of Technology Stockholm, Sweden Philipp Haller Joint work with Jonas Spenger, Aleksey Veresov, and Paris Carbone Technical University of Denmark, Copenhagen, Denmark, Nov 7, 2025
• Wide adoption in modern cloud infrastructure • Example: Apache Flink used to power thousands of streaming jobs at Uber and ByteDance • Other widely-used systems: Apache Spark, Google Dataflow, Azure Event Hubs • Essential: recovery from failures, as failures are to be expected in any long-running streaming job running on a large cluster of computers • Problem: failure recovery is difficult! • Failure recovery protocols must balance efficiency and reliability • As a result, practical failure recovery protocols are complex The correctness of failure recovery protocols is a crucial problem for the reliability of stateful dataflow systems!
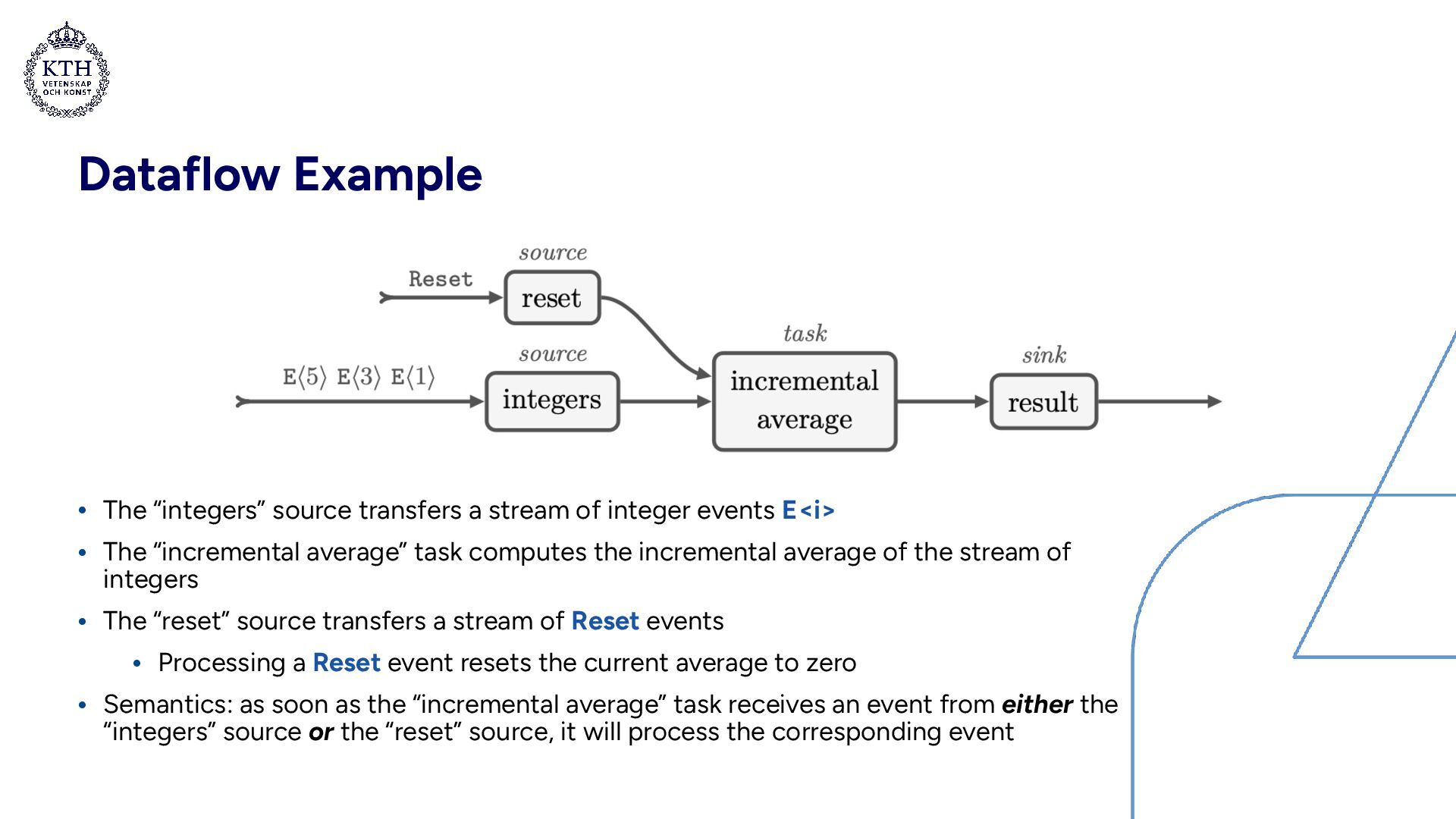
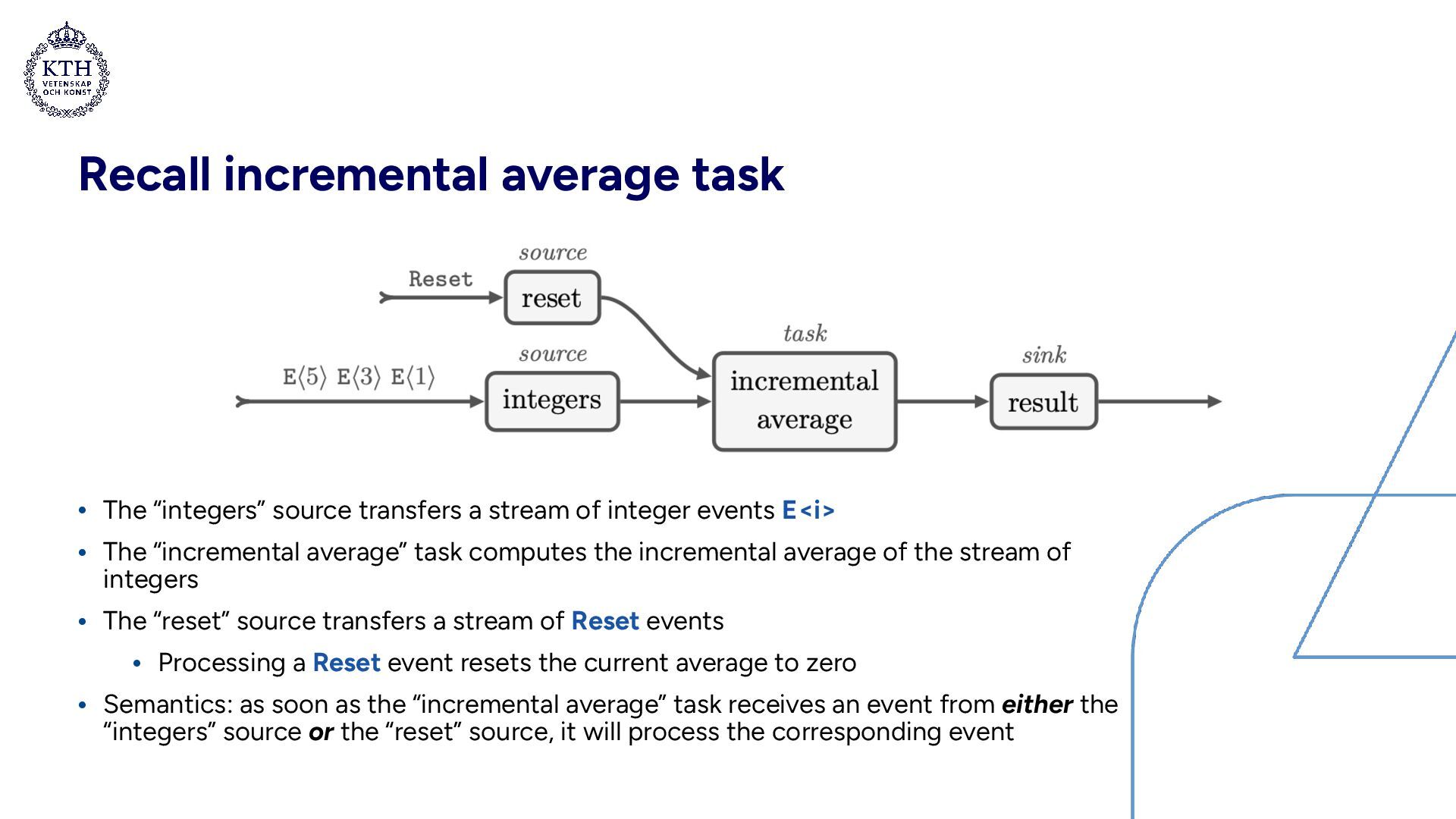
integer events E<i> • The “incremental average” task computes the incremental average of the stream of integers • The “reset” source transfers a stream of Reset events • Processing a Reset event resets the current average to zero • Semantics: as soon as the “incremental average” task receives an event from either the “integers” source or the “reset” source, it will process the corresponding event
