How not to fall into a rabbit hole when debugging mysterious bugs in a large open source library.
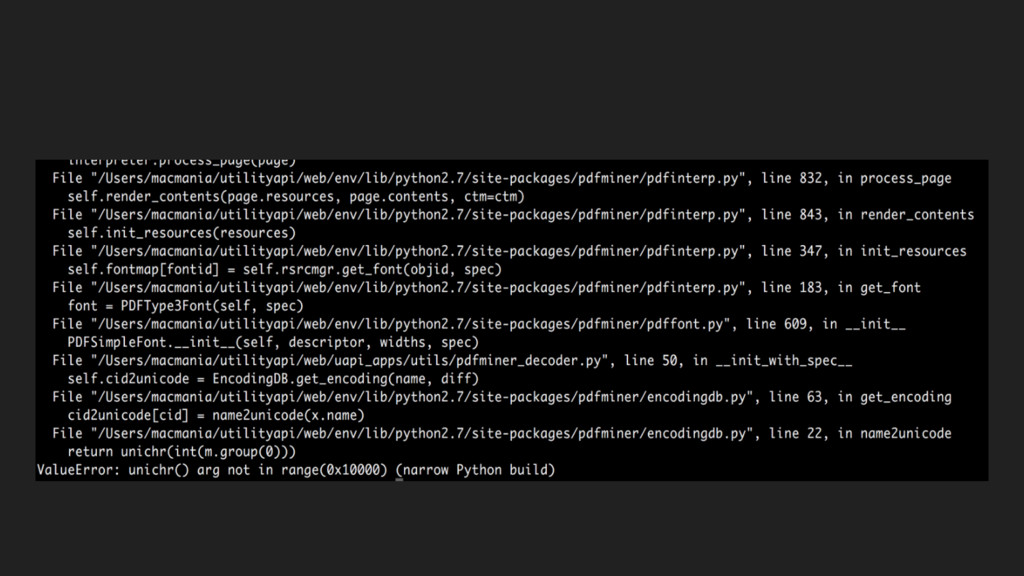
Almost everyone uses some open source library, but when that library fails to do what you want - i.e. decoding only 2 pages out of a 4 page pdf file or it just straight up raises an exception.
Many would dive deep into the code. In this talk, I will try to convince you *not to do that* by sharing my anecdotal experiences such as finding an elusive unicode character encoding difference between two popular OS's from a large open source project.
Video: https://youtu.be/nAhjroo374I
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}