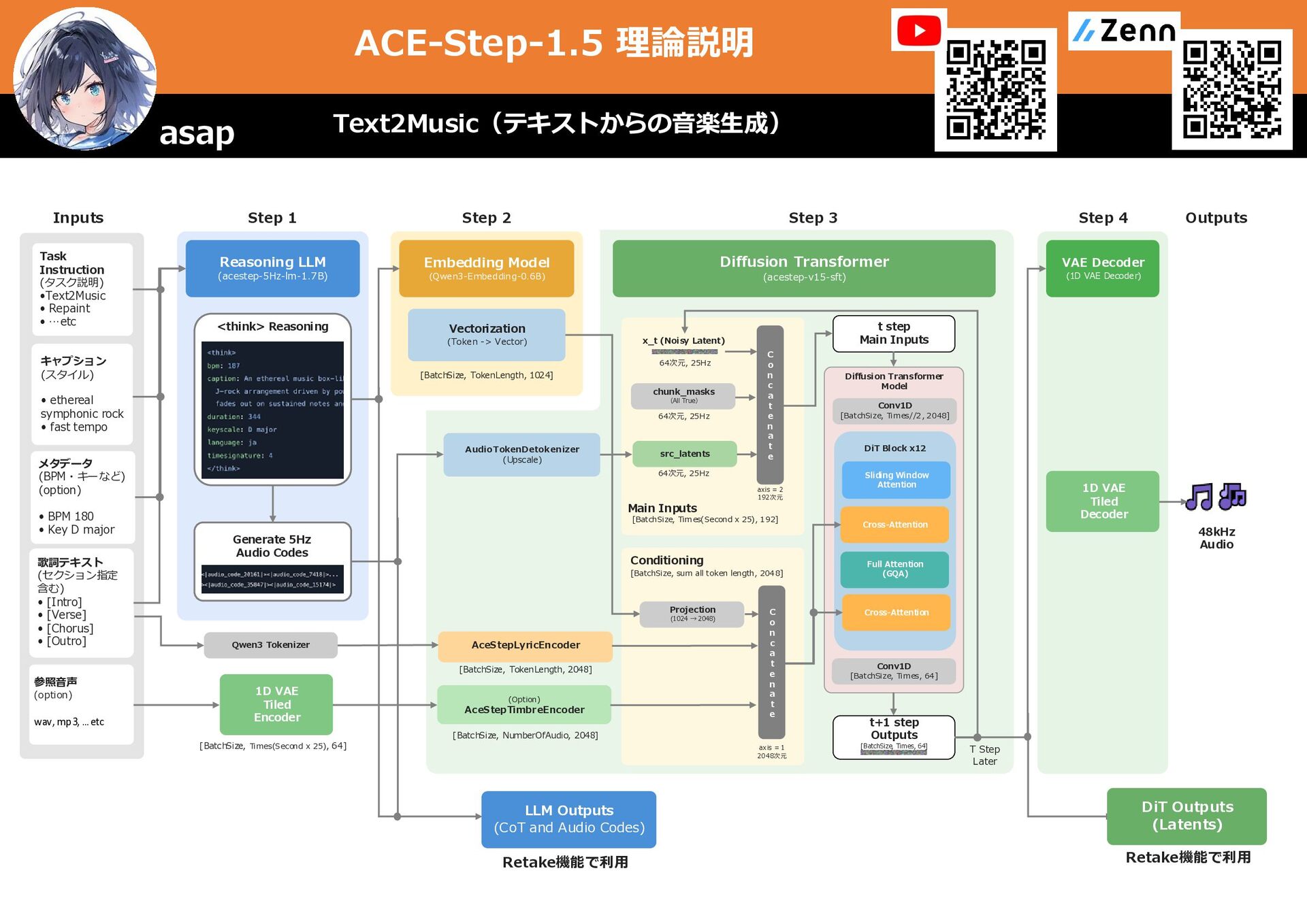
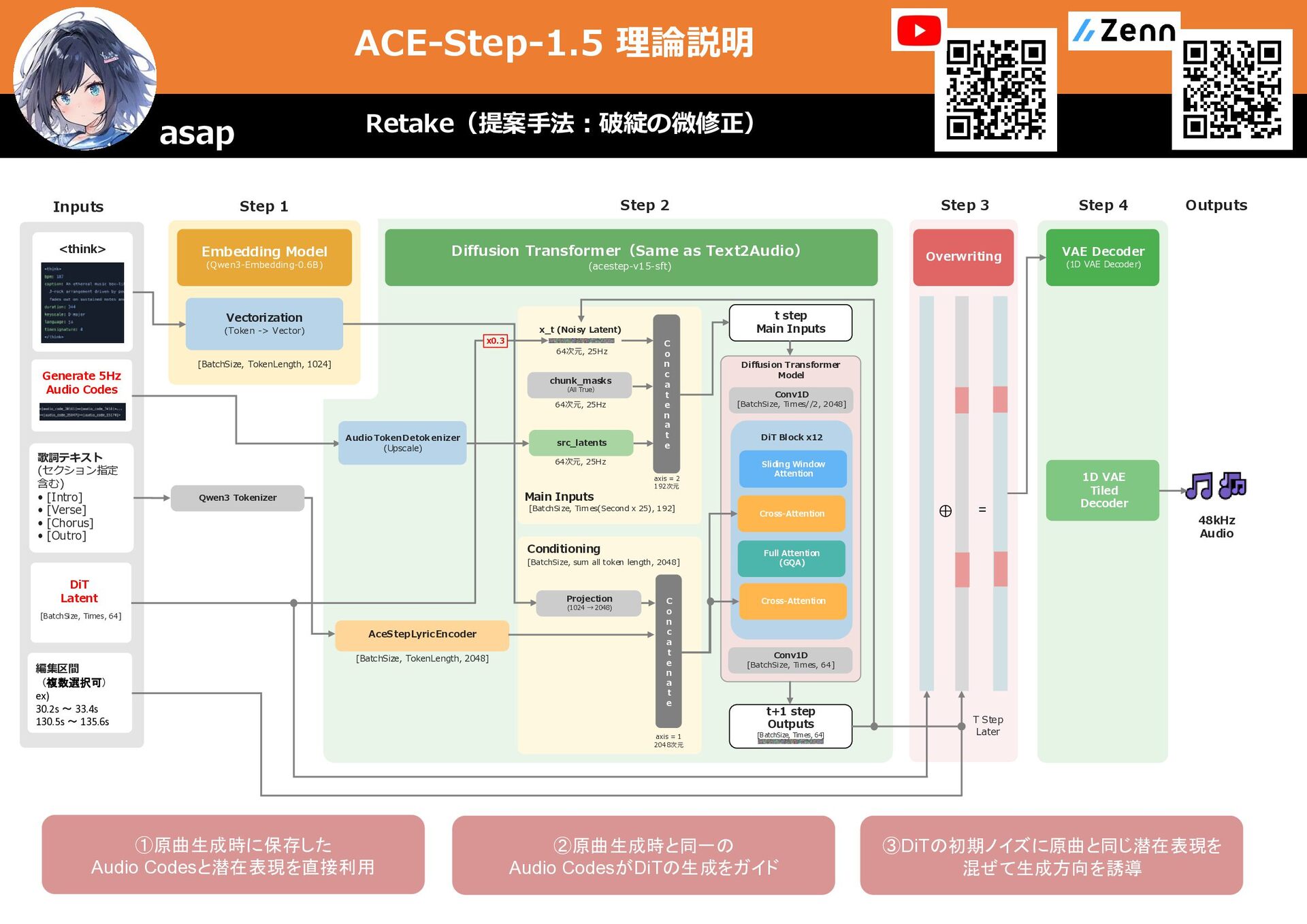
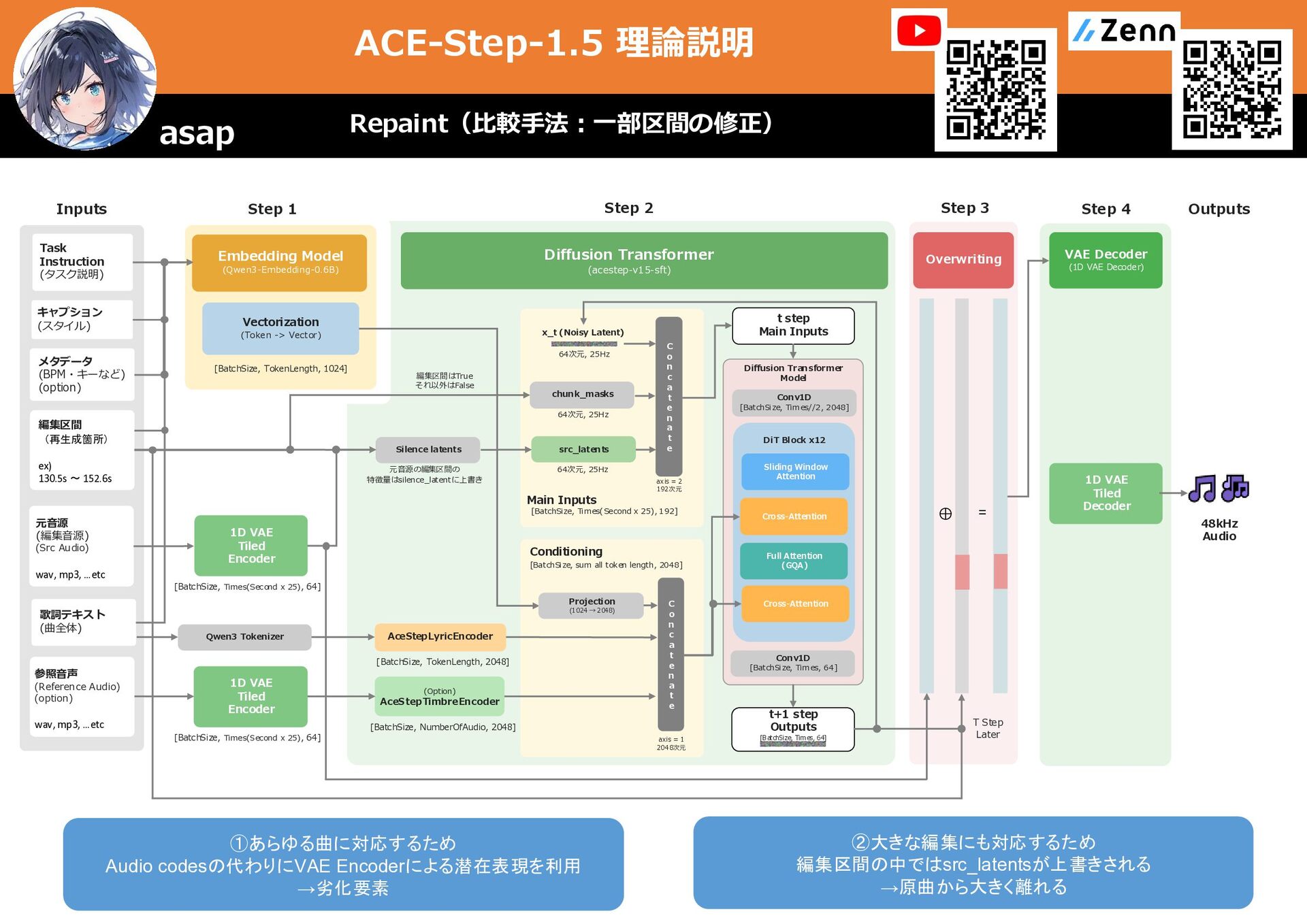
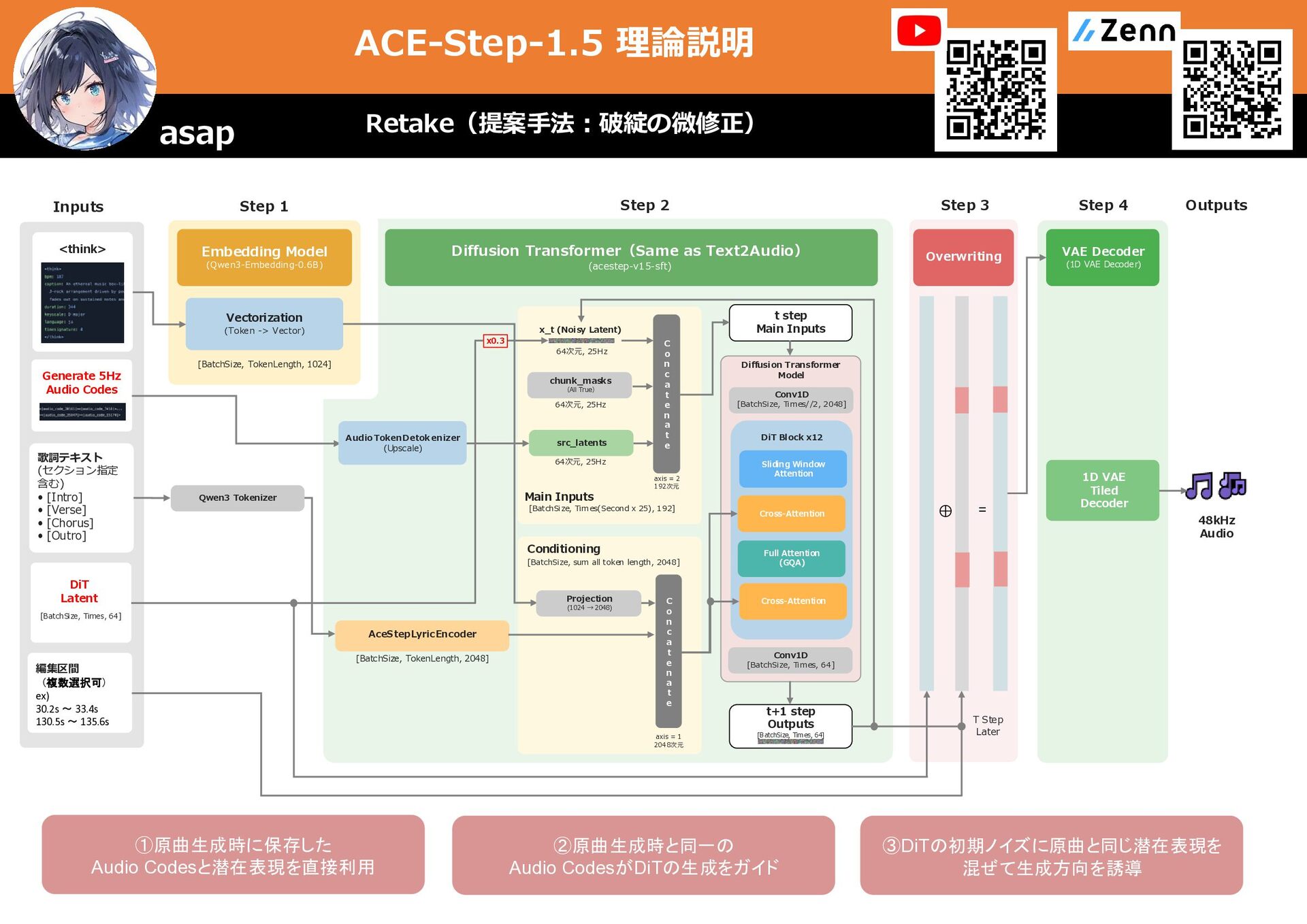
キャプション (スタイル) メタデータ (BPM・キーなど) (option) Diffusion Transformer (acestep-v15-sft) Main Inputs [BatchSize, Times(Second x 25), 192] 64次元, 25Hz chunk_masks 64次元, 25Hz axis = 2 192次元 Conditioning [BatchSize, sum all token length, 2048] AceStepLyricEncoder [BatchSize, NumberOfAudio, 2048] (Option) AceStepTimbreEncoder [BatchSize, TokenLength, 2048] VAE Decoder (1D VAE Decoder) 1D VAE Tiled Decoder 参照音声 (Reference Audio) (option) wav, mp3, …etc 歌詞テキスト (曲全体) Task Instruction (タスク説明) Embedding Model (Qwen3-Embedding-0.6B) Vectorization (Token -> Vector) [BatchSize, TokenLength, 1024] C o n c a t e n a t e C o n c a t e n a t e x_t (Noisy Latent) 64次元, 25Hz src_latents t step Main Inputs t+1 step Outputs [BatchSize, Times, 64] Projection (1024 → 2048) axis = 1 2048次元 Qwen3 Tokenizer 1D VAE Tiled Encoder [BatchSize, Times(Second x 25), 64] Conv1D [BatchSize, Times//2, 2048] DiT Block x12 Sliding Window Attention Full Attention (GQA) Cross-Attention Diffusion Transformer Model Cross-Attention Conv1D [BatchSize, Times, 64] 48kHz Audio 編集区間 (再生成箇所) ex) 130.5s 〜 152.6s 元音源 (編集音源) (Src Audio) wav, mp3, …etc 1D VAE Tiled Encoder [BatchSize, Times(Second x 25), 64] 編集区間はTrue それ以外はFalse Silence latents T Step Later ⊕ = Overwriting Step 3 元音源の編集区間の 特徴量はsilence_latentに上書き Repaint(比較手法:一部区間の修正) asap ①あらゆる曲に対応するため Audio codesの代わりにVAE Encoderによる潜在表現を利用 →劣化要素 ②大きな編集にも対応するため 編集区間の中ではsrc_latentsが上書きされる →原曲から大きく離れる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}