Presentation Title: Building Reliable Machine Learning Models: From Evaluation to Deployment
Description:
In this session, we focus on the essential principles and techniques for building machine learning models that are not only accurate in training environments but also reliable when applied to real-world data. We will cover:
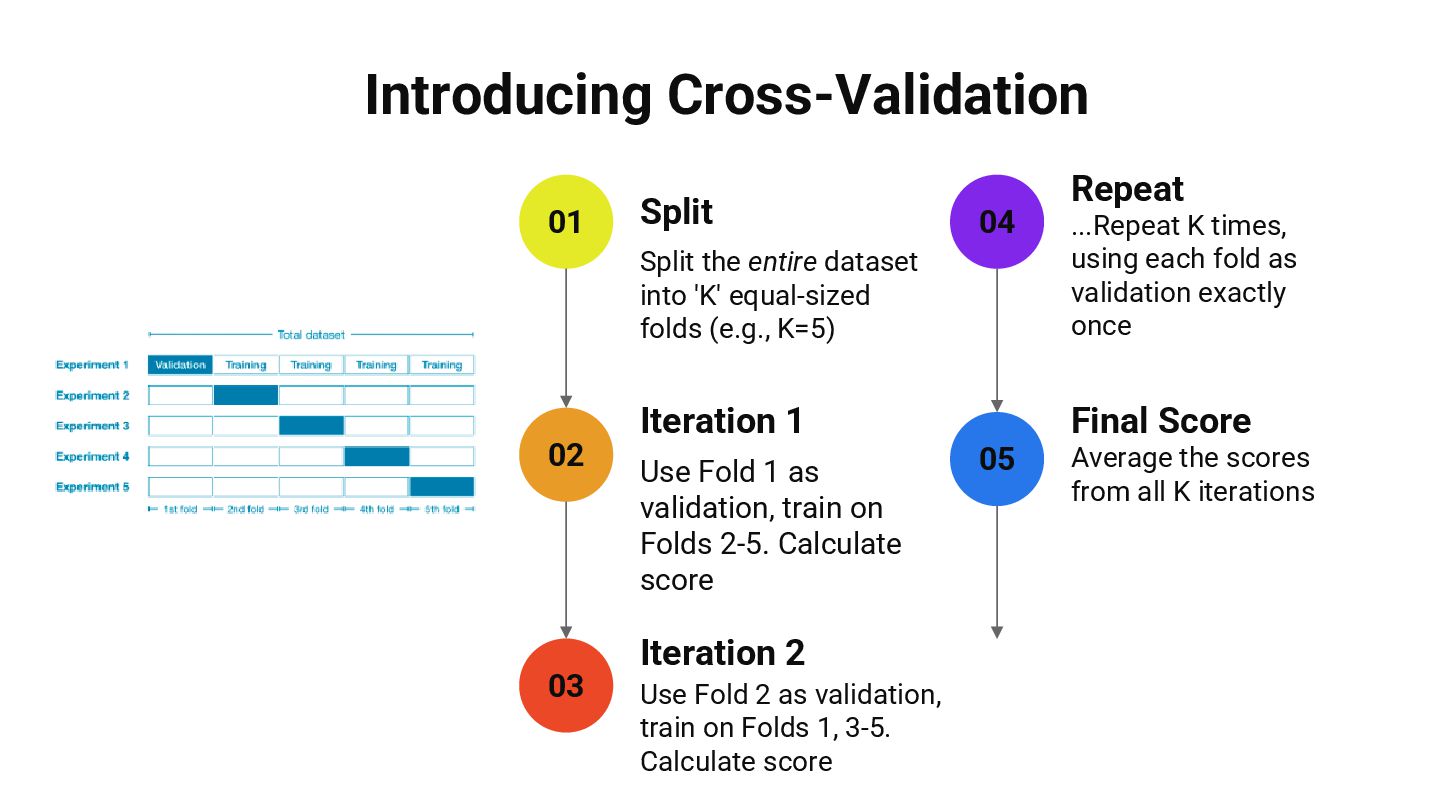
