Practical introduction to machine learning (classification, dimensionality reduction and cross validation), with a focus on insight, accessibility and strategy.
Pradeep Reddy Raamana
Baycrest Health Sciences, Toronto, ON, Canada
Title: Practical Introduction to machine learning for neuroimaging:
classifiers, dimensionality reduction, cross-validation and neuropredict
Alternative title: How to apply machine learning to your data, even if you do not know how to program
Objectives:
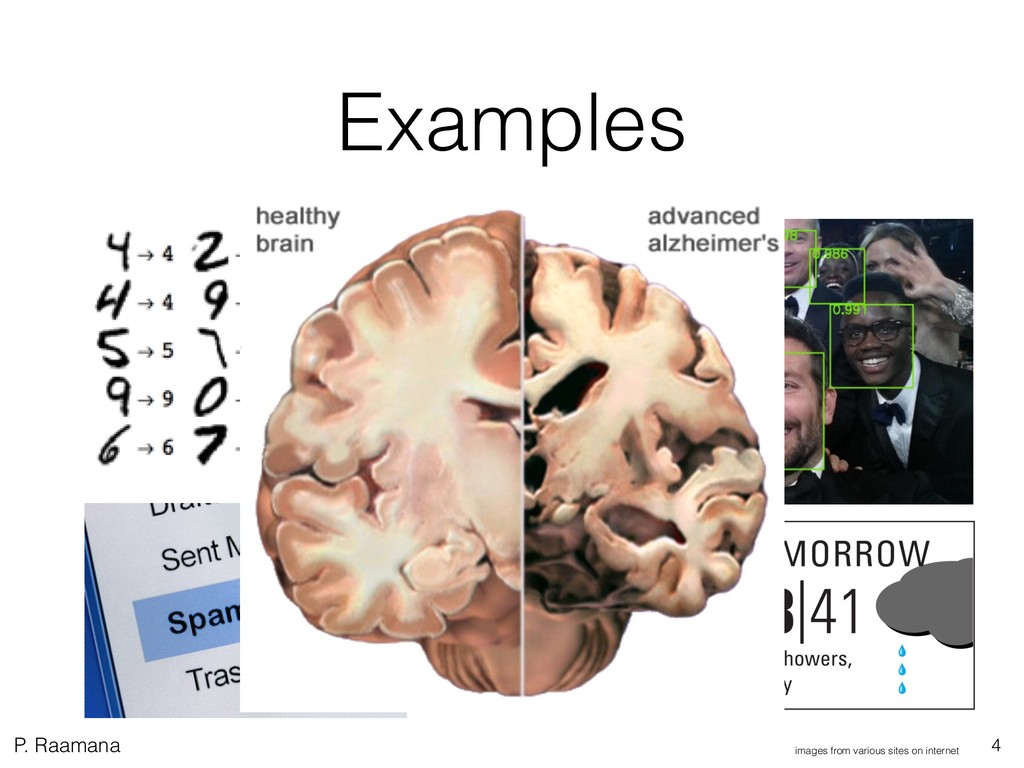
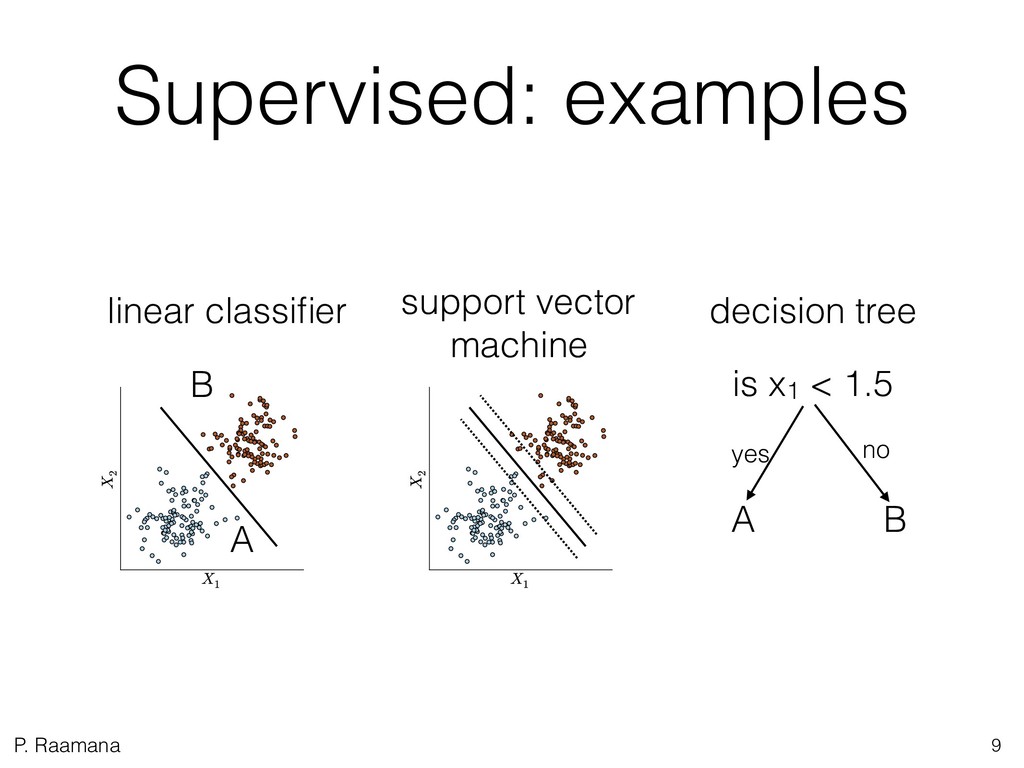
1. Learn what is machine learning and get a high-level overview of few popular types of classification and dimensionality reduction methods. Learn (without any math) how support vector machines work.
