Description
This talk will present strategies in Python for handling data that is too large to fit in memory and/or too slow to process in one thread, but small enough to still fit in one machine.
Abstract
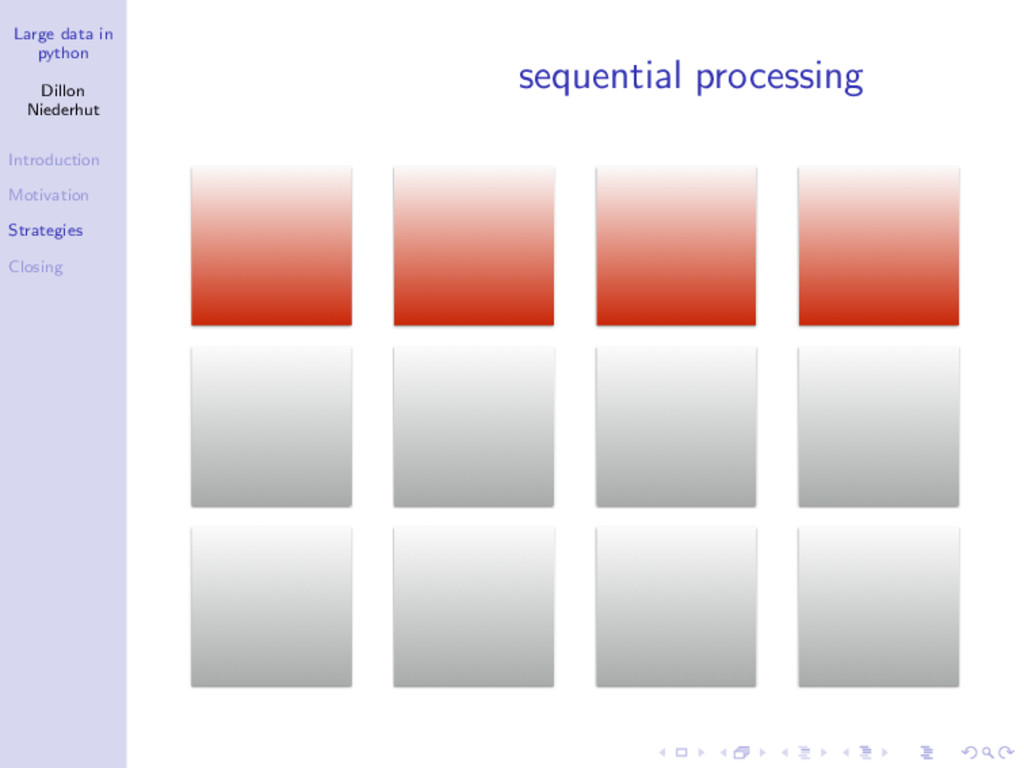
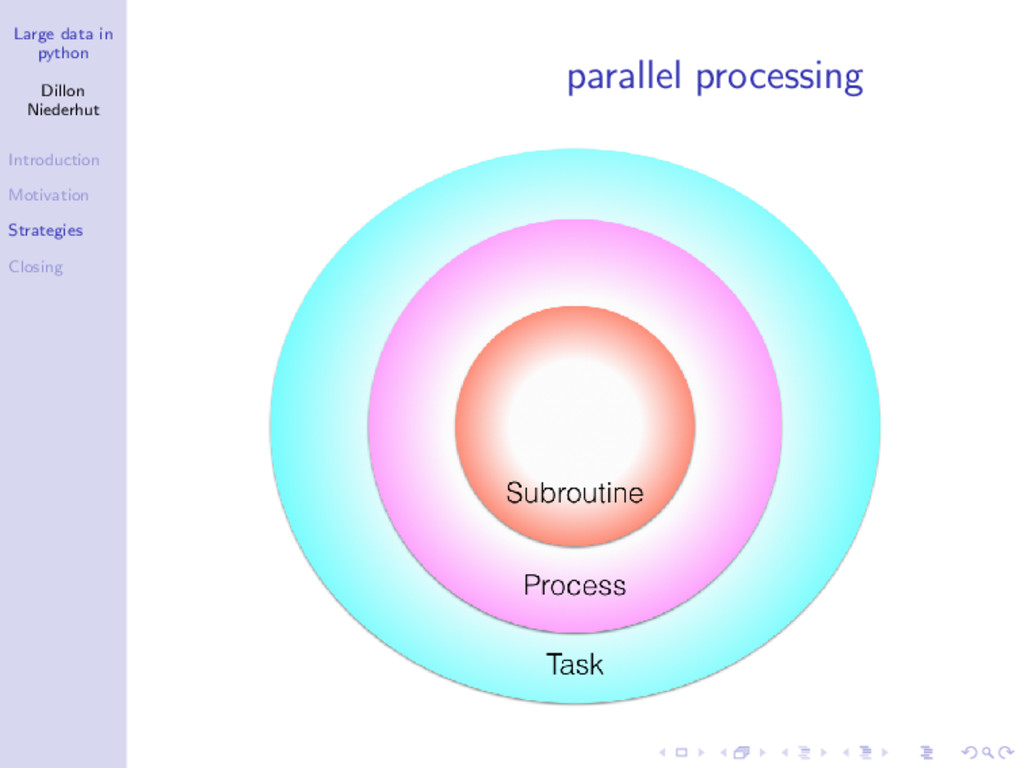
Unless you work at a large internet company, you probably don't have BIG data, but you might have LARGE data. Large data consume an unacceptable amount of time and memory when medium strategies are used, but also incur unnecessary financial and latency costs when big strategies are used. Two basic strategies for handling large data, chunking and parallelization, will be discussed with live coded examples in Python.
Bio
I'm a research scientist currently living in the Bay Area and working in neuroethology, human evolution, and natural language processing. I currently work at D-Lab, where I help researchers apply advances in computation to their research paradigms.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}