un listado con 891 registros de pasajeros • test.csv → contiene 418 registros de pasajeros El conjunto train debe ser usado para construir el modelo mediante el algoritmo de minería de datos que se seleccione. 2. 1. Datos - Kaggle
• survived: Indica si el pasajero sobrevive (0=No, 1=Sí) • pclass: Indica la clase del tiquete ( 1-primera clase, 2=segunda clase, 3-tercera clase) • name: Nombre del pasajero • sex: Sexo del pasajero (male, female) • age: Edad del pasajero • sibsp: Número de familiares a bordo • parch: Número de padres e hijos a bordo • ticket: Número del ticket • cabin: Número de la cabina • embarked: Puerta de embarque (C-Cherburgo, Q-Queenston, S-Southampton)
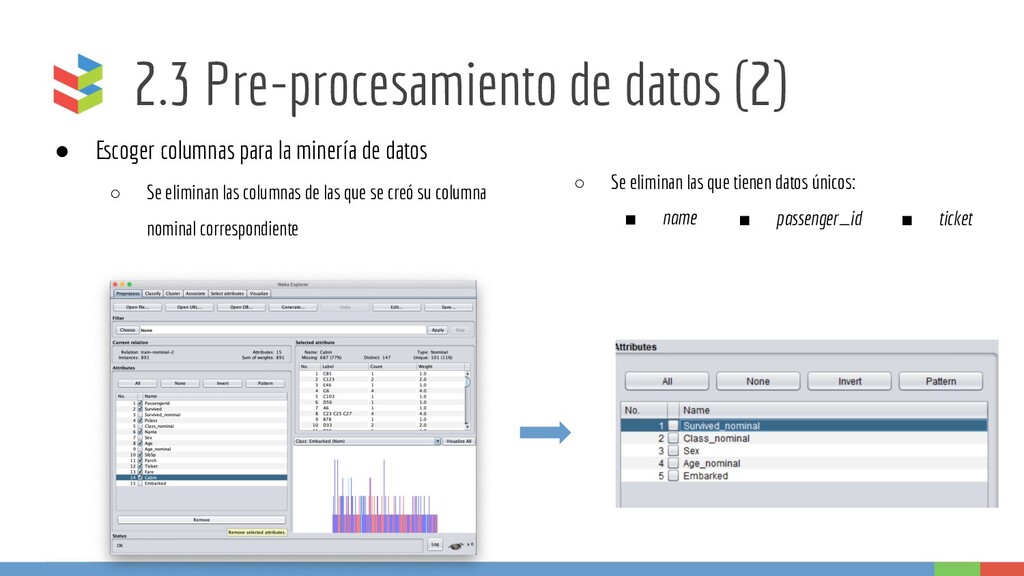
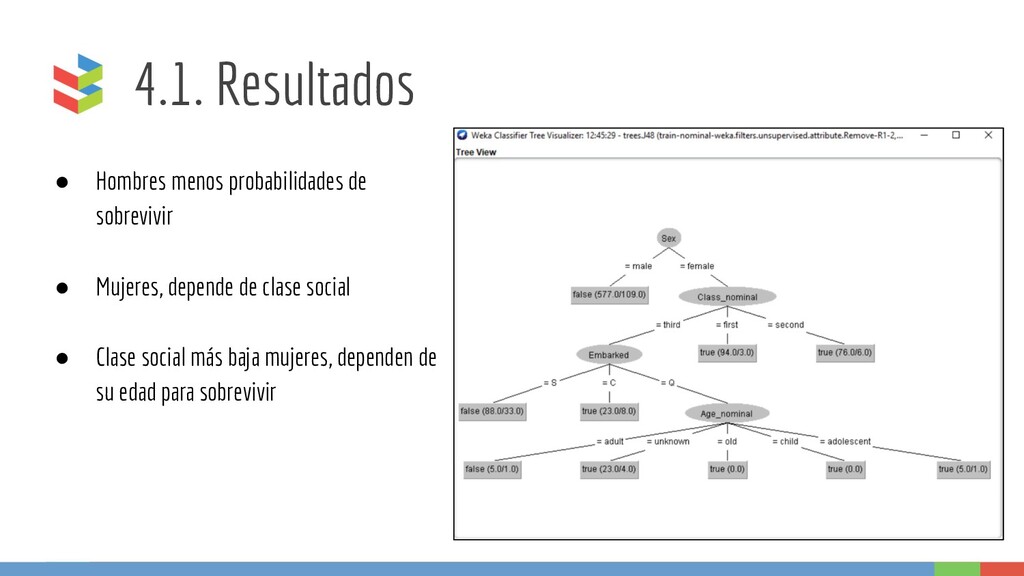
minería de datos ◦ Se eliminan las columnas de las que se creó su columna nominal correspondiente ◦ Se eliminan las que tienen datos únicos: ▪ name ▪ passenger_id ▪ ticket
