Cheap code branches permeate our daily workflow, but the code we write is only half the story. Introducing data model changes into production can challenge developers and ops people alike, but how do we deal with these issues in our experimental phase?
In this talk, we'll discuss using features provided by modern filesystems like ZFS & Btrfs to branch databases along with code, letting developers experiment and ops people model complex environments, all from the comfort of our laptops.
{kind=link}
![JD Harrington [email protected] @psi work at Saturday,](https://files.speakerdeck.com/presentations/f25747d0b2a10130fbb44677e9ed93b5/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
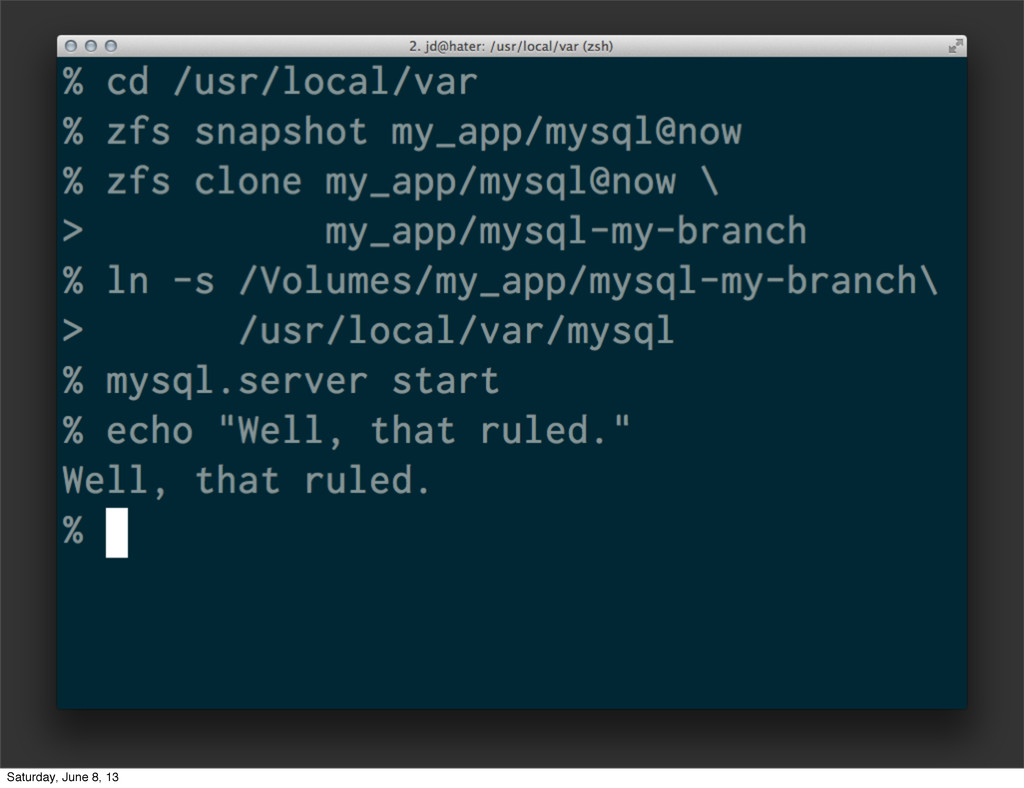{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
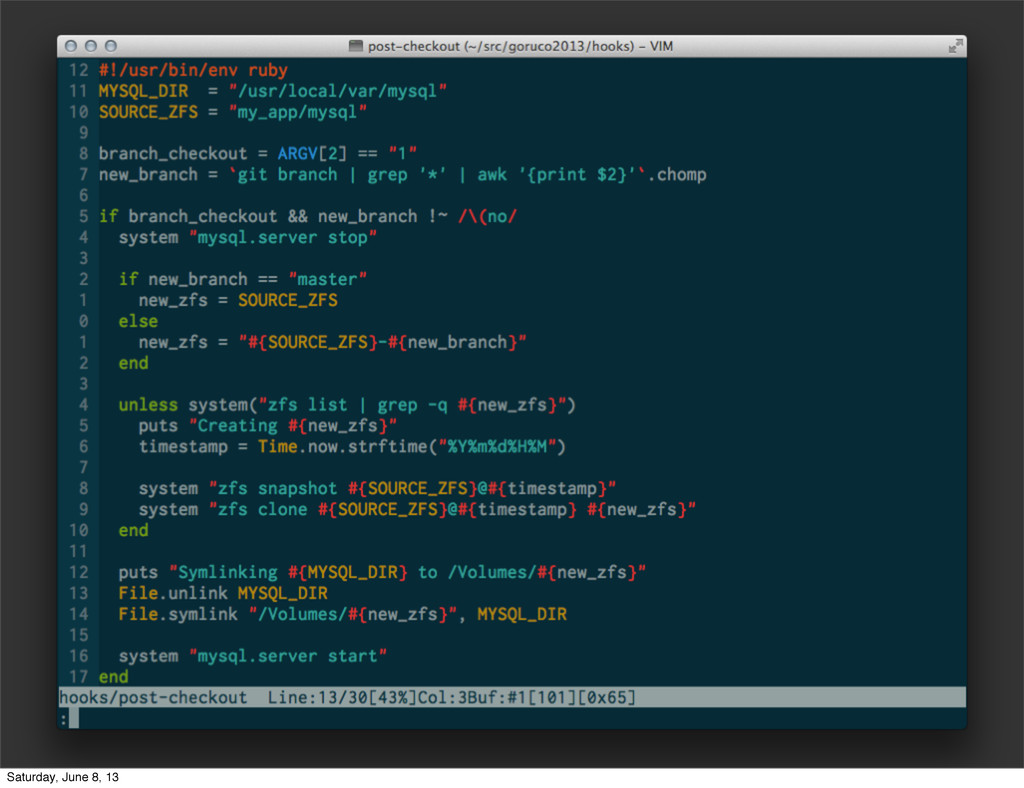{kind=link}
{kind=link}
{kind=link}
{kind=link}