Presentation given by Ryan Abernathey at AGU 2018:
https://agu.confex.com/agu/fm18/meetingapp.cgi/Paper/390015
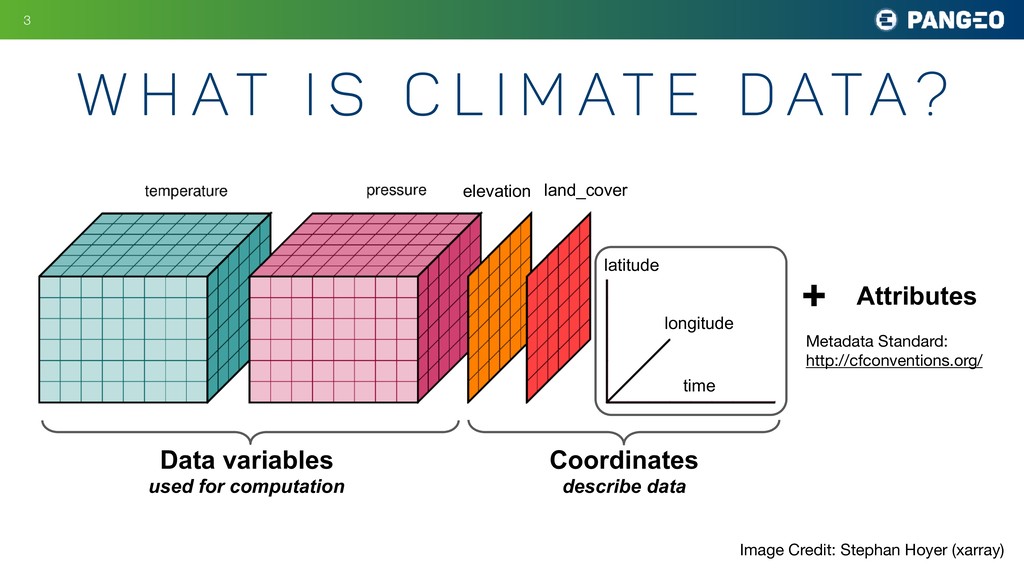
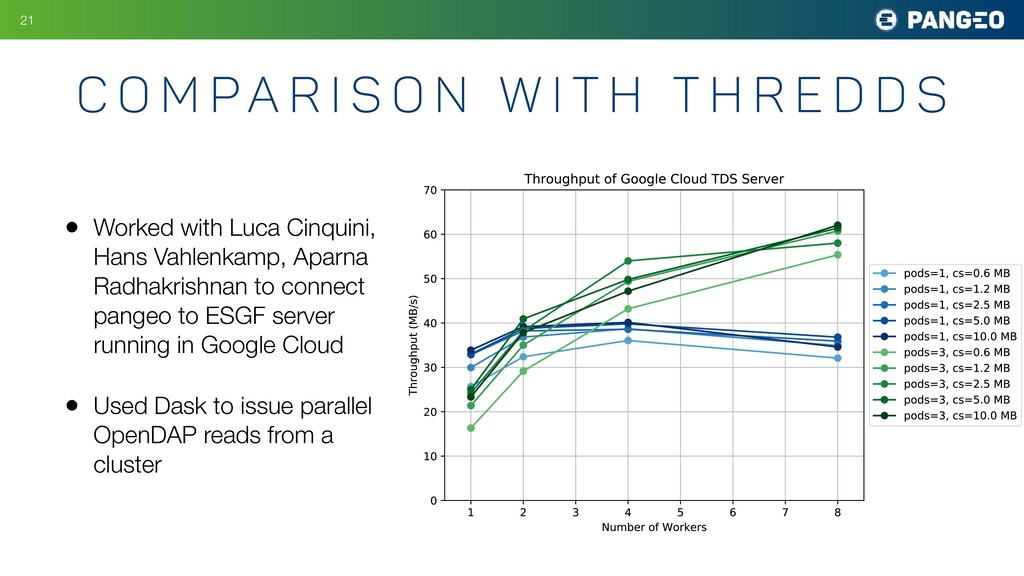
The Pangeo Project aims to empower scientists to work with very large datasets quickly and interactively. We do this by deploying open source technologies, such as
xarray, dask, jupyter, and kubernetes on conventional high-performance computers (HPC; like NCAR's Cheyenne and NASA's Pleiades) or on cloud platforms (like Google Cloud Platform or Amazon Web Services). Using the Pangeo software stack, users can distribute their computations over many compute nodes with minimal changes to their code, making it easy to scale analysis up to large datasets. Examples of datasets that Pangeo users want to analyze include remote sensing products (such as ocean infrared sea-surface temperature) as well as high resolution simulation outputs.
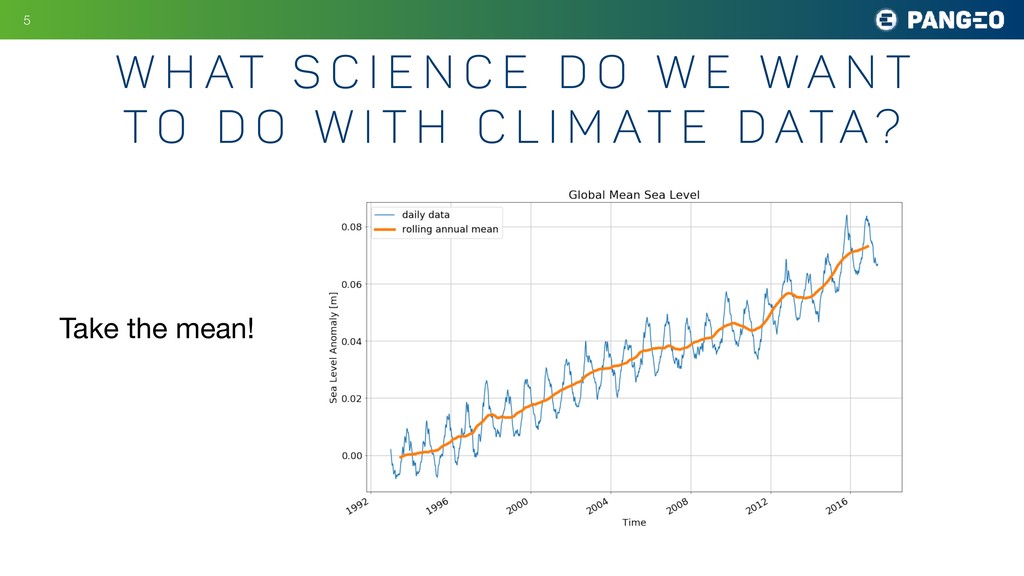
Using Pangeo, scientists are no longer limited by the rate the CPU can perform calculations, since many compute nodes can be used in parallel for analysis. Instead, the main bottleneck in most workflows is nearly always the rate at which data can be delivered to the compute nodes. Consequently, the access mechanism and file format of the underlying data becomes a crucial consideration for performance.
