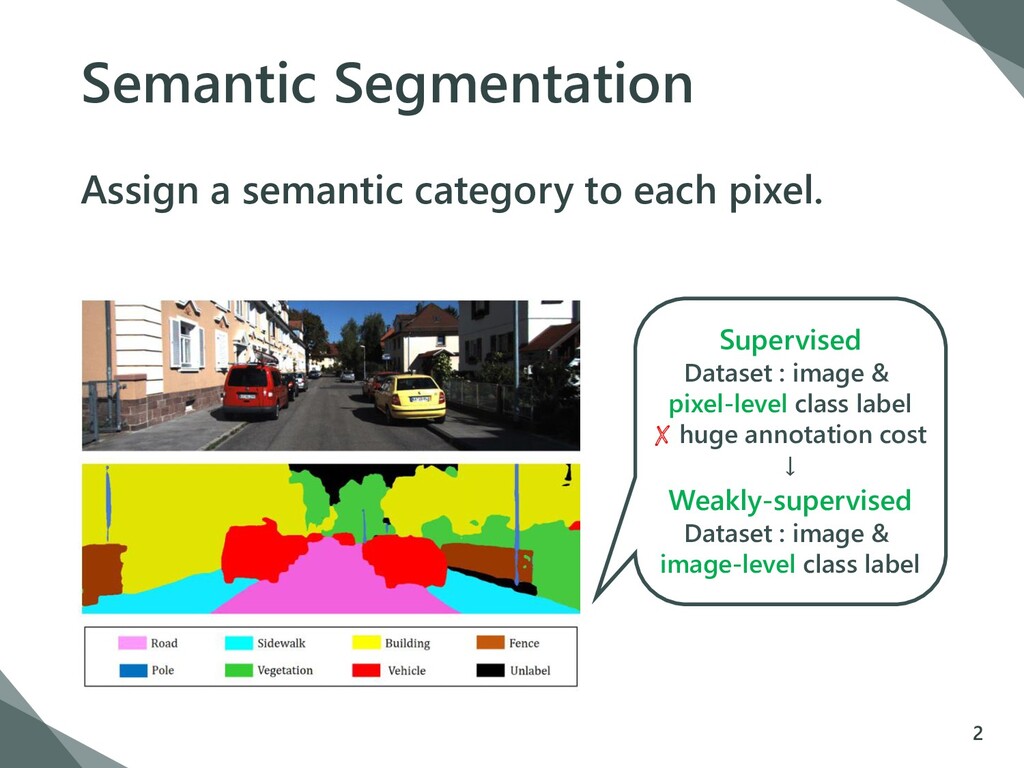
label. 1. predict an initial category-wise response map to localize the object 2. refine the initial response as the pseudo GT 3. train the segmentation network based on pseudo labels 3 1 2 3
