Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
オブザーバビリティで理解するコンピュータサイエンス
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Qryuu
July 18, 2021
Science
1.7k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
オブザーバビリティで理解するコンピュータサイエンス
JTF2021 D2 登壇資料
- CPU使用率の読み方 コアごと使用率の意味と計算機概論
- N+1問題 見つけ方とその発生原因
Qryuu
July 18, 2021
More Decks by Qryuu
See All by Qryuu
監視論Ⅳ ~監視からオブザーバビリティーへの招待~
qryuu
0
530
人体モニタリングによる運動療法継続
qryuu
0
200
監視とは何か ~監視エンジニアのスキルと成長~
qryuu
8
8.9k
監視論 ~SREと次世代MSP~
qryuu
10
5.1k
Other Decks in Science
See All in Science
AkarengaLT vol.41
hashimoto_kei
1
150
データベース12: 正規化(2/2) - データ従属性に基づく正規化
trycycle
PRO
0
1.3k
不動産業界における業界特化のデータ整備とAI活用 ─Vertical DataとVertical AI─
estie
1
800
Build your own LLM, Live, with MicroGPT
ianozsvald
0
110
[NLP2026 参加報告会] AI for Science まとめ / NLP2026
lychee1223
0
1.9k
Testing the Longevity Bottleneck Hypothesis
chinson03
0
370
Amusing Abliteration
ianozsvald
1
230
ITTF卓球世界ランキングのポイント比を用いた試合結果予測モデルの性能評価 / Performance evaluation of match result prediction models using the point ratio of the ITTF Table Tennis World Ranking
konakalab
0
140
見上公一.pdf
genomethica
0
170
Cross-Media Technologies, Information Science and Human-Information Interaction
signer
PRO
3
32k
20260410_SystemsThinking
takusamar
1
120
Tensor Factorization Meets Deformed Information Geometry: Convex Relaxation under Deformed Algebra