• Failures: assumptions common to asynchronous distributed systems [CGR11] • Failures are assumed to be crash-recovery failures: a node loses its volatile state when crashing • We assume the existence of an eventually perfect failure detector, which is used for (eventually) triggering the recovery. • System components (all found in production dataflow systems): • Failure-free coordinator implemented using a distributed consensus protocol such as Paxos • Snapshot storage is assumed to be persistent and durable, e.g., provided by HDFS • The input to the dataflow graph is assumed to be logged such that it can be replayed upon failure, using a durable log system such as Kafka [CGR11] Christian Cachin, Rachid Guerraoui, and Luís E. T. Rodrigues. Introduction to Reliable and Secure Distributed Programming (2. ed.). Springer, 2011
Barrier Snapshotting [CEFHRT17] protocol within a stateful dataflow system, as used in Apache Flink • A novel definition of failure transparency for programming models expressed in small-step operational semantics with explicit failure rules • The first definition of failure transparency for stateful dataflow systems • A proof that the implementation model is failure transparent and guarantees liveness • A mechanization of the definitions, theorems, and models in Rocq [CEFHRT17] Paris Carbone, Stephan Ewen, Gyula Fóra, Seif Haridi, Stefan Richter, Kostas Tzoumas: State Management in Apache Flink®: Consistent Stateful Distributed Stream Processing. Proc. VLDB Endow. 10(12): 1718-1729 (2017)
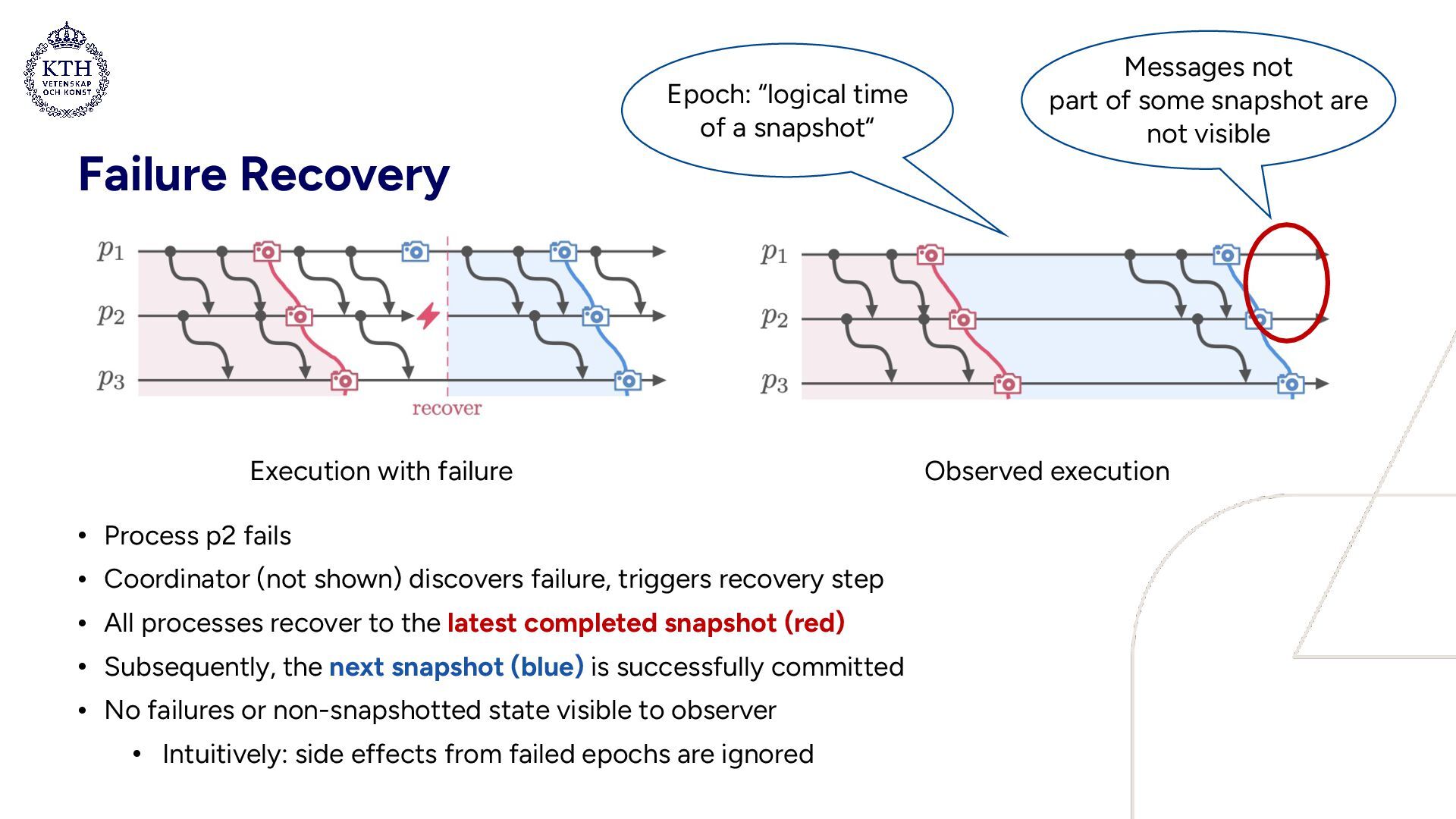
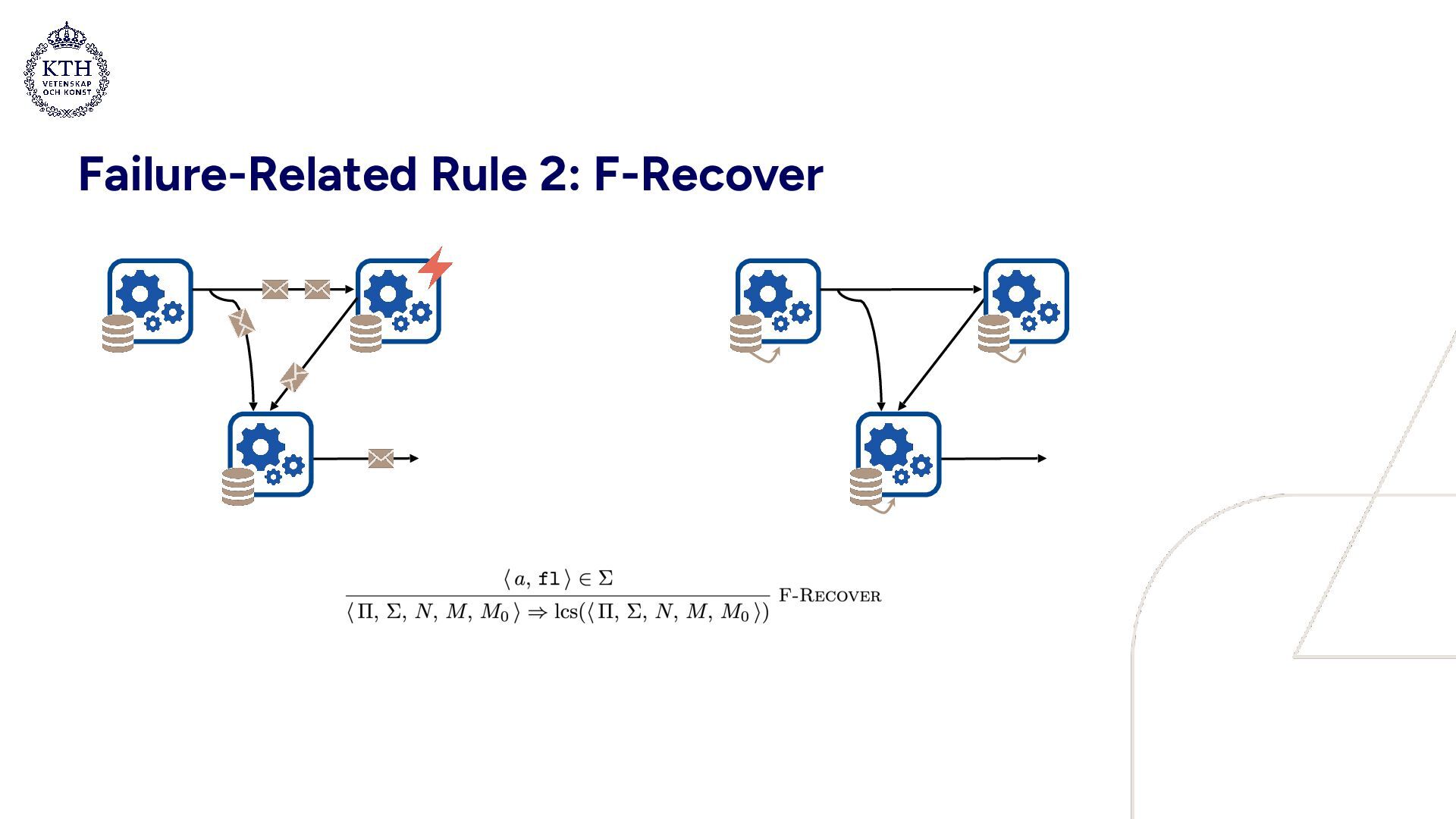