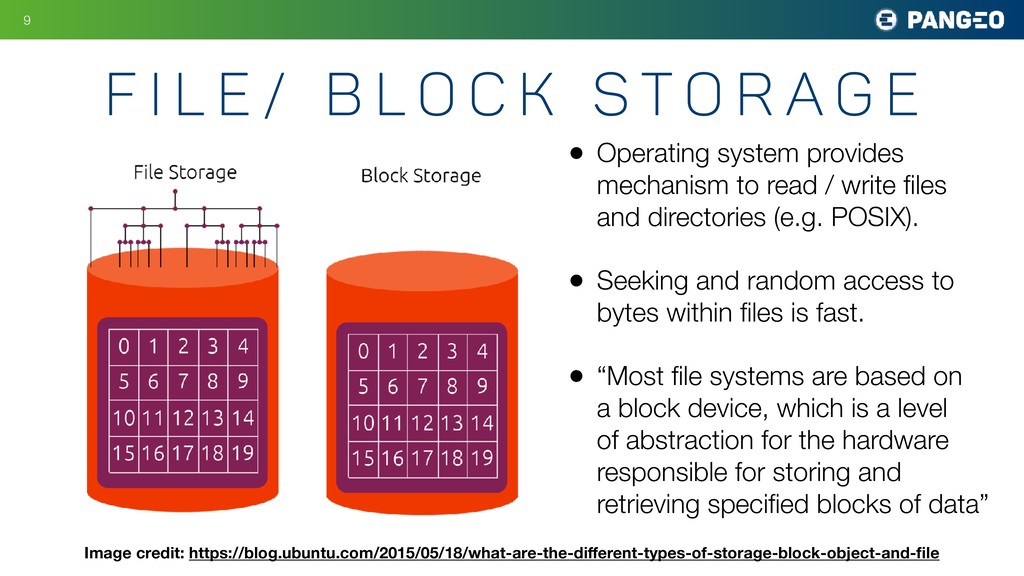
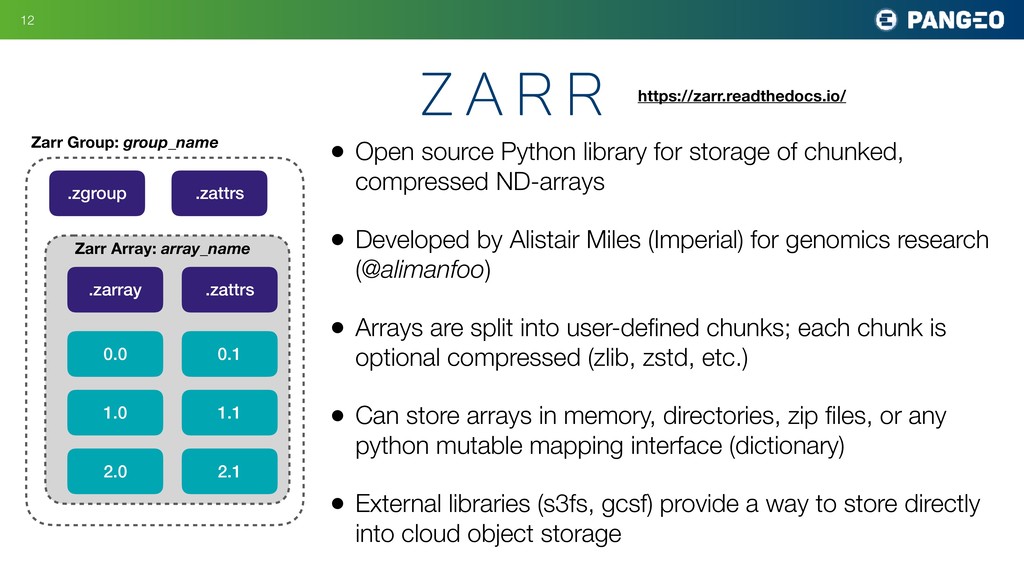
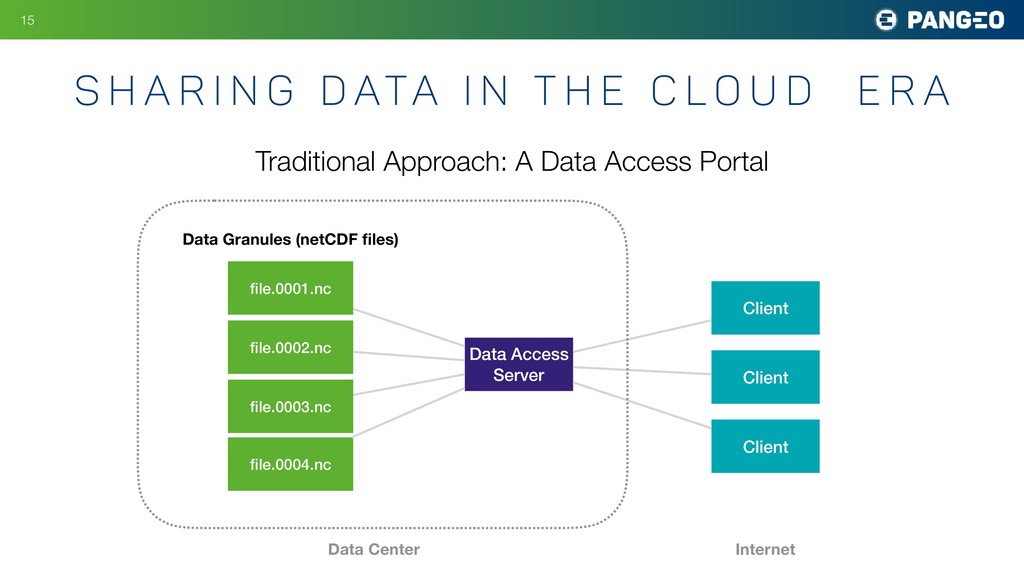
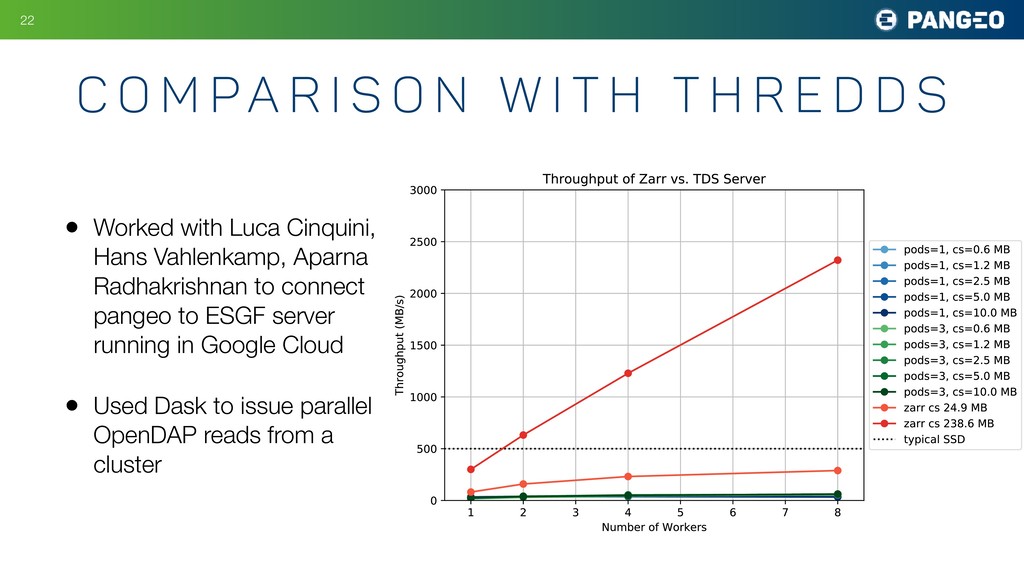
The most common format for relevant datasets is an archive of hundreds to thousands of individual netCDF / HDF files. This format does not work particularly well on cloud object storage; the opaque nature of the files makes it nearly impossible to extract a single variable or piece of data or metedata without reading the whole file. The