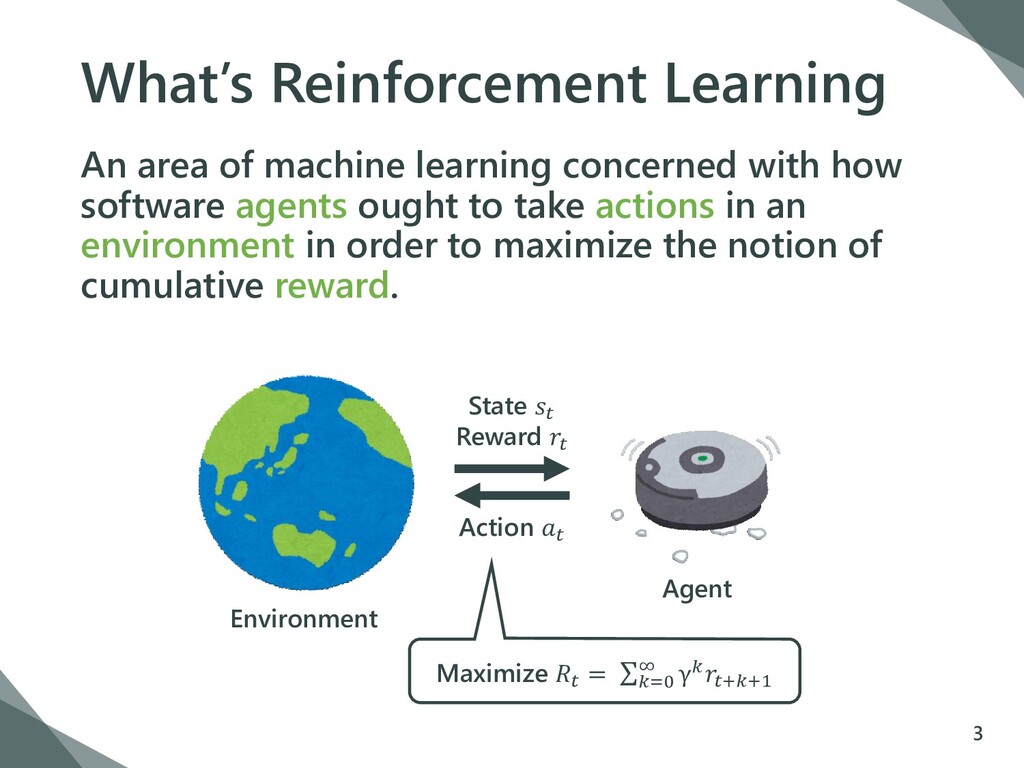
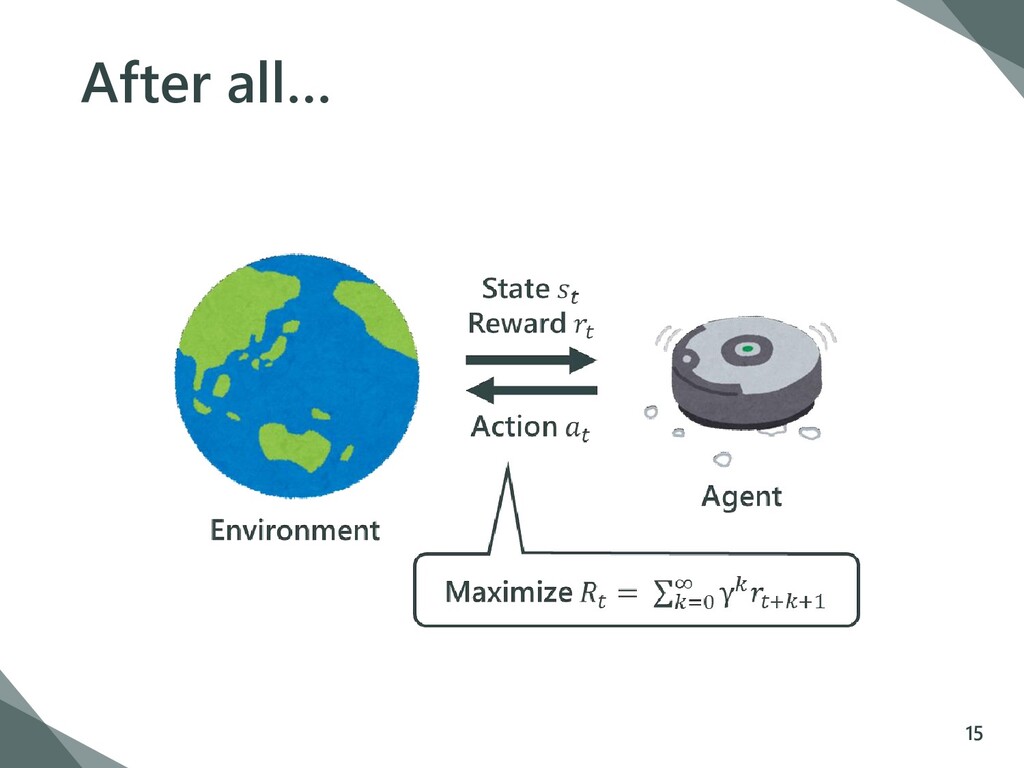
how software agents ought to take actions in an environment in order to maximize the notion of cumulative reward. 3 Environment Agent State Reward Action Maximize = σ=0 ∞ γ++1
selection State Value Function π −the expected return starting with state under π −"how good" it is to be in the given state Action Value Function π(, ) −the action-value of (, ) under π 4
to discrete values −slow learning because of ignorance of the relationships between values −the curse of dimensionality → approximate the Q-function by NN 10
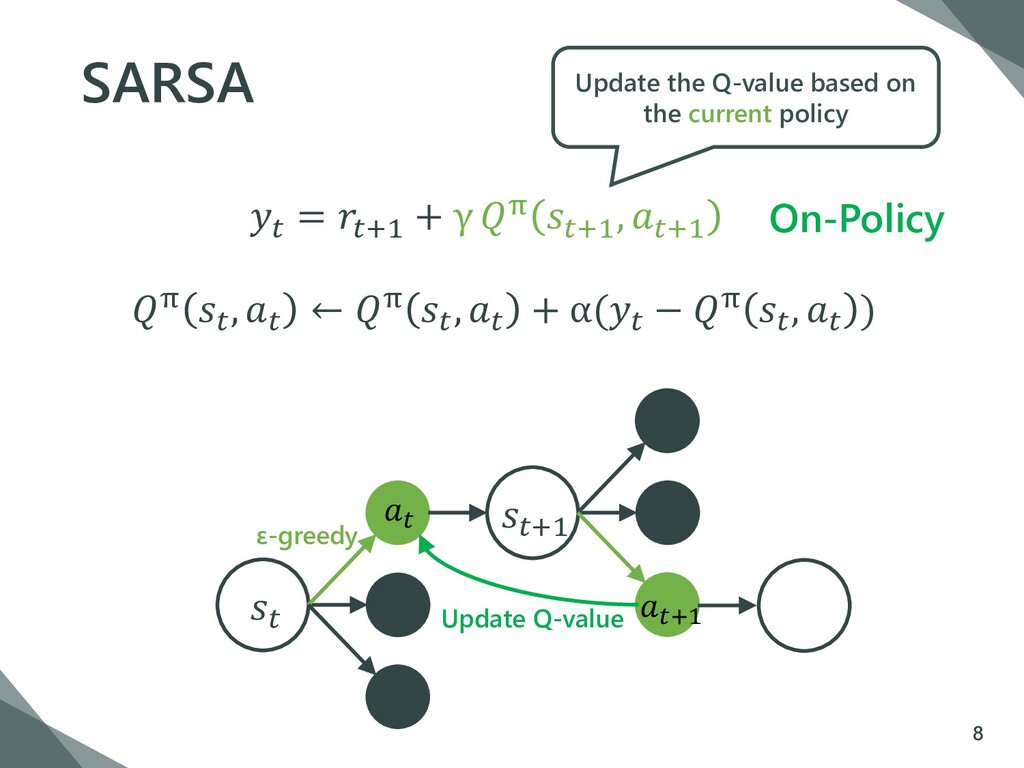
, ← π , + α( − π , ) approximate the Q-function by CNN −target network −experience replay −reward clipping 11 ′ fix the parameters of the Q-function max π +1 , ′ for a certain period ′
, ← π , + α( − π , ) approximate the Q-function by CNN −target network −experience replay −reward clipping 12 ′ store past state transitions and their rewards in the replay buffer and apply mini-batch learning by sampling from replay buffer
= [∇θ logπθ ∗ πθ (∗)] for parameterized policy πθ There are some algorithms for different πθ (∗). −REINFORCE : −Actor-Critic : π = π − π 14 how good the policy is
Learning for Image Processing −[Cao+, CVPR17] −A2-RL [Li+, CVPR18] −PixelRL [Furuta+, AAAI19] −Adversarial RL [Ganin+, ICML18] 31 Very recently, deep RL has been used for image processing There are much more RL algorithms…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Cao+, CVPR17] Attention-Aware Face Hallucination 17](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_16.jpg){kind=link}
![[Cao+, CVPR17] Attention-Aware Face Hallucination algorithm : REINFORCE state :](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_17.jpg){kind=link}