discovers failure, triggers recovery step • All processes recover to the latest completed snapshot (red) • Subsequently, the next snapshot (blue) is successfully committed • No failures or non-snapshotted state visible to observer • Intuitively: side effects from failed epochs are ignored Execution with failure Observed execution Epoch: “logical time of a snapshot“ Messages not part of some snapshot are not visible
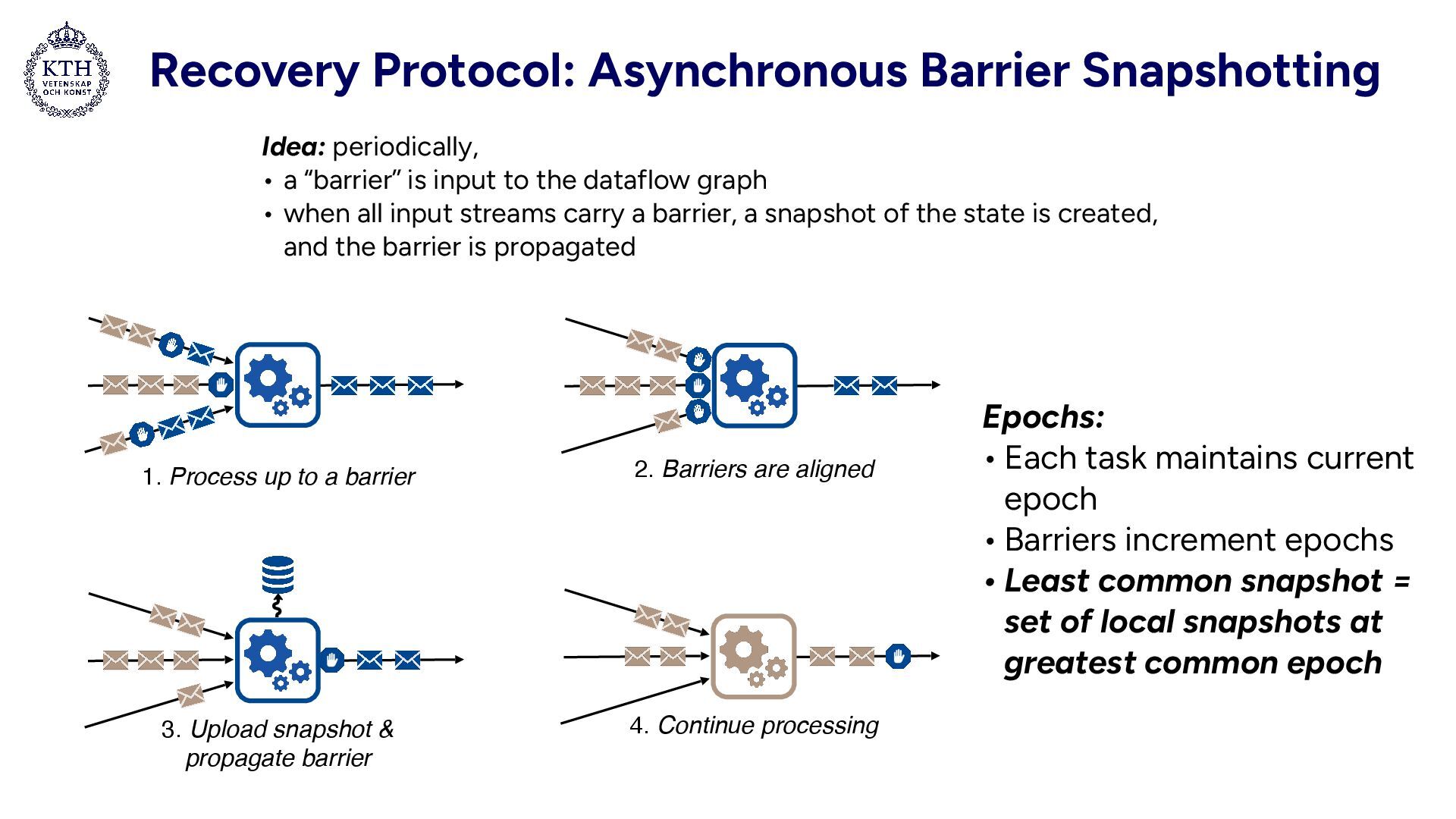
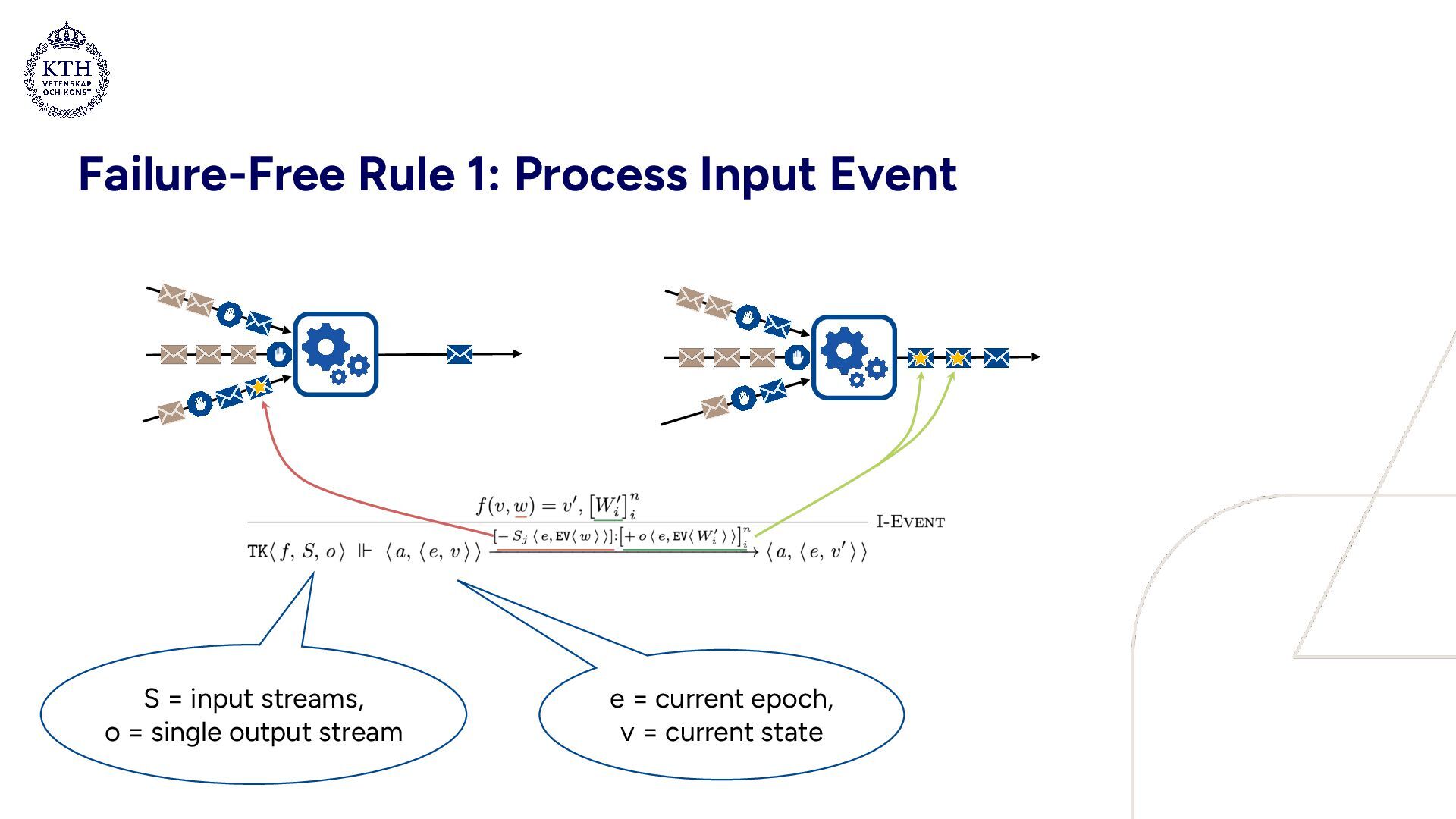
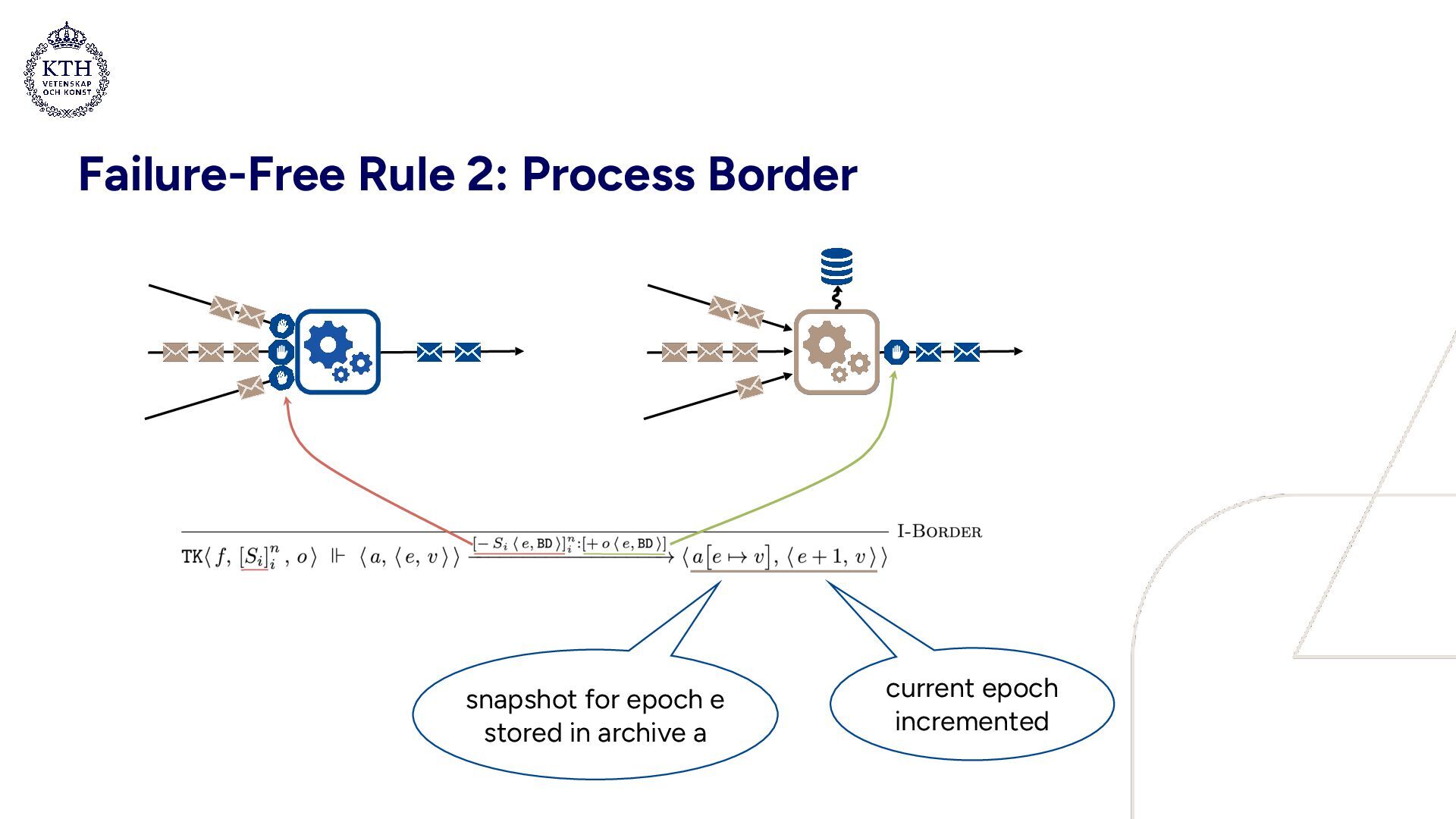
barrier 2. Barriers are aligned 3. Upload snapshot & propagate barrier 4. Continue processing Idea: periodically, • a “barrier” is input to the dataflow graph • when all input streams carry a barrier, a snapshot of the state is created, and the barrier is propagated Epochs: • Each task maintains current epoch • Barriers increment epochs • Least common snapshot = set of local snapshots at greatest common epoch
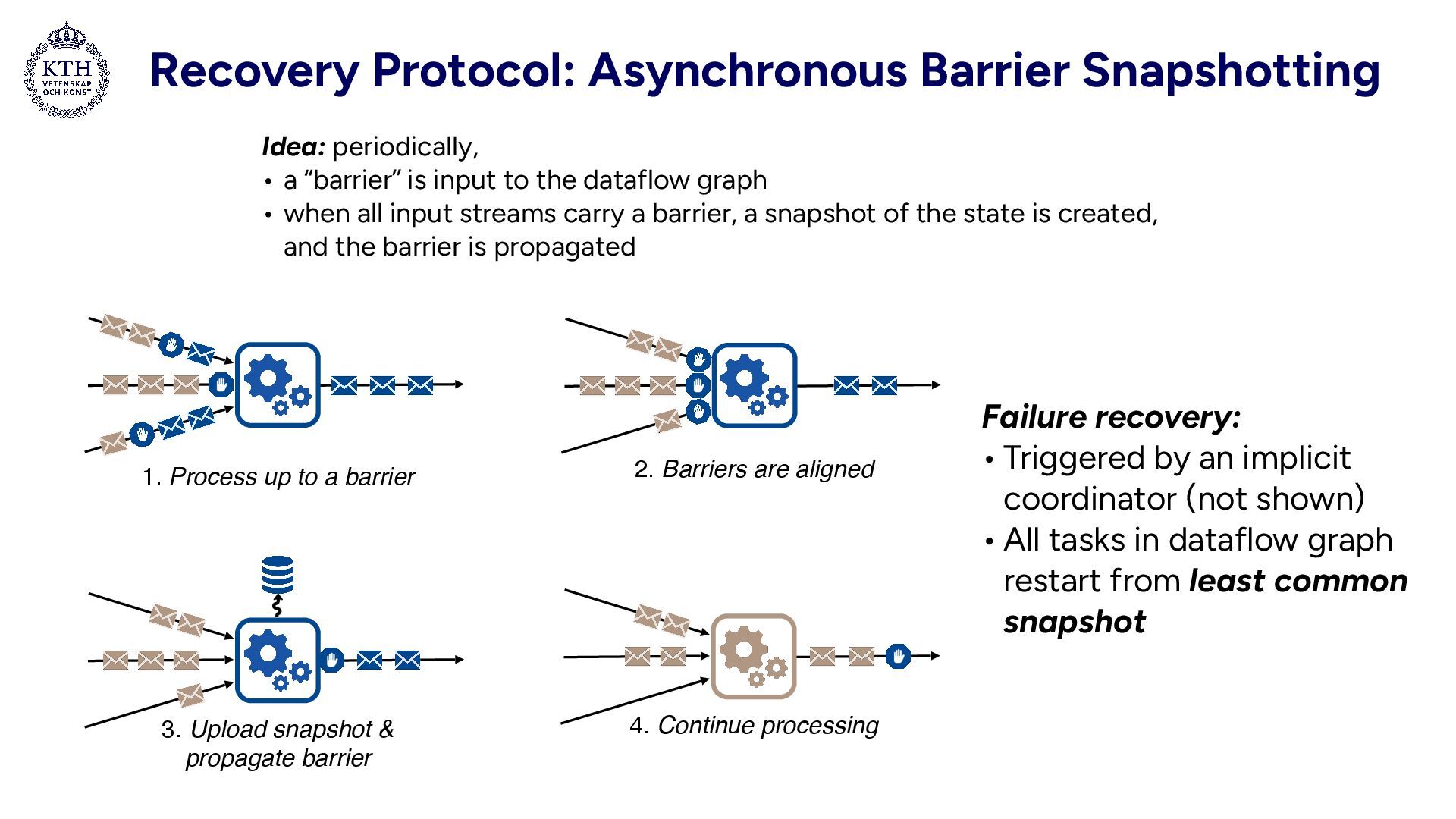
barrier 2. Barriers are aligned 3. Upload snapshot & propagate barrier 4. Continue processing Idea: periodically, • a “barrier” is input to the dataflow graph • when all input streams carry a barrier, a snapshot of the state is created, and the barrier is propagated Failure recovery: • Triggered by an implicit coordinator (not shown) • All tasks in dataflow graph restart from least common snapshot
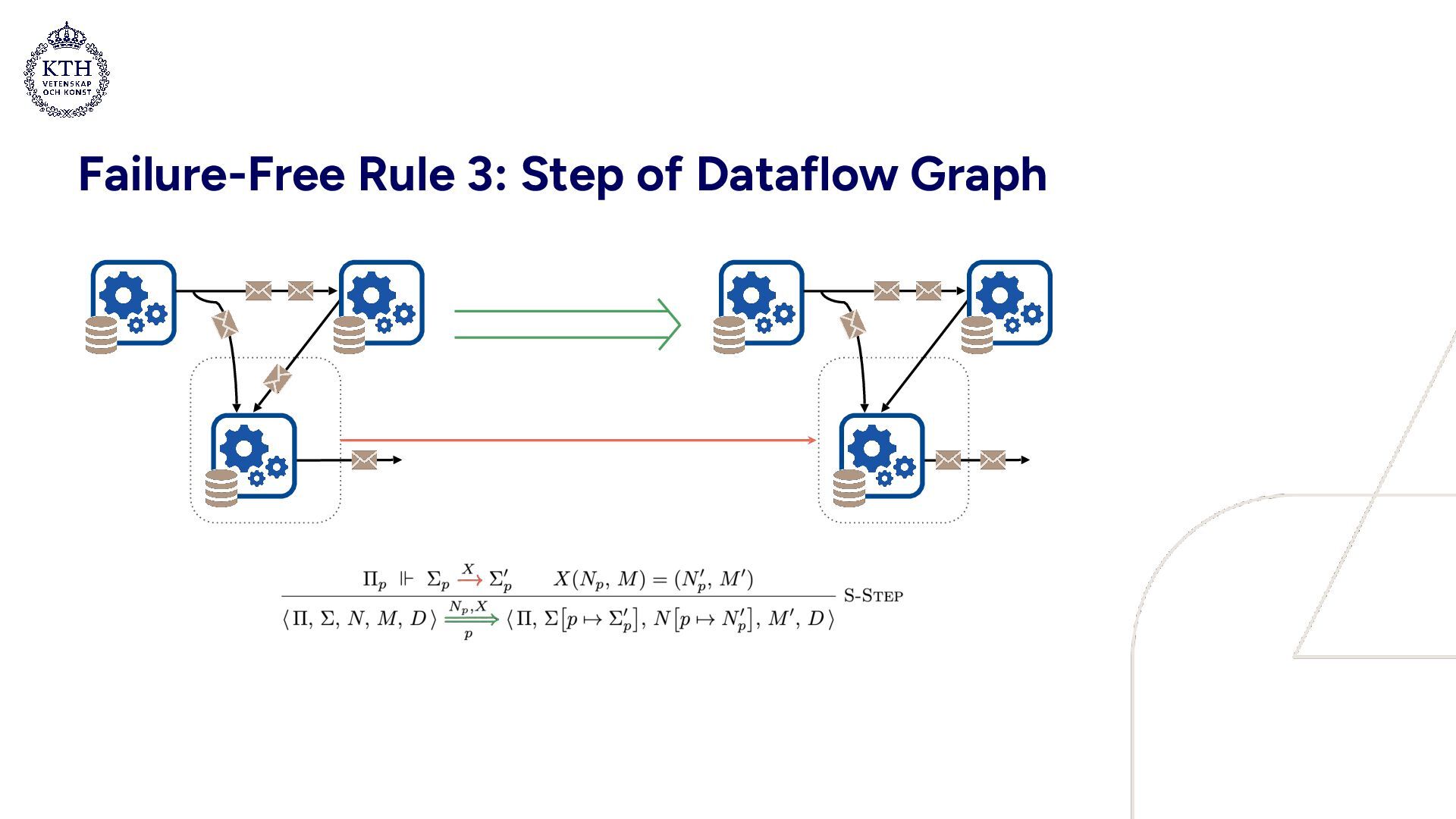
