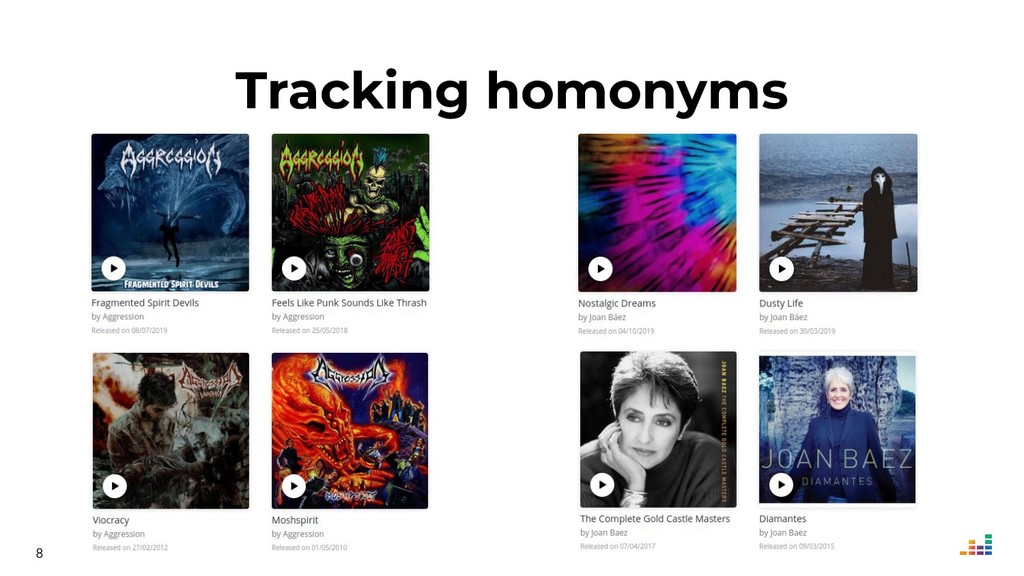
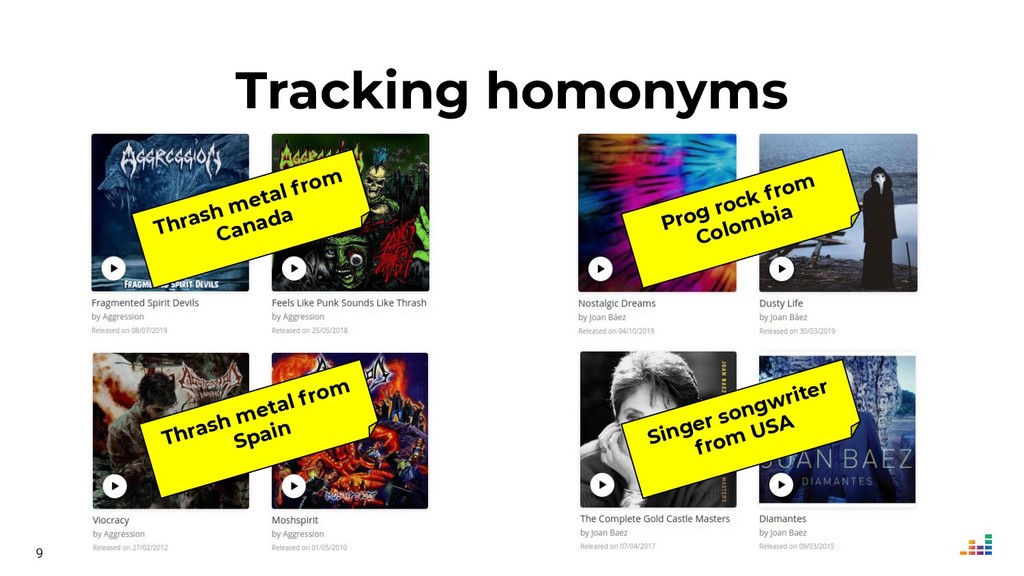
Did you know American singer/songwriter Joan Baez has a near-homonym in Colombia, Joan Báez, who plays progressive rock?
Did you know there are (at least) two bands called Aggression that play thrash metal?
Jazzman Avishai Cohen, anyone? There are two contemporary jazz musicians who go by that name.