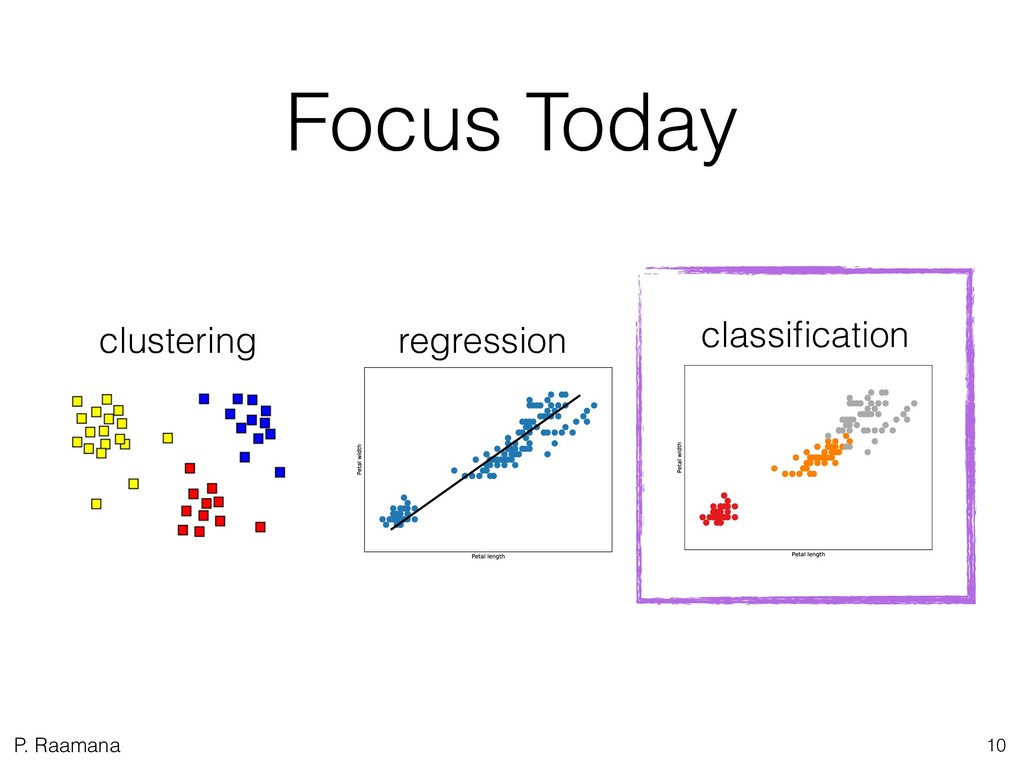
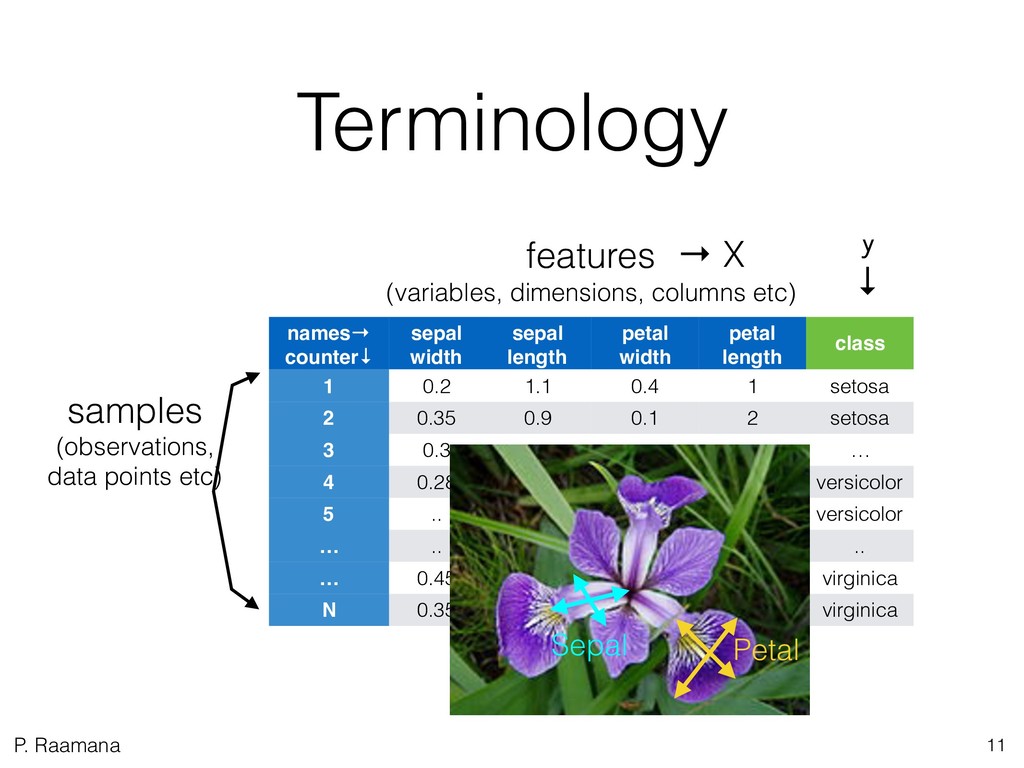
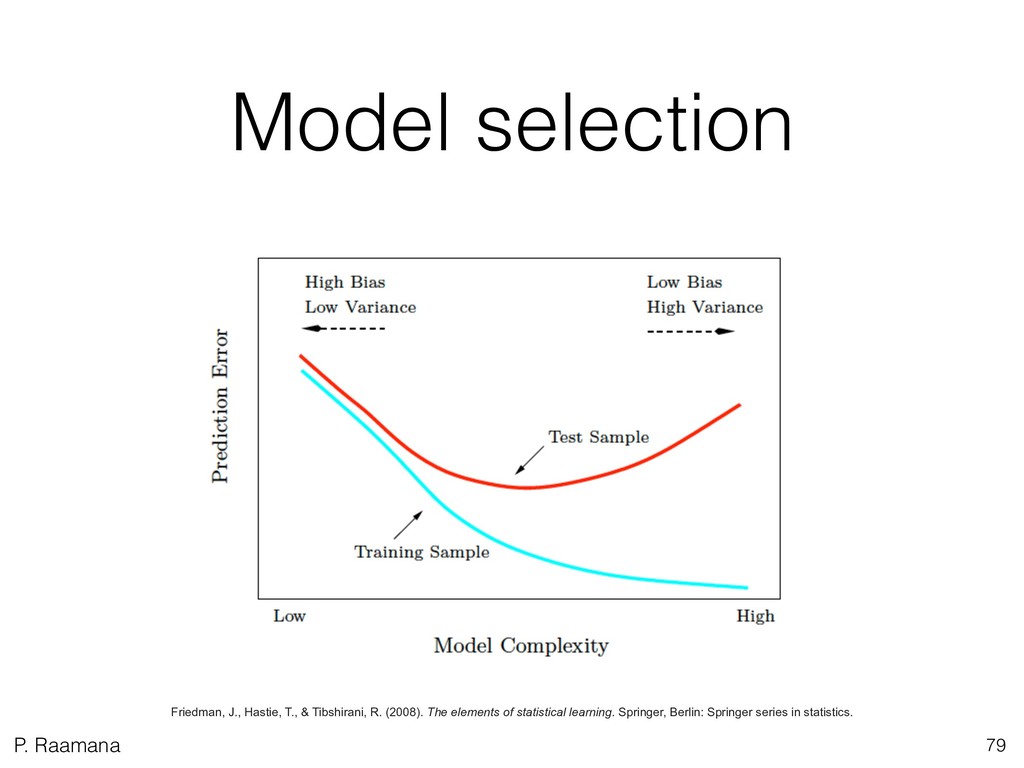
2. Learn how to plan a predictive analysis study on your own data? What are the key steps of the workflow? What are the best practices, and which cross-validation scheme to choose? How to evaluate and report classification accuracy?