![[Cao+, CVPR17] Qualitative Results 19](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_18.jpg){kind=link}
![A2-RL [Li+, CVPR18] Aesthetics Aware Image Cropping 20](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_19.jpg){kind=link}
![A2-RL [Li+, CVPR18] Aesthetics Aware Image Cropping algorithm : A3C](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_20.jpg){kind=link}
![A2-RL [Li+, CVPR18] Qualitative Results 22](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_21.jpg){kind=link}
![PixelRL [Furuta+, AAAI19] Pixel-wise multi-agent reinforcement learning - Employ fully](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_22.jpg){kind=link}
![PixelRL [Furuta+, AAAI19] Image Denoising 24](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_23.jpg){kind=link}
![PixelRL [Furuta+, AAAI19] Image Restoration 25](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_24.jpg){kind=link}
![PixelRL [Furuta+, AAAI19] Image Restoration 26](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_25.jpg){kind=link}
![Adversarial RL [Ganin+, ICML18] Synthesizing Programs 27 Renderer is non-differential](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_26.jpg){kind=link}
![Adversarial RL [Ganin+, ICML18] Generate vector images from raster images](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_27.jpg){kind=link}
![Adversarial RL [Ganin+, ICML18] Generate vector images from raster images](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_28.jpg){kind=link}
![Adversarial RL [Ganin+, ICML18] MNIST Reconstraction 30](https://files.speakerdeck.com/presentations/23ad3a3bbb0b4aa2a371af59d6a2e1d4/slide_29.jpg){kind=link}
{kind=link}