📌 Overview:
This presentation is divided into two core sections, designed to provide a foundational yet practical understanding of modern machine learning techniques: Deep Neural Networks (DNN) and Stochastic Gradient Descent (SGD). Whether you're new to neural networks or looking to strengthen your conceptual grasp, this guide bridges theory and hands-on implementation in an accessible and well-structured manner.
🧠 1. Deep Neural Networks (DNN)
🔍 Objective:
To understand how hidden layers in neural networks help model complex, nonlinear relationships in data.
🧱 Sections Covered:
Introduction
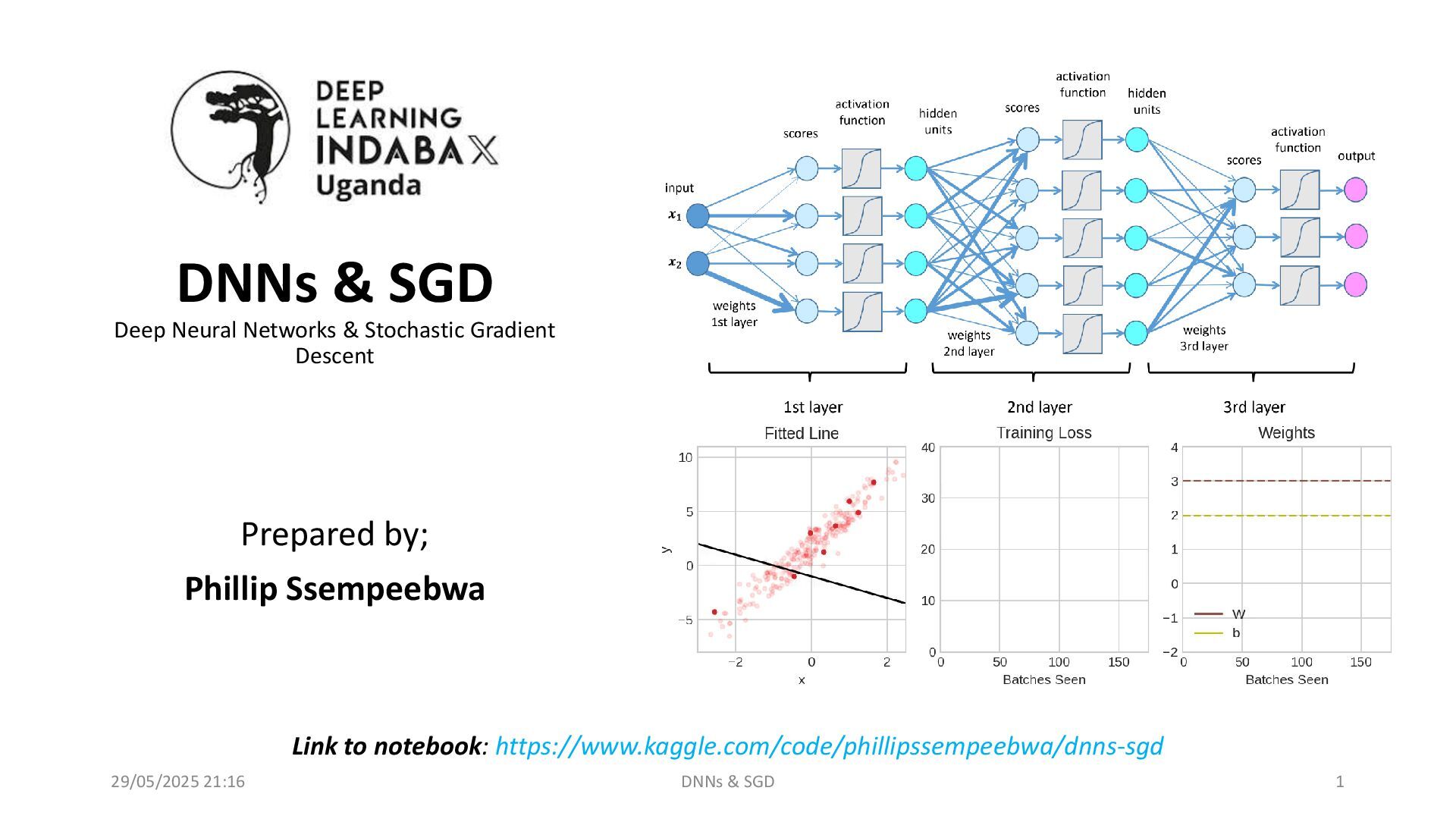
A brief recap of basic neural networks (input → output) and why we need more than one layer.
