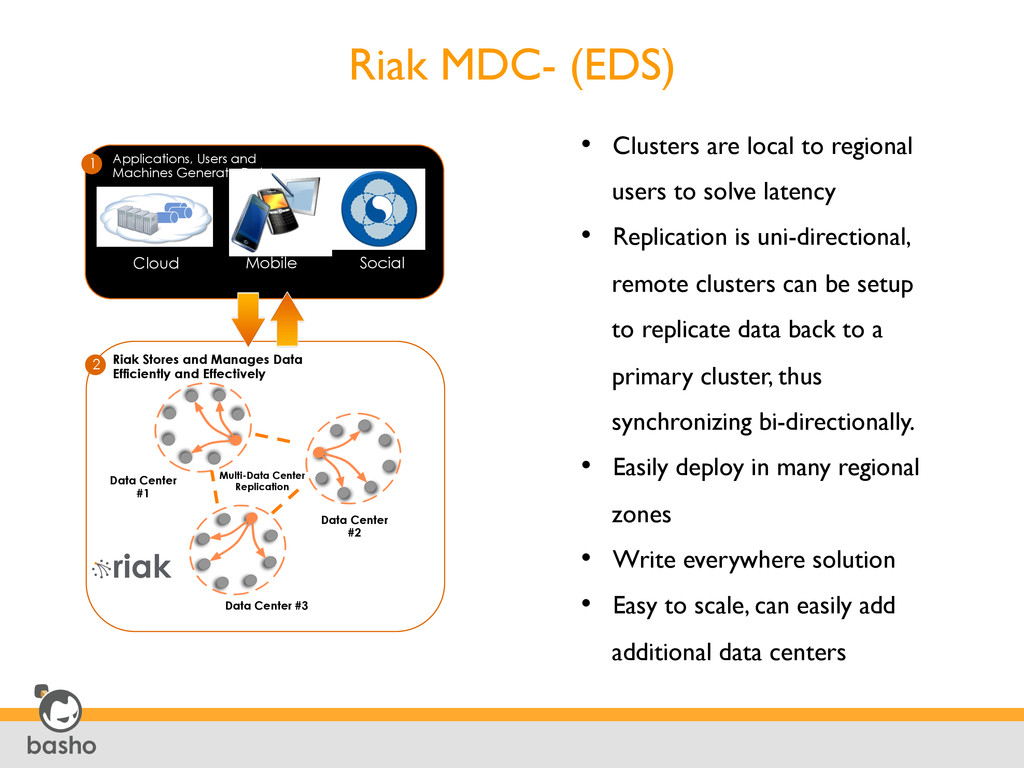
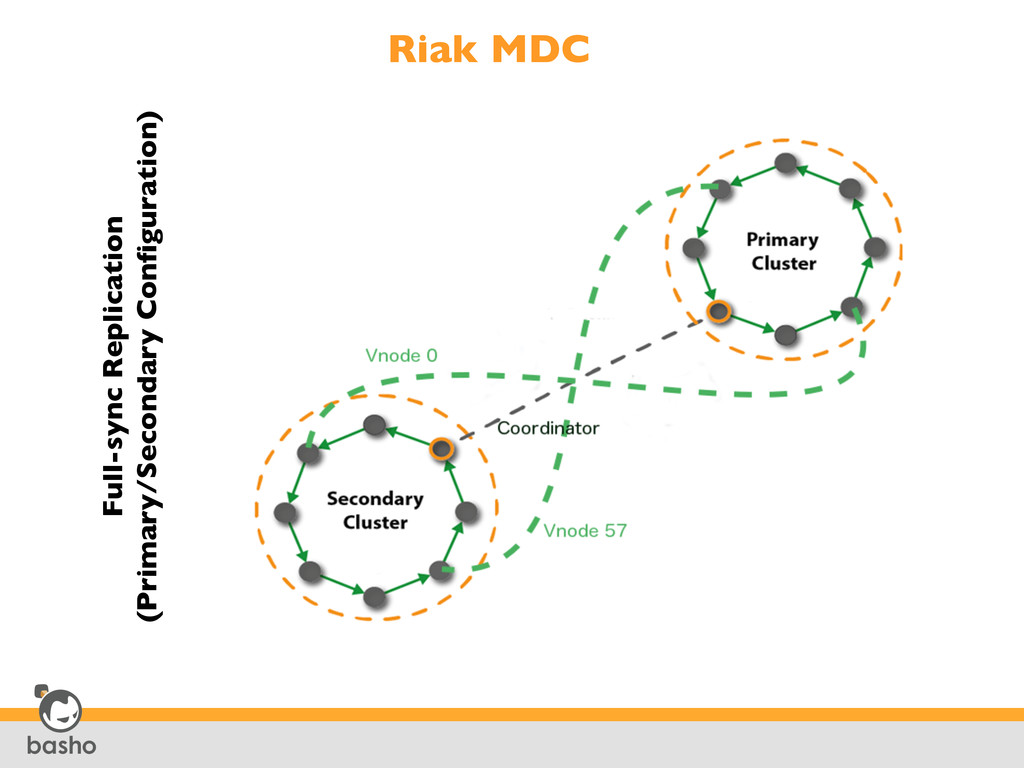
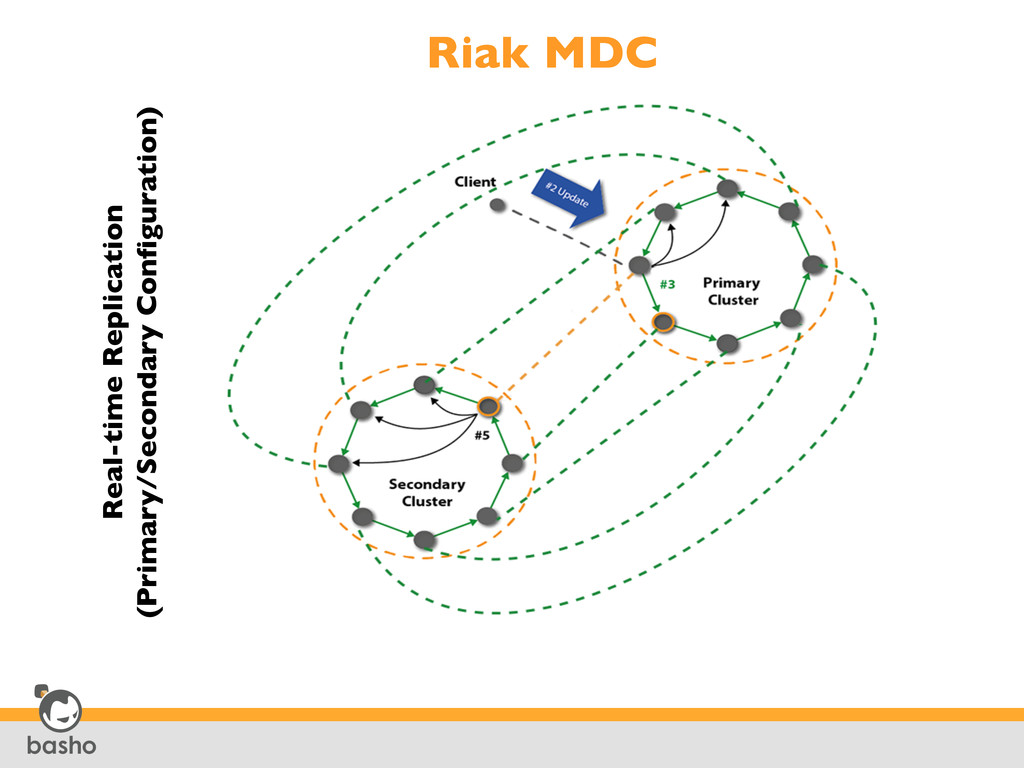
Center #3 Data Center #1 Multi-Data Center Replication Applications, Users and Machines Generate Data 1 2 Riak Stores and Manages Data Efficiently and Effectively • Clusters are local to regional users to solve latency • Replication is uni-directional, remote clusters can be setup to replicate data back to a primary cluster, thus synchronizing bi-directionally. • Easily deploy in many regional zones • Write everywhere solution • Easy to scale, can easily add additional data centers
rsync, tar, custom backup tools will work • FS-level snapshots of directory can be done while node is running • Backups aren't yet perfected and that future releases will have more efficient, specialized backup methods for each backend
status (counters, histograms, etc.) via the HTTP /stats endpoint or ‘riak- admin status’ • Anything that speaks HTTP can be plugged into Riak • Plugins exist for most OSS monitoring tools (munin, cacti, nagios, graphite, statsd)
diagnostic checks that can used to debug your cluster before it’s in production; checks for common misconfigurations • Riak Control is a full-fledged management GUI that Basho develops and maintains.
