Institute of Technology Stockholm, Sweden Philipp Haller Joint work with Xin Zhao, Jonas Spenger, Aleksey Veresov, Kolya Krafeld, Ruben van Gemeren, and Paris Carbone University of California, Santa Cruz, California, USA, April 29, 2026
systems • And how to ensure their safety through programming systems • Here, resiliency = fault tolerance • Replication essential for implementing fault-tolerant distributed systems • Example: state machine replication • Coordination overhead of data replication • In general, ensuring consistency of replicas requires consensus protocols such as Paxos or Raft • Consensus protocols require message passing among replicas and synchronous storage flushes*) • Client requests must wait for consensus rounds to complete which reduces throughput and increases latency • Especially in geo-distributed systems *) In some systems synchronous flushing can be avoided by relying on surviving peers to provide state upon recovery.
which class of problems permits coordination-free implementations • Implementations provide low latency and high throughput • Problems outside this class require coordination • CALM theorem: limited to monotonic problems*) • Direction 2: introduce alternate consistency models that avoid coordination • Adds constraints → not sufficient for all problems • Direction 3: no coordination if possible, on-demand coordination when necessary *) Hellerstein and Alvaro. 2020. Keeping CALM: when distributed consistency is easy. Commun. ACM 63(9): 72-81 (2020) Li and Lee. 2025. A Preliminary Model of Coordination-free Consistency. arXiv:2504.01141
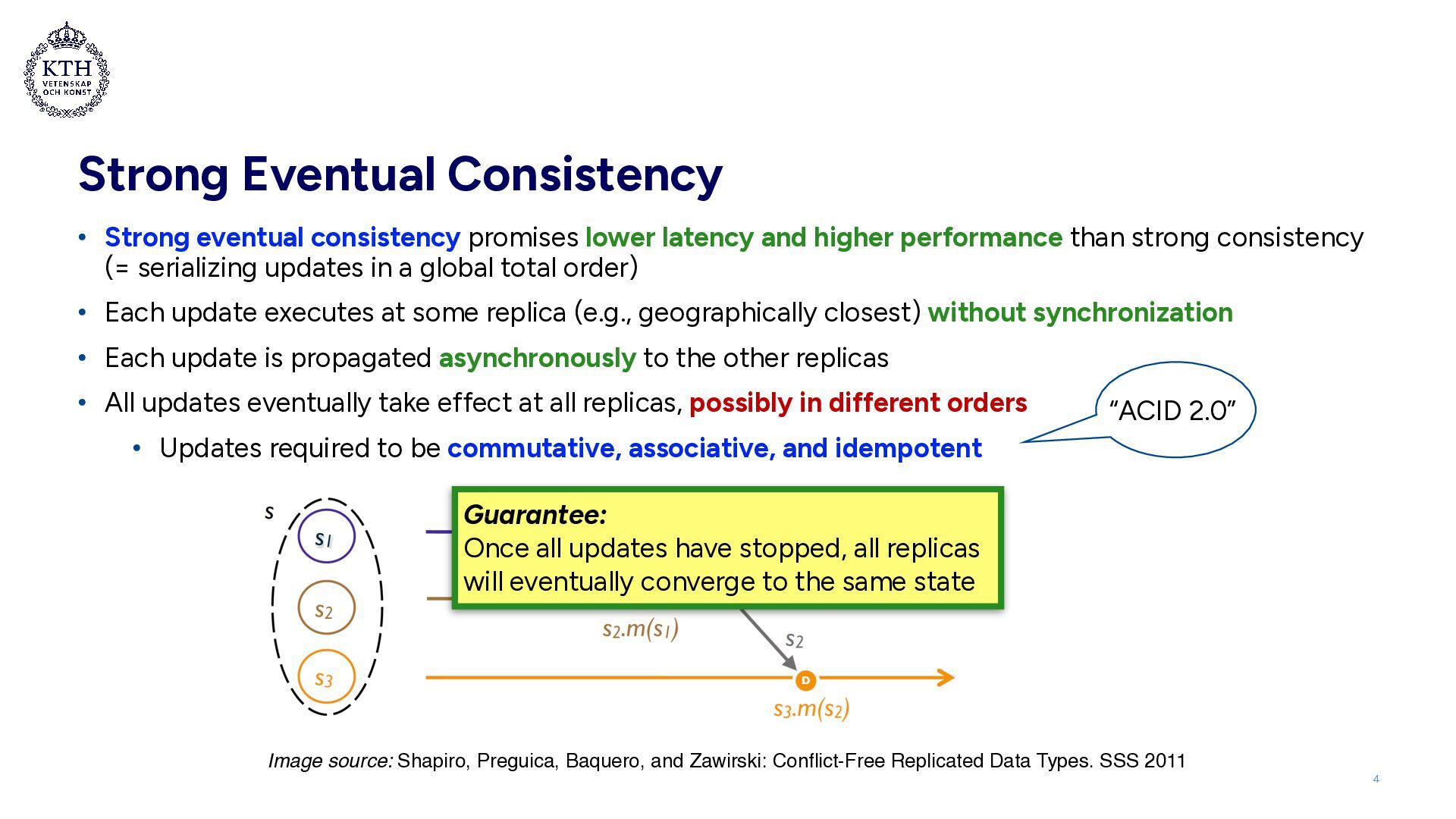
and higher performance than strong consistency (= serializing updates in a global total order) • Each update executes at some replica (e.g., geographically closest) without synchronization • Each update is propagated asynchronously to the other replicas • All updates eventually take effect at all replicas, possibly in different orders • Updates required to be commutative, associative, and idempotent 4 Image source: Shapiro, Preguica, Baquero, and Zawirski: Conflict-Free Replicated Data Types. SSS 2011 Guarantee: Once all updates have stopped, all replicas will eventually converge to the same state “ACID 2.0”
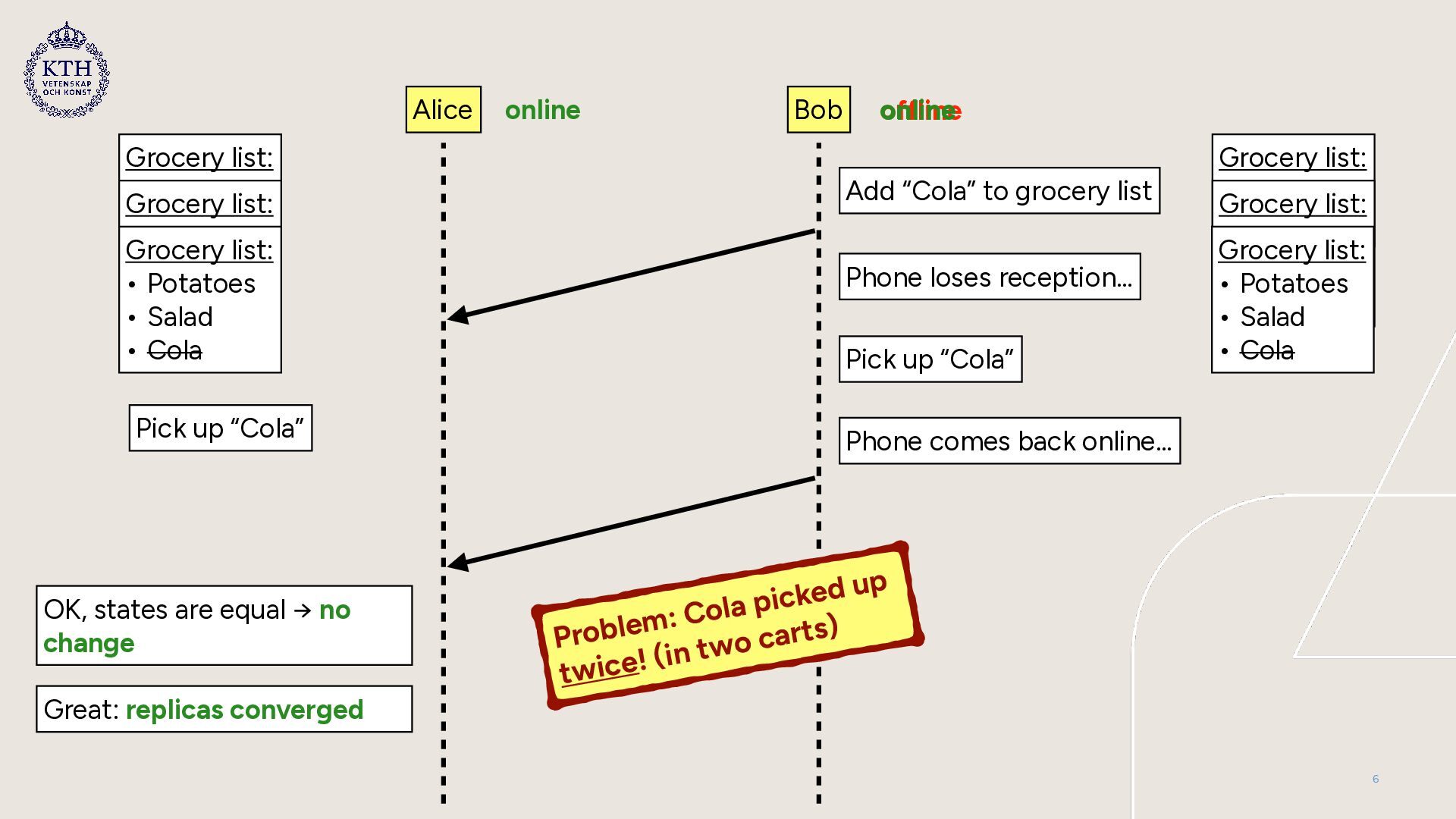
Idea: multiple users can edit the grocery list concurrently on their phones • Key feature: grocery list should support offline editing • Supported operations: • Add item to grocery list • Remove item from grocery list • Mark item as “picked up” 5
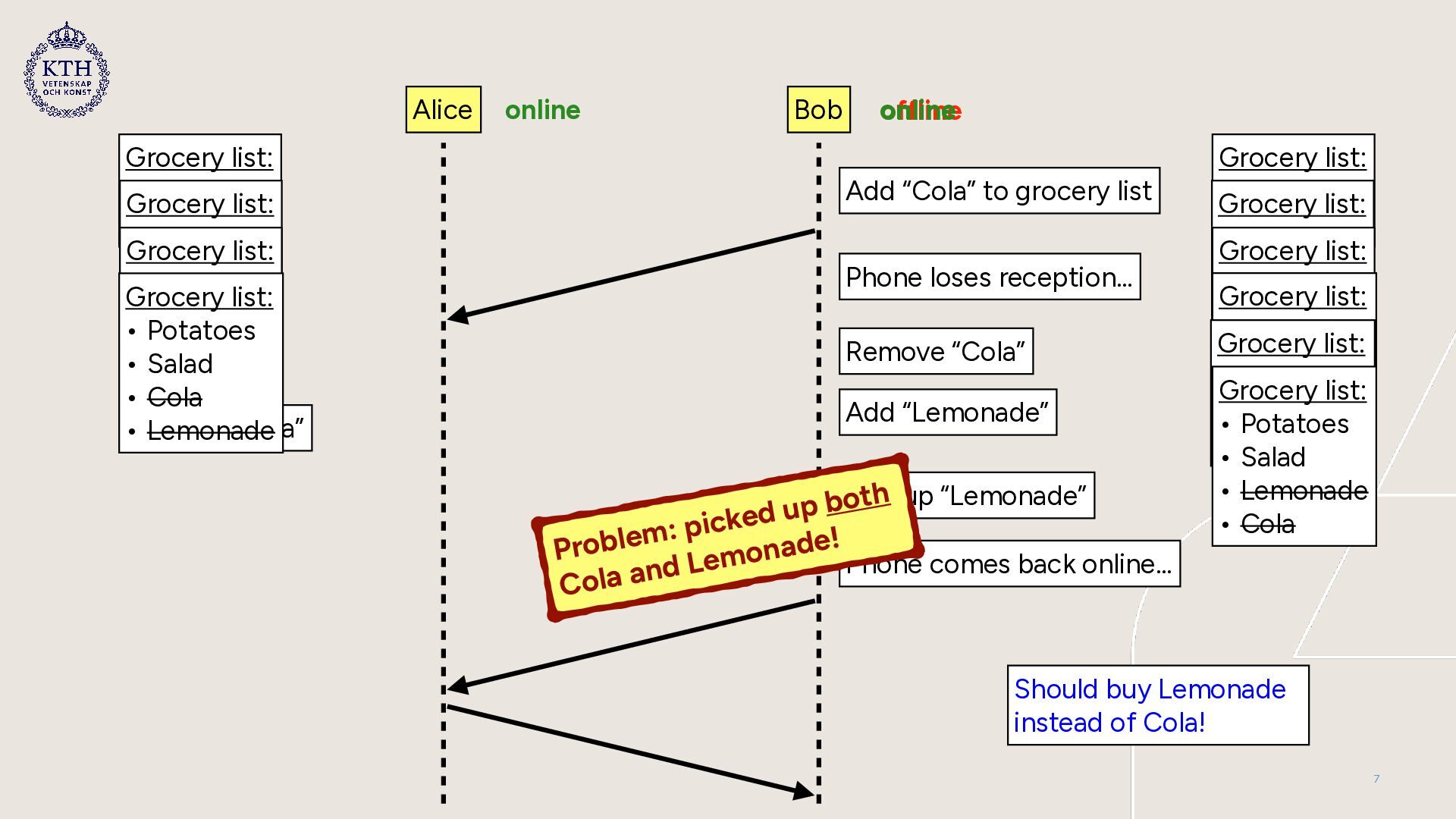
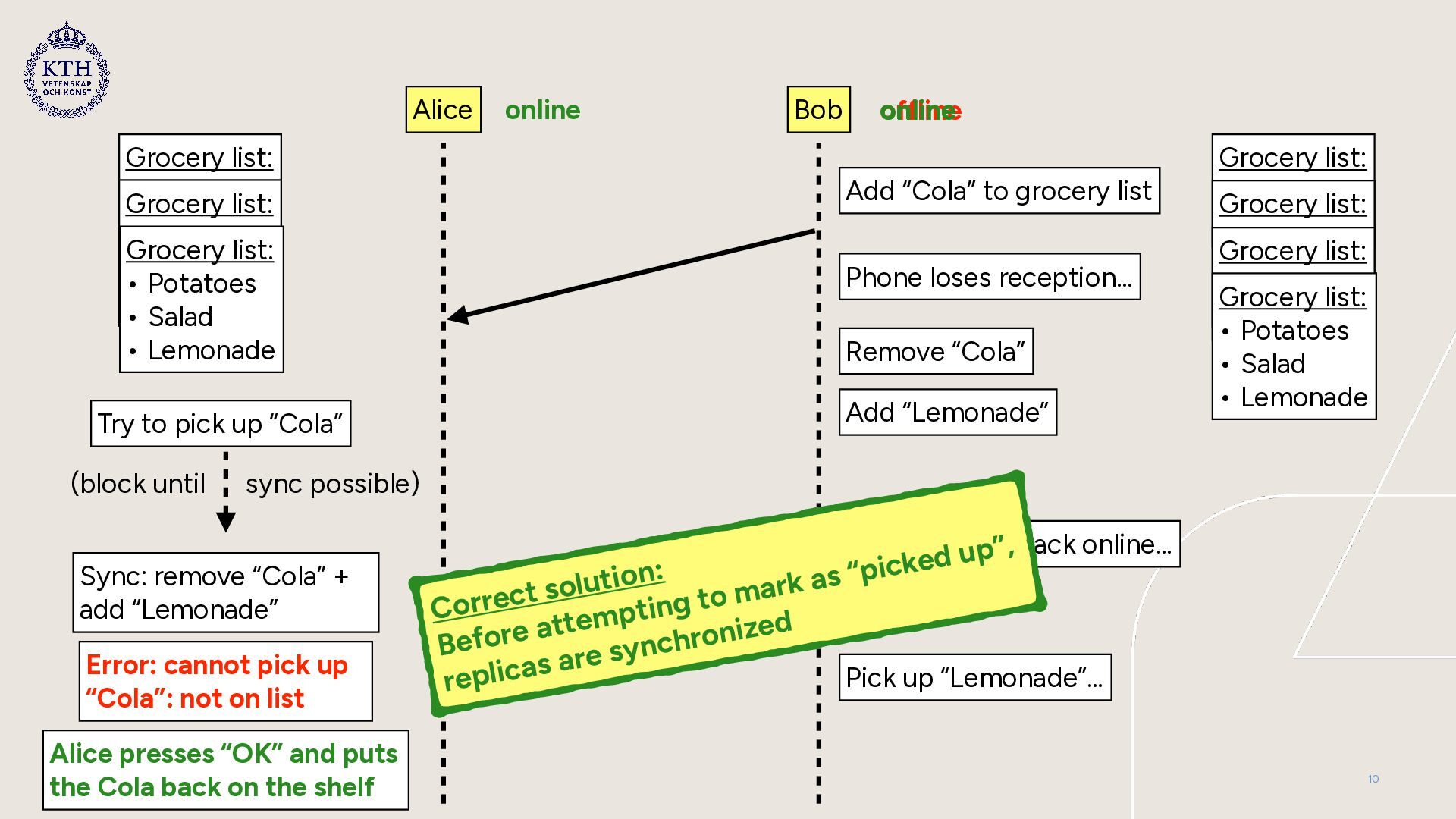
pick-ups while offline can lead to double pick-ups • Marking an item as “picked up” is problematic if lists out of sync • Possible disagreement about what should be picked up • Solution: • Make “pick up” a blocking operation that only works online • Force synchronization of all replicas → block until synchronized • Try to perform “pick-up” on all synchronized replicas 8
which class of problems permits coordination-free implementations • Implementations provide low latency and high throughput • Problems outside this class require coordination • CALM theorem: limited to monotonic problems*) • Direction 2: introduce alternate consistency models that avoid coordination • Adds constraints → not sufficient for all problems • Direction 3: no coordination if possible, on-demand coordination when necessary *) Hellerstein and Alvaro. 2020. Keeping CALM: when distributed consistency is easy. Commun. ACM 63(9): 72-81 (2020) Li and Lee. 2025. A Preliminary Model of Coordination-free Consistency. arXiv:2504.01141
