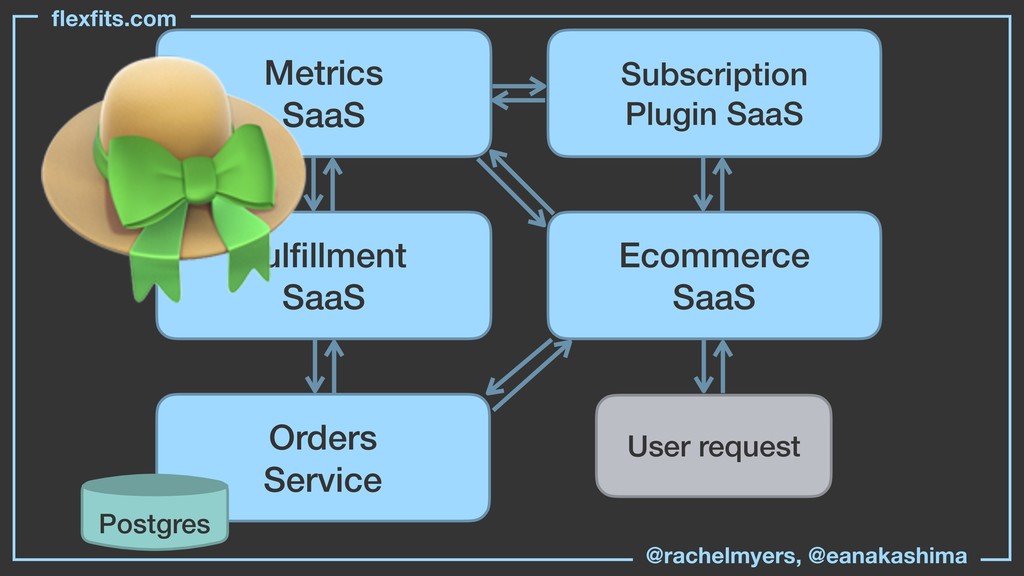
The way engineers traditionally became Distributed Systems engineers was by creating infrastructure in house and building hands-on familiarity with how data moved through a system. But specialization among engineers and increasing levels of abstraction have created a situation in which almost no one has a complete view of how data moves through an entire system, end to end.
At the same time it’s become harder to understand the systems we’re building because we didn’t build them ourselves. The skills required for understanding and diagnosing problems within a distributed system are more important for everyone, front-end, back-end, and “full-stack”, because our systems are increasingly distributed.
Topics we’ll cover:
