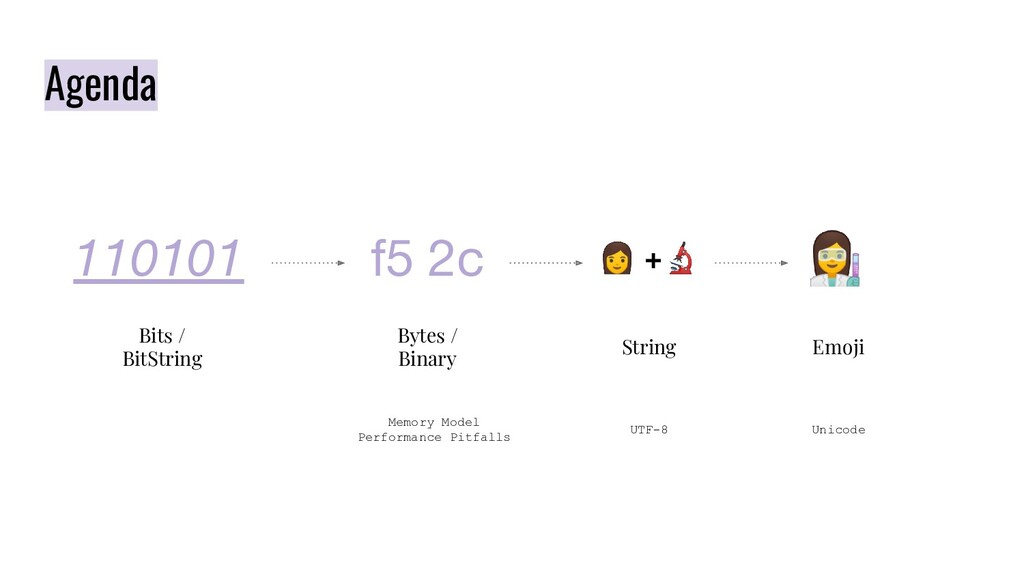
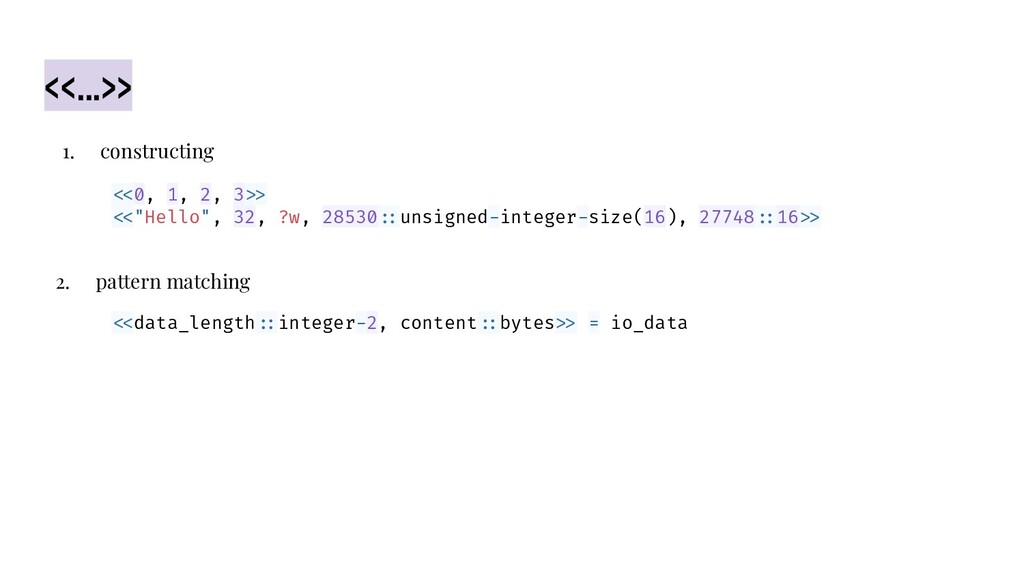
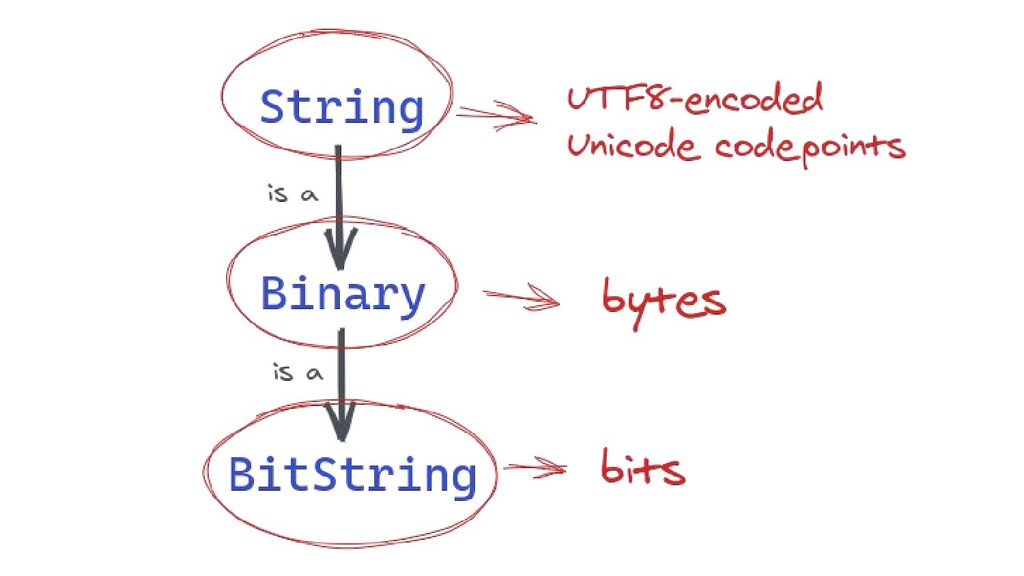
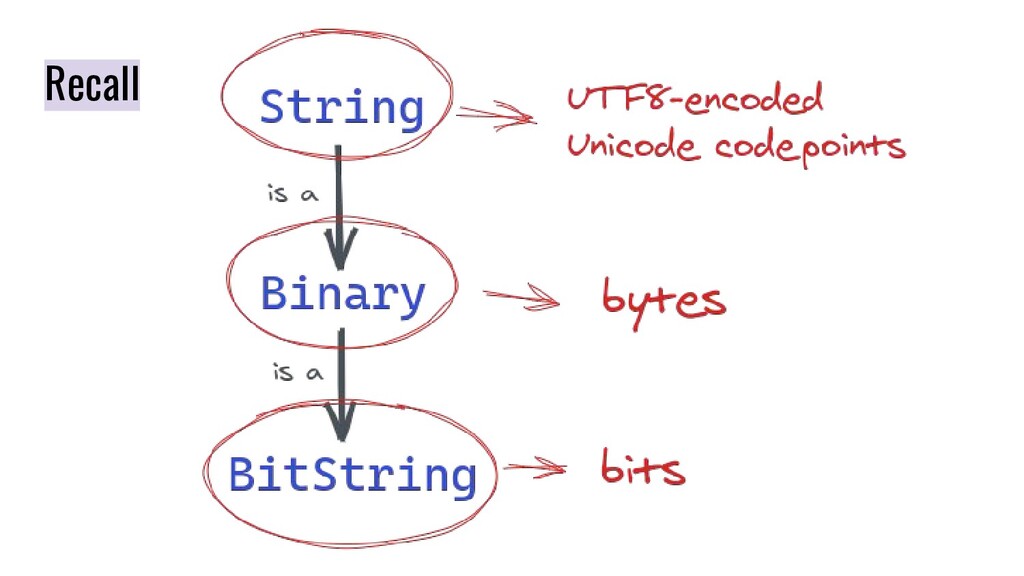
This was the slide for the topic I shared on Beijing Elixir Meetup in May 2020. In this speech, I shared some interesting experiences I have gained when studying binaries in Elixir / Erlang. It involves BitString, Binary, String, Charlist, Unicode, and UTF-8.
Also, there is a serial of blog posts related to it, covering more details.
https://medium.com/@qhwa_85848/questions-for-bitstring-binary-charlist-and-string-in-elixir-5b7e0c1e41a0
Thanks for watching and please share your thoughts.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}