We’ve all heard the talk on Agile and Lean, and how we should develop our applications incrementally, but even if you’ve not dabbled into that yet, “change” is a truism in software, and soon or later you’re going to need to change something -- to cater for a new need or to fix a bug.
For the most part, applying code changes incrementally is known and handled by most people graciously, yet there’s one -- dreadful - component that is usually a little harder to manage, the database.
Typically, people will be using some sort of ORM such as Hibernate to interact with the database and define their schema, and during development, any change to their “models” implies resetting the database as to apply the new changes. That works fine for development, but once the app is in production they can no longer just “reset”. Which is when they finally resort to writing SQL by hand and applying it directly onto the database. There’s nothing wrong with that, but it could be better for now they’ve got a few more problems:
- How can they ensure that the schema is in sync with the code?
- How can they share the schema changes with their colleagues?
- How can they ensure that they can go back to a safe state if some problem happens during their manual schema updates run? “Taking a backup before, doing the change, and rolling back if a problem arises perhaps?”
- If they use branches for working on different tasks, how can they avoid the “oh, I was working on feature A and I changed the schema, so now that I’m on feature B the schema is broken”.
Enter database schema migrations. Migrations are a mechanism that allows you to solve all of the issues above. In this session, we’ll know exactly what they’re and how we can use them in the context of PHP applications.
I’d be remiss not to say that most PHP frameworks today already come with a database migration tool which you can use to construct and make changes to your database and easily share them through your version control system of choice. Though that is true, not all software is greenfield, a lot of it is brownfield. Thus, learning Phinx may still useful.
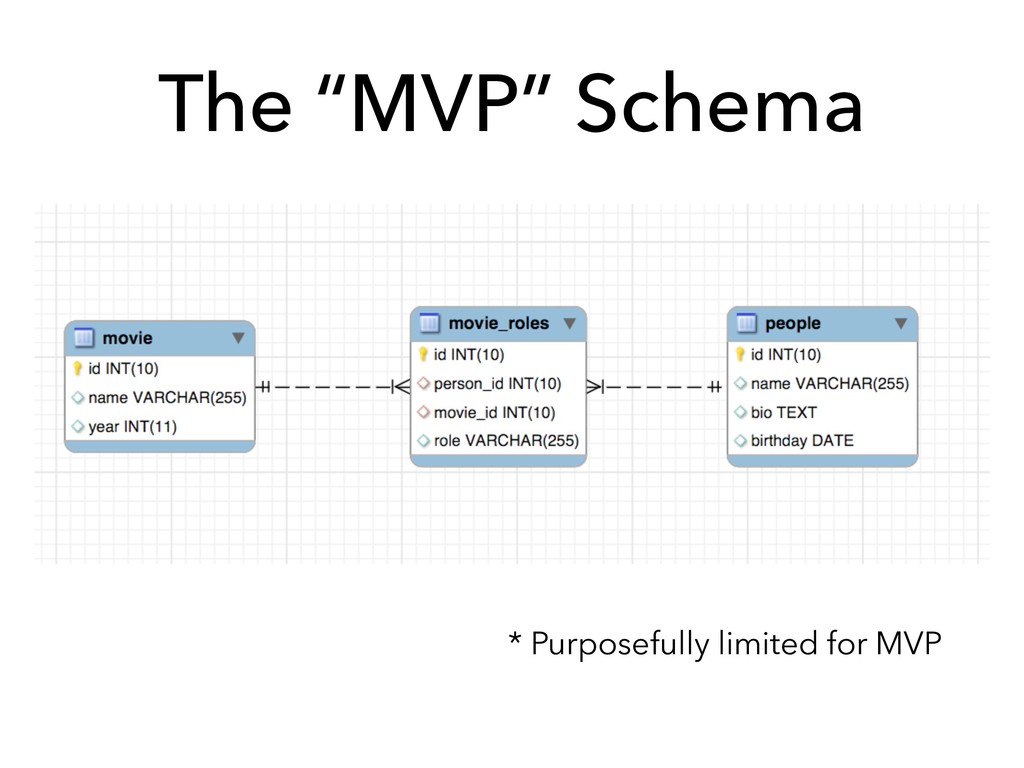
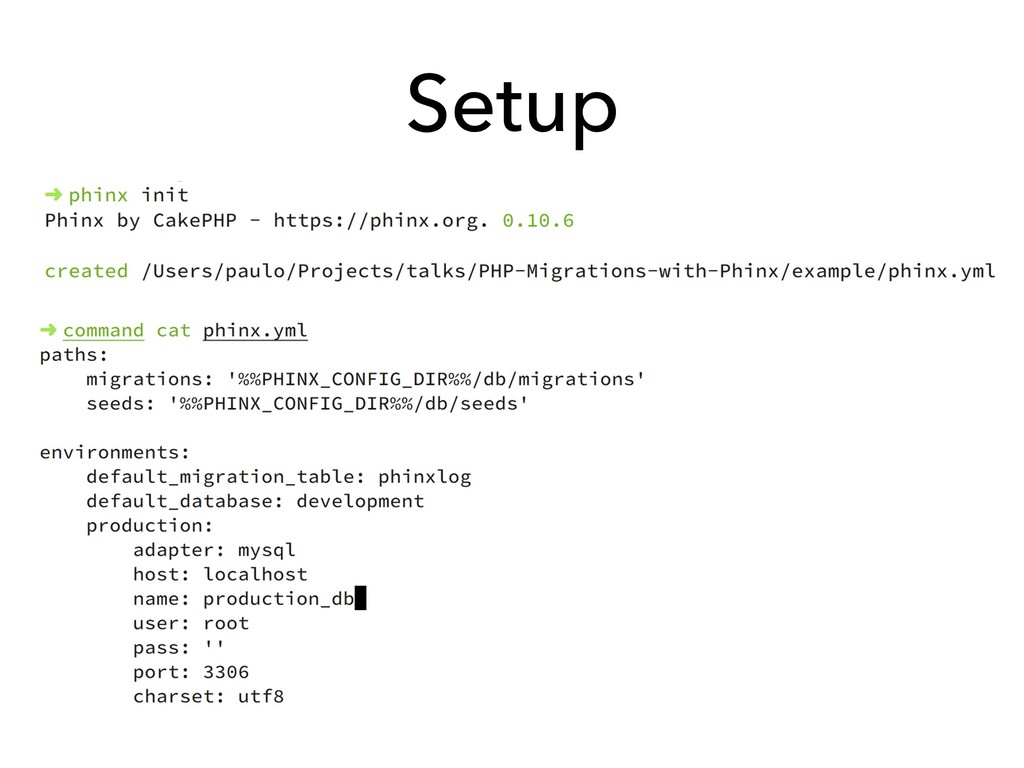
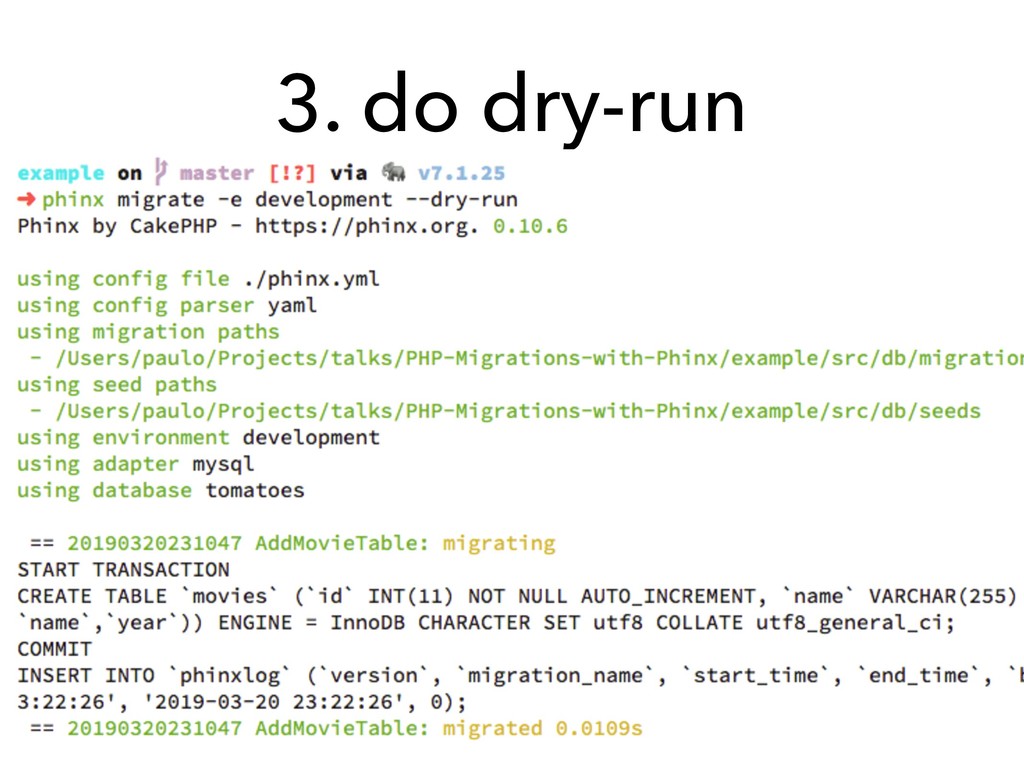
This talk is about how we can design our databases in an evolutionary fashion by using database schema migrations, more specifically in the PHP language using the [Phinx](https://phinx.org) library.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}