• Well suited for modeling concurrent systems • A compact set of evaluation rules: • 3 rules describe a failure-free system • 2 rules are related to failures • 2 rules are auxiliary
stream of integer events E<i> • The “incremental average” task computes the incremental average of the stream of integers • The “reset” source transfers a stream of Reset events • Processing a Reset event resets the current average to zero • Semantics: as soon as the “incremental average” task receives an event from either the “integers” source or the “reset” source, it will process the corresponding event
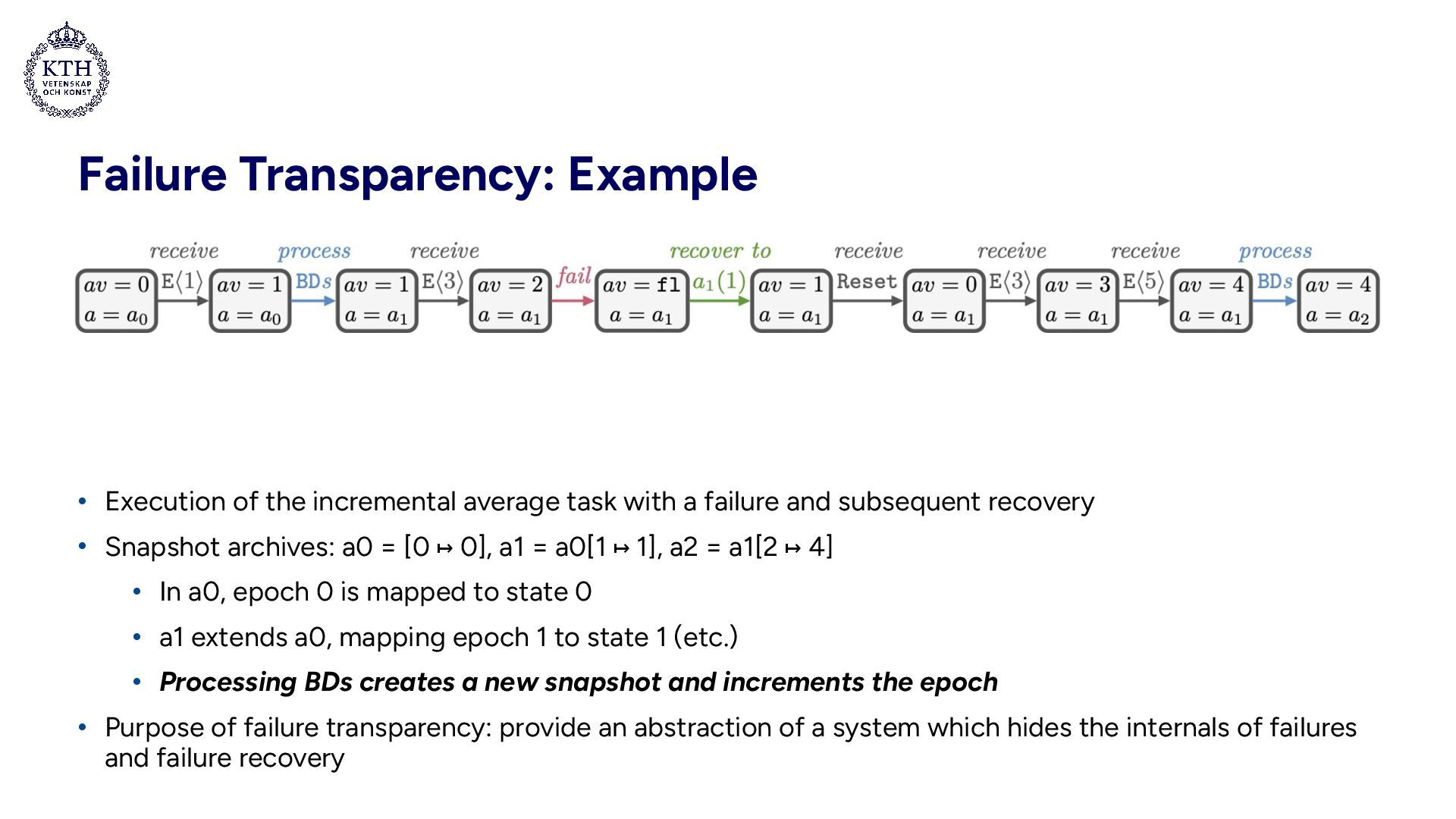
with a failure and subsequent recovery • Snapshot archives: a0 = [0 ↦ 0], a1 = a0[1 ↦ 1], a2 = a1[2 ↦ 4] • In a0, epoch 0 is mapped to state 0 • a1 extends a0, mapping epoch 1 to state 1 (etc.) • Processing BDs creates a new snapshot and increments the epoch • Purpose of failure transparency: provide an abstraction of a system which hides the internals of failures and failure recovery
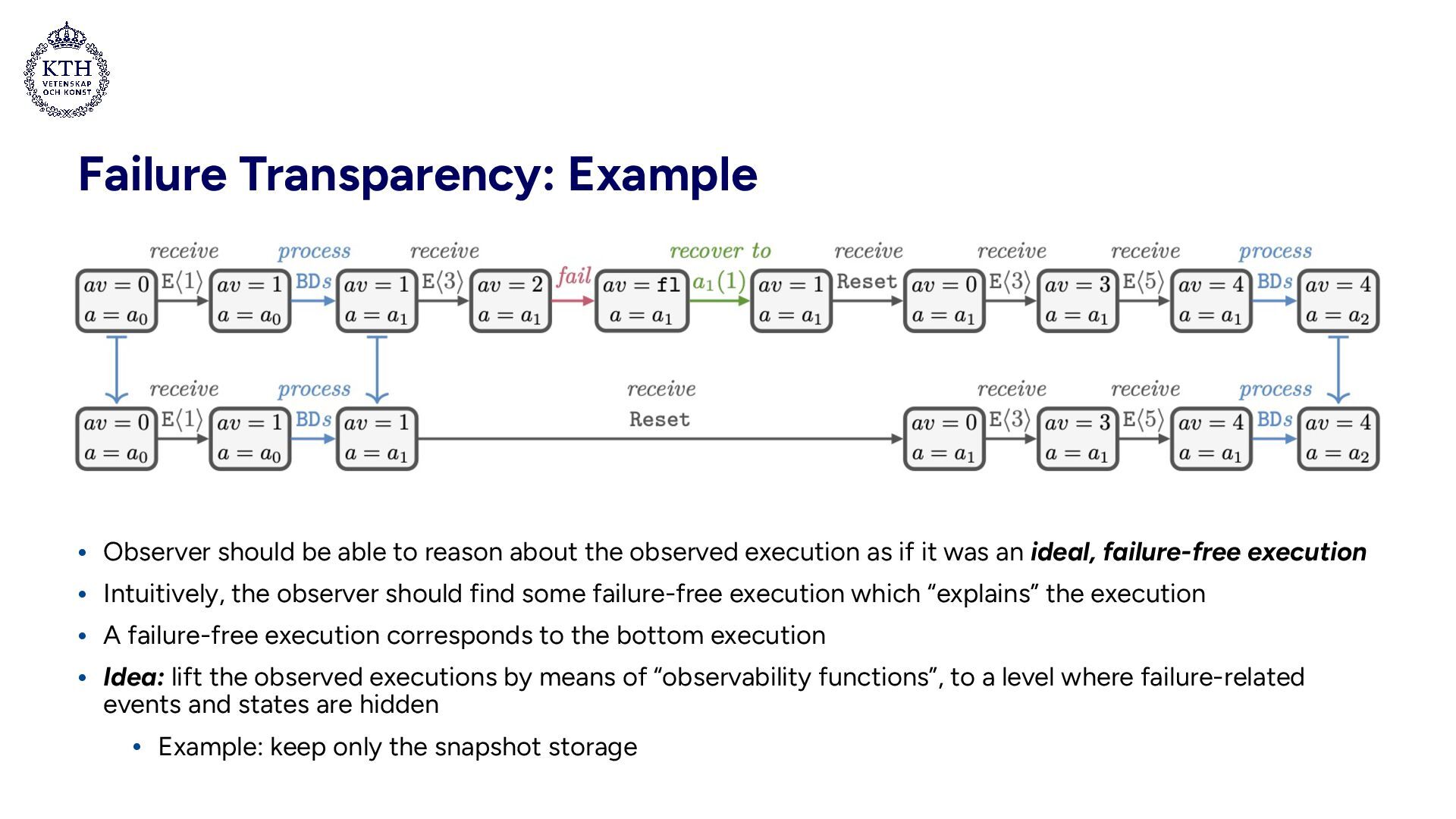
about the observed execution as if it was an ideal, failure-free execution • Intuitively, the observer should find some failure-free execution which “explains” the execution • A failure-free execution corresponds to the bottom execution • Idea: lift the observed executions by means of “observability functions”, to a level where failure-related events and states are hidden • Example: keep only the snapshot storage