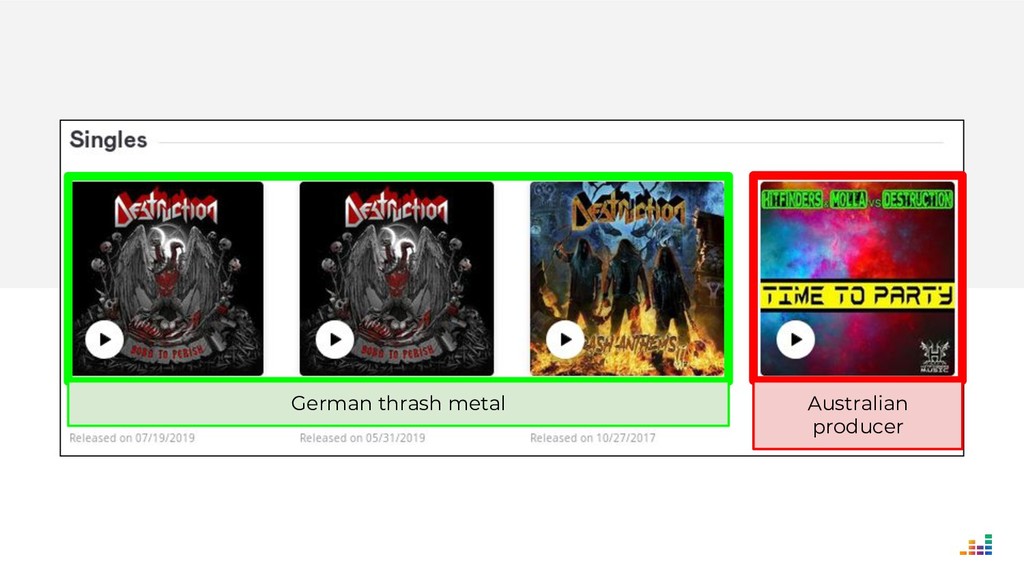
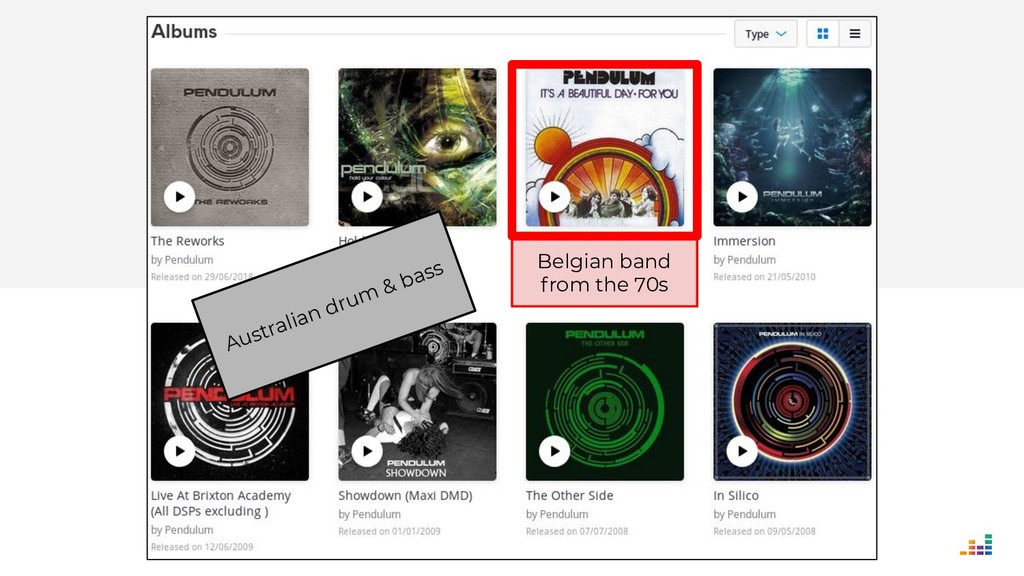
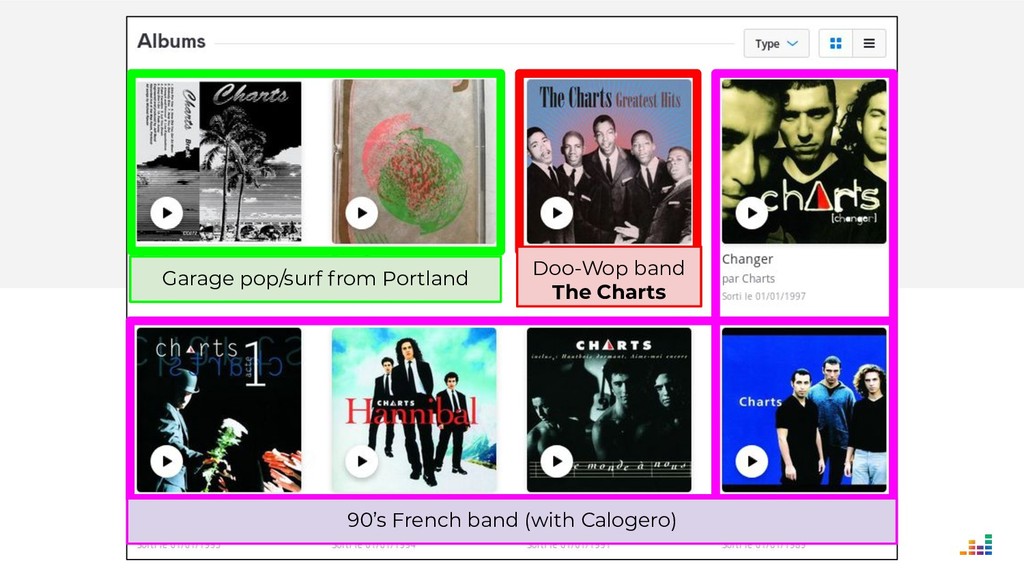
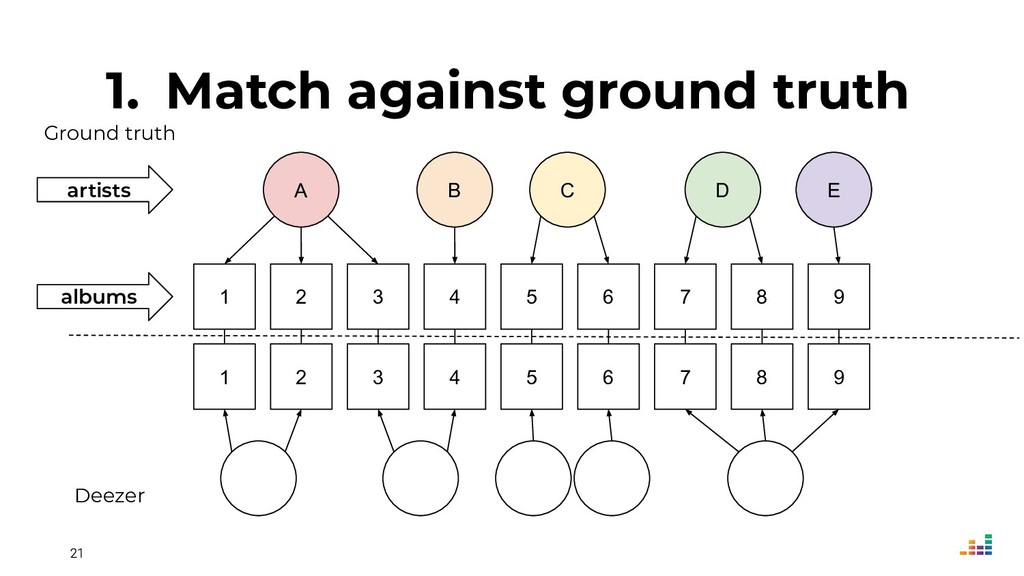
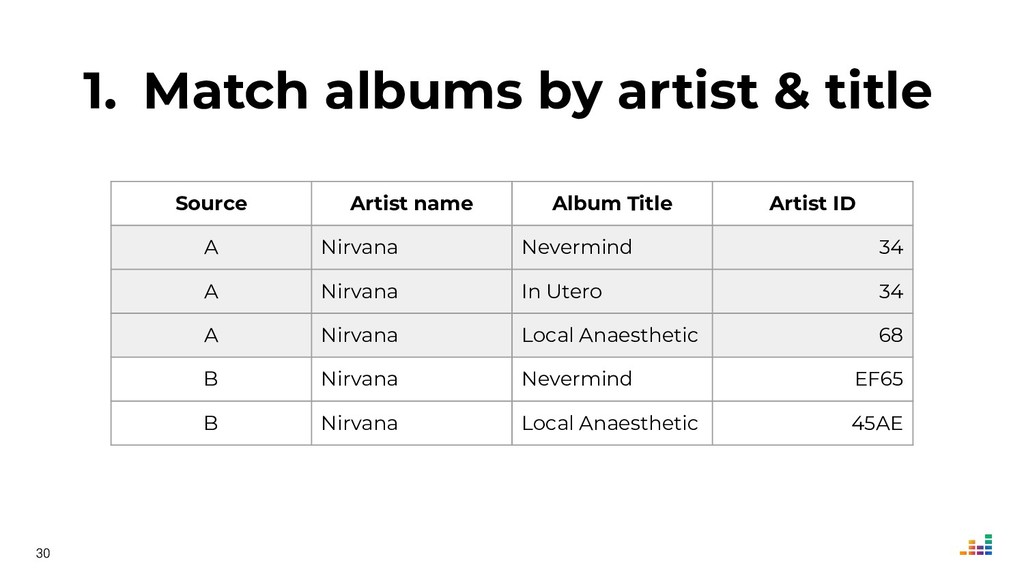
At Deezer, the data we receive from music labels is often ambiguous. And if we display an album in the wrong artist page, users get (rightfully!) mad and may turn to the competition the next time they want to listen to their favorite tracks.
In this talk, I'll present some of the techniques we use to verify our metadata and fix our music catalog.