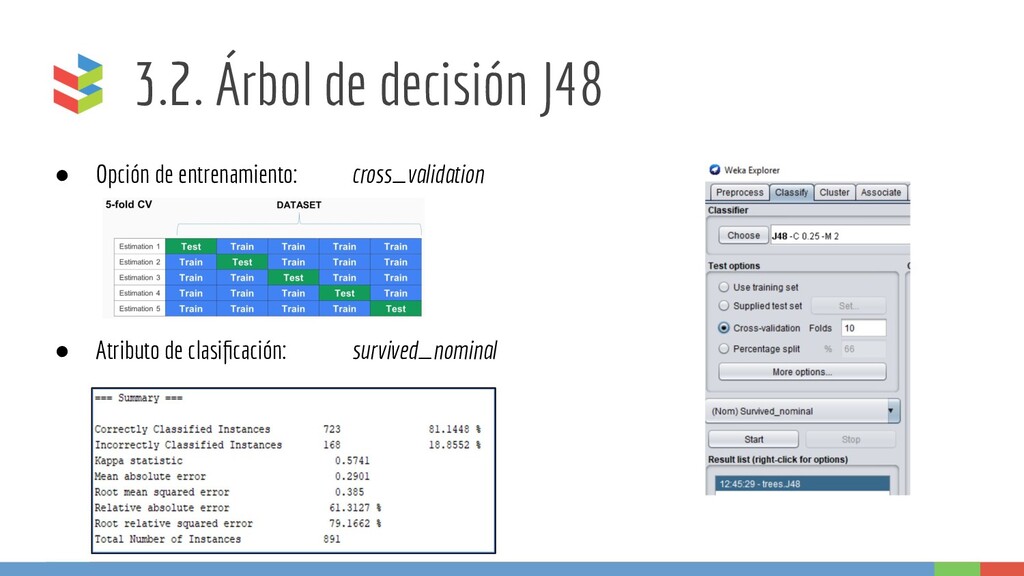
conjunto de datos • En cada nodo del árbol, se elige un atributo de los datos que más eficazmente divide el conjunto de muestras en subconjuntos enriquecidos en una clase u otra. • Implementación: J48 en WEKA
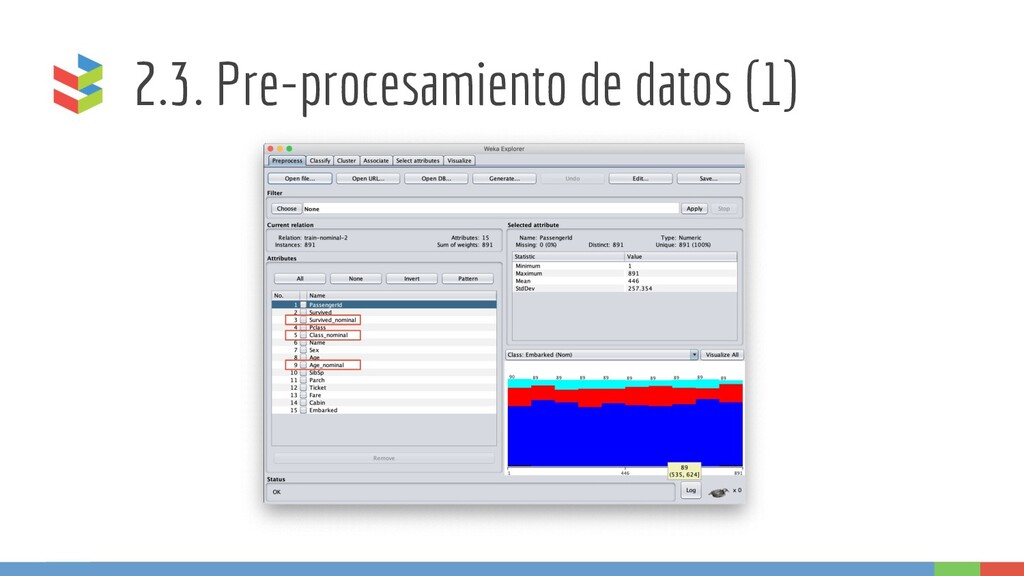
datos, en este proyecto se utilizaron Weka y Scikit-Learn de Python • El preprocesamiento es el paso que más tiempo ha tomado, pues es necesario encontrar que información es útil para el objetivo, y como transformar datos no relevantes en datos útiles.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![17 ¡Gracias! [email protected] ¡Cuéntanos tus ideas! @quitolambda @stackbuilders stackbuilders.com/join Trabaja](https://files.speakerdeck.com/presentations/5279f165b1294e26b649b2a7f77fe499/slide_16.jpg){kind=link}