gkazunii
0
110
Featured
See All Featured
Paper Plane
katiecoart
PRO
2
52k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Docker and Python
trallard
47
4k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
330
The SEO Collaboration Effect
kristinabergwall1
1
500
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
We Have a Design System, Now What?
morganepeng
55
8.2k
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.5k
Transcript
オブザーバビリティから理解する コンピュータサイエンス ~コンピュータサイエンスが職務境界の問題を見つける~ JTF2021
自己紹介 ▪ PN:九龍真乙 ▪ Twitter: @qryuu ▪ SlideShre: https://www.slideshare.net/qryuu ▪
GitHub: https://github.com/qryuu ▪ クックパッド: https://cookpad.com/kitchen/4142562 ▪ Youtube: https://www.youtube.com/channel/UCcPidyLCfGp49pmF4Zb761Q ▪ 専門:Zabbix, New Relic,テクニカルサポート, テクニカルトレーナー 2
セッションの目的 ▪ パフォーマンスDataをどのように読み解くのか ▪ その問題は何故発生するのか ▪ 問題は職務境界に存在する事が多いです、その問題を運用の視 点で見つけて見ましょう 3
セッションの目的 ▪ オブザーバビリティプラットフォームや監視ツールを使ってい ても、実際にその意味を読み解くにはコンピュータサイエンス の理解が必要です。 ▪ モニタリングツールで何を見てそれをどのように解釈するのか、 なぜそのようなことが起こるのか ▪ 実際の問題を2つ取り上げて解説します。
4
今日の課題 ▪ CPU使用率の読み方 – コア毎使用率の意味と計算機概論 ▪ N+1(または1+N)問題 – 見つけ方とその発生原因 5
CPU使用率 コア偏り問題は何故発生するのか 6
コア毎のCPU使用率 ▪ Zabbixでは ▪ system.cpu.util[0,idle, avg1] ▪ system.cpu.util[1,idle, avg1] ▪
CPUコア毎の使用率を取得 できます。 7
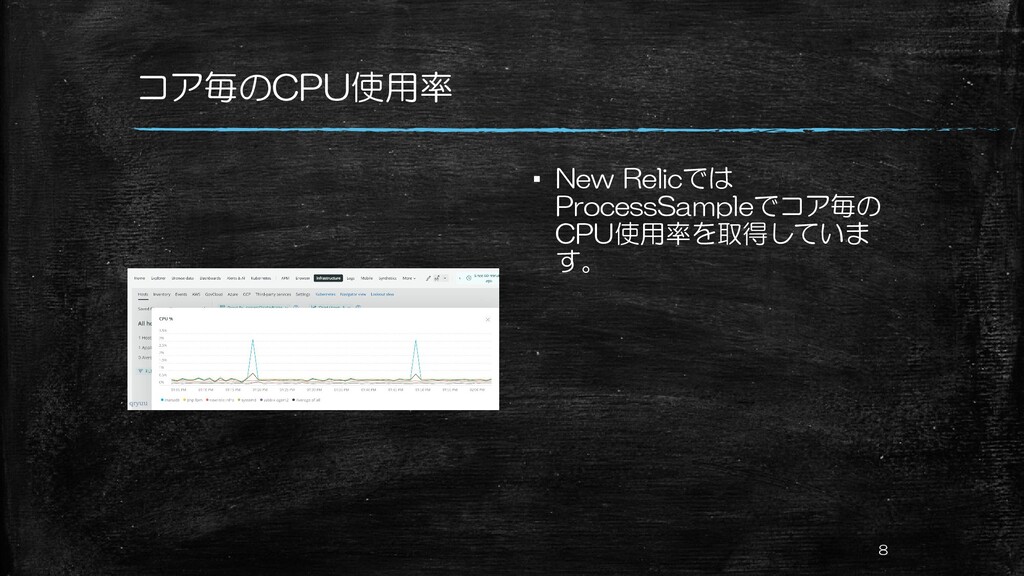