model is failure transparent • We prove liveness of the implementation model • The implementation model eventually produces outputs for all epochs in its input • Discussion of related work on failure transparency, failure transparency proofs, resilient distributed programming models, and failure recovery Aleksey Veresov, Jonas Spenger, Paris Carbone, Philipp Haller: Failure Transparency in Stateful Dataflow Systems. ECOOP 2024: 42:1-42:31
correct services with low effort • However, restricted in expressiveness: directed, acyclic graphs of tasks • Actor concurrency model lifts this restriction: • Cyclic, dynamic communication graphs • Widely used for building reliable services • Industrial adoption, examples: • Telecom services with Erlang at Ericsson [Armstrong86] • Messaging services with Erlang at WhatsApp [EST18] • Social media with Scala Actors at Twitter/X [Mok09]
services: • Hierarchical actor supervision (Erlang, Akka) • Event sourcing, etc. • Libraries (Erlang/OTP) • Handling failures is the user's responsibility (although libraries help) • Missing: a failure-transparent actor programming model
actors; (ii) send messages to other actors • Actors never fail • Actors are failure-transparent • Implementation: • Actors can fail • Failure = crash-recovery failure: • Actor loses volatile state and restarts Goal: proof of failure transparency of the implementation with respect to the specification
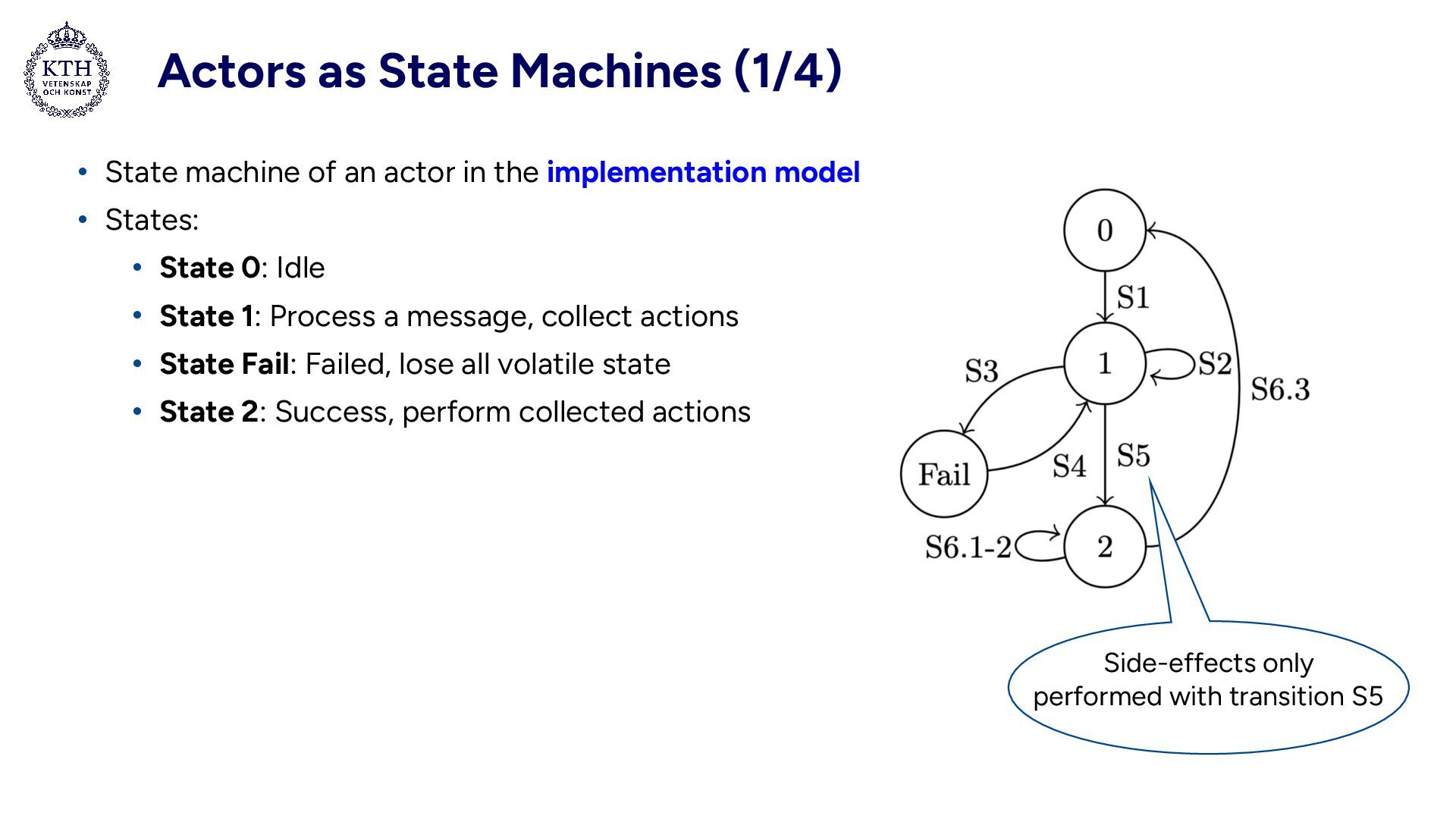
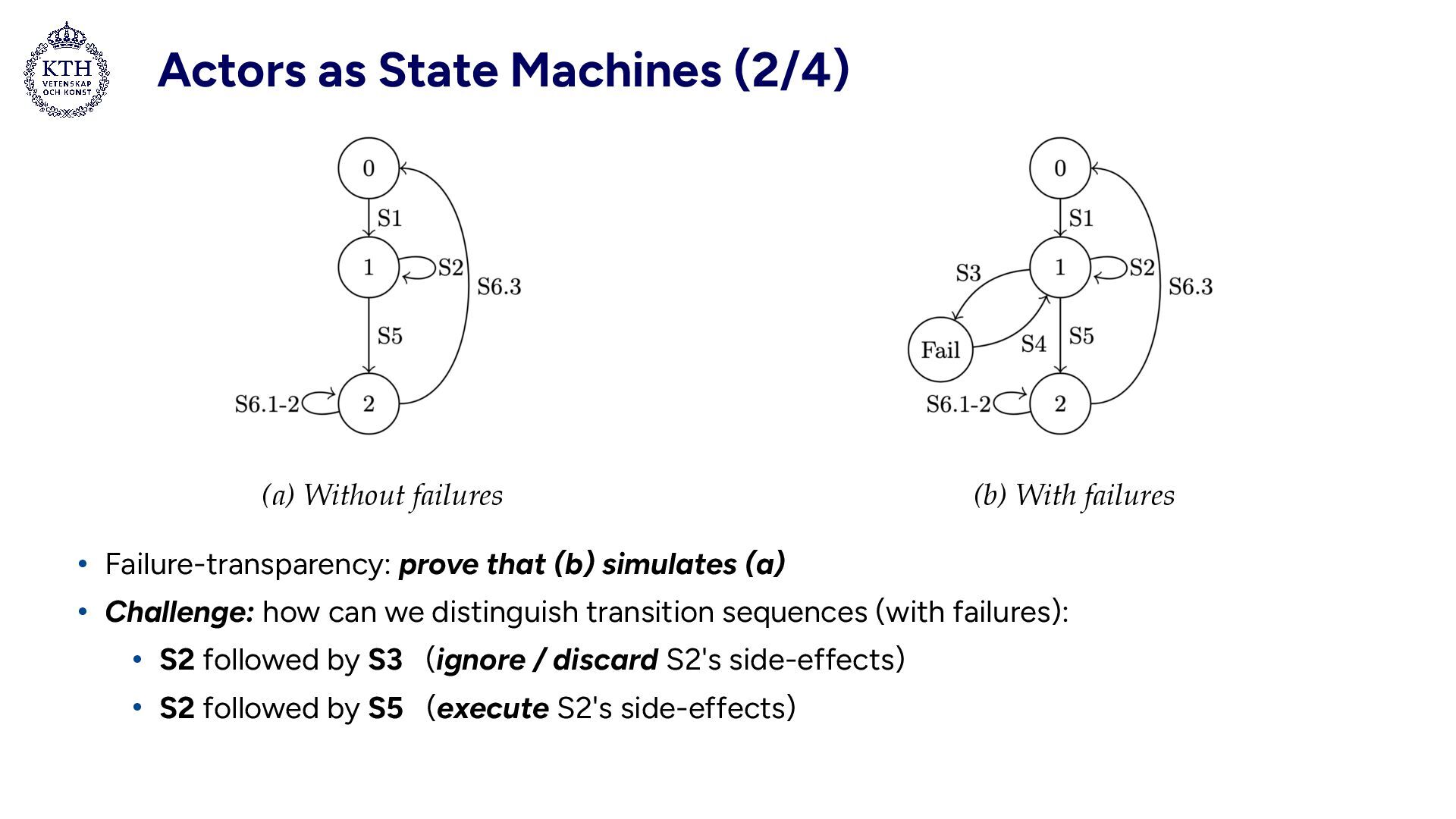
actor in the implementation model • States: • State 0: Idle • State 1: Process a message, collect actions • State Fail: Failed, lose all volatile state • State 2: Success, perform collected actions Side-effects only performed with transition S5
simulates (a) • Challenge: how can we distinguish transition sequences (with failures): • S2 followed by S3 (ignore / discard S2's side-effects) • S2 followed by S5 (execute S2's side-effects) (a) Without failures (b) With failures
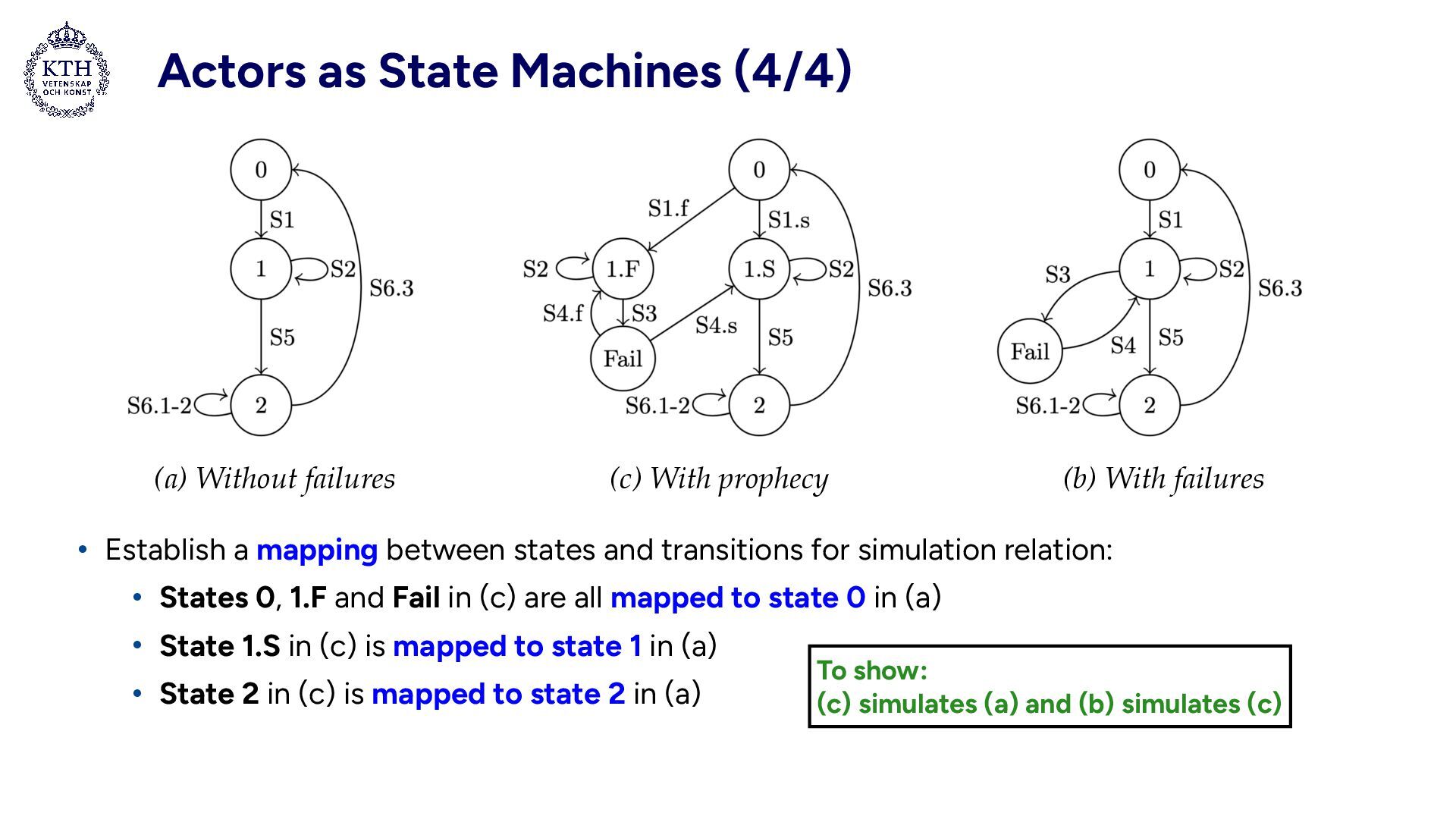
• Represent if execution will • (.F) Fail/Recover • (.S) Succeed (c) With prophecy (a) Without failures (b) With failures Leslie Lamport, Stephan Merz: Prophecy Made Simple. ACM Trans. Program. Lang. Syst. 44(2): 6:1-6:27 (2022)
states and transitions for simulation relation: • States 0, 1.F and Fail in (c) are all mapped to state 0 in (a) • State 1.S in (c) is mapped to state 1 in (a) • State 2 in (c) is mapped to state 2 in (a) (c) With prophecy (a) Without failures (b) With failures To show: (c) simulates (a) and (b) simulates (c)
extend failure-transparency from stateful dataflow streaming to the actor model • We present a proof of failure transparency by showing that the implementation model using prophecy variables simulates the failure-free specification model • Prototype implementation available at: https://github.com/jspenger/ durable-actor • Paper: Jonas Spenger, Paris Carbone, Philipp Haller: Failure-Transparent Actors. In: Meseguer, J., Varela, C.A., Venkatasubramanian, N. (eds) Concurrent Programming, Open Systems and Formal Methods: Essays Dedicated to Gul Agha to Celebrate His Scientific Career. LNCS, vol. 16120: 81-113. Springer, 2025.