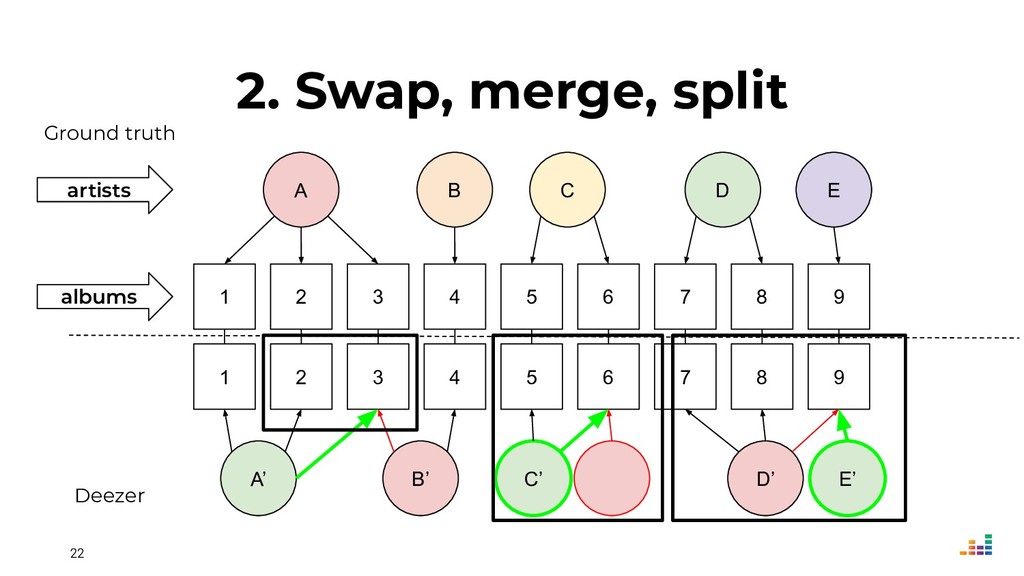
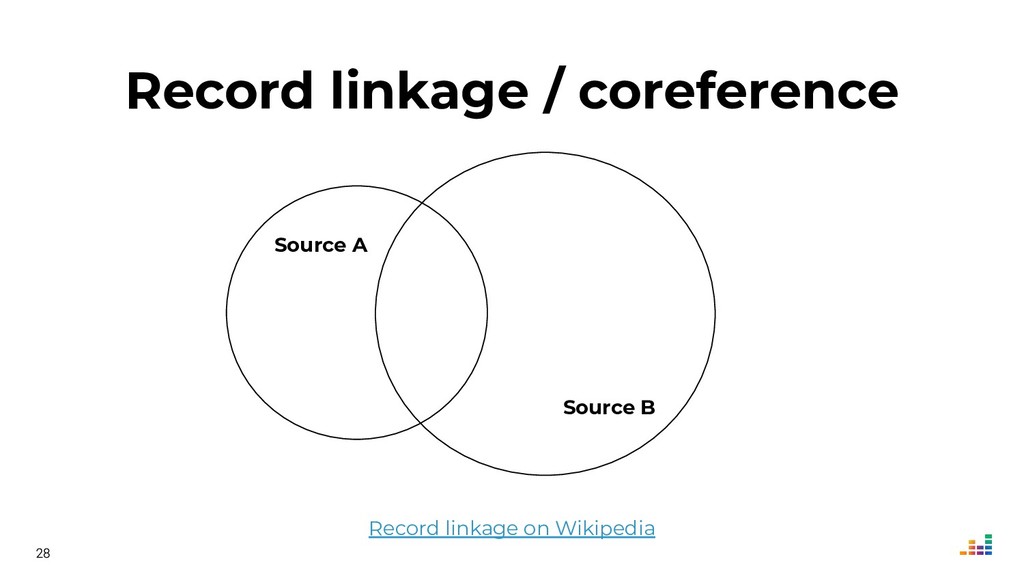
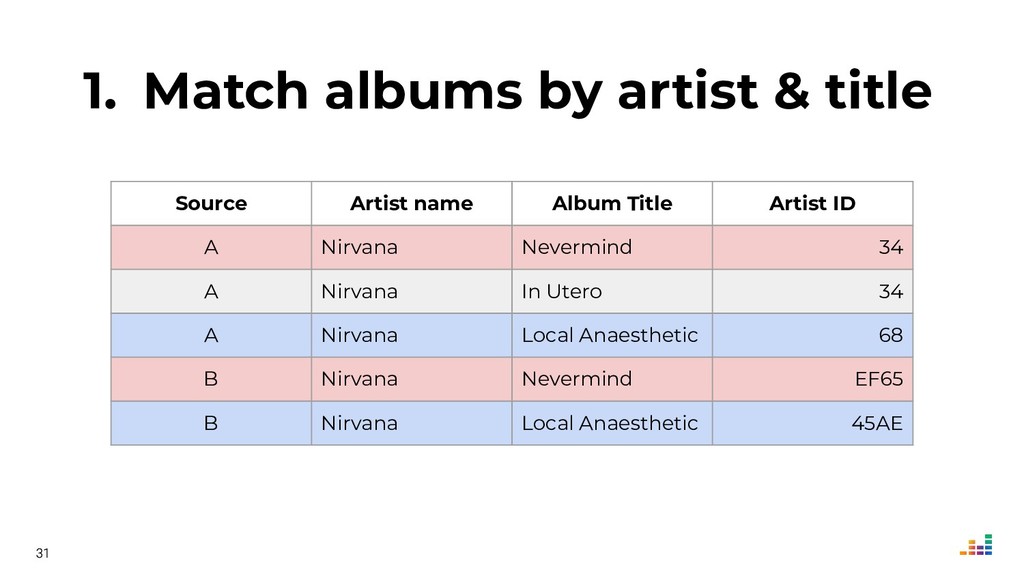
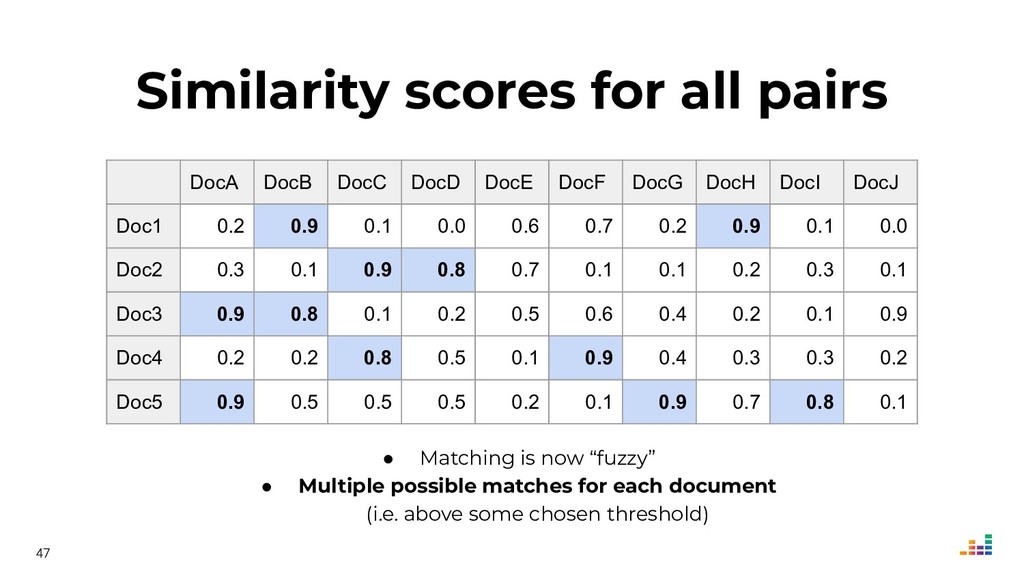
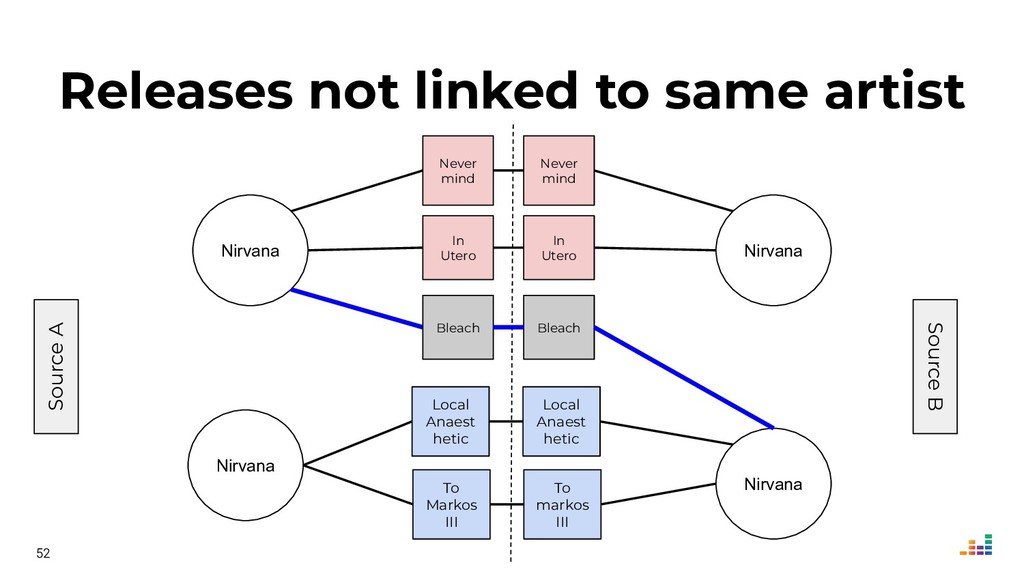