Potatoes • Salad Grocery list: • Potatoes • Salad online online Grocery list: • Potatoes • Salad • Cola Grocery list: • Potatoes • Salad • Cola Phone loses reception… offline Remove “Cola” Add “Lemonade” Grocery list: • Potatoes • Salad Grocery list: • Potatoes • Salad • Lemonade Phone comes back online… online Try to pick up “Cola” Sync: remove “Cola” + add “Lemonade” Error: cannot pick up “Cola”: not on list Alice presses “OK” and puts the Cola back on the shelf Pick up “Lemonade”… Correct solution: Before attempting to mark as “picked up”, replicas are synchronized (block until sync possible) Grocery list: • Potatoes • Salad • Lemonade 10
based on Conflict-Free Replicated Data Types (CRDTs) • Extend CRDTs with on-demand sequential consistency • Add support for sequentially consistent operations • Don’t have to be commutative! • Define a consistency model and a distributed protocol that enforces the consistency model → Observable Atomic Consistency Protocol (OACP) 11
(RDT) storing values of a lattice • Example 1: lattice = natural numbers where join(x, y) = max(x, y) • Example 2: lattice = subset lattice where join(x, y) = x.union(y) • Operations with different consistency levels: • A totally-ordered operation (“TOp”) atomically: • synchronizes the replicas; and • applies the operation to the state of each replica. • A convergent operation (“CvOp”) is commutative, associative, and idempotent, and is processed without coordination. • Let’s have a look at an example… E.g., using distributed consensus (Paxos, Raft, …) Actually, a join- semilattice 12
(OAC) model • A mechanized model of OACP implemented using Maude model checker with checked properties: • the state of all replicas is made consistent upon executing a totally- ordered operation; • the protocol preserves the order defined by OAC. • An experimental evaluation including latency, throughput, coordination overhead, and scalability Xin Zhao, Philipp Haller: Replicated data types that unify eventual consistency and observable atomic consistency. J. Log. Algebraic Methods Program. 114: 100561 (2020) https://doi.org/10.1016/j.jlamp.2020.100561 15
multiple consistency models within the same application is prone to catastrophic errors • Type system that distinguishes values according to their consistency • Proofs of (1) type soundness, (2) noninterference, and (3) consistency properties • Windowed CRDTs • Challenge in stream processing systems: how to efficiently scale global aggregations? • Approach: coordination-free updates of windows, precise reads once a global watermark of the stream processing pipeline indicates windows complete Xin Zhao, Philipp Haller: Consistency types for replicated data in a higher-order distributed programming language. Art Sci. Eng. Program. 5(2): 6 (2021) https://doi.org/10.22152/programming-journal.org/2021/5/6 Jonas Spenger, Kolya Krafeld, Ruben van Gemeren, Philipp Haller, Paris Carbone: Holon Streaming: Global Aggregations with Windowed CRDTs. CoRR abs/2510.25757 (2025) https://doi.org/10.48550/arXiv.2510.25757
• Wide adoption in modern cloud infrastructure • Example: Apache Flink used to power thousands of streaming jobs at Uber and ByteDance • Other widely-used systems: Apache Spark, Google Dataflow, Azure Event Hubs • Essential: recovery from failures, as failures are to be expected in any long-running streaming job running on a large cluster of computers • Problem: failure recovery is difficult! • Failure recovery protocols must balance efficiency and reliability • As a result, practical failure recovery protocols are complex The correctness of failure recovery protocols is a crucial problem for the reliability of stateful dataflow systems!