コア毎のCPU使用率 ▪ New Relicでは ProcessSampleでコア毎の CPU使用率を取得していま す。 8
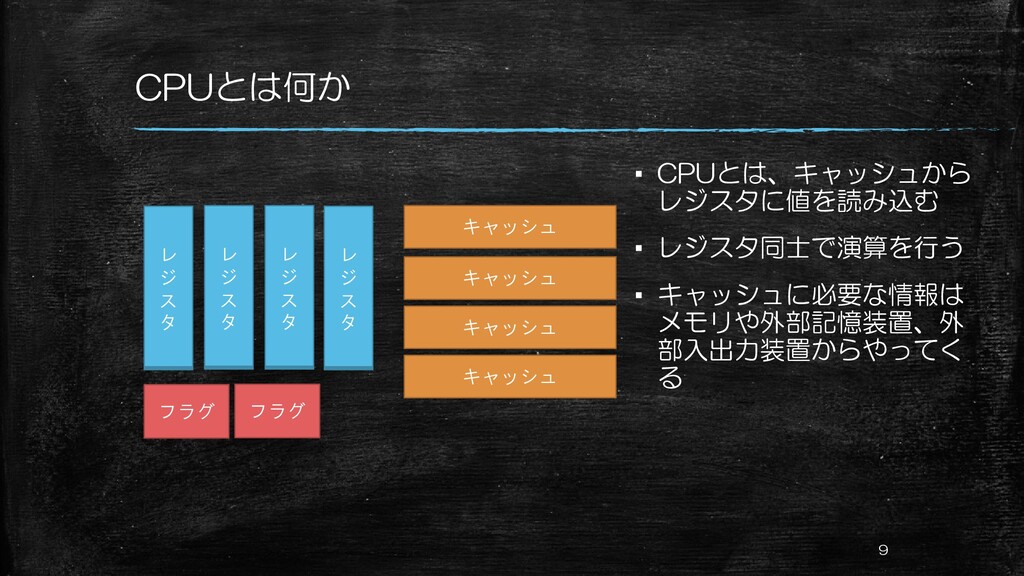
CPUとは何か ▪ CPUとは、キャッシュから レジスタに値を読み込む ▪ レジスタ同士で演算を行う ▪ キャッシュに必要な情報は メモリや外部記憶装置、外 部入出力装置からやってく
る 9 レ ジ ス タ レ ジ ス タ レ ジ ス タ レ ジ ス タ キャッシュ キャッシュ キャッシュ キャッシュ フラグ フラグ
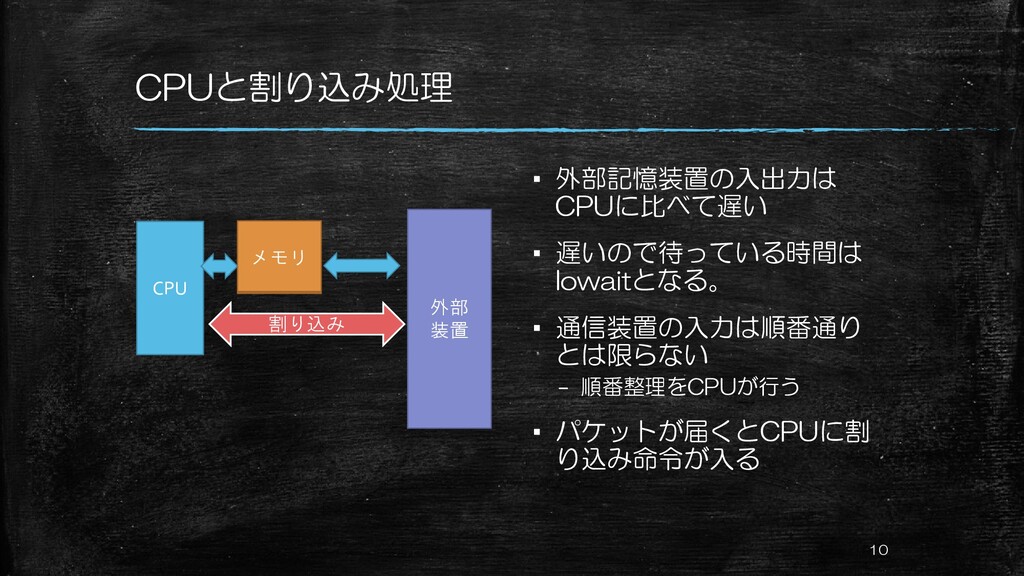
CPUと割り込み処理 ▪ 外部記憶装置の入出力は CPUに比べて遅い ▪ 遅いので待っている時間は Iowaitとなる。 ▪ 通信装置の入力は順番通り とは限らない
– 順番整理をCPUが行う ▪ パケットが届くとCPUに割 り込み命令が入る 10 CPU メモリ 外部 装置 割り込み
通信負荷とコア専有 ▪ 受信パケットは順番通り届かない – 経路毎に先着後着があるので、並べ替えないとデータにならない – 割り込み処理は通常特定のコアに偏る – 現代の処理は通信処理が大きい –
パケット処理に1コアが専有され、他のコアは処理したくても処理する データが無い ▪ CPUではなくてNICに処理させるのがハードウェアオフロード 11
解決策 ▪ DPDK(Data Plane Development Kit) – CPUを通信専用にして全コアで処理する(ソフトウェアルータ向け) ▪ https://ascii.jp/elem/000/001/691/1691592/
▪ RSS(Receive-Side Scaling) – NICからの割り込みを複数コアに分散させる ▪ https://qiita.com/nyamage/items/04f348a868475cef 0c77 ▪ https://speakerdeck.com/yuukit/linux-network- performance-improvement-at-hatena 12
解決策 ▪ シングルスレッド性能を上げる ▪ 小数コアマルチサーバー構成への変更 13
監視運用の視点から ▪ 高トラフィック環境では、データ処理では無くパケット処理の ためにCPUの1コアが専有される – 割り込み処理の特性 – 処理するデータが無いので他のコアは暇 ▪ 問題解決には対応したNICやOSカーネルのチューニングが必要
– バニラな環境だと発生しやすい ▪ ただのCPU使用率だと見落とす(コア毎の値が必要) – 1コアのみ専有は総CPU使用率としては低く出る – シングルコア限界を見つける必要がある 14
N+1問題 発生原因と気付きづらさ 15
N+1問題 ▪ フレームワークがSQLを組み立ててくれる(プログラマがSQL を意識しない)言語で発生しやすい ▪ 同じSQL問合せを処理をデータ件数分実行してしまう。 ▪ アプリケーションパフォーマンス劣化のよくある原因 ▪ https://qiita.com/massaaaaan/items/4eb770f20e636f