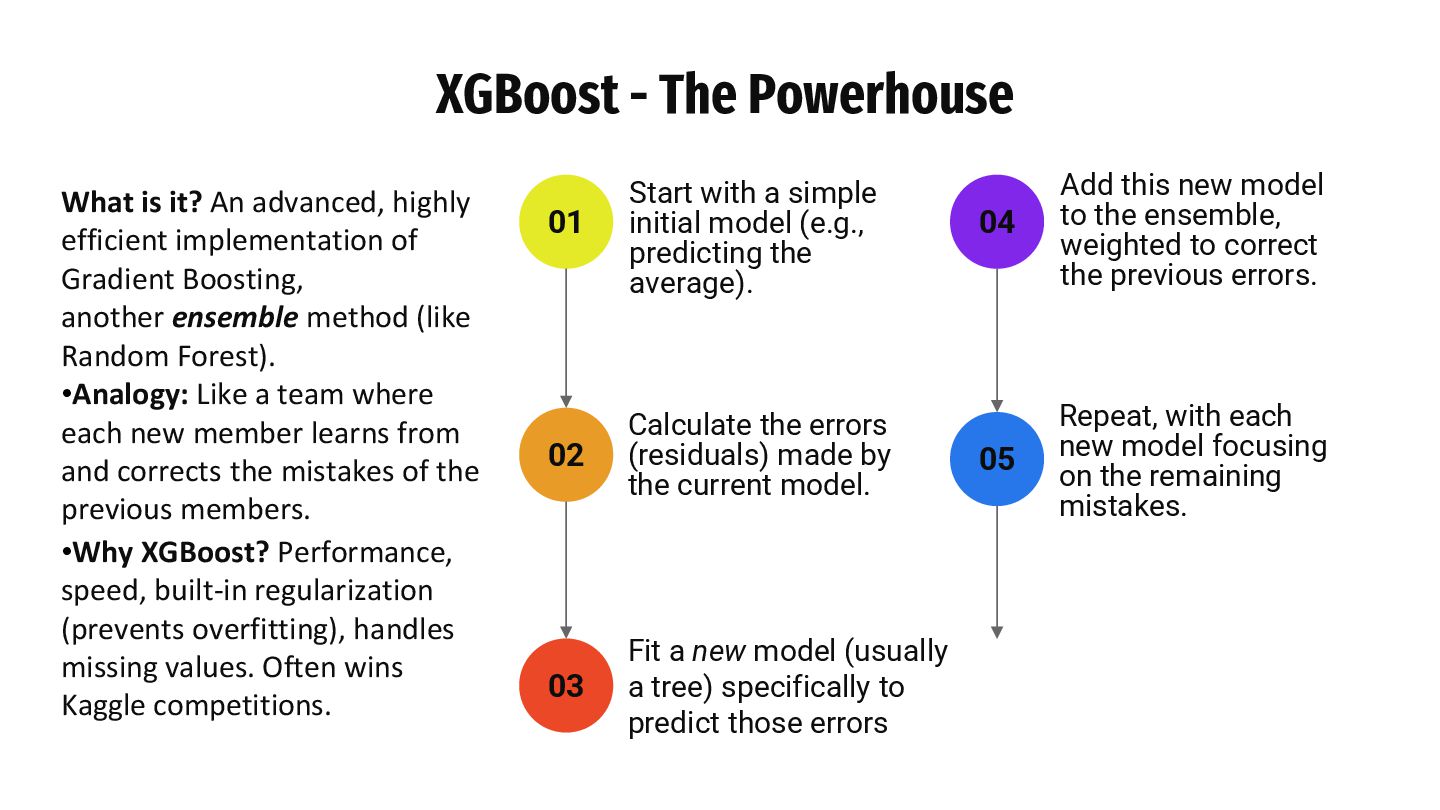
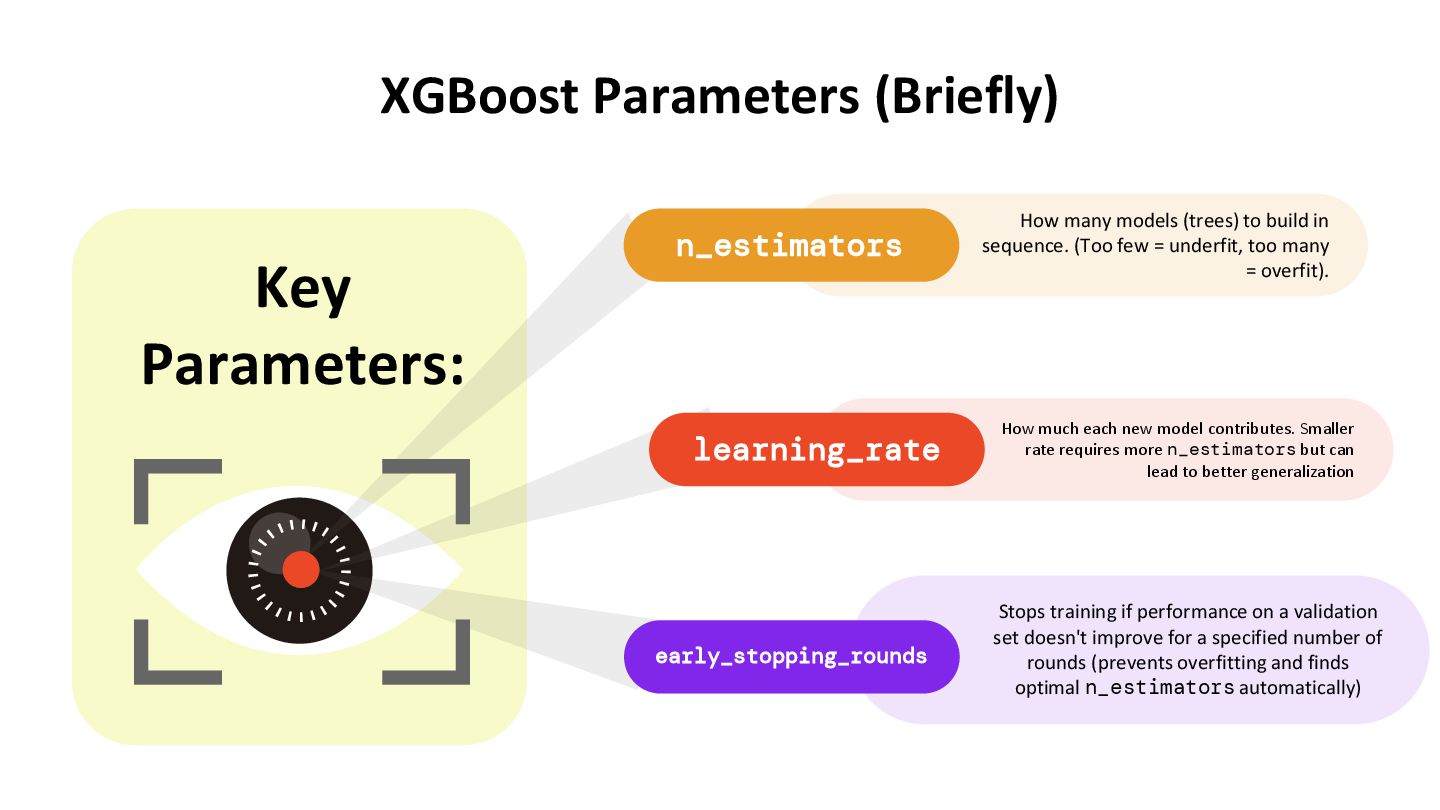
Cross-Validation – A robust technique for evaluating model performance XGBoost – A powerful gradient boosting algorithm for structured data Data Leakage – A critical pitfall that can lead to overly optimistic results Logistic Regression – Practical application using a clean ML pipeline
