Hypertuning with Keras Tuner: Building Robust Image Classifiers
This talk explores automated hyperparameter tuning using Keras Tuner to optimize a neural network for the Fashion MNIST dataset. I discuss model optimization strategies, experimental tracking, and evaluation with K-Fold Cross-Validation.
📌 Tools & Libraries:
TensorFlow 2.18.0
Keras Tuner 1.4.7
Seaborn, Matplotlib, Scikit-learn
📌 Project Outcomes:
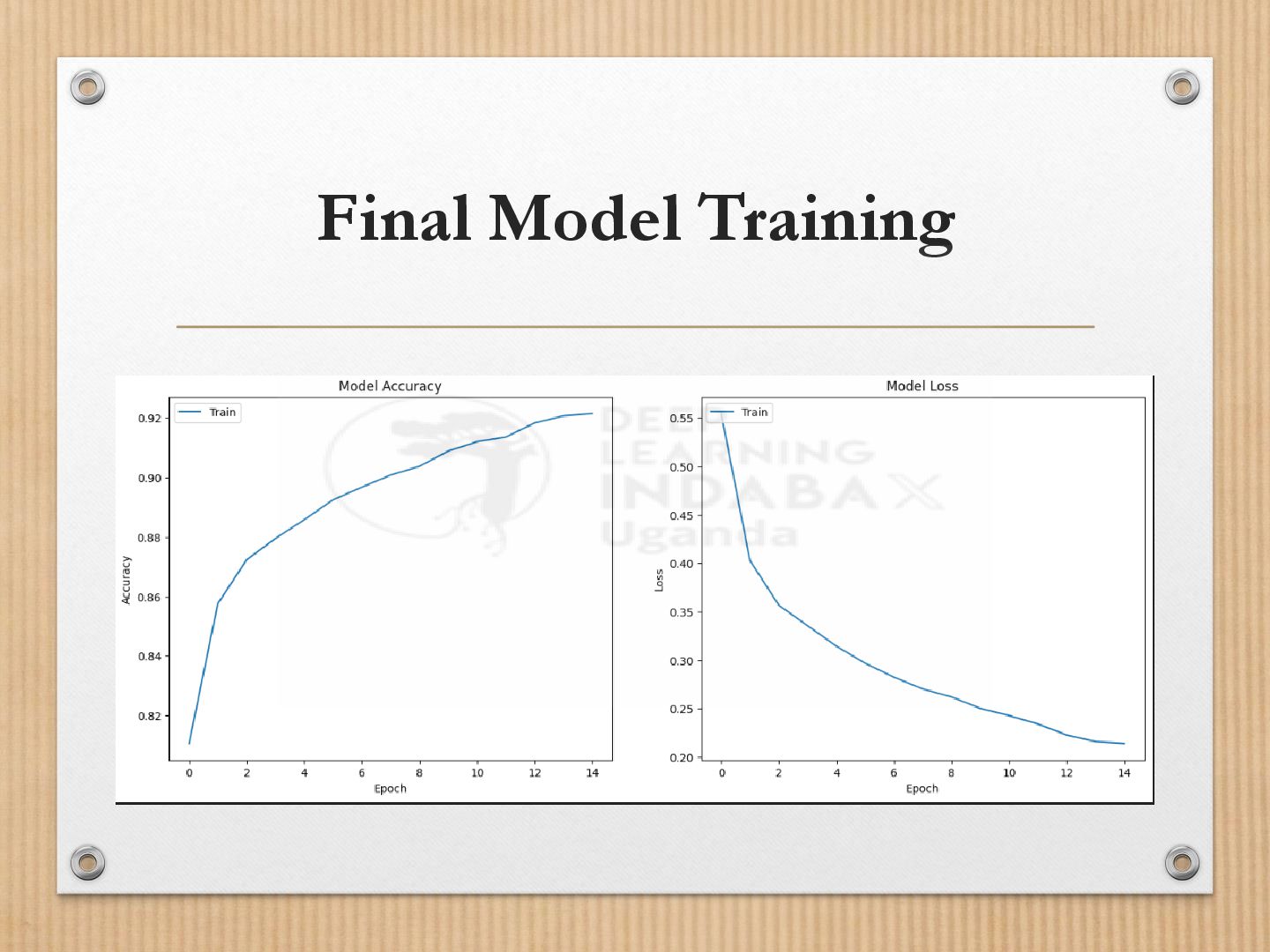
Identified optimal units = 352 and learning rate = 0.001
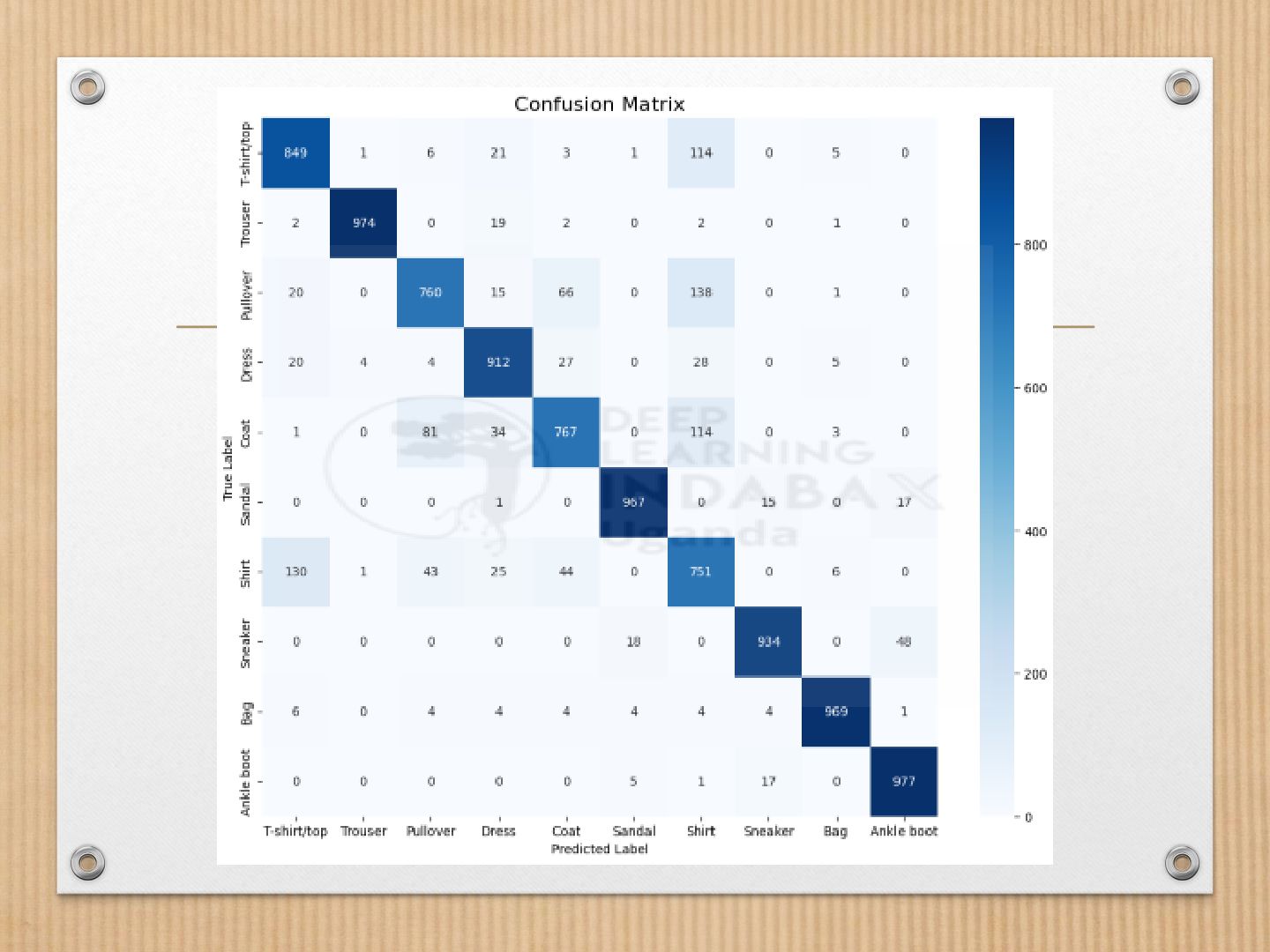
Achieved ~88.6% test accuracy
Demonstrated consistency across folds (std ~0.0053)
Pinpointed areas for further model refinement
🧠 Focus:
Hyperparameter optimization, search algorithms, reproducible experimentation, and performance diagnostics for deep learning.
📘 Full notebook:
View on Kaggle
🔊 Presented at:
Deep Learning IndabaX Uganda 2025 🇺🇬
Part of the IndabaX Research Fellow Program
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data Preprocessing • Normalize pixel values to [0, 1] •](https://files.speakerdeck.com/presentations/3893930910124c43a9e65c314928104c/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Good bye! •[email protected] •philldevcoder.netlify.app •+256765918791](https://files.speakerdeck.com/presentations/3893930910124c43a9e65c314928104c/slide_18.jpg){kind=link}