Barrier Snapshotting protocol within a stateful dataflow system, as used in Apache Flink • A novel definition of failure transparency for programming models expressed in small-step operational semantics with explicit failure rules • The first definition of failure transparency for stateful dataflow systems • A proof that the provided implementation model is failure transparent and guarantees liveness • Failure-transparent actors is a proposal to extend failure-transparency from stateful dataflow streaming to the actor model Jonas Spenger, Paris Carbone, Philipp Haller: Failure-Transparent Actors. In: Meseguer, J., Varela, C.A., Venkatasubramanian, N. (eds) Concurrent Programming, Open Systems and Formal Methods: Essays Dedicated to Gul Agha to Celebrate His Scientific Career. LNCS, vol. 16120: 81-113. Springer, 2025. Aleksey Veresov, Jonas Spenger, Paris Carbone, Philipp Haller: Failure Transparency in Stateful Dataflow Systems. ECOOP 2024: 42:1-42:31
Rodrigues. Introduction to Reliable and Secure Distributed Programming (2. ed.). Springer, 2011 [CEFHRT17] Paris Carbone, Stephan Ewen, Gyula Fóra, Seif Haridi, Stefan Richter, Kostas Tzoumas: State Management in Apache Flink®: Consistent Stateful Distributed Stream Processing. Proc. VLDB Endow. 