We leverage several metadata sources to consolidate a "source of truth" which then helps us spot & correct errors in our database.
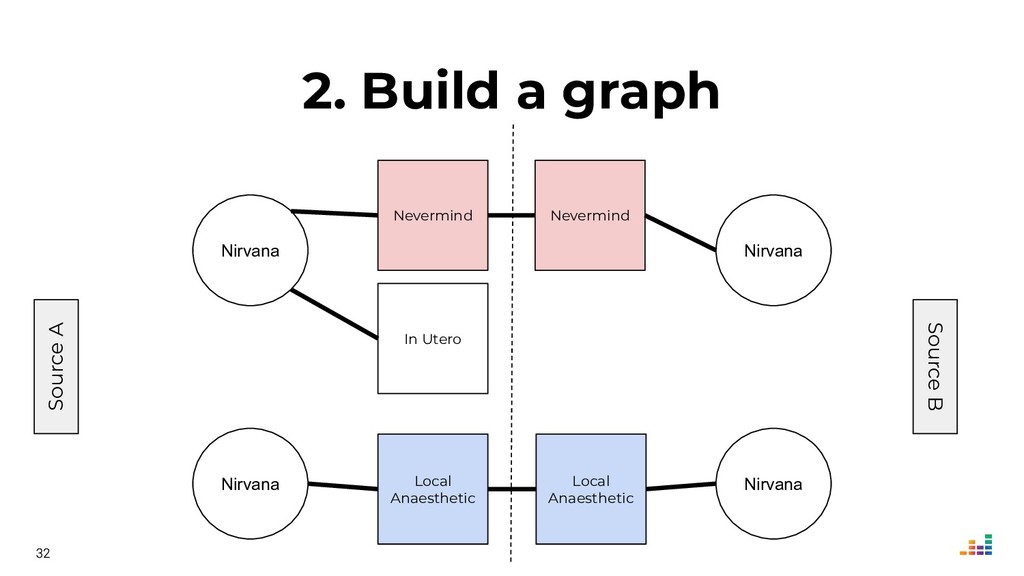