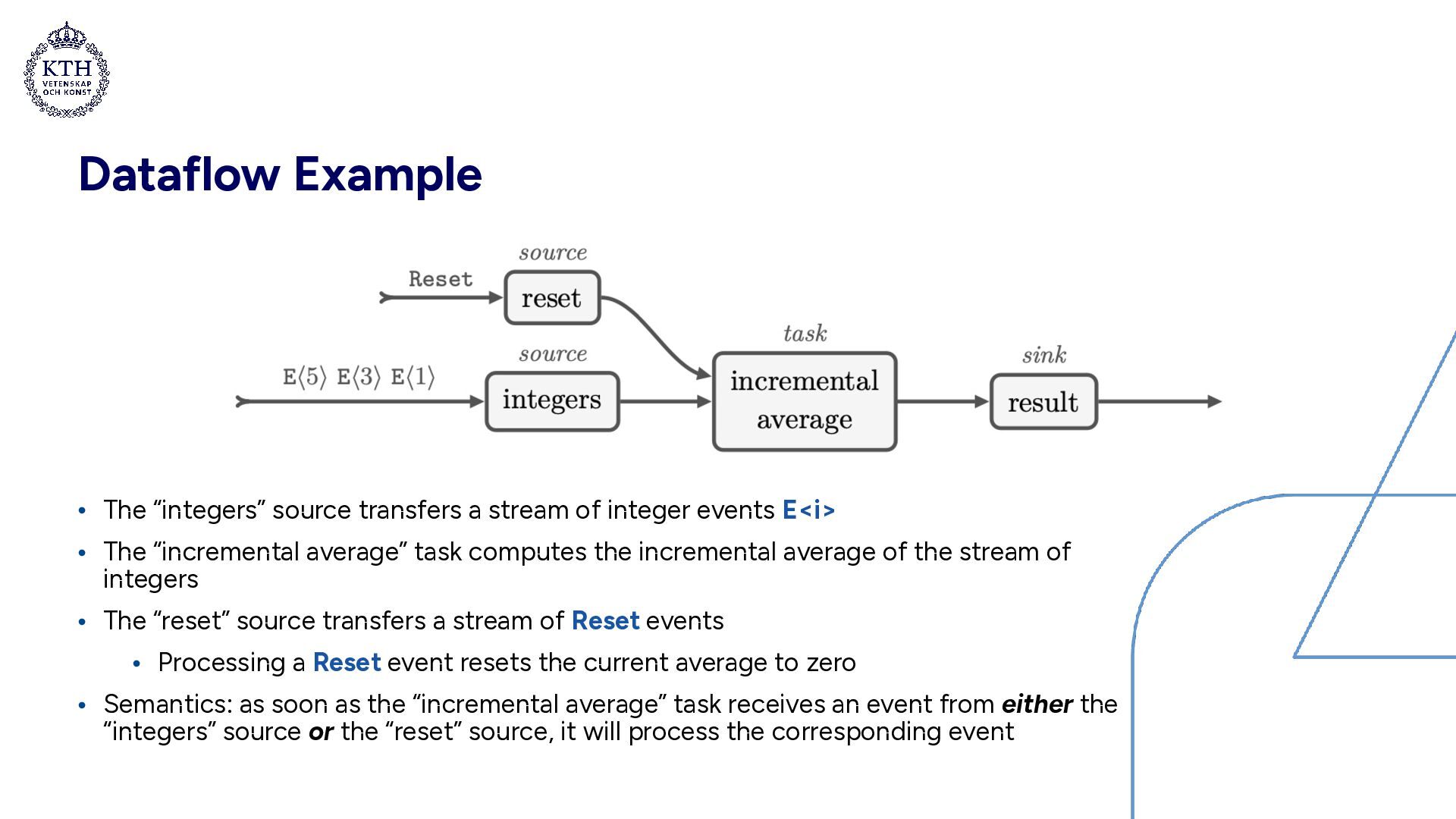
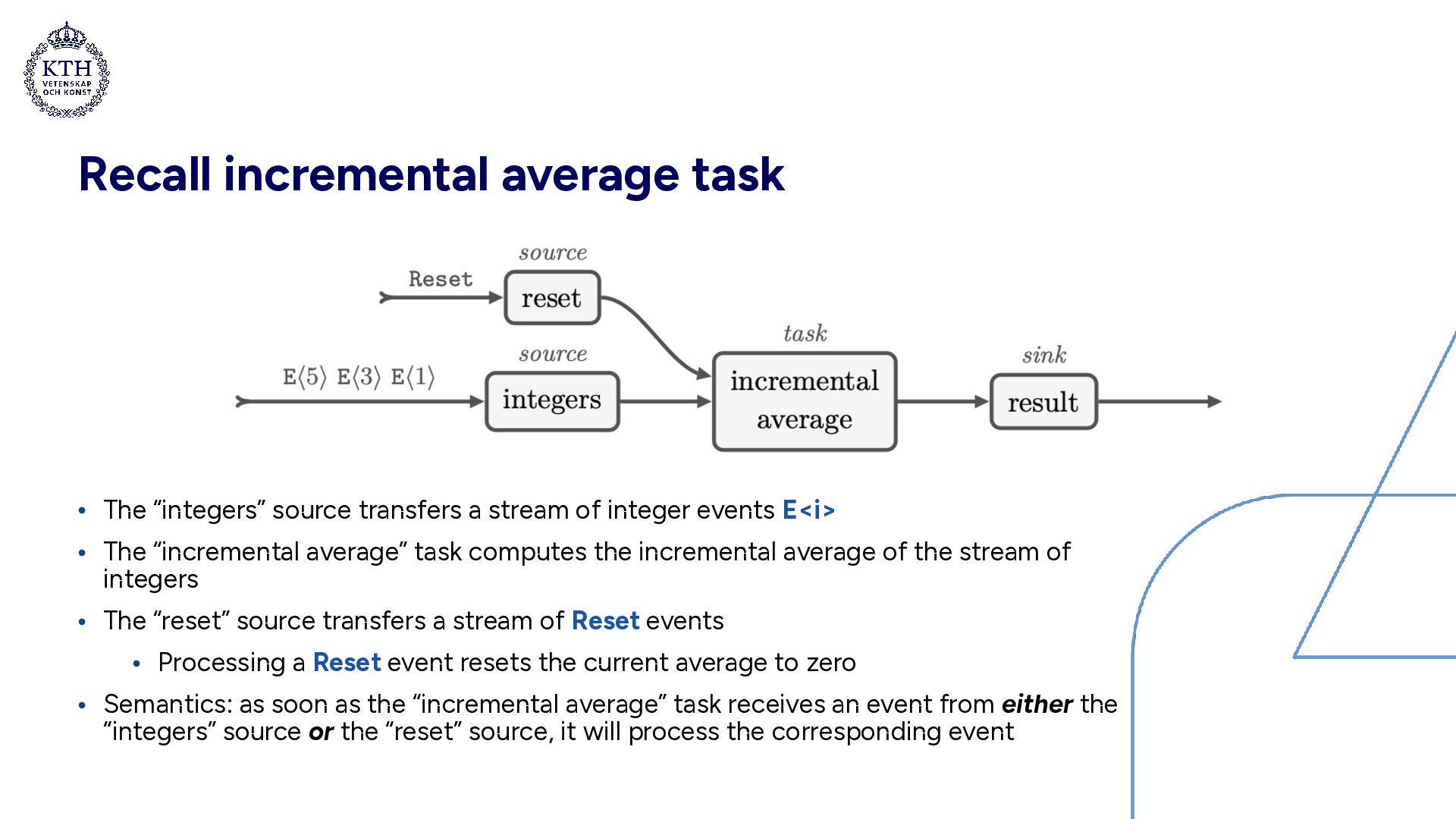
integer events E<i> • The “incremental average” task computes the incremental average of the stream of integers • The “reset” source transfers a stream of Reset events • Processing a Reset event resets the current average to zero • Semantics: as soon as the “incremental average” task receives an event from either the “integers” source or the “reset” source, it will process the corresponding event
• Failures: assumptions common to asynchronous distributed systems [CGR11] • Failures are assumed to be crash-recovery failures: a node loses its volatile state when crashing • A failure detector is used for triggering the recovery • System components (all found in production dataflow systems): • Failure-free coordinator implemented using a distributed consensus protocol such as Paxos • Snapshot storage is assumed to be persistent and durable, e.g., provided by HDFS • The input to the dataflow graph is assumed to be logged such that it can be replayed upon failure, using a durable log system such as Kafka [CGR11] Christian Cachin, Rachid Guerraoui, and Luís E. T. Rodrigues. Introduction to Reliable and Secure Distributed Programming (2. ed.). Springer, 2011
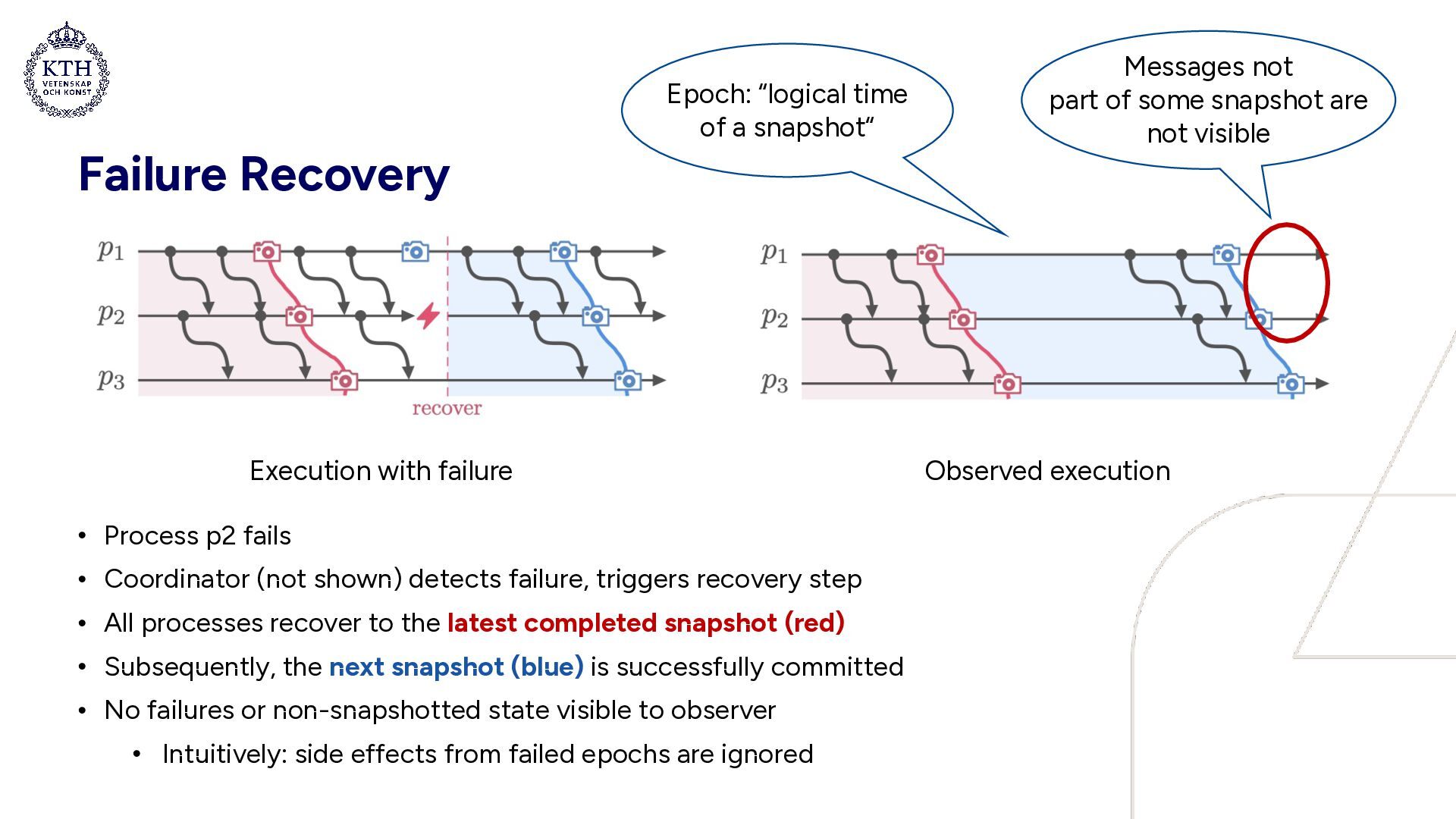