Layers
Explanation of input, hidden, and output layers, with visual representations.
The Activation Function
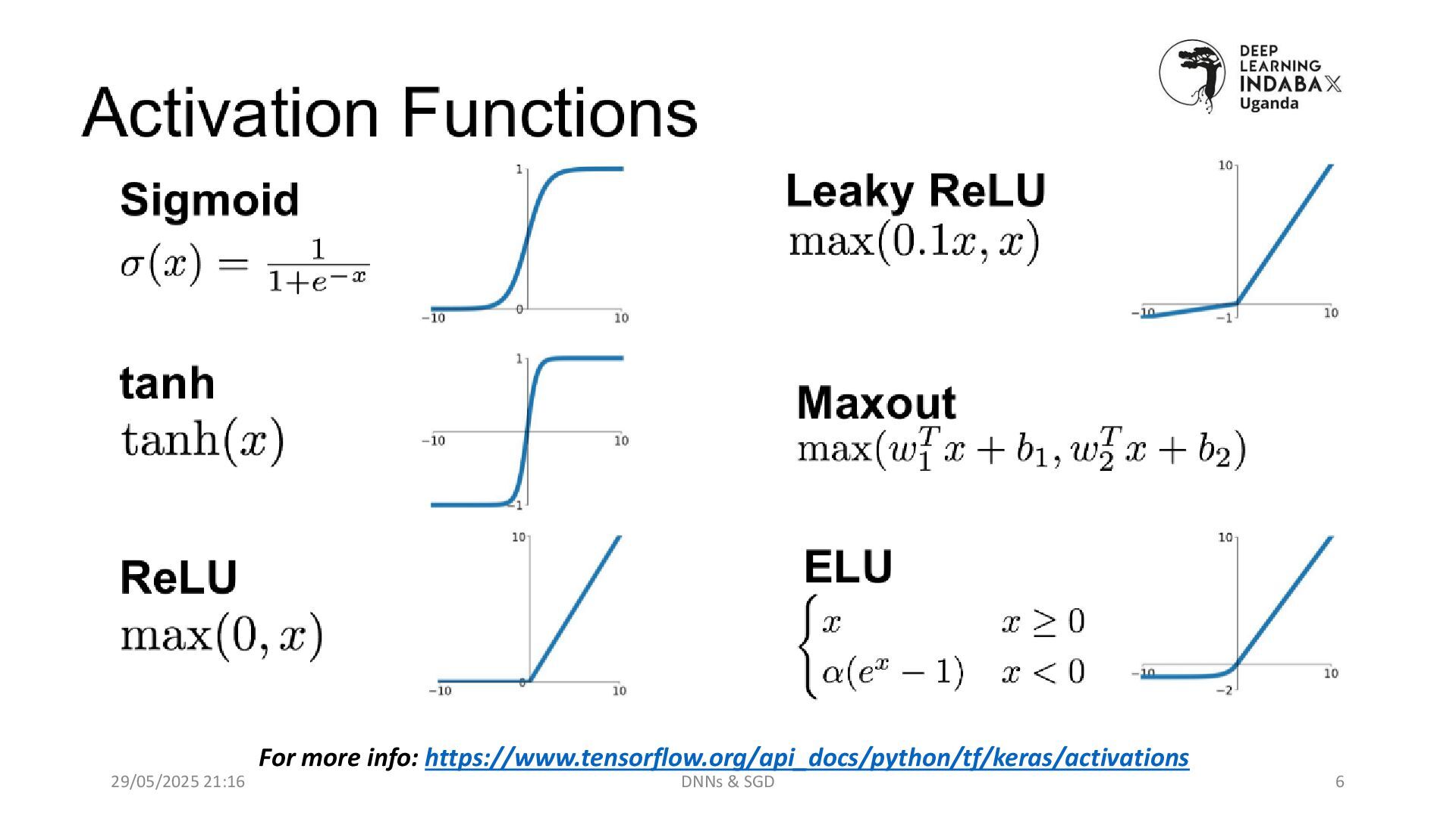
Introduction to functions like ReLU, Sigmoid, and Tanh that introduce non-linearity, making neural networks powerful.
Stacking Dense Layers
How multiple layers (fully connected/dense) improve learning capacity and flexibility. Includes tips on choosing the number of layers and neurons.
Building Sequential Models
Hands-on approach using tools like Keras/TensorFlow to build networks using the Sequential API. Covers code examples and layer-by-layer breakdowns.
⚙️ 2. Stochastic Gradient Descent (SGD)
🔍 Objective:
To understand how models are trained using loss optimization and how SGD helps reach optimal weights efficiently.