10(12): 1718-1729 (2017) [VSCH24] Aleksey Veresov, Jonas Spenger, Paris Carbone, Philipp Haller: Failure Transparency in Stateful Dataflow Systems. ECOOP 2024: 42:1-42:31 [LM22] Leslie Lamport, Stephan Merz: Prophecy Made Simple. ACM Trans. Program. Lang. Syst. 44(2): 6:1-6:27 (2022) [SCH25] Jonas Spenger, Paris Carbone, Philipp Haller: Failure-Transparent Actors. In: Meseguer, J., Varela, C.A., Venkatasubramanian, N. (eds) Concurrent Programming, Open Systems and Formal Methods: Essays Dedicated to Gul Agha to Celebrate His Scientific Career. LNCS, vol. 16120: 81-113. Springer, 2025. [Armstrong96] Armstrong, Joe.: Erlang—a Survey of the Language and its Industrial Applications. Proc. INAP. Vol. 96. 1996. [Mok09] Waiming Mok. "How Twitter is Scaling." https://waimingmok.wordpress.com/2009/06/27/how-twitter-is- scaling/ [EST18] Erlang Solutions Team. "20 Years of Open Source Erlang: OpenErlang Interview with Anton Lavrik from WhatsApp." https://www.erlang-solutions.com/blog/20-years-of-open-source-erlang-openerlang-interview-with- anton-lavrik-from-whatsapp/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Actors as State Machines (3/4) • Introduce ”Prophecy variables” [LM22]](https://files.speakerdeck.com/presentations/8ff73764bbab41ffb512906aa1225657/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [CGR11] Christian Cachin, Rachid Guerraoui, and Luís E. T.](https://files.speakerdeck.com/presentations/8ff73764bbab41ffb512906aa1225657/slide_30.jpg){kind=link}