detects failure, triggers recovery step • All processes recover to the latest completed snapshot (red) • Subsequently, the next snapshot (blue) is successfully committed • No failures or non-snapshotted state visible to observer • Intuitively: side effects from failed epochs are ignored Execution with failure Observed execution Epoch: “logical time of a snapshot“ Messages not part of some snapshot are not visible
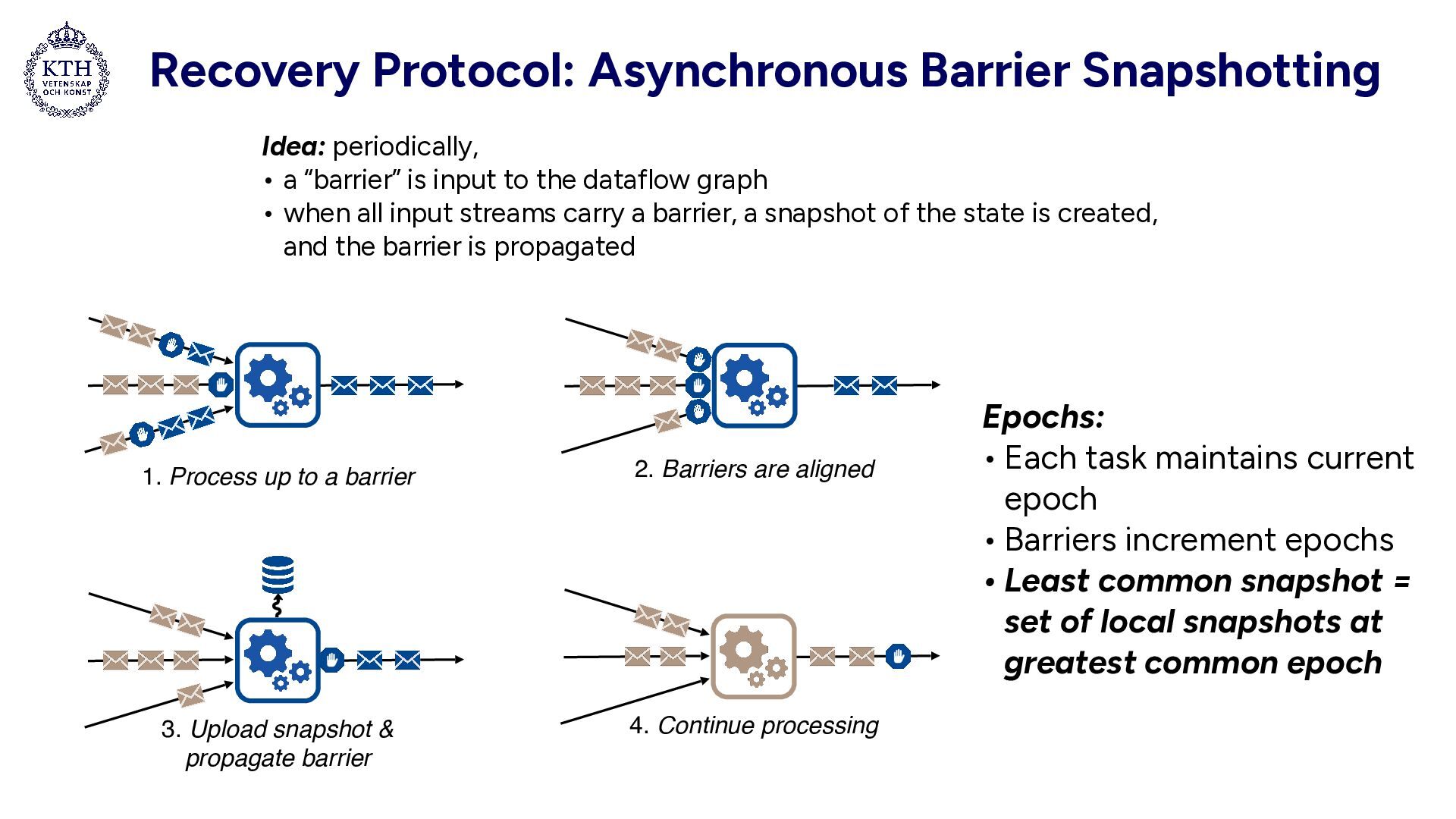
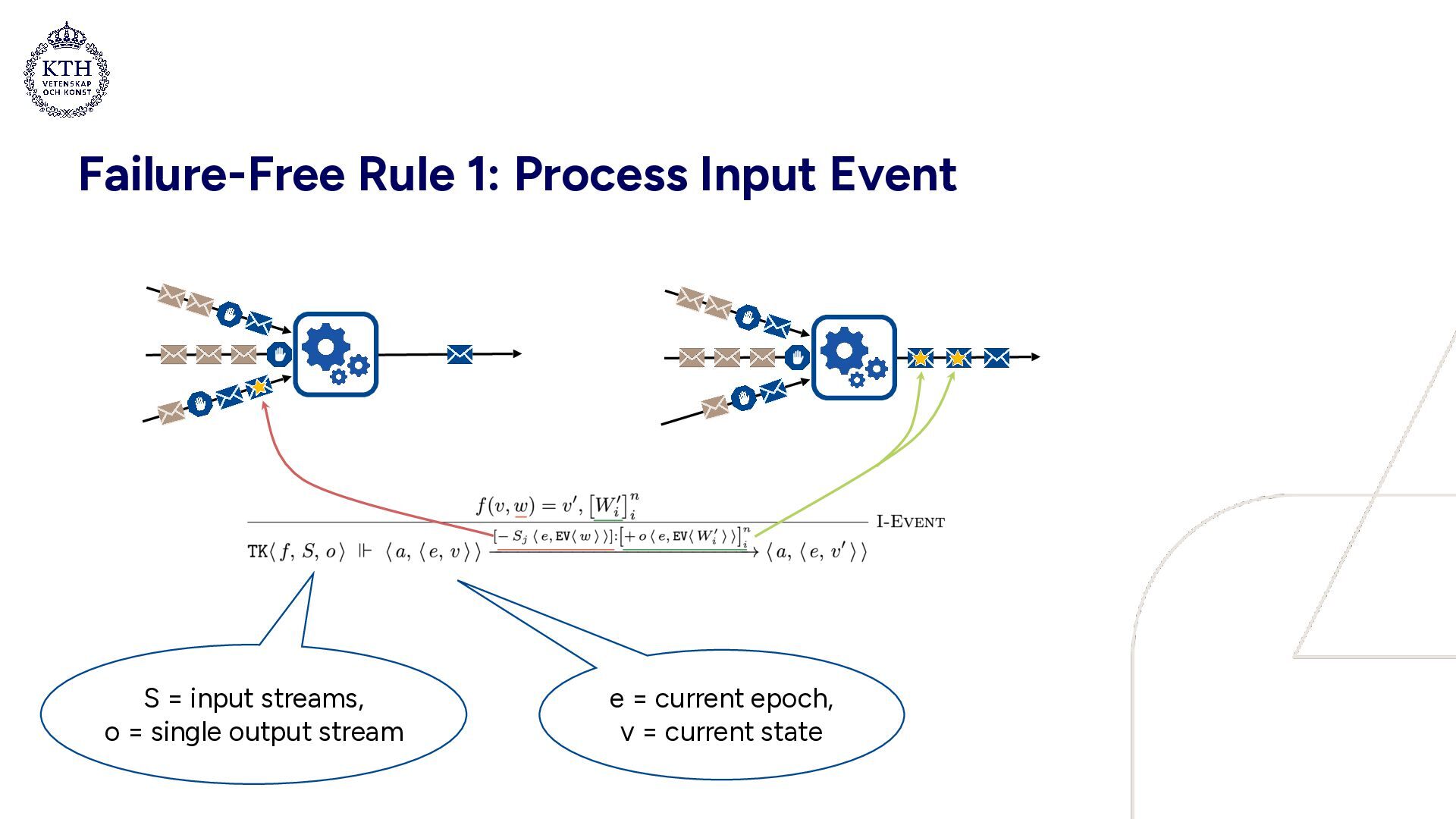
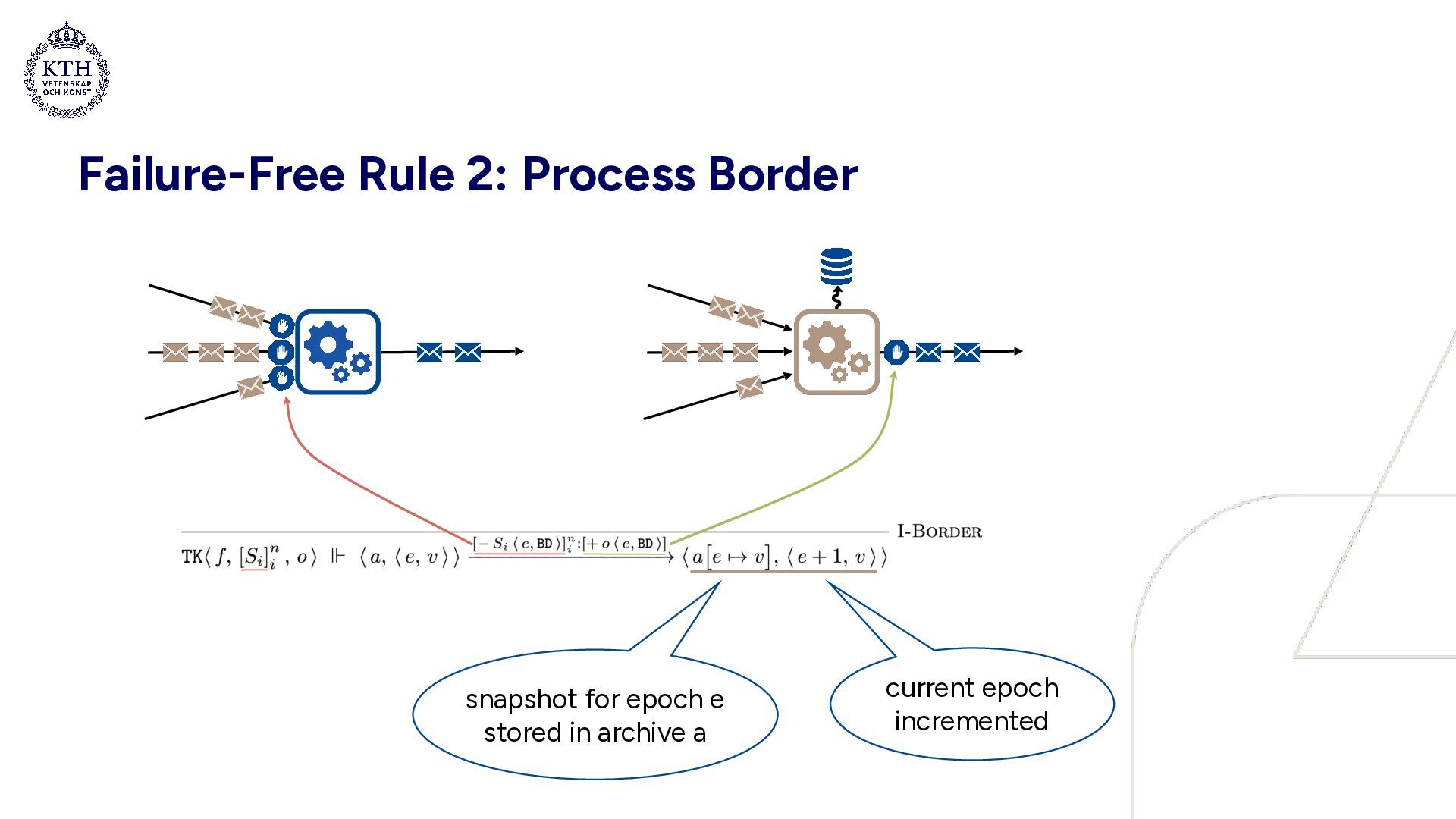
barrier 2. Barriers are aligned 3. Upload snapshot & propagate barrier 4. Continue processing Idea: periodically, • a “barrier” is input to the dataflow graph • when all input streams carry a barrier, a snapshot of the state is created, and the barrier is propagated Epochs: • Each task maintains current epoch • Barriers increment epochs • Least common snapshot = set of local snapshots at greatest common epoch
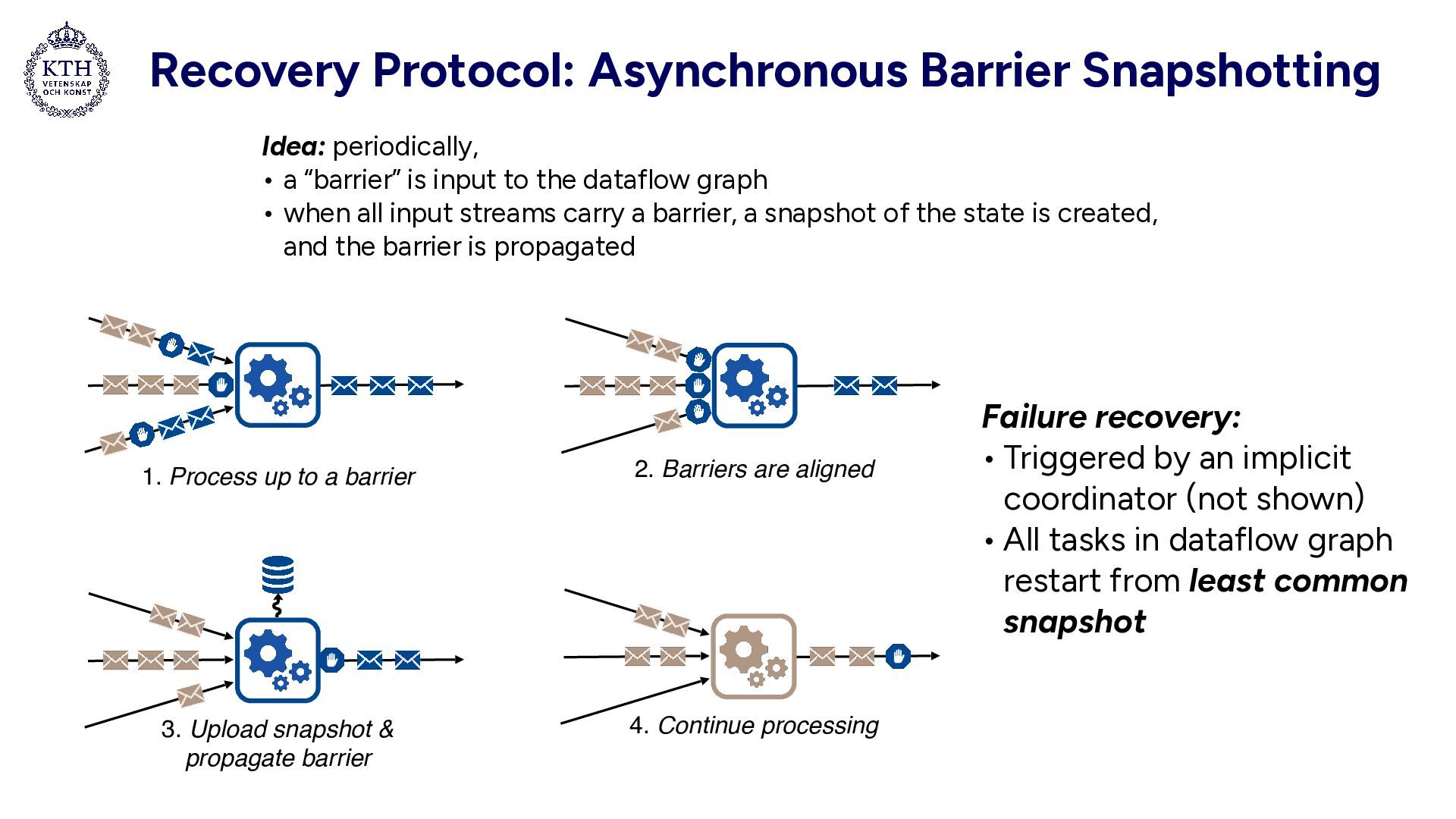
barrier 2. Barriers are aligned 3. Upload snapshot & propagate barrier 4. Continue processing Idea: periodically, • a “barrier” is input to the dataflow graph • when all input streams carry a barrier, a snapshot of the state is created, and the barrier is propagated Failure recovery: • Triggered by an implicit coordinator (not shown) • All tasks in dataflow graph restart from least common snapshot
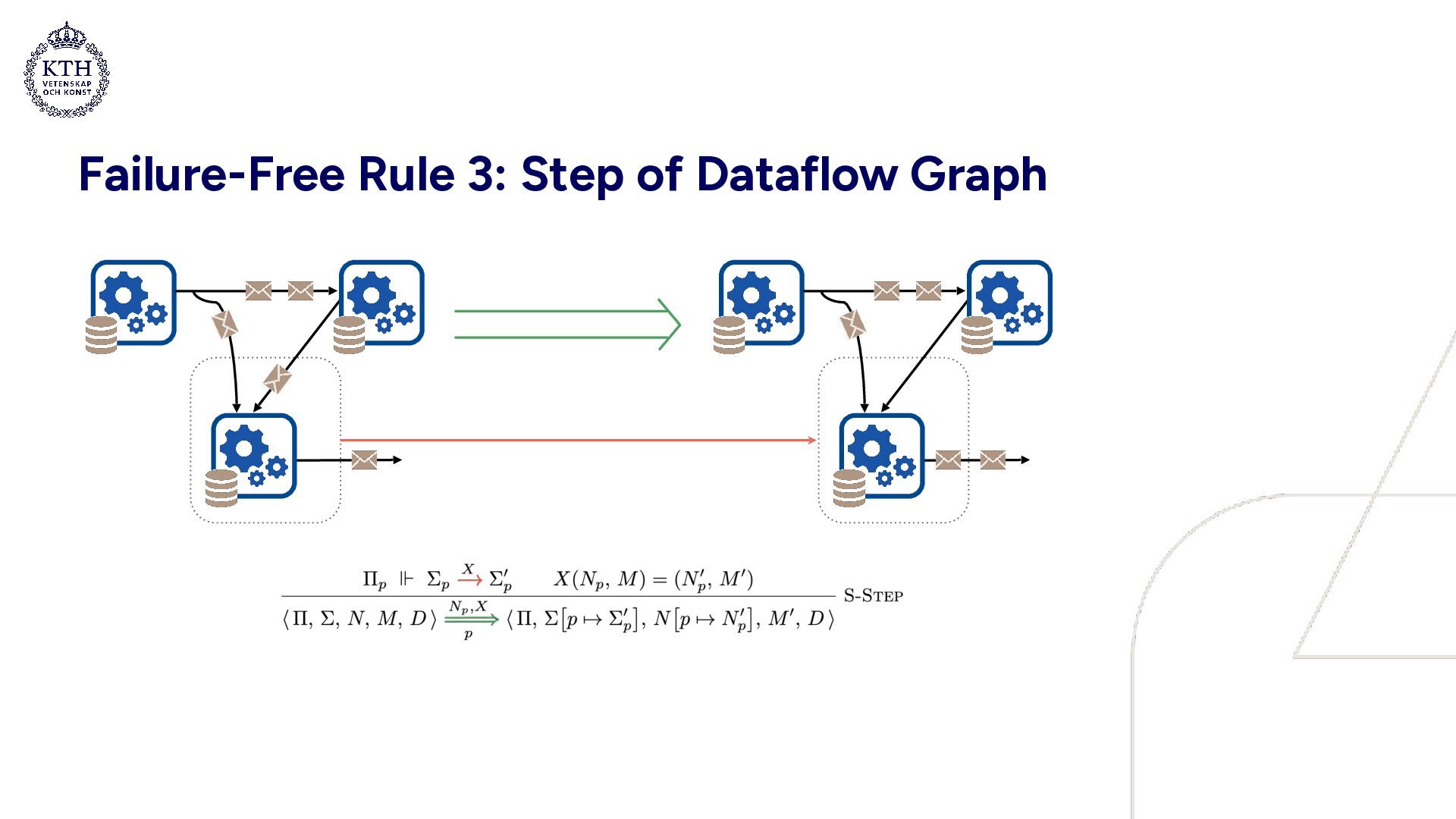
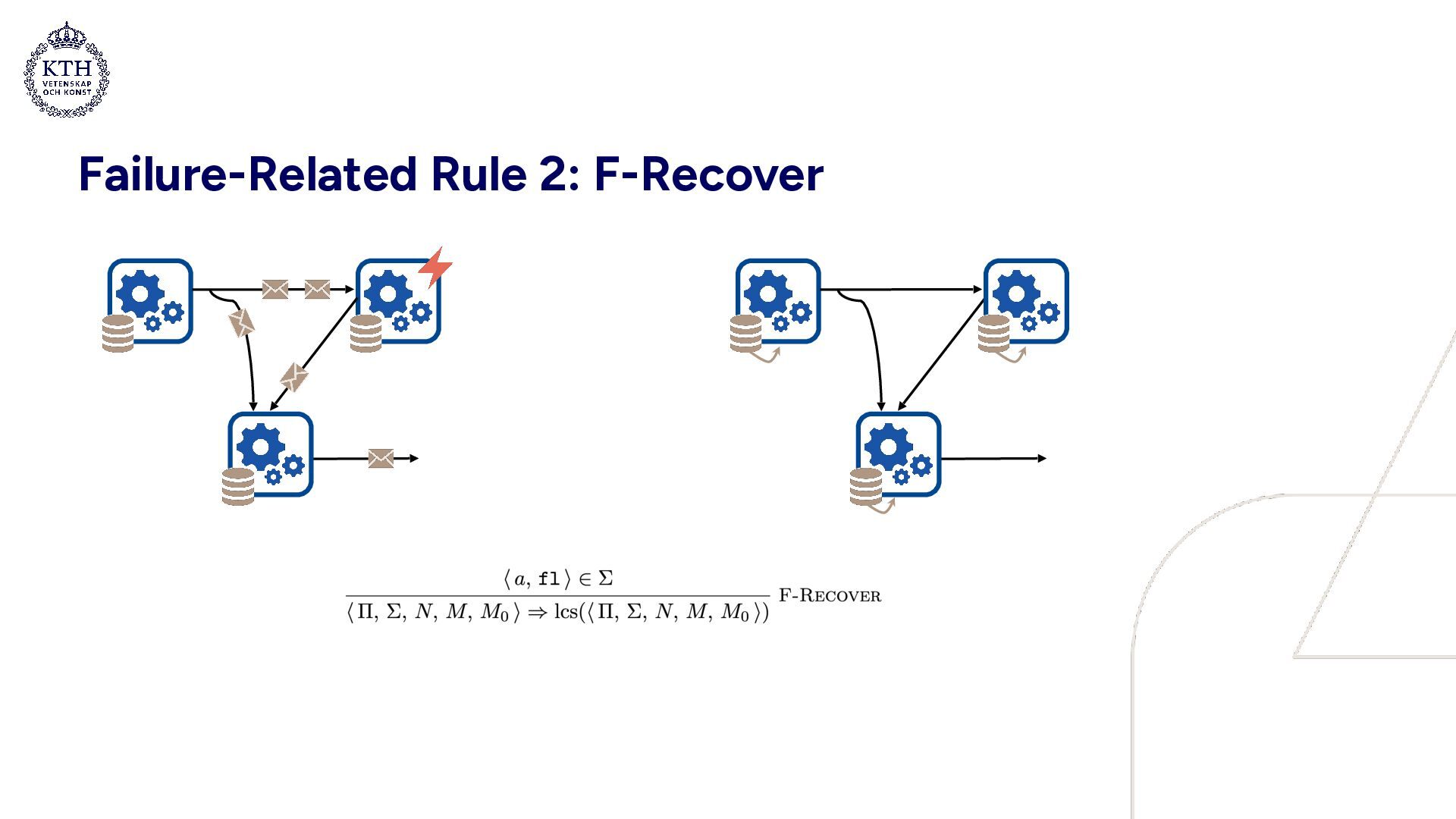
• Well suited for modeling concurrent systems • A compact set of evaluation rules: • 3 rules describe a failure-free system • 2 rules are related to failures • 2 rules are auxiliary
