u n k s n o t A l i g n e d w i t h A n a ly s i s 4 Space Tim e ✅Calculate global statistics at each point in time ❌Calculate timeseries statistics as each point in space
will not exceed a user-specified memory threshold. • Minimize the number of required tasks. Specificallly, for N source chunks and M target chunks, the number of tasks is always less than N + M. • Be embarassingly parallel. The task graph should be as simple as possible, to make it easy to execute using different task scheduling frameworks. This also means avoiding write locks, which are complex to manage. D e s i g n P r i n c i p l e s 8
9 Source Target • Read each source chunk only once • Write source data to many target chunks • Problem: need to synchronize writes Source Target • Write each target only once • Read each source file many times • Problem: can blow out memor serial loop over source chunks may be very slow Push Pull
{kind=link}
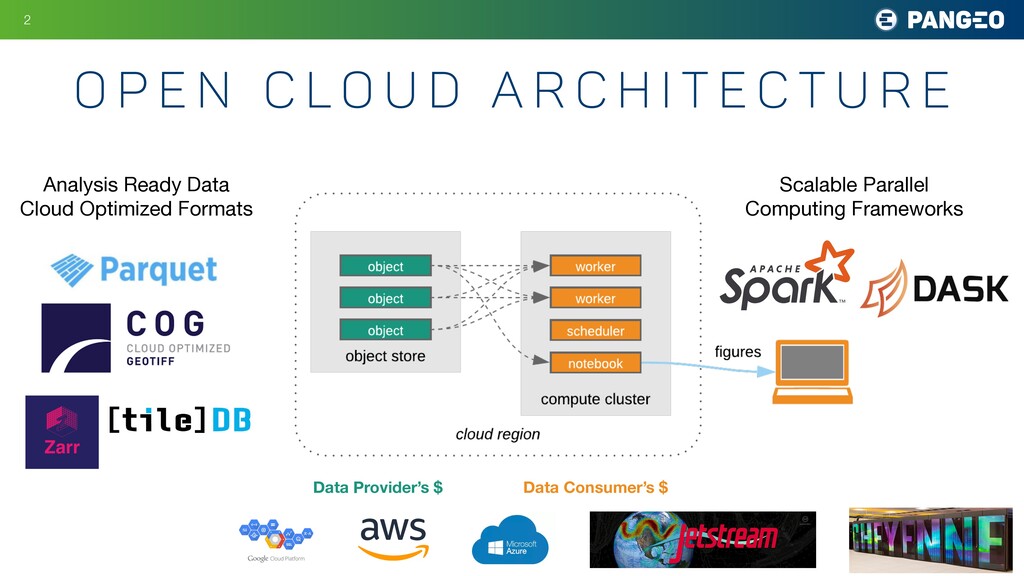{kind=link}
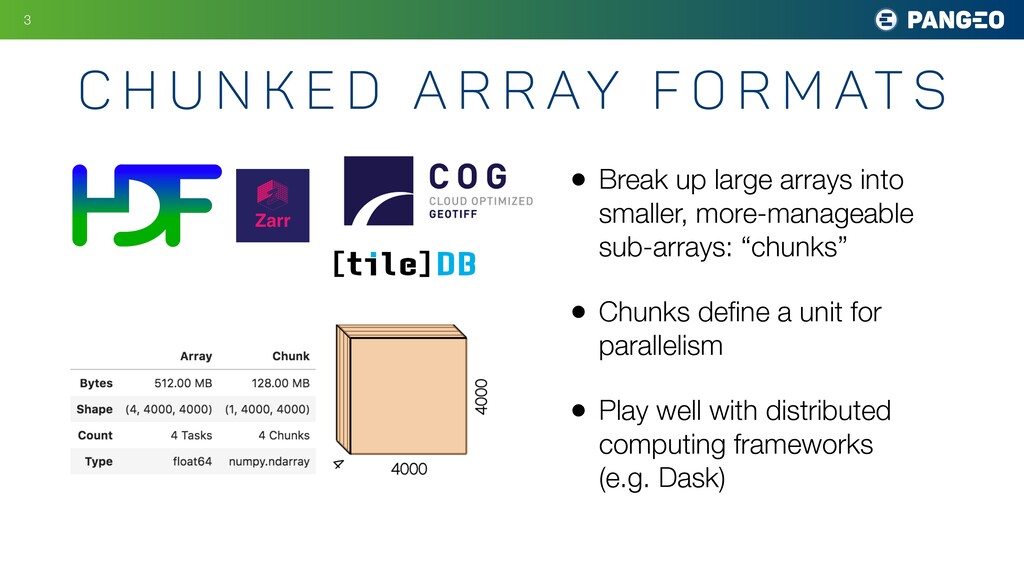{kind=link}
{kind=link}
{kind=link}
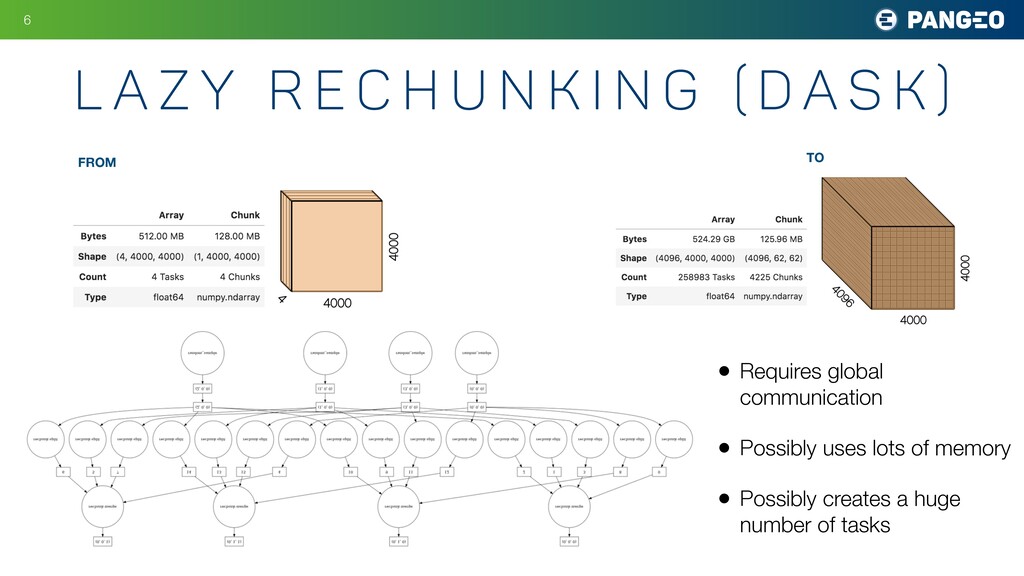{kind=link}
{kind=link}
{kind=link}
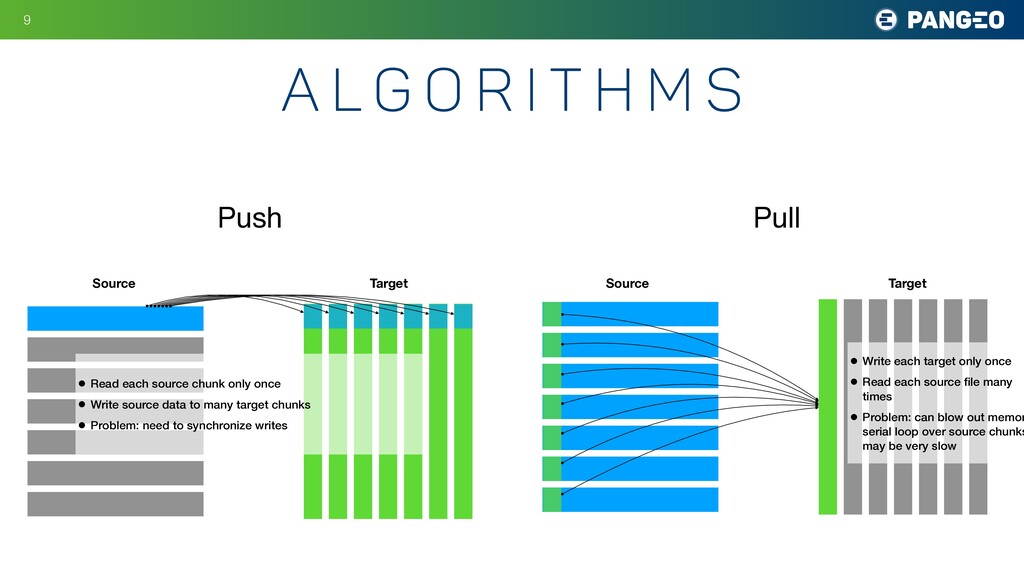{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}