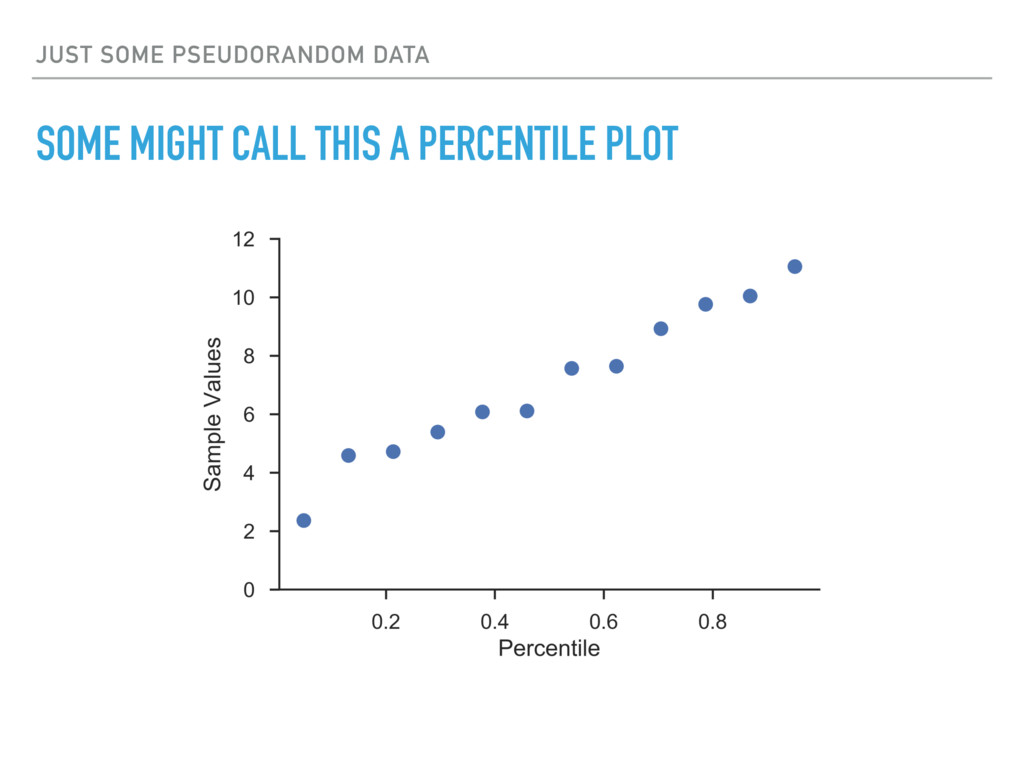
Sort your data ▸ Compute the ranks and plotting positions ▸ Create a scatter plot of the plotting positions vs. value Alpha and Beta independently range from 0 to 1 and are selected based on the applications.
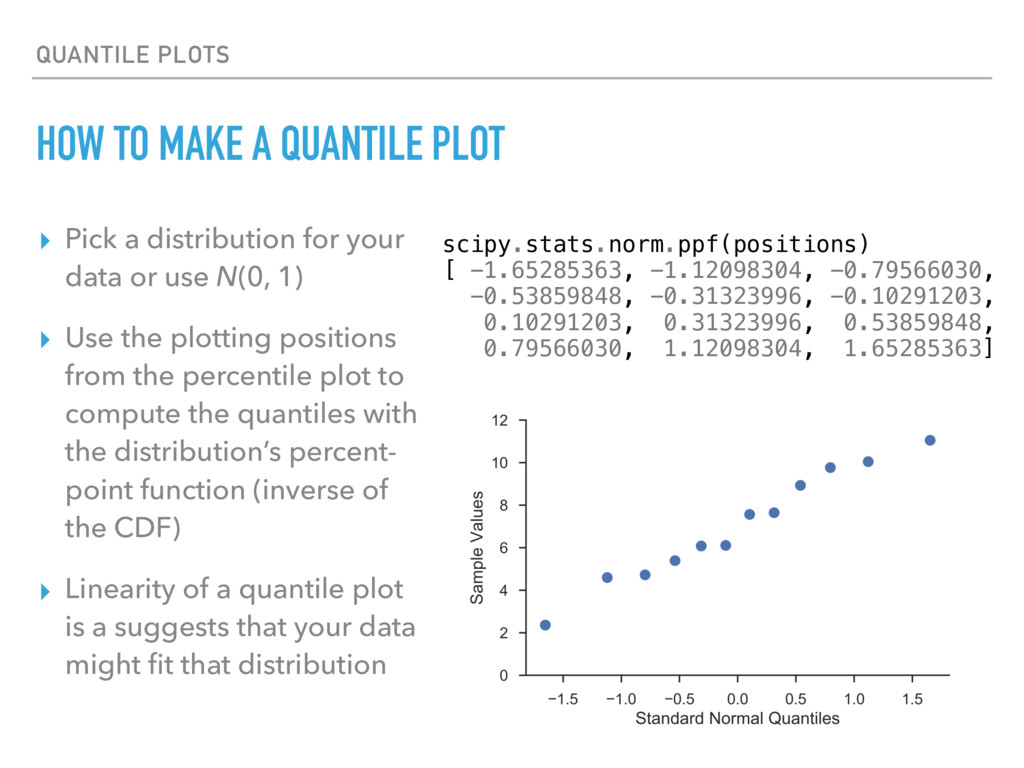
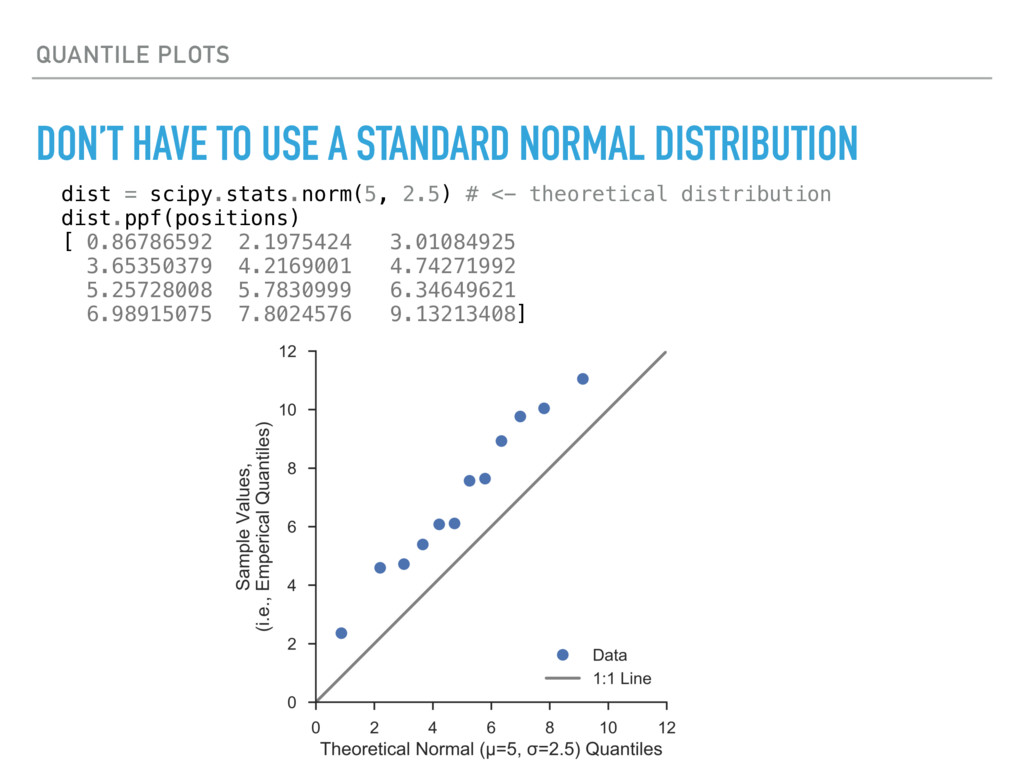