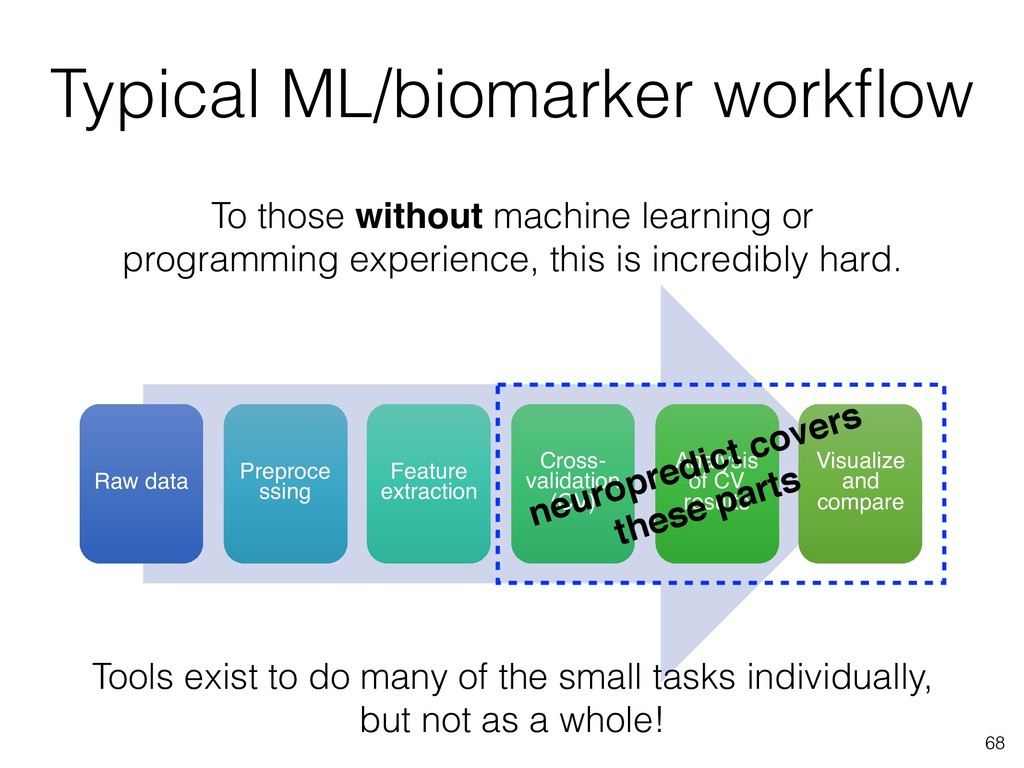
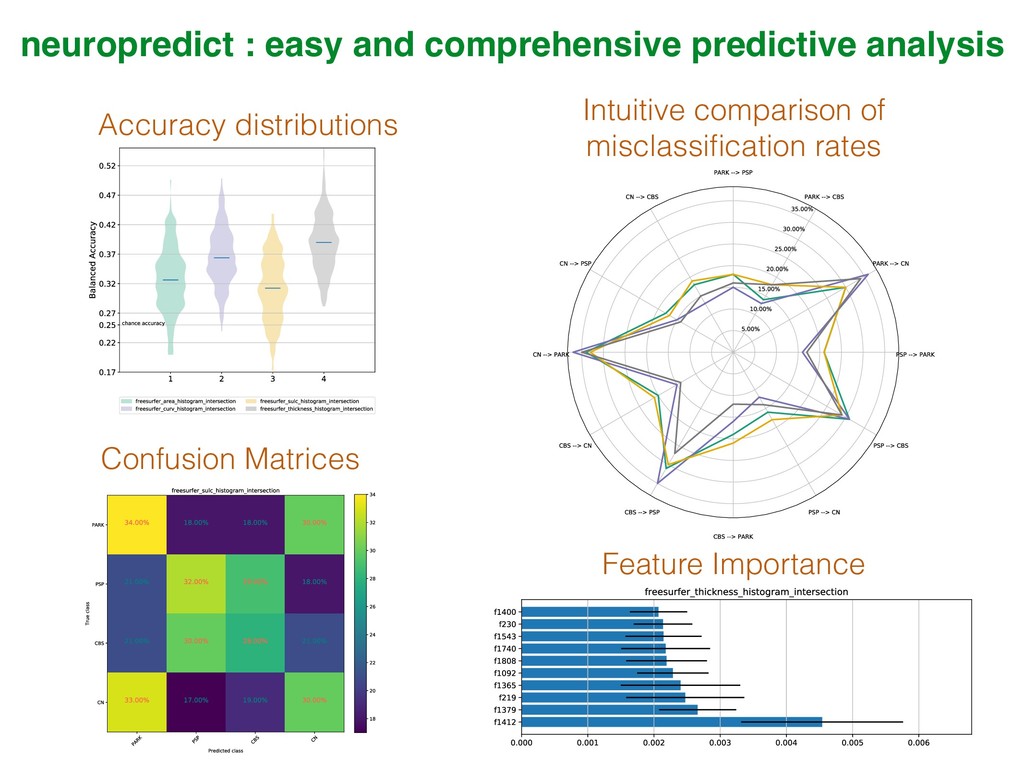
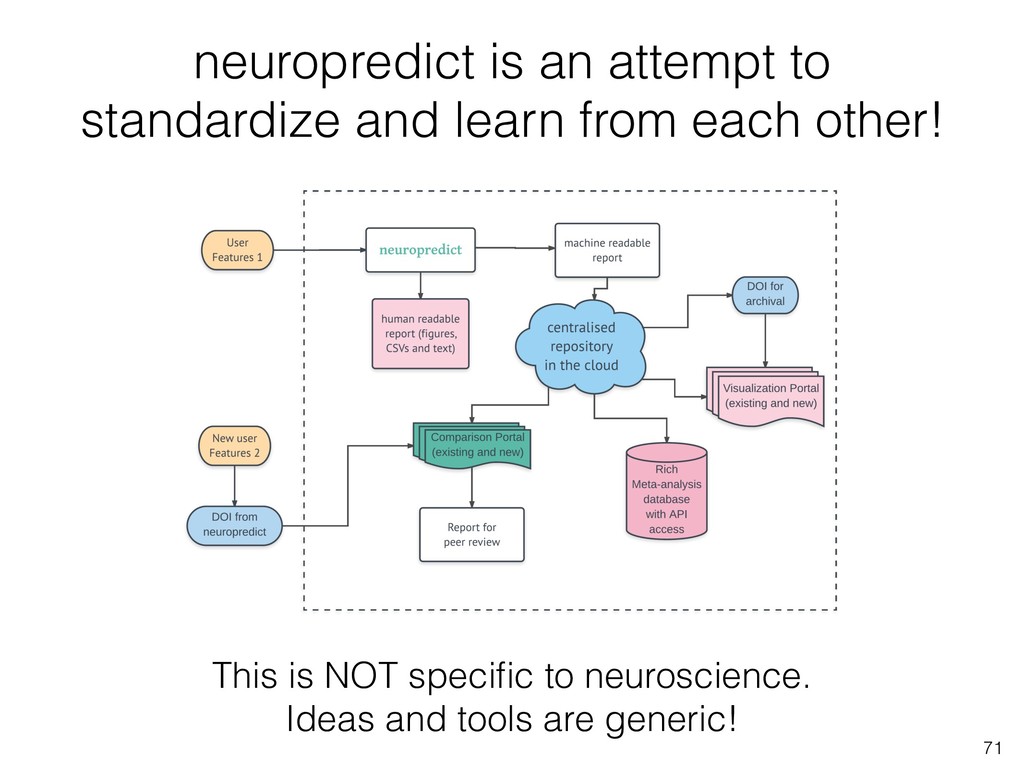
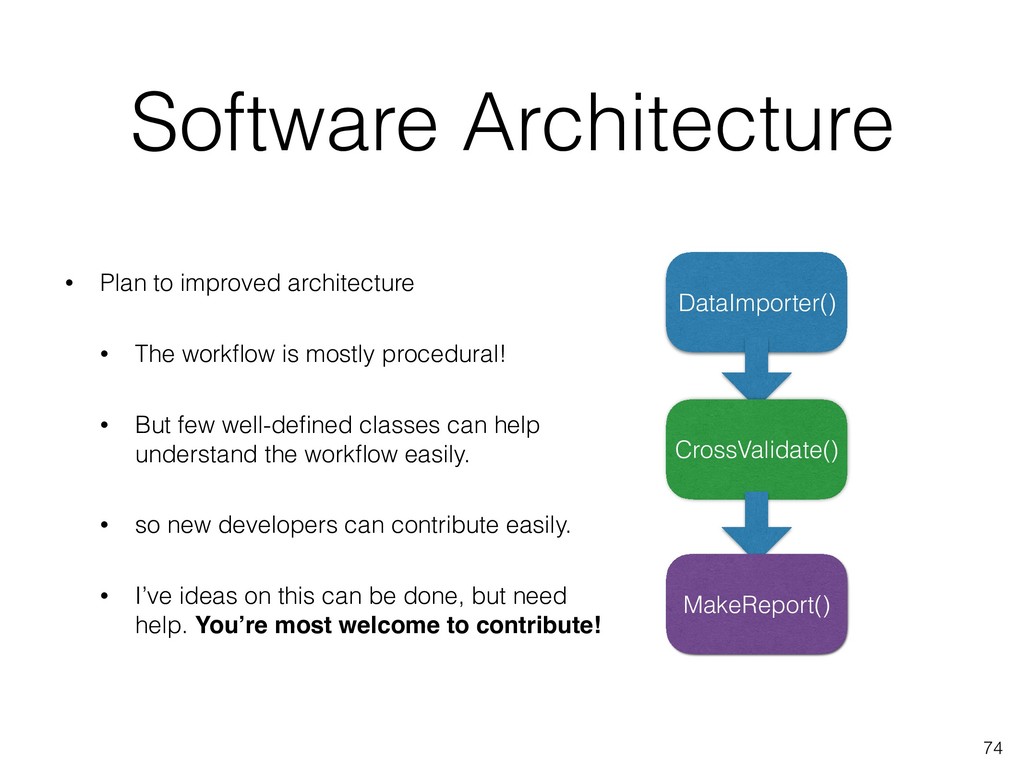
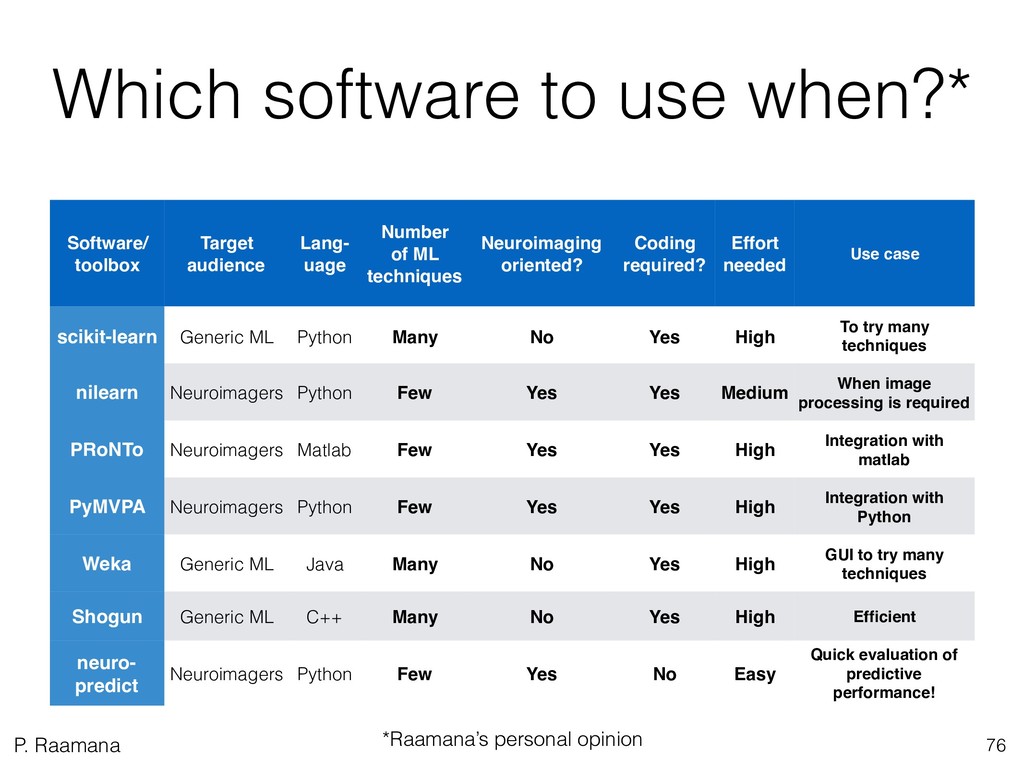
3. Learn which toolboxes to use when, with a practical categorization of few toolboxes. This is followed by detailed demo of neuropredict, for automatic estimation of predictive power of different features or classifiers without needing to code at all.
Recommended reading for the workshop:
• Pereira, F., Mitchell, T., & Botvinick, M. (2009). Machine learning classifiers and fMRI: a tutorial overview. Neuroimage, 45(1), S199-S209.