7a1361 16
N+1問題 ▪ インフラエンジニアやDBAは気付きにくい – SQLを意識して書く、自分でJOINする ▪ プログラマも気付きにくい – コードにエラーも無く、処理結果も合っている –
フレームワークの出力するSQLが非効率 – DB応答が遅いのでインフラ(DB)の問題だと思い込む 17
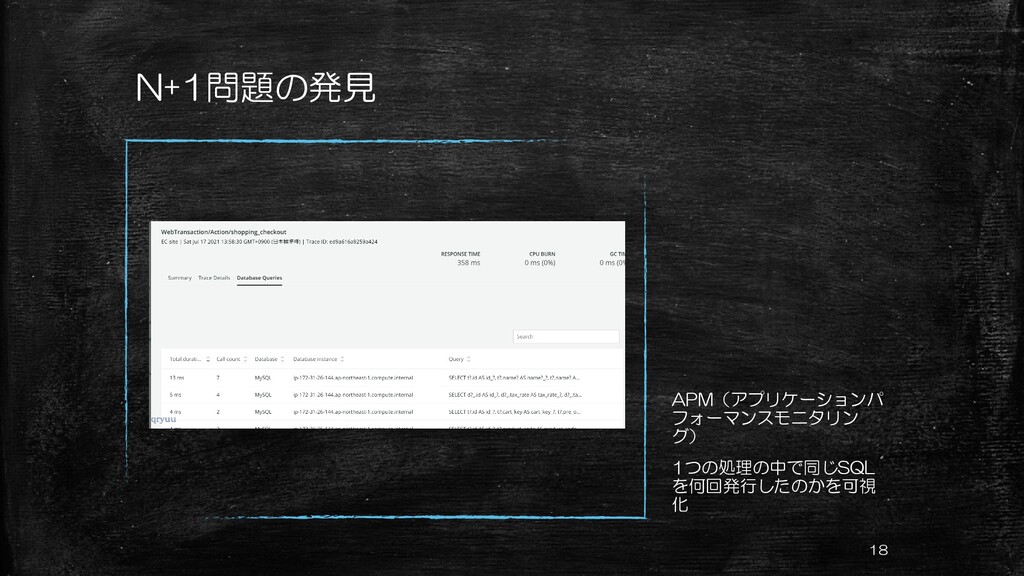
N+1問題の発見 APM(アプリケーションパ フォーマンスモニタリン グ) 1つの処理の中で同じSQL を何回発行したのかを可視 化 18
解決策 ▪ APMによってN+1問題が発生していることを確認 ▪ preload やeager_loadなどSQLの結果をキャッシュしておく フレームワーク処理を利用する。 19
監視運用の視点から ▪ 原因はアプリケーションコード ▪ 事象としてはDBが遅いのでインフラ起因のように見える ▪ インフラ監視だけだと気づけない ▪ APMで実際の処理を可視化して原因コードを特定 ▪
アプリケーションに改善を依頼 20
コンピュータサイエンス ▪ ほとんどの事象には原因がある。 – おまじない、オカルトではない ▪ レジスタ、キャッシュ、割り込み処理 ▪ 計算量概念、計算コスト概念(DeleteとDrop) ▪
コンピュータサイエンスを理解する事で監視ツールの値が読め るようになる ▪ 監視ツールの値を読むことで概念ではなくコンピュータサイエ ンスの実験として実際に観測できる 21
参考文献 ▪ 入門 計算機概論 – https://www.amazon.co.jp/dp/427412956X ▪ https://ascii.jp/elem/000/001/691/1691592/ ▪ https://qiita.com/nyamage/items/04f348a868475cef
0c77 ▪ https://speakerdeck.com/yuukit/linux-network- performance-improvement-at-hatena ▪ https://qiita.com/massaaaaan/items/4eb770f20e636f 7a1361 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![コア毎のCPU使用率 ▪ Zabbixでは ▪ system.cpu.util[0,idle, avg1] ▪ system.cpu.util[1,idle, avg1] ▪](https://files.speakerdeck.com/presentations/e0d39f1c965a41a09a80976a91acf4f5/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}