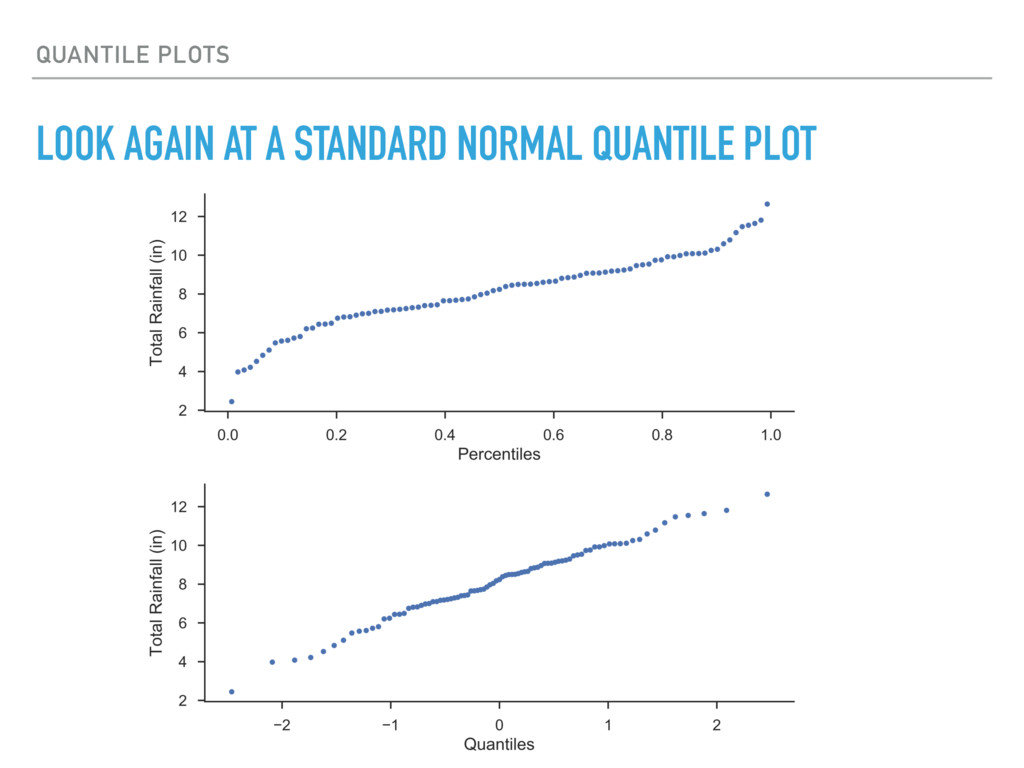
a distribution for your data or use N(0, 1) ▸ Use the plotting positions from the percentile plot to compute the quantiles with the distribution’s percent- point function (inverse of the CDF) ▸ Linearity of a quantile plot is a suggests that your data might fit that distribution