• Fernández-Delgado, M., Cernadas, E., Barro, S., & Amorim, D. (2014). Do we Need Hundreds of Classifiers to Solve Real World Classification Problems? Journal of Machine Learning Research, 15, 3133–3181.
• Varoquaux, G., Raamana, P. R., Engemann, D. A., Hoyos-Idrobo, A., Schwartz, Y., & Thirion, B. (2017). Assessing and tuning brain decoders: cross-validation, caveats, and guidelines. NeuroImage, 145, 166-179.
• Example study on comparison of multiple feature sets:
o Raamana, P. R., & Strother, S. C. (2017). Impact of spatial scale and edge weight on predictive power of cortical thickness networks. bioRxiv, 170381.
• Overview of the field
o W.r.t to biomarkers: Woo, C.-W., Chang, L. J., Lindquist, M. A., & Wager, T. D. (2017). Building better biomarkers: brain models in translational neuroimaging. Nature Neuroscience, 20(3), 365–377.
o W.r.t to a public dataset (ADNI): Weiner, M. W., Veitch, D. P., Aisen, P. S., Beckett, L. A., Cairns, N. J., Green, R. C., ... & Petersen, R. C. (2017). Recent publications from the Alzheimer's Disease Neuroimaging Initiative: Reviewing progress toward improved AD clinical trials. Alzheimer's & Dementia.
• Bigger recommended list available on crossinvalidation.com
Bio
Dr. Pradeep Reddy Raamana is a postdoctoral fellow at the Rotman Research Institute, Baycrest Health Sciences in Toronto, ON, Canada. His research interests include the development of 1) robust imaging biomarkers and algorithms for early detection and differential diagnosis of brain disorders, and 2) easy-to-use software to lower and remove the barriers for predictive-modelling and quality control for neuroimagers. He is also interested in characterizing the impact of different methodological choices at different stages of medical image processing (preprocessing and prediction). He blogs at crossinvalidation.com and tweets at @raamana_.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Feature [variable] selection • Ranking based • Variable selection •](https://files.speakerdeck.com/presentations/4216fff2924c4c7087f5ea060be7c788/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}