label. 1. predict an initial category-wise response map to localize the object 2. refine the initial response as the pseudo GT 3. train the segmentation network based on pseudo labels 4 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Self Attention [Wang+, CVPR18] Non-local mean operation x : input](https://files.speakerdeck.com/presentations/95a0d71f40b24c4ca9b7c18211a37dde/slide_12.jpg){kind=link}
![Self Attention [Wang+, CVPR18] Non-local block 14](https://files.speakerdeck.com/presentations/95a0d71f40b24c4ca9b7c18211a37dde/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
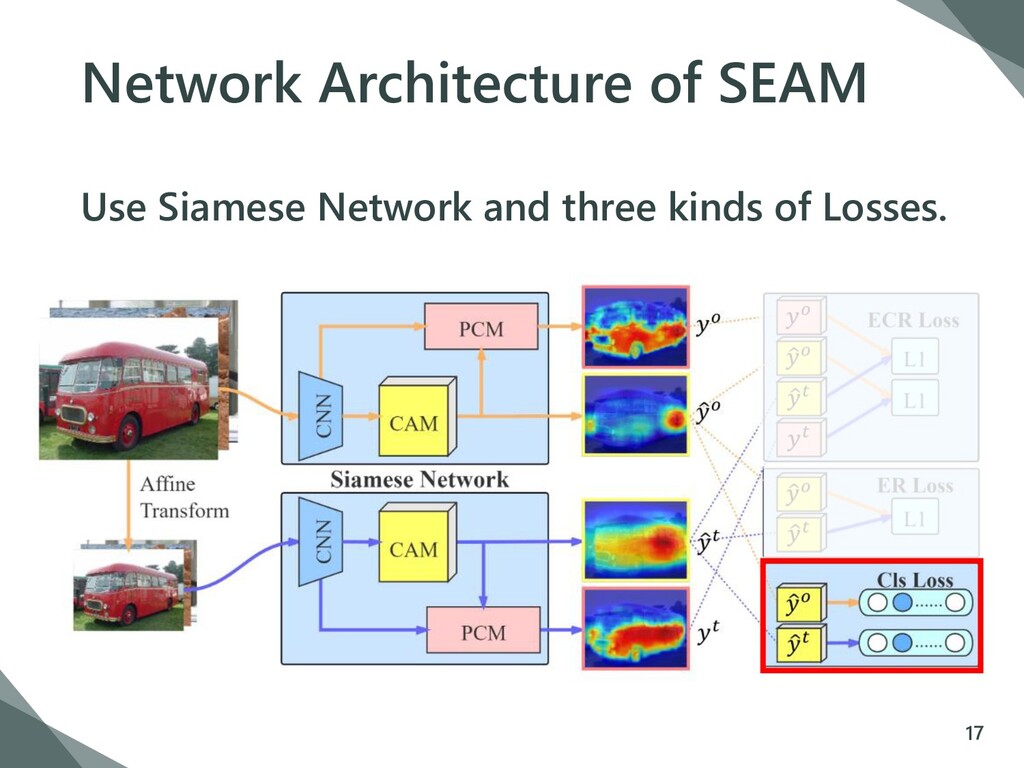{kind=link}
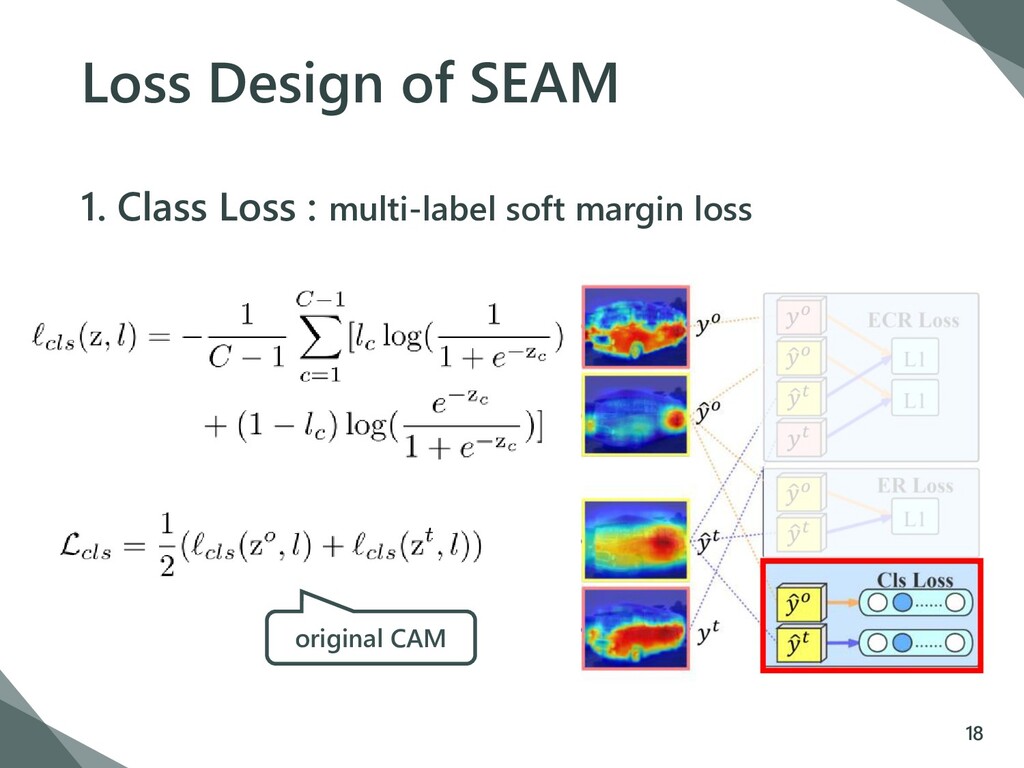{kind=link}
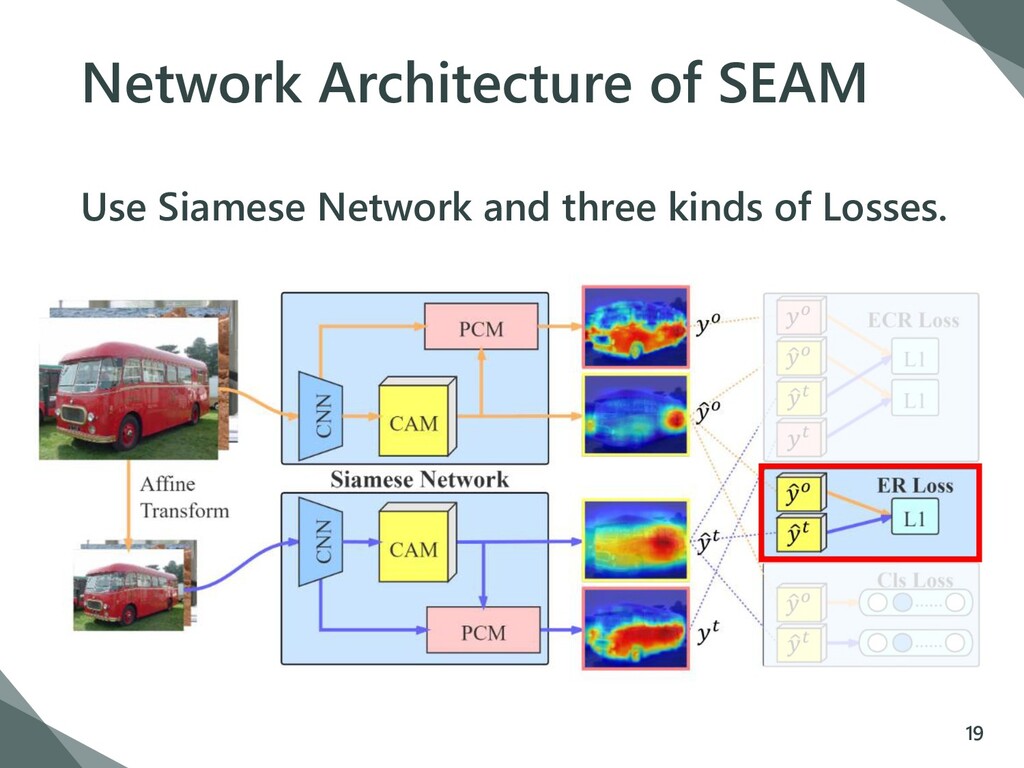{kind=link}