Pangeo project has been experimenting instead with the zarr format. When used in conjunction with xarray, reading data from zarr looks and feels identical to reading traditional netCDF files. However, there are major advantage to the zarr format:
Metadata is kept separate from data in a lightweight .json format
Arrays are stored in a flexible chunked / compressed binary format
Individual chunks can be retrieved independently in a thread-safe manner
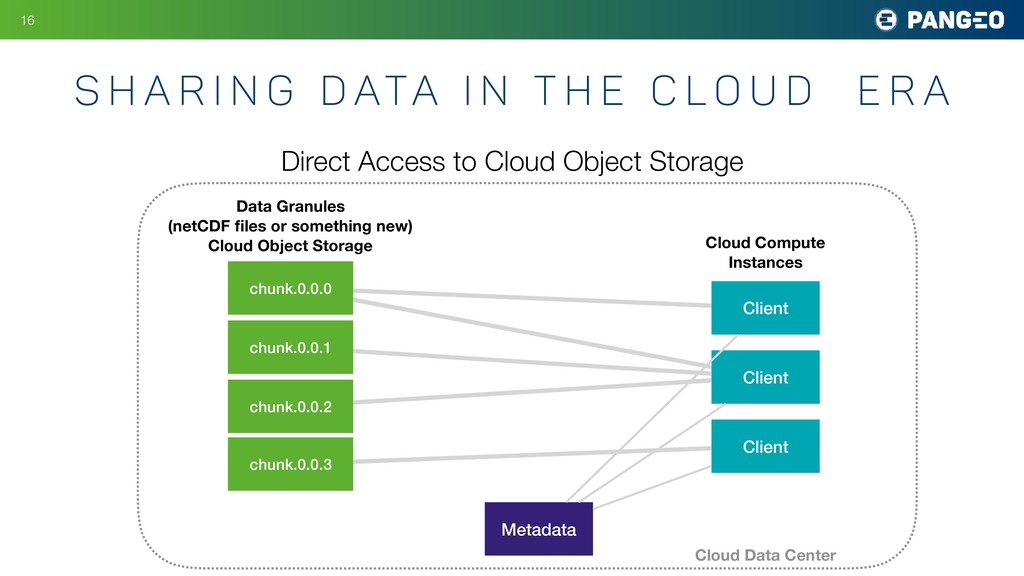