stream of integer events E<i> • The “incremental average” task computes the incremental average of the stream of integers • The “reset” source transfers a stream of Reset events • Processing a Reset event resets the current average to zero • Semantics: as soon as the “incremental average” task receives an event from either the “integers” source or the “reset” source, it will process the corresponding event
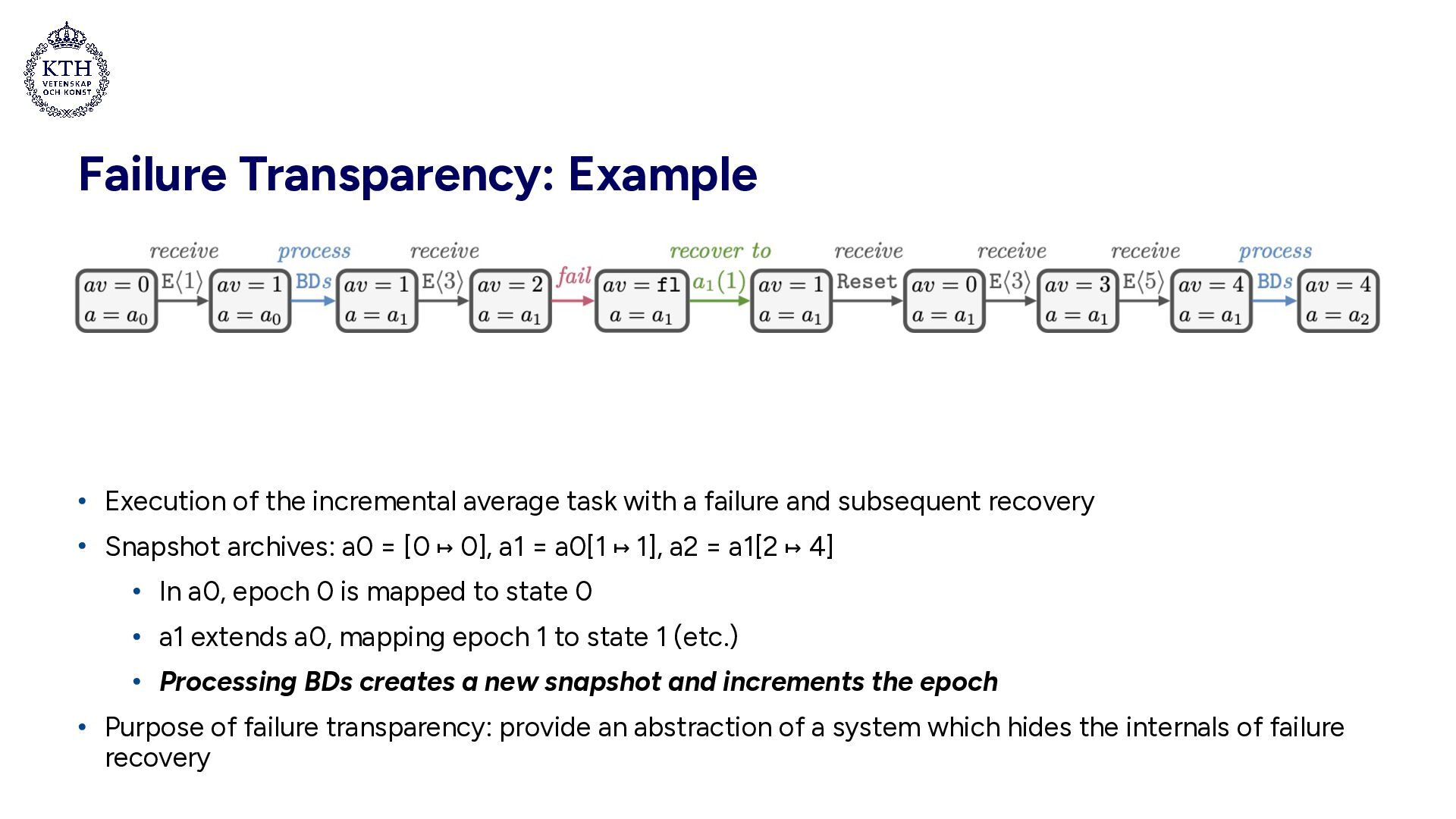
with a failure and subsequent recovery • Snapshot archives: a0 = [0 ↦ 0], a1 = a0[1 ↦ 1], a2 = a1[2 ↦ 4] • In a0, epoch 0 is mapped to state 0 • a1 extends a0, mapping epoch 1 to state 1 (etc.) • Processing BDs creates a new snapshot and increments the epoch • Purpose of failure transparency: provide an abstraction of a system which hides the internals of failure recovery
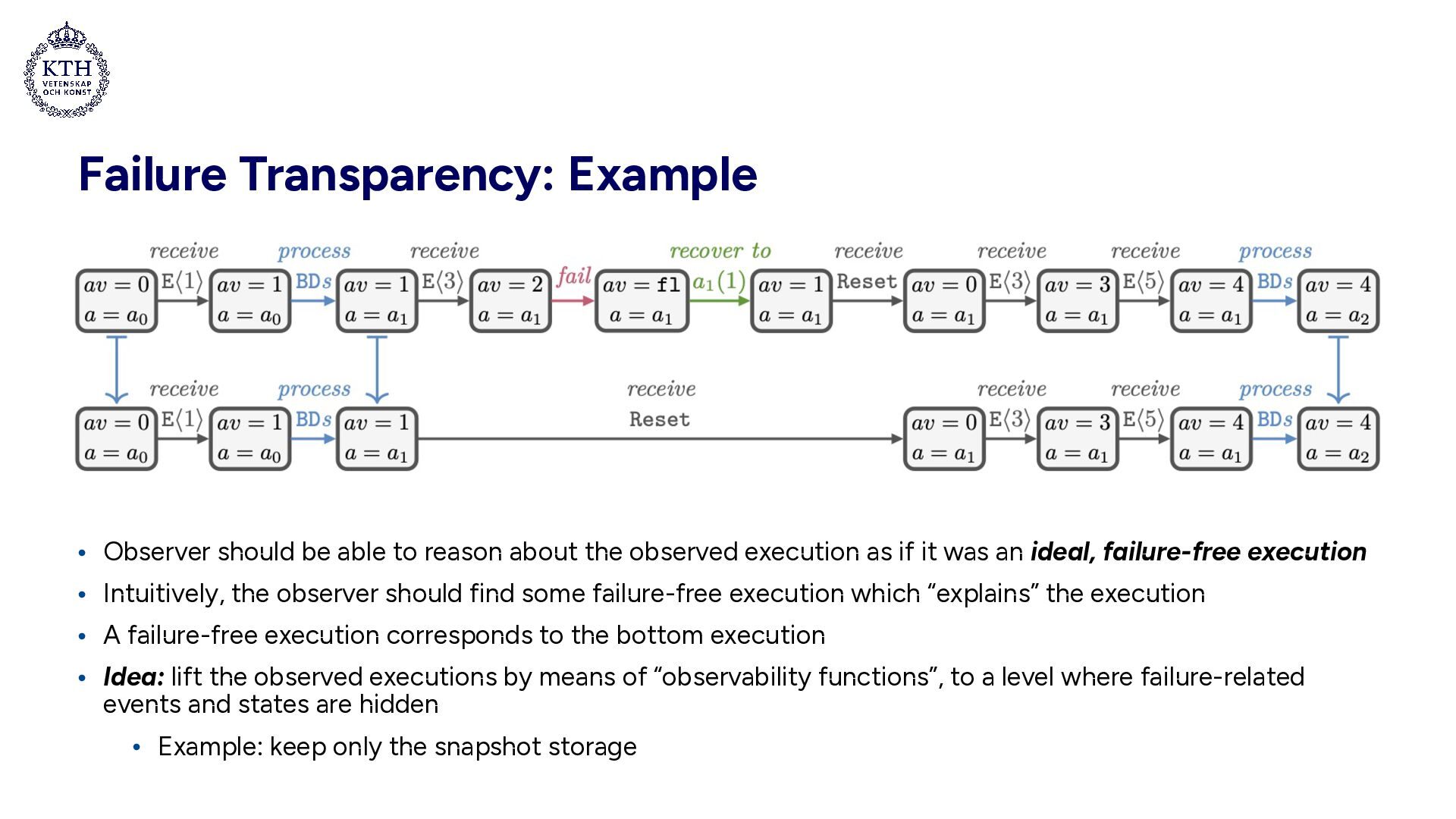
about the observed execution as if it was an ideal, failure-free execution • Intuitively, the observer should find some failure-free execution which “explains” the execution • A failure-free execution corresponds to the bottom execution • Idea: lift the observed executions by means of “observability functions”, to a level where failure-related events and states are hidden • Example: keep only the snapshot storage
using rules R (incl. failures) there is a failure-free execution C’ starting in configuration c’ using rules R’ such that C is explained by (failure-free) C’ for all failure-free configurations c’ that are translated to c