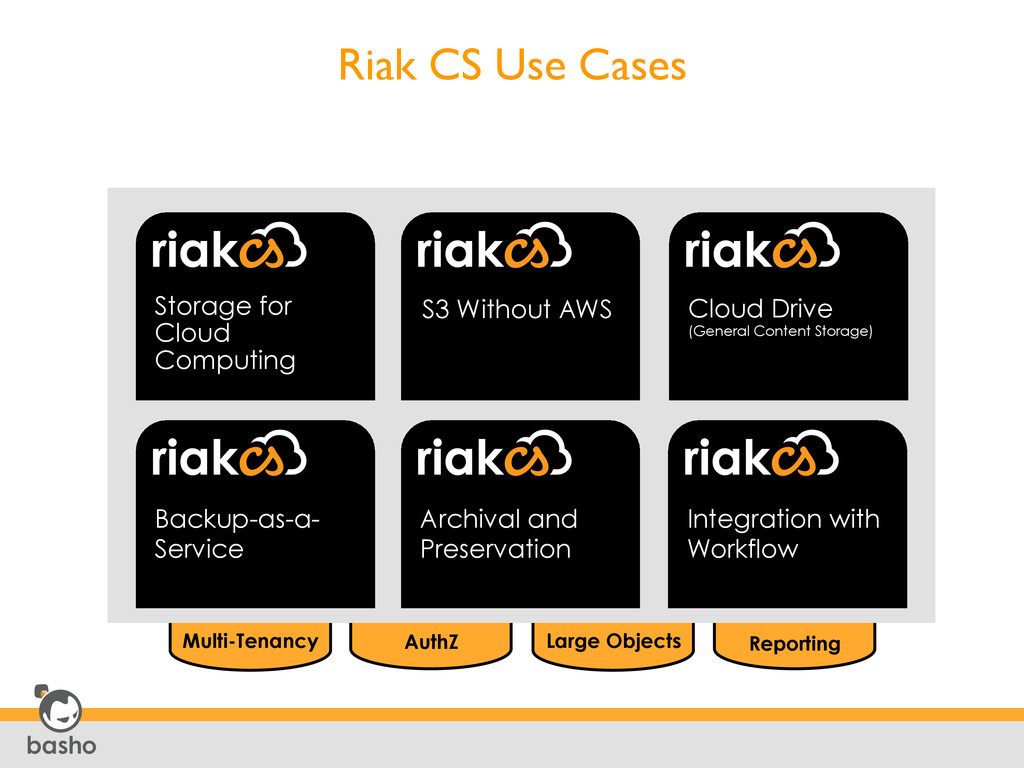
User Authentication and Authorization • Amazon S3 API-compatibility • Per-Tenant visibility • Provisioning, Metering, Billing and Reporting • Multi part upload up to 5TB
Cloud Computing S3 Without AWS Cloud Drive (General Content Storage) Backup-as-a- Service Archival and Preservation Integration with Workflow Multi-Tenancy
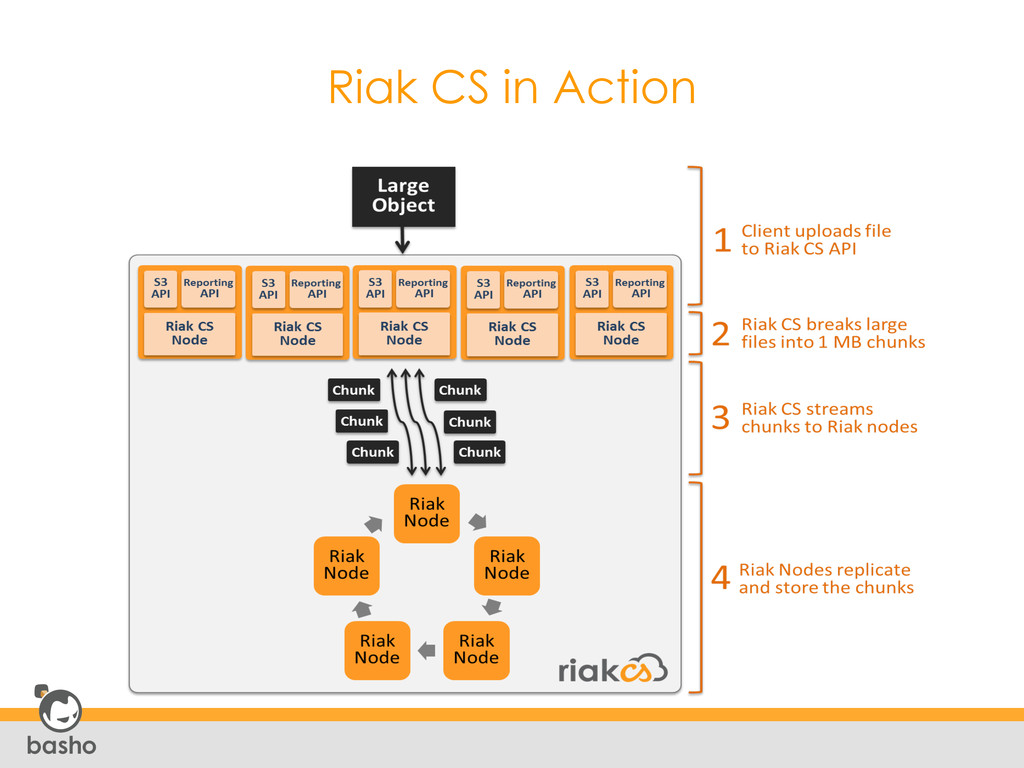
is streamed in real- time • Objects are replicated in full or real- time sync mode • If a client requests an object from a site but not all of the blocks that constitute that object have been replicated to that site, missing blocks will be requested and streamed from the “origin” cluster How It Works
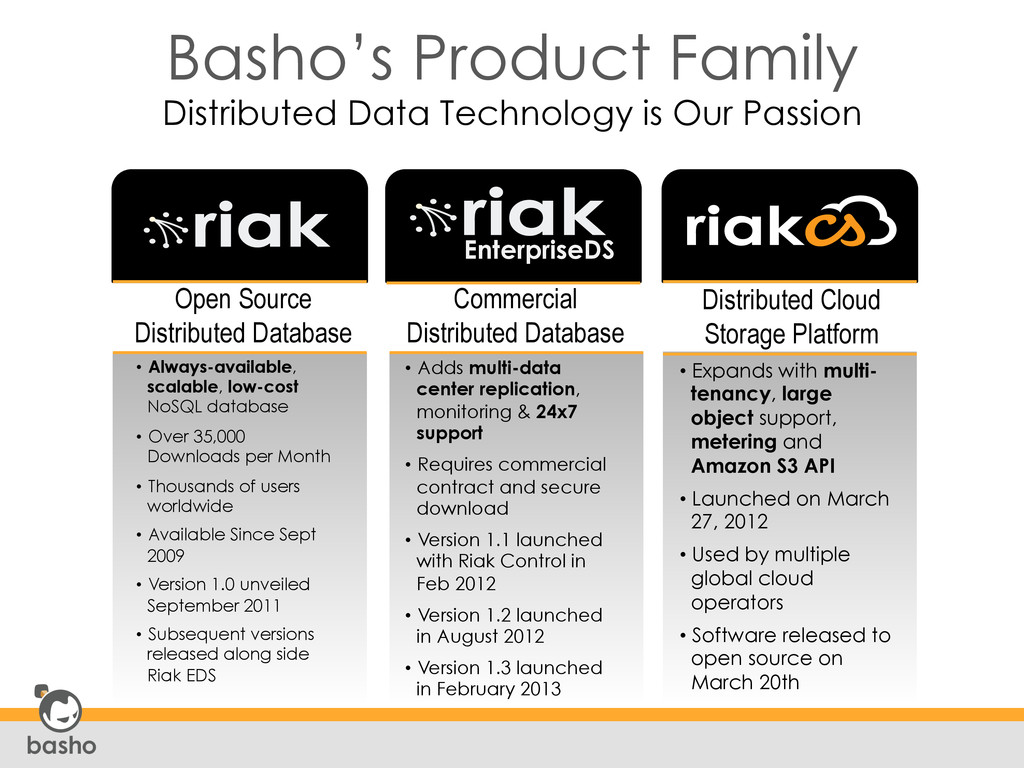
Open Source Distributed Database Commercial Distributed Database Distributed Cloud Storage Platform • Always-available, scalable, low-cost NoSQL database • Over 35,000 Downloads per Month • Thousands of users worldwide • Available Since Sept 2009 • Version 1.0 unveiled September 2011 • Subsequent versions released along side Riak EDS • Adds multi-data center replication, monitoring & 24x7 support • Requires commercial contract and secure download • Version 1.1 launched with Riak Control in Feb 2012 • Version 1.2 launched in August 2012 • Version 1.3 launched in February 2013 • Expands with multi- tenancy, large object support, metering and Amazon S3 API • Launched on March 27, 2012 • Used by multiple global cloud operators • Software released to open source on March 20th
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Q & A [email protected]](https://files.speakerdeck.com/presentations/248b3280aec901309d4e264b871ec8c9/slide_45.jpg){kind=link}