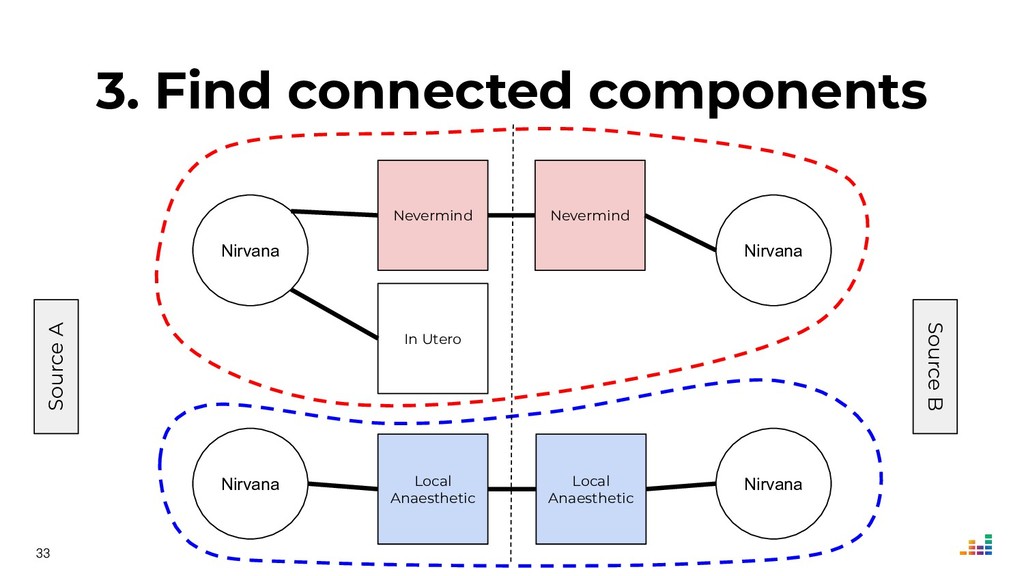
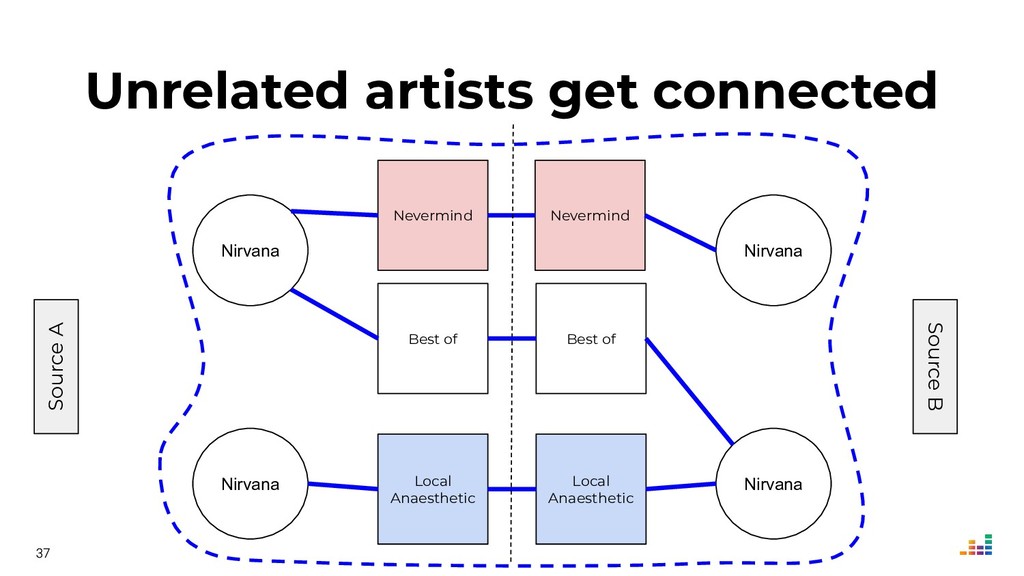
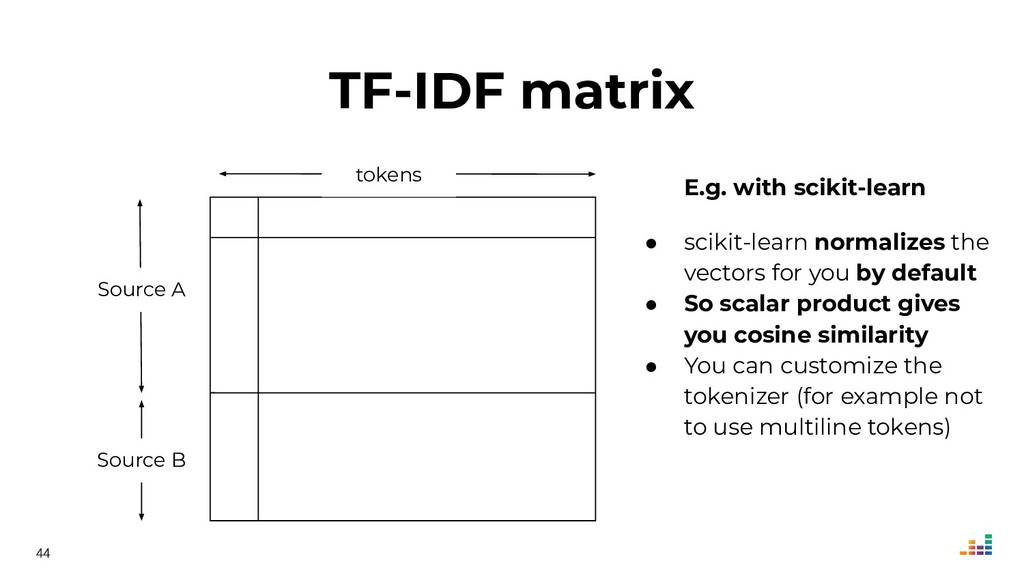
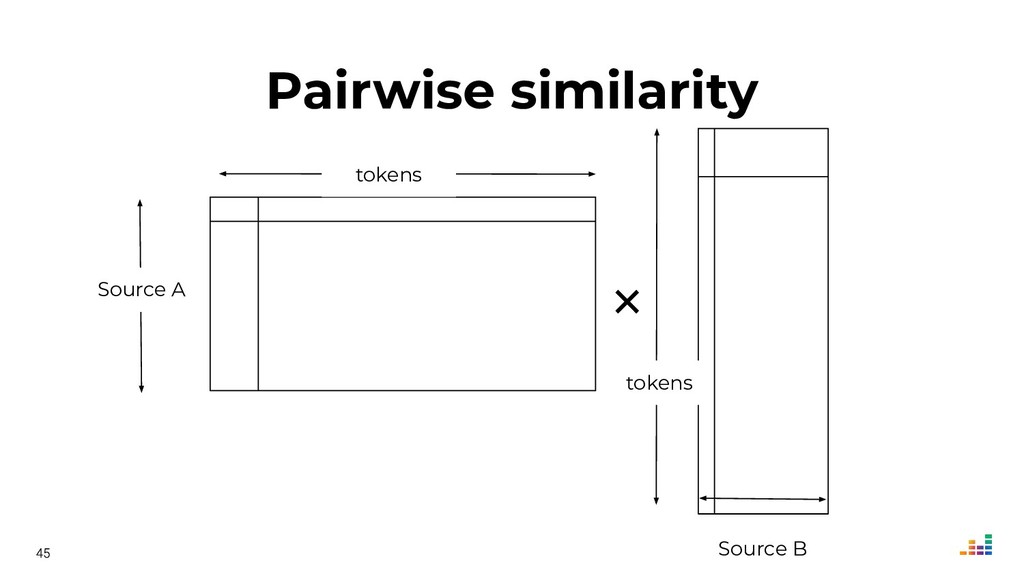