🧱 Sections Covered:
Introduction
Why we need an optimization algorithm and how it fits into the training pipeline.
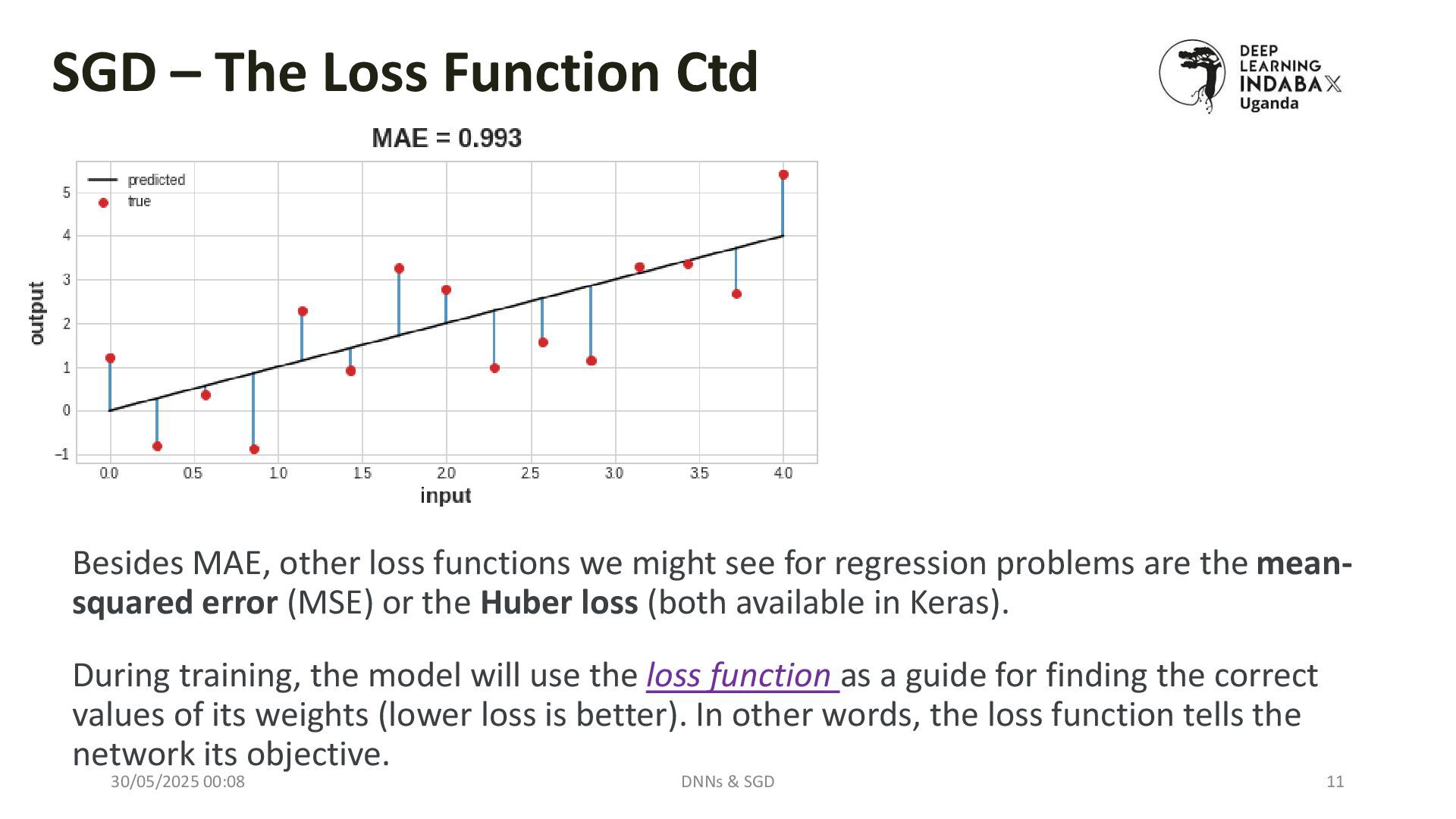
The Loss Function
Discusses how loss (e.g., MSE, CrossEntropy) measures model performance, and why minimizing it matters.