a subset of “failure rules” F ⊆ R • Then, the set of rules R is failure transparent wrt. F iff R is observationally explainable by R \ F • Formally: Only initial configurations (c ∈ K) are translated → Only executions from initial configurations are considered
Barrier Snapshotting protocol within a stateful dataflow system, as used in Apache Flink • A novel definition of failure transparency for programming models expressed in small-step operational semantics with explicit failure rules • The first definition of failure transparency for stateful dataflow systems • A proof that the implementation model is failure transparent and guarantees liveness • A mechanization of the definitions, theorems, and models using the Rocq proof assistant Aleksey Veresov, Jonas Spenger, Paris Carbone, Philipp Haller: Failure Transparency in Stateful Dataflow Systems. ECOOP 2024: 42:1-42:31 https://doi.org/10.4230/LIPIcs.ECOOP.2024.42
correct services with low effort • Thanks to failure transparency! • However, restricted in expressiveness: directed acyclic graphs of tasks • Actor concurrency model lifts this restriction: • Cyclic, dynamic communication graphs • Widely used for building reliable services: • Messaging services with Erlang at WhatsApp [EST18] • Social media with Scala Actors [Mok09] • Online multiplayer games with Akka at Fortnite [MMA19] • Cloud services with Orleans at Microsoft [BBGKT14]