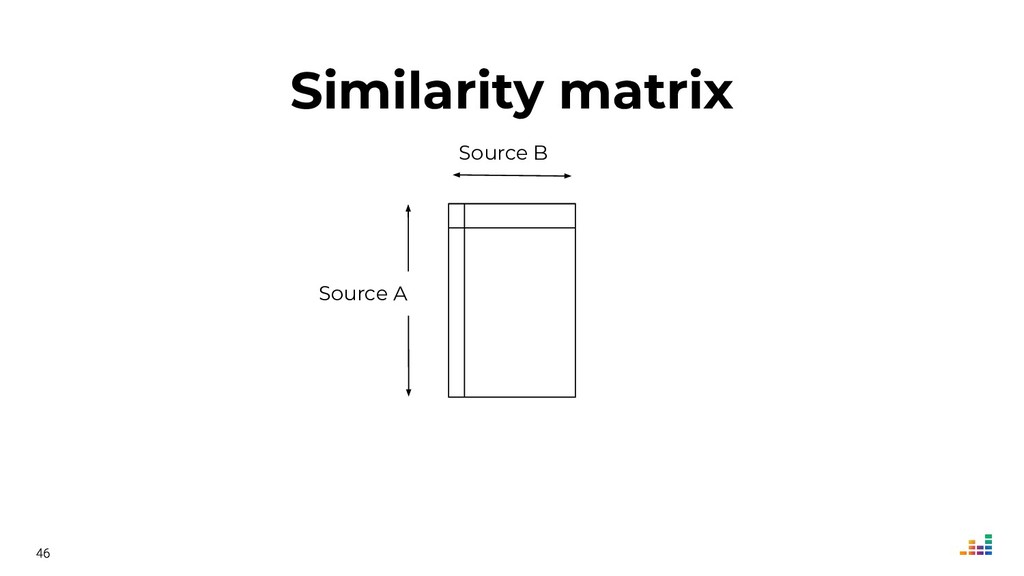
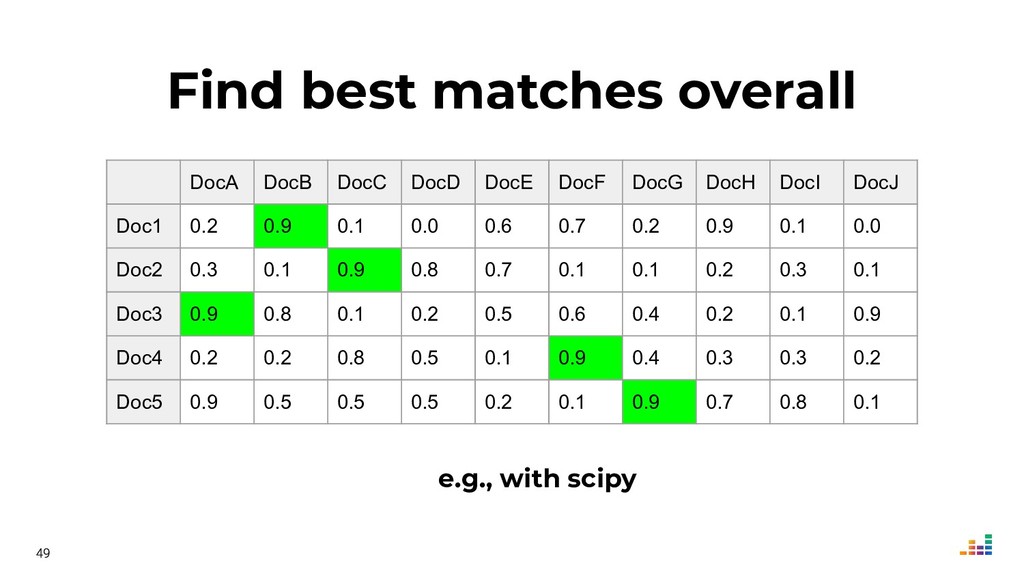
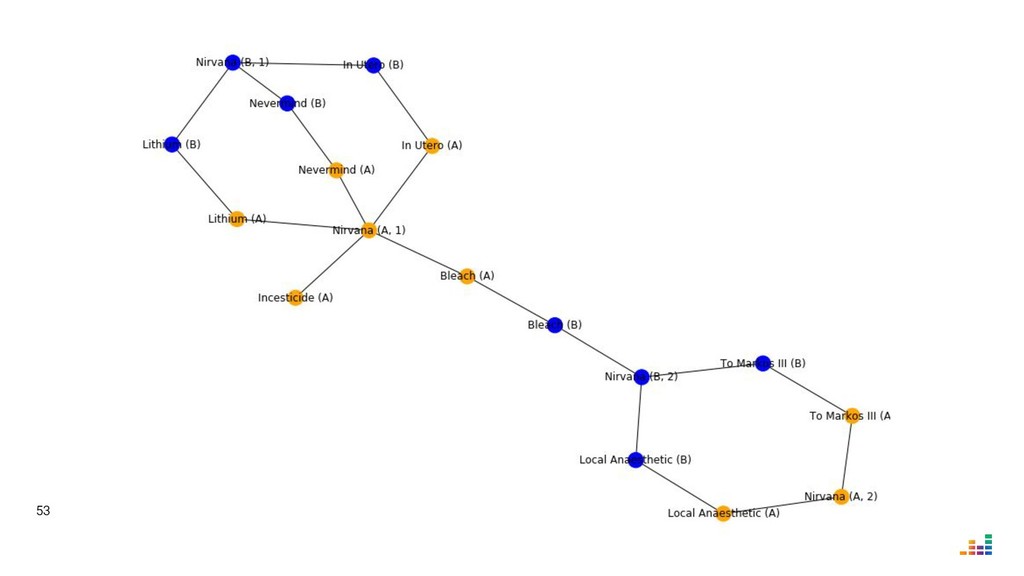
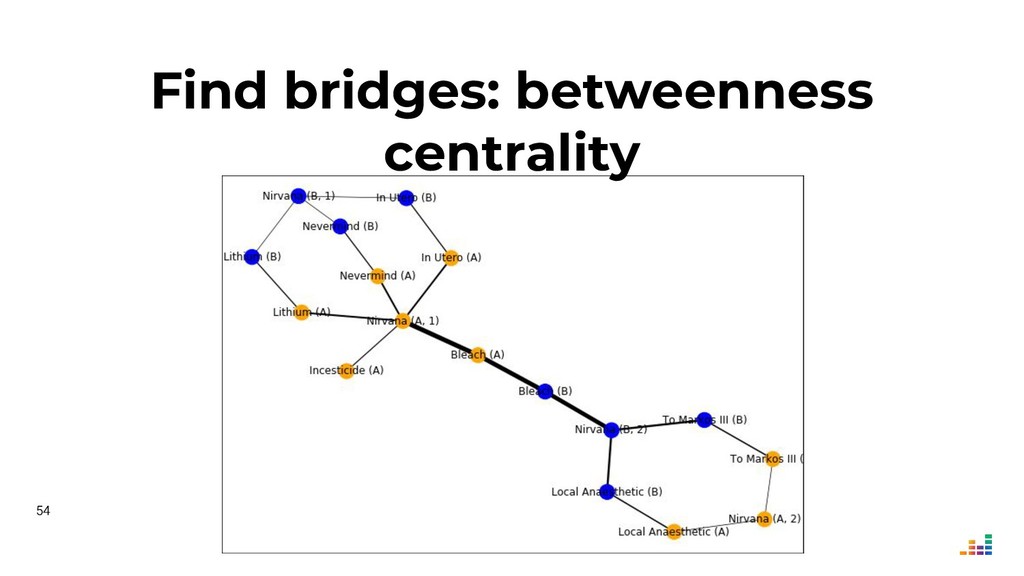
We'll explore topics like record linkage, bag-of-words, TF-IDF, graph algorithms and community detection. All of this in Python using scikit-learn, scipy and networkx.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}