scipy.stats.norm.ppf(positions) [ -1.65285363, -1.12098304, -0.79566030, -0.53859848, -0.31323996, -0.10291203, 0.10291203, 0.31323996, 0.53859848, 0.79566030, 1.12098304, 1.65285363]
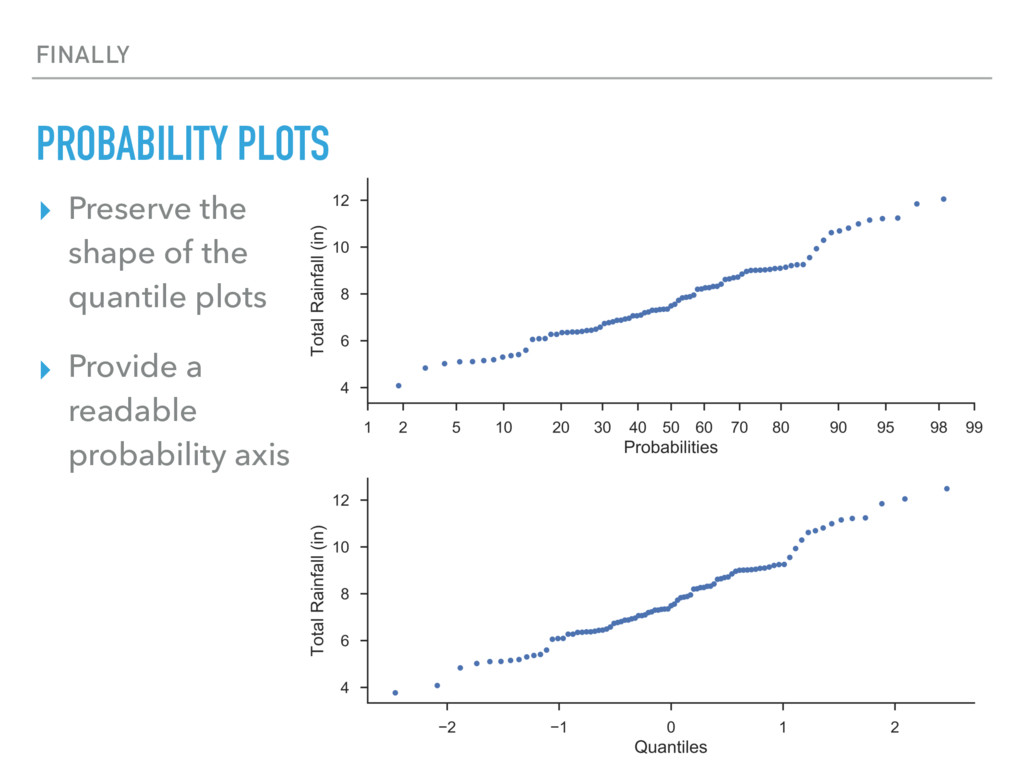
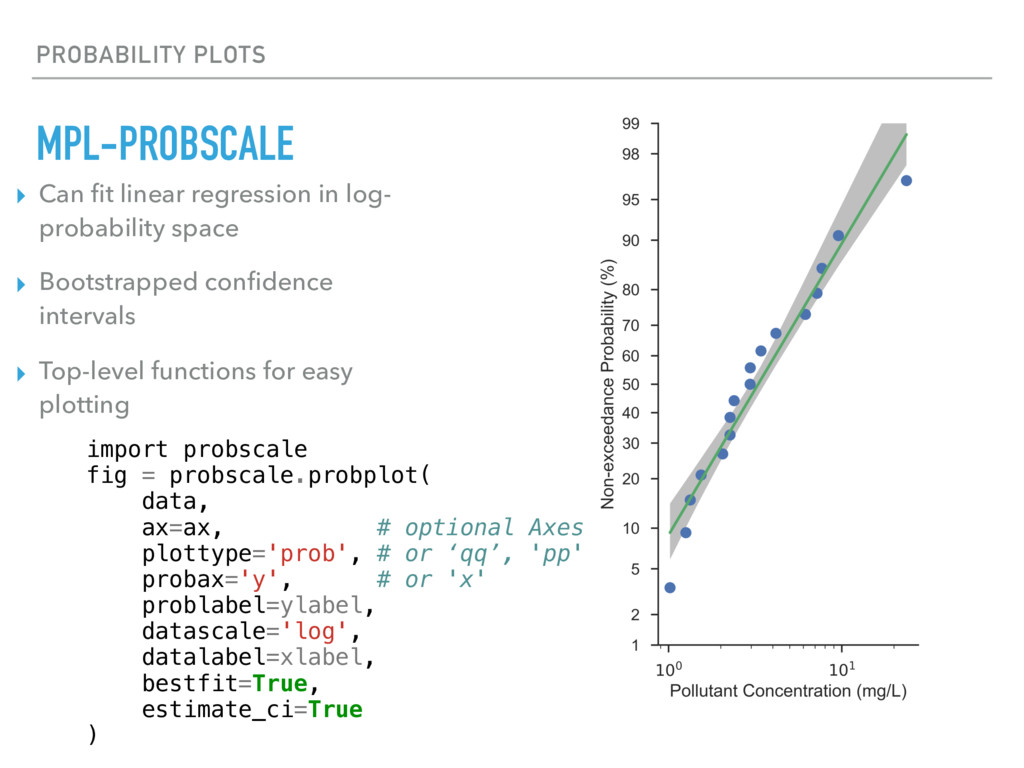
Similar to a quantile plot, but expressed as a probability instead of a z- score ▸ Simply import probscale and you’re set ▸ Uses MPL’s scale and transform APIs to implement and register the scale with MPL’s internals. ▸ Distribution agnostic. ▸ Format tick labels as percents or fractions (0 - 1) ▸ GET IT! $ conda install mpl-probscale --channel=conda-forge
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}