This talk emphasizes that machine learning is not a one-shot process, but an iterative cycle of building, testing, and refining models. We’ll discuss how to make key decisions, including:
Which features (variables) to include Which model type to choose (e.g., Linear Regression, Decision Tree, Neural Network) How to tune hyperparameters effectively
The ultimate goal is to build models that generalize well to new, unseen data. A central challenge we’ll address is:
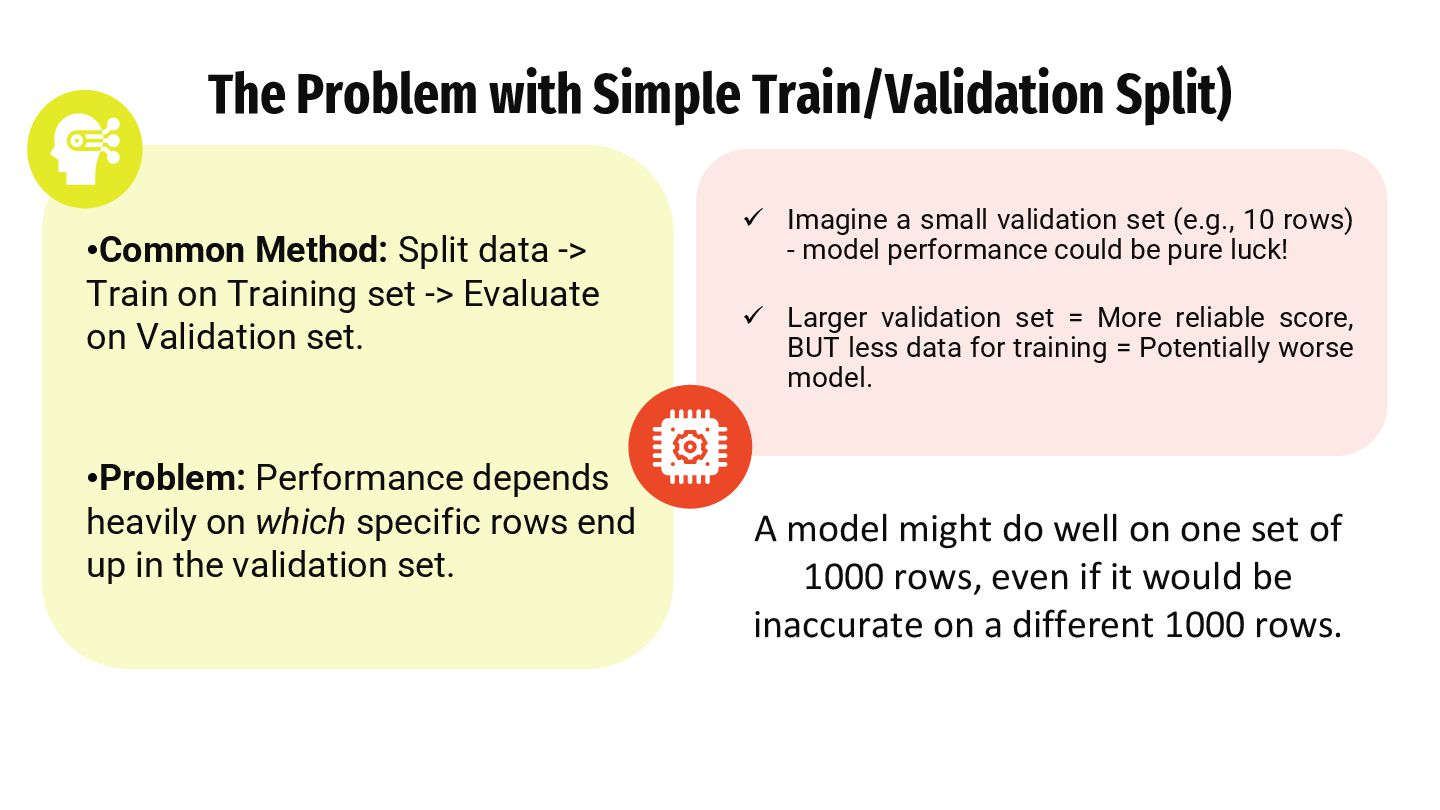
How do we reliably measure if our model is good before deploying it?
Explore the full pipeline and notebook here:
Notebook: Telco Churn EDA + Logistic Regression + Cross-Validation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}