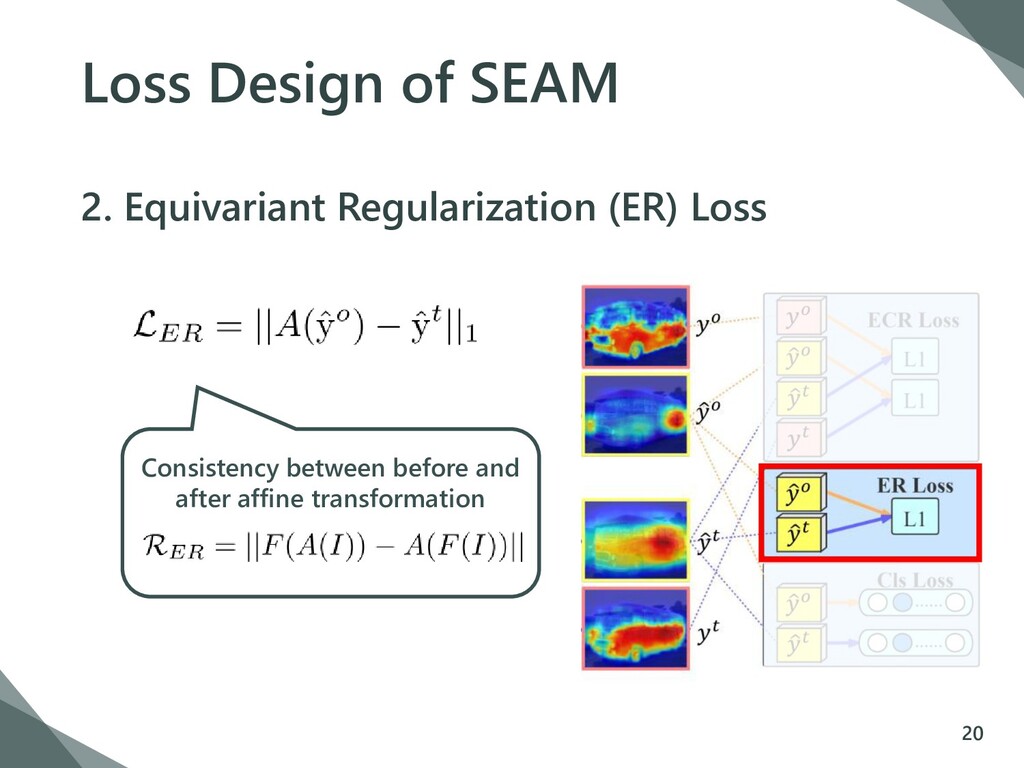{kind=link}
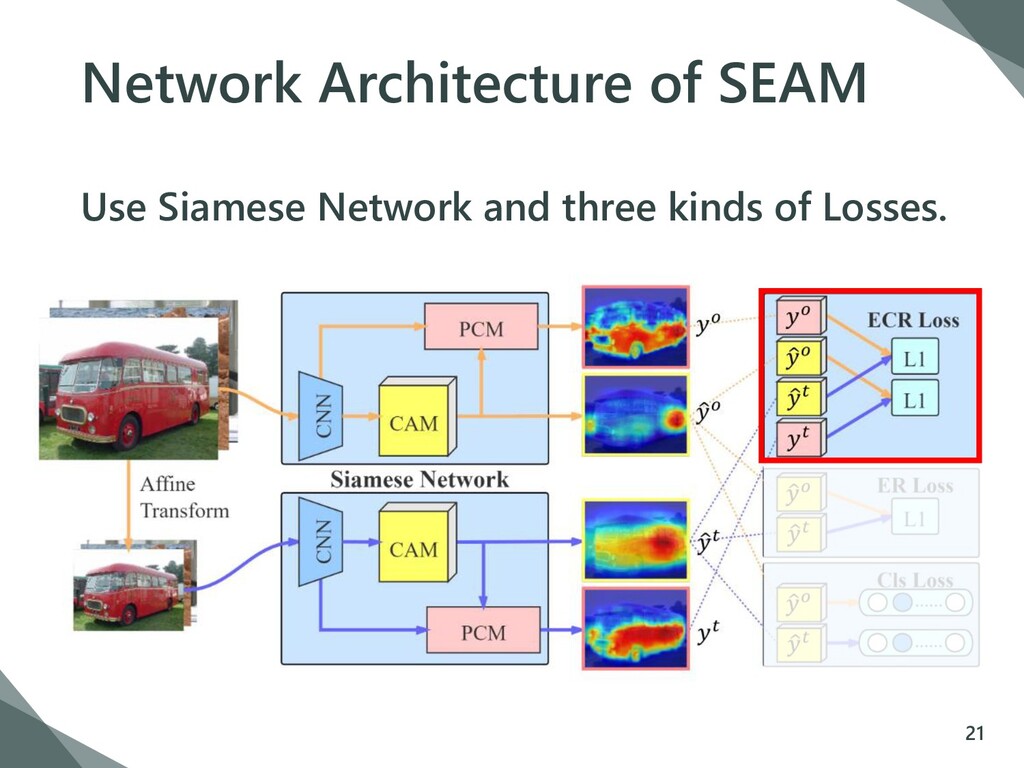{kind=link}
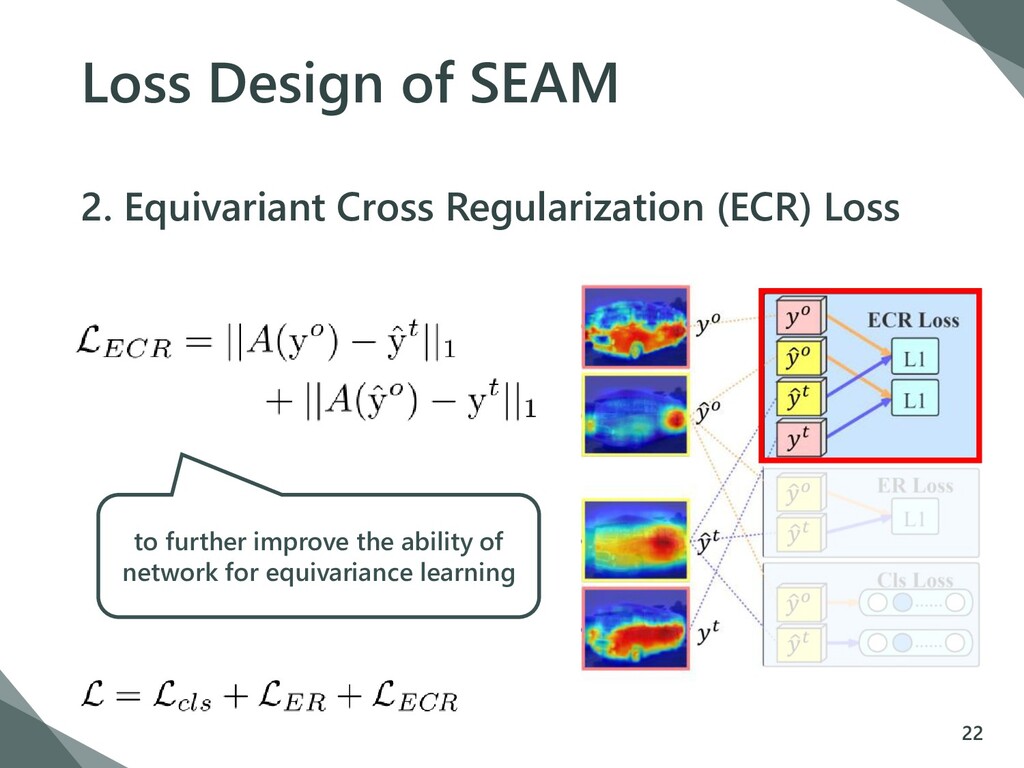{kind=link}
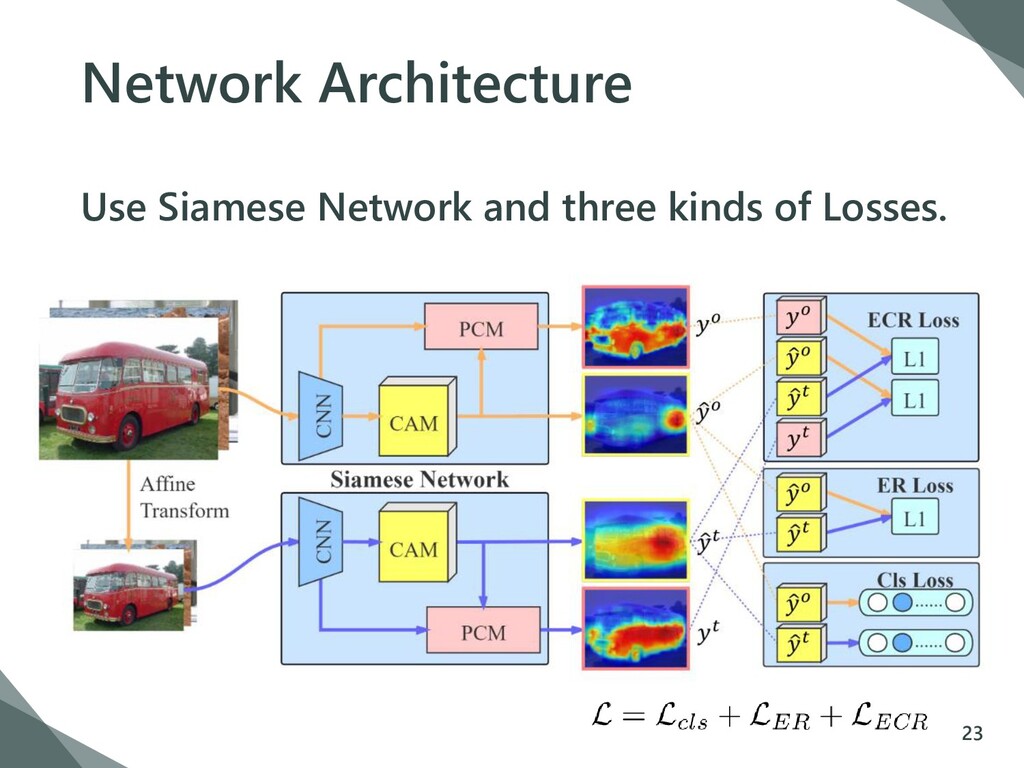{kind=link}
{kind=link}
{kind=link}
{kind=link}