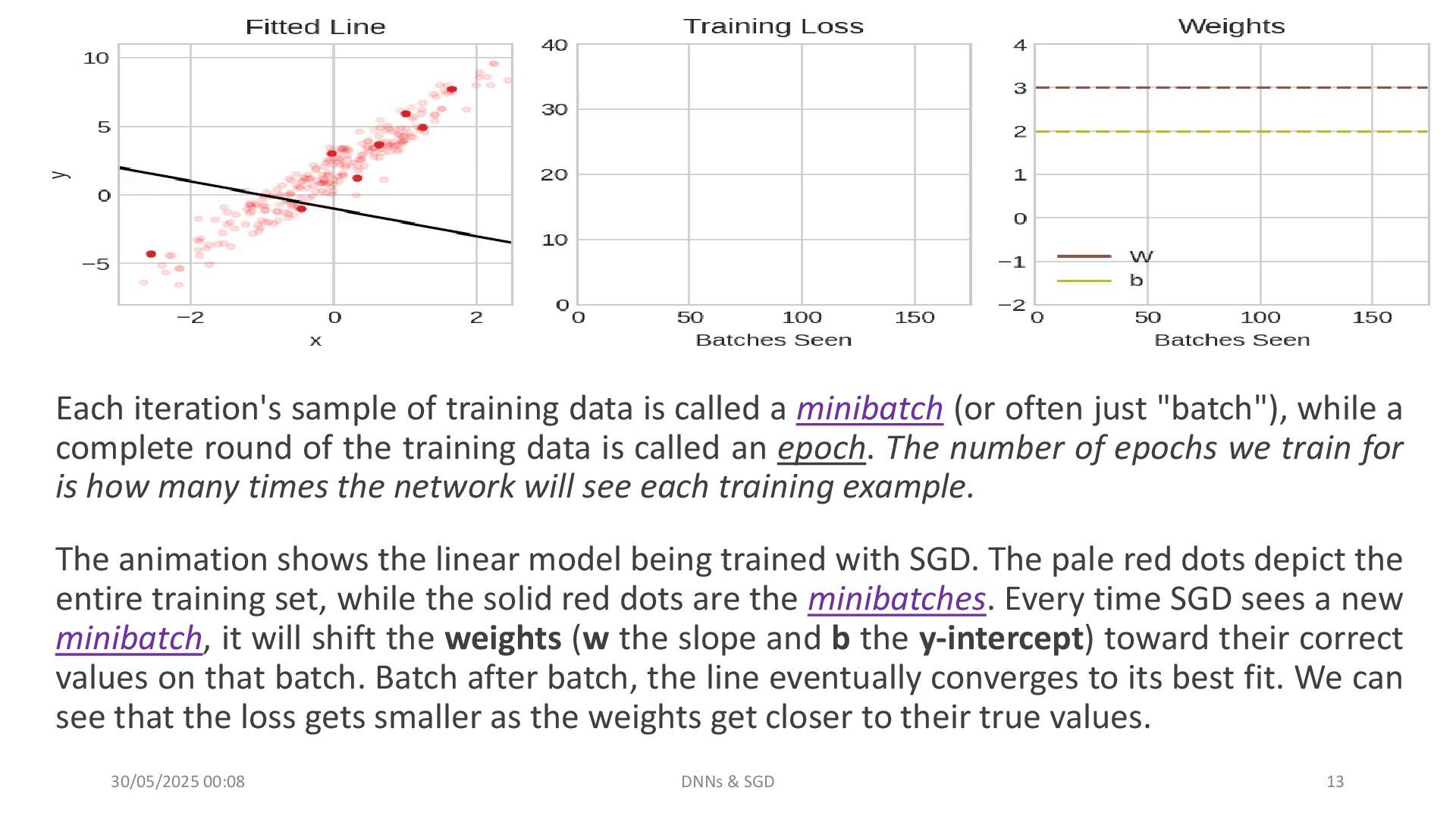
The Optimizer - SGD
In-depth explanation of Stochastic Gradient Descent, how it updates weights using small data samples, and its role in efficient learning.
Learning Rate and Batch Size
Two critical hyperparameters that influence training speed and convergence:
Learning Rate: How big the steps are toward the minimum loss
Batch Size: How many samples are used for each update
Adding Loss and Optimizer in Code
Demonstration of how to plug the loss function and SGD optimizer into a neural network using a modern ML framework.
🧰 Tools & Frameworks
Python
Keras / TensorFlow
NumPy / Matplotlib for data prep & visualization
📈 Expected Outcomes
By the end of this presentation, you will:
Understand how DNNs model complex relationships through stacked layers and nonlinear activation functions.
Know how SGD efficiently updates weights during training.
Be able to build and train a DNN using real code examples with proper loss functions and optimizers.
📎 References
https://www.tensorflow.org/learn
https://keras.io/guides/sequential_model/
https://cs231n.github.io/neural-networks-1/
https://ml-cheatsheet.readthedocs.io/en/latest/activation_functions.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}