services: • Hierarchical actor supervision (Erlang, Akka, Apache Pekko) • Design patterns like event sourcing • Libraries (Erlang/OTP) • Handling failures is the user's responsibility (although libraries help) • Missing: an actor programming model that is provably failure-transparent
actors; (ii) send messages to other actors • Actors never fail • Actors are failure-transparent • Implementation: • Actors can fail • Failure = crash-recovery failure: • Actor loses volatile state and restarts Goal: proof of failure transparency of the implementation with respect to the specification
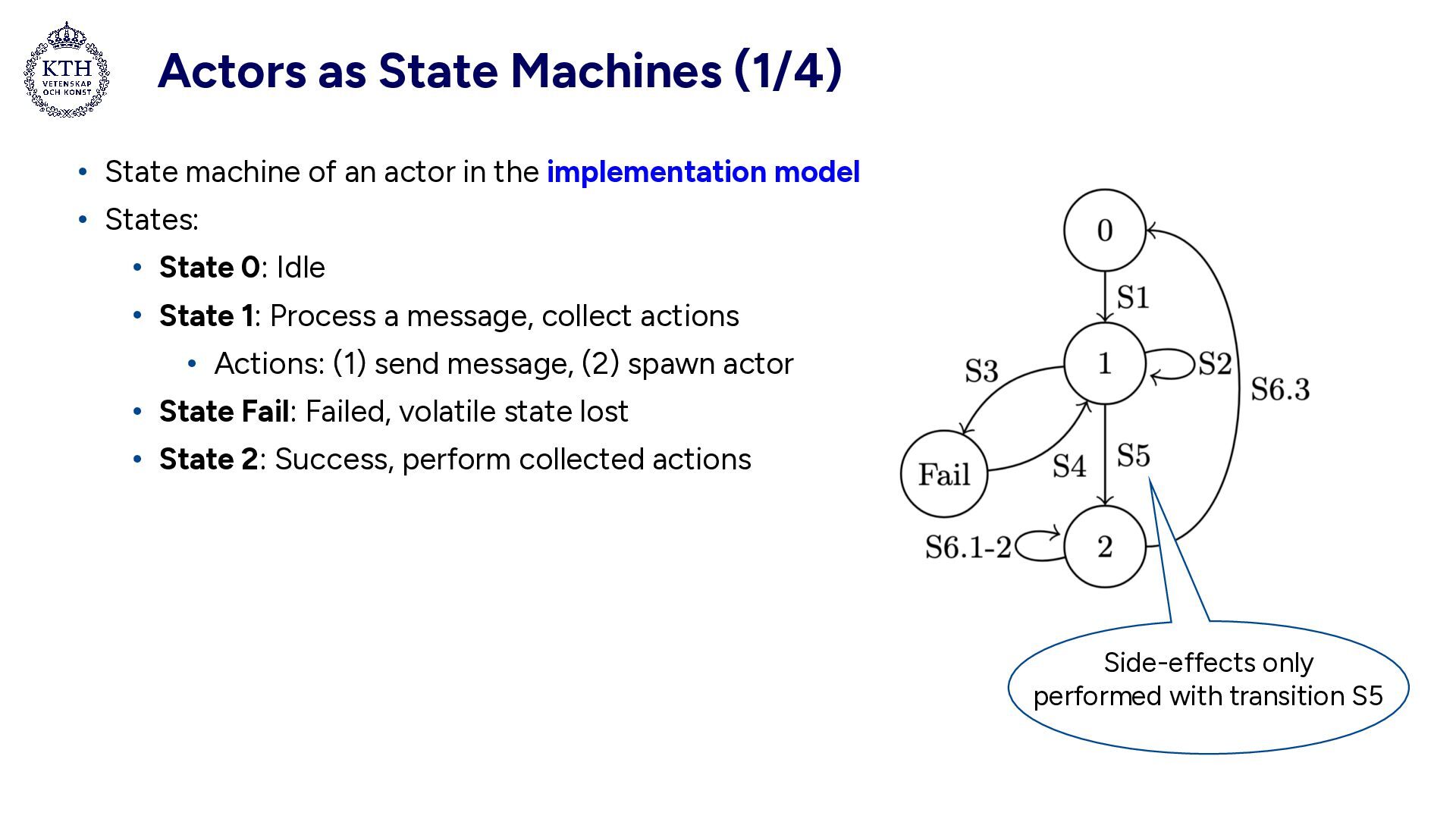
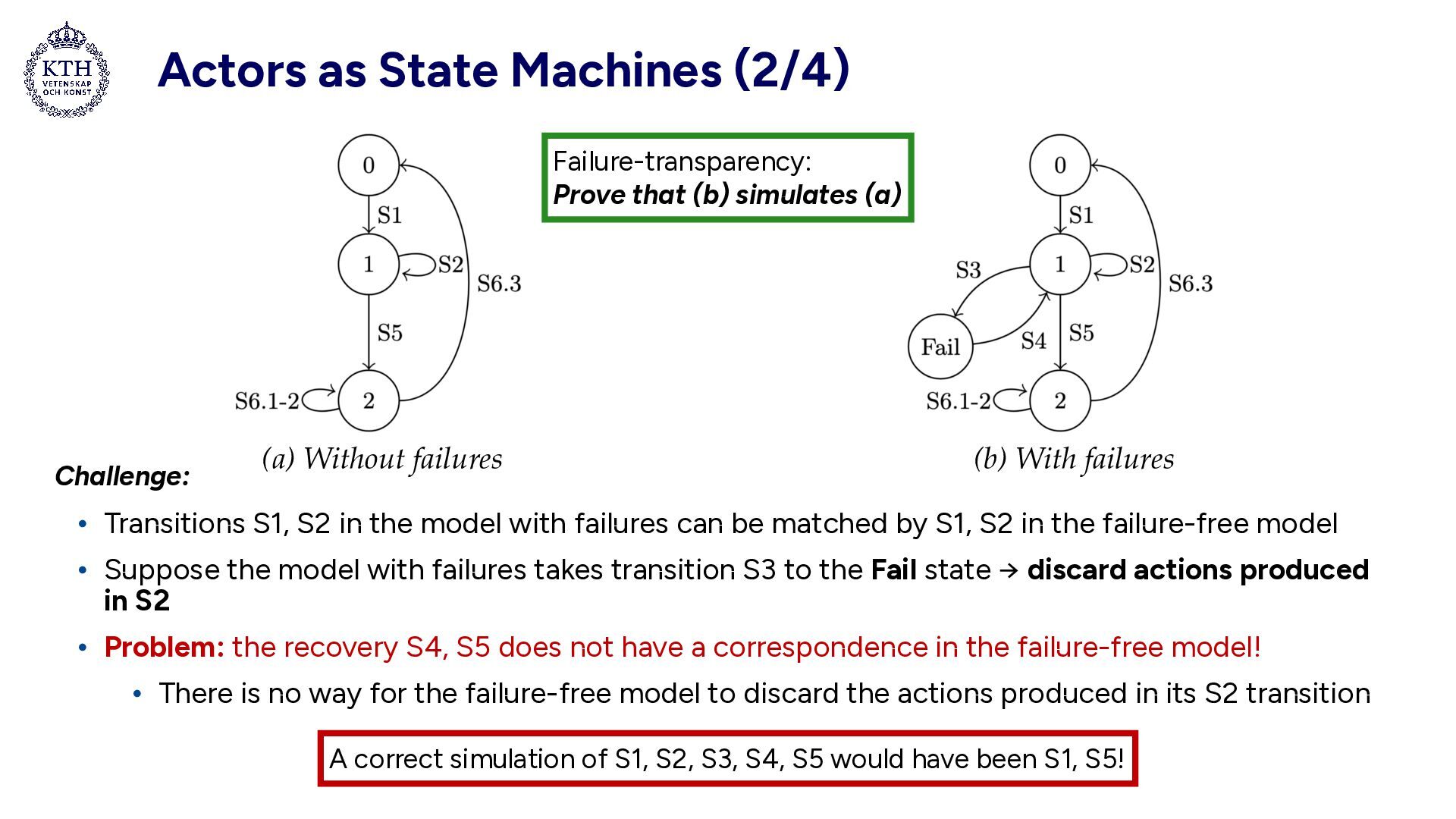
actor in the implementation model • States: • State 0: Idle • State 1: Process a message, collect actions • Actions: (1) send message, (2) spawn actor • State Fail: Failed, volatile state lost • State 2: Success, perform collected actions Side-effects only performed with transition S5
the model with failures can be matched by S1, S2 in the failure-free model • Suppose the model with failures takes transition S3 to the Fail state → discard actions produced in S2 • Problem: the recovery S4, S5 does not have a correspondence in the failure-free model! • There is no way for the failure-free model to discard the actions produced in its S2 transition (a) Without failures (b) With failures Failure-transparency: Prove that (b) simulates (a) Challenge: A correct simulation of S1, S2, S3, S4, S5 would have been S1, S5!