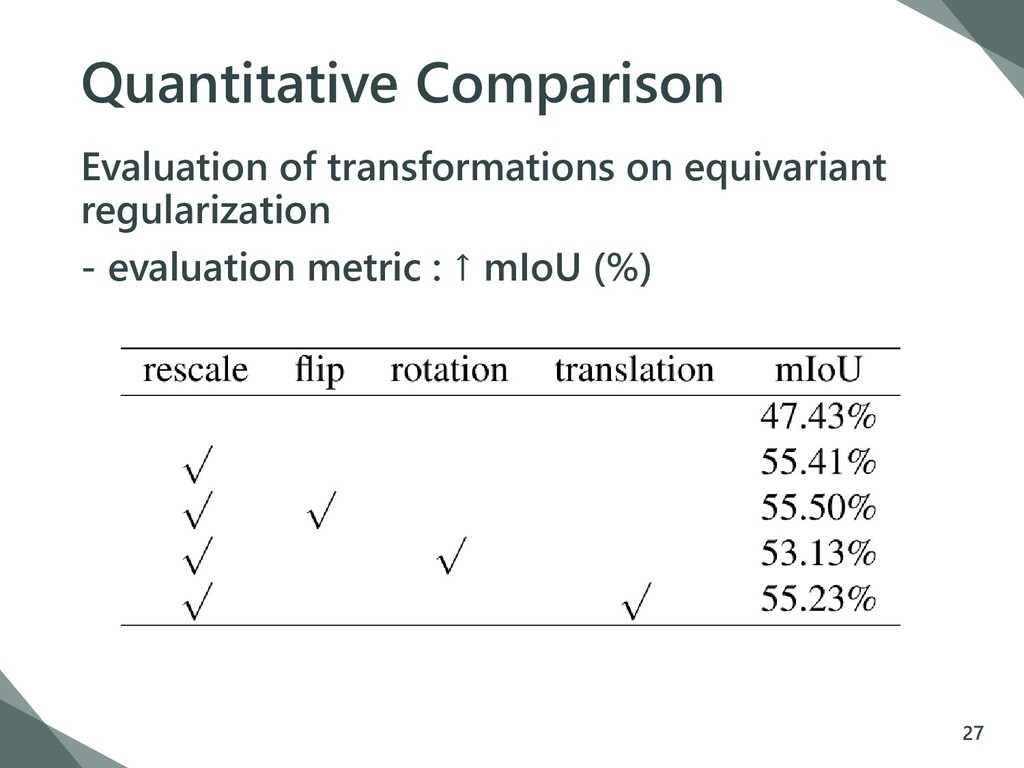{kind=link}
{kind=link}
![Quantitative Comparison Evaluation of WSSS performance 29 [Chang+, CVPR20] val](https://files.speakerdeck.com/presentations/95a0d71f40b24c4ca9b7c18211a37dde/slide_28.jpg){kind=link}
{kind=link}