When zarr data is placed in cloud object storage, the result is a high-performance, "analysis ready" data archive. The rate at which data can be extracted from such an archive scales linearly with the number of compute nodes which are reading from it simultaneously.
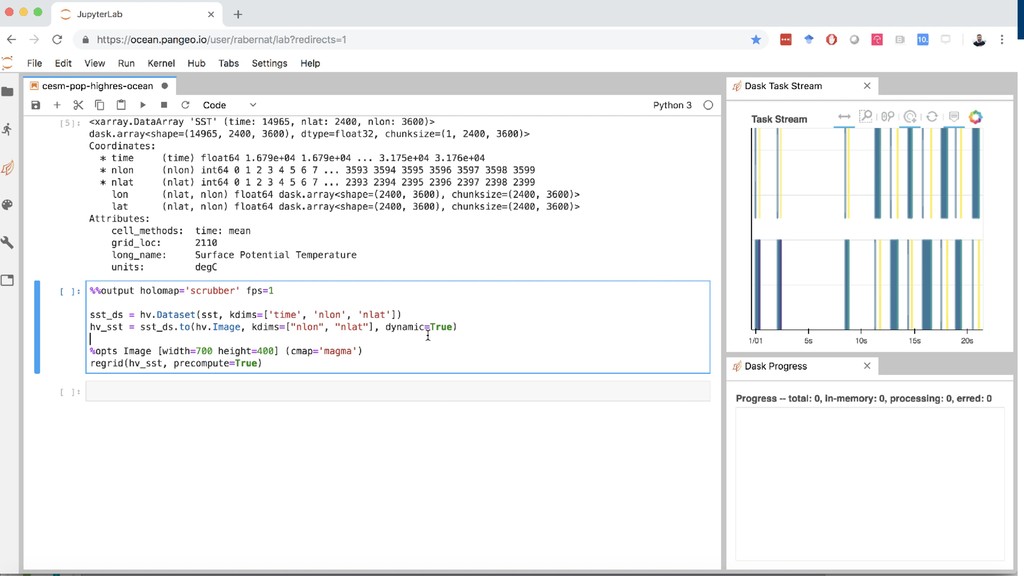
This talk will demonstrate the performance characteristics and scalability of zarr datasets in real-world workflows using a cloud-based Pangeo environment.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}