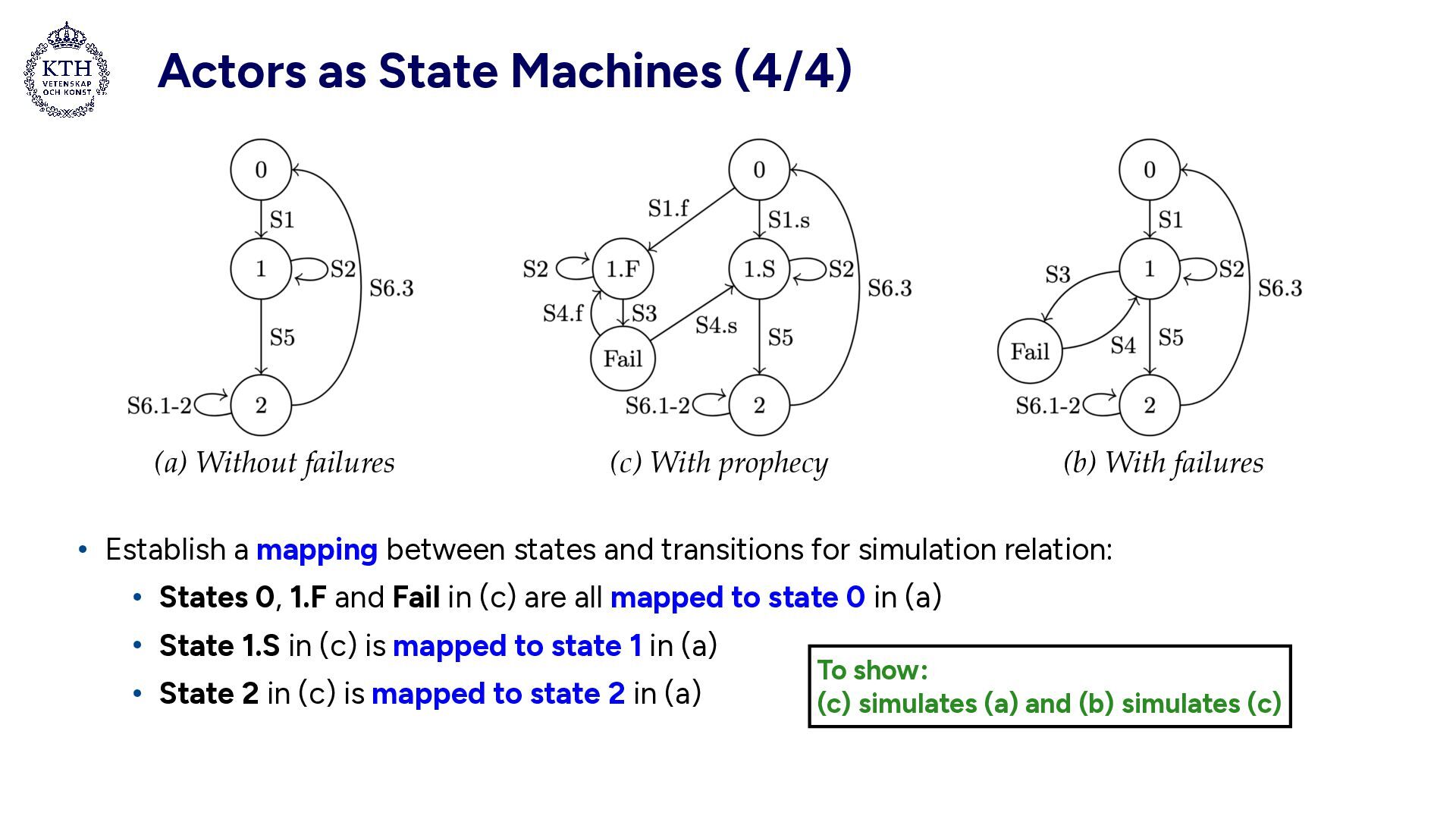
• Represent if execution will Fail (.F) or Succeed (.S) • Using prophecy to simulate the transitions S1, S2, S3, S4, S5 of the model with failures: • S1.f, S2, S3, S4.s, S5 (c) With prophecy (a) Without failures (b) With failures Leslie Lamport, Stephan Merz: Prophecy Made Simple. ACM Trans. Program. Lang. Syst. 44(2): 6:1-6:27 (2022) https://doi.org/10.1145/3492545 Solution: Key insights: • Goal: show that all transition sequences of the model with failures can be simulated • For each transition sequence of (b), we know the values of the prophecy variables • Using the prophecy variables enables model (b) to simulate (c)
states and transitions for simulation relation: • States 0, 1.F and Fail in (c) are all mapped to state 0 in (a) • State 1.S in (c) is mapped to state 1 in (a) • State 2 in (c) is mapped to state 2 in (a) (c) With prophecy (a) Without failures (b) With failures To show: (c) simulates (a) and (b) simulates (c)
extend failure-transparency from stateful dataflow streaming to the actor model • We present a proof of failure transparency by showing that the (low-level) implementation model simulates the specification model using prophecy variables (which is shown to simulate the specification model) • Prototype implementation available at: https://github.com/jspenger/durable-actor • Paper: Jonas Spenger, Paris Carbone, Philipp Haller: Failure-Transparent Actors. Concurrent Programming, Open Systems and Formal Methods: Essays Dedicated to Gul Agha to Celebrate His Scientific Career. LNCS, vol. 16120: 81-113. Springer, 2026. https://doi.org/10.1007/978-3-032-05291-9_4
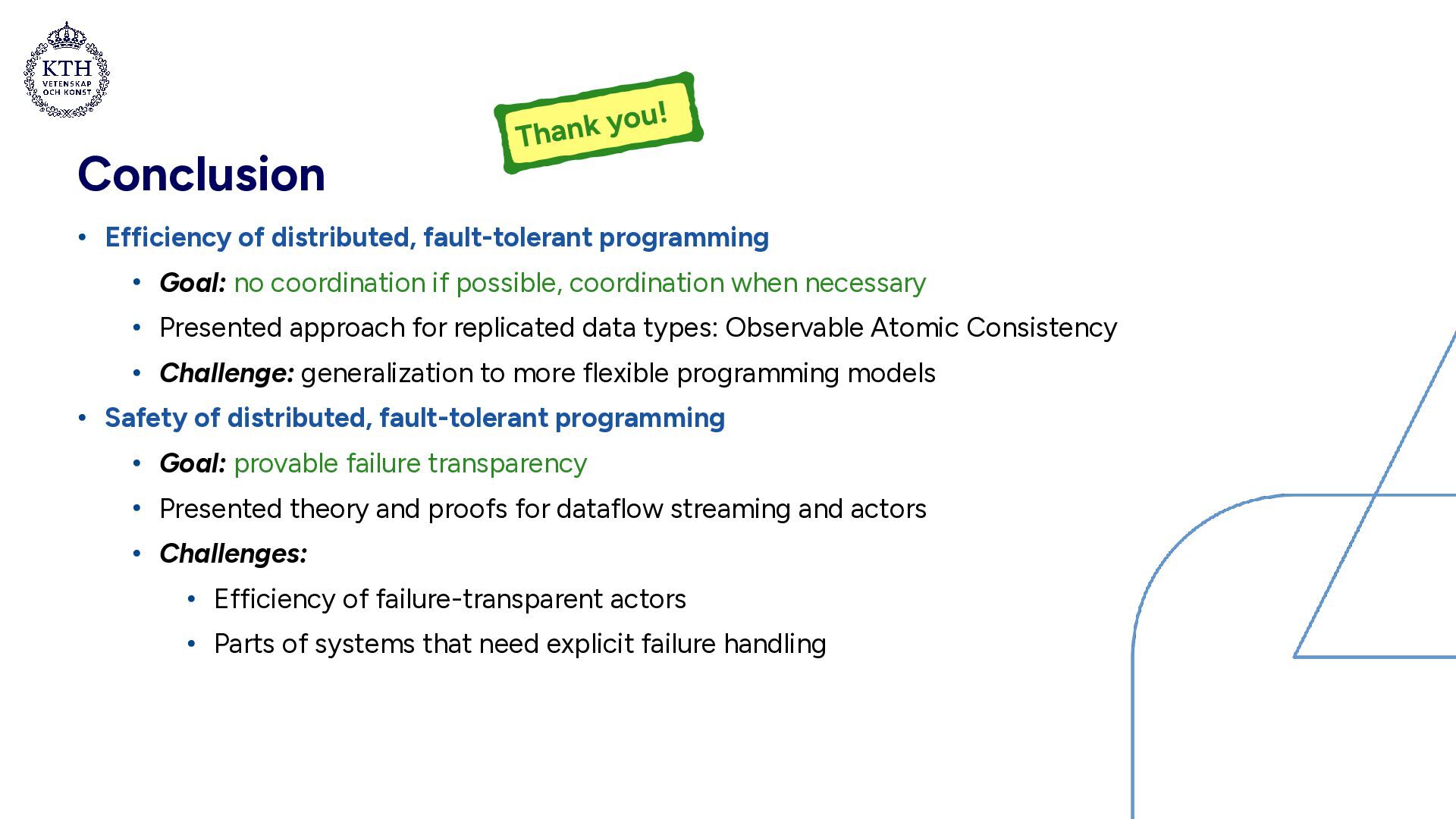
coordination if possible, coordination when necessary • Presented approach for replicated data types: Observable Atomic Consistency • Challenge: generalization to more flexible programming models • Safety of distributed, fault-tolerant programming • Goal: provable failure transparency • Presented theory and proofs for dataflow streaming and actors • Challenges: • Efficiency of failure-transparent actors • Parts of systems that need explicit failure handling Thank you!
Introduction to Reliable and Secure Distributed Programming (2. ed.). Springer, 2011 [BBGKT14] Philip A. Bernstein, Sergey Bykov, Alan Geller, Gabriel Kliot, Jorgen Thelin: Orleans: Distributed Virtual Actors for Programmability and Scalability. Microsoft Research Technical Report MSR-TR-2014-41, 2014. https://www.microsoft.com/en-us/research/publication/orleans-distributed-virtual-actors-for-programmability-and-scalability/ [CEFHRT17] Paris Carbone, Stephan Ewen, Gyula Fóra, Seif Haridi, Stefan Richter, Kostas Tzoumas: State Management in Apache Flink®: Consistent Stateful Distributed Stream Processing. Proc. VLDB Endow. 10(12): 1718-1729 (2017) https://doi.org/10.14778/3137765.3137777 [VSCH24] Aleksey Veresov, Jonas Spenger, Paris Carbone, Philipp Haller: Failure Transparency in Stateful Dataflow Systems. ECOOP 2024: 42:1-42:31 https://doi.org/10.4230/LIPIcs.ECOOP.2024.42 [LM22] Leslie Lamport, Stephan Merz: Prophecy Made Simple. ACM Trans. Program. Lang. Syst. 44(2): 6:1-6:27 (2022) https://doi.org/10.1145/3492545 [SCH26] Jonas Spenger, Paris Carbone, Philipp Haller: Failure-Transparent Actors. Concurrent Programming, Open Systems and Formal Methods: Essays Dedicated to Gul Agha to Celebrate His Scientific Career. LNCS, vol. 16120: 81-113. Springer, 2026. https://doi.org/10.1007/978-3-032-05291-9_4 [MMA19] Christopher S. Meiklejohn, Heather Miller, Peter Alvaro: PARTISAN: Scaling the Distributed Actor Runtime. USENIX ATC 2019: 63-76 https://www.usenix.org/conference/atc19/presentation/meiklejohn [Mok09] Waiming Mok: How Twitter is Scaling. https://waimingmok.wordpress.com/2009/06/27/how-twitter-is-scaling/ [EST18] Erlang Solutions Team: 20 Years of Open Source Erlang: OpenErlang Interview with Anton Lavrik from WhatsApp. https://www.erlang- solutions.com/blog/20-years-of-open-source-erlang-openerlang-interview-with-anton-lavrik-from-whatsapp/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Actors as State Machines (3/4) • Introduce ”Prophecy variables” [LM22]](https://files.speakerdeck.com/presentations/31fe43b4f78d4e98a36d53bb9e209e48/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [CGR11] Christian Cachin, Rachid Guerraoui, Luís E. T. Rodrigues:](https://files.speakerdeck.com/presentations/31fe43b4f78d4e98a36d53bb9e209e48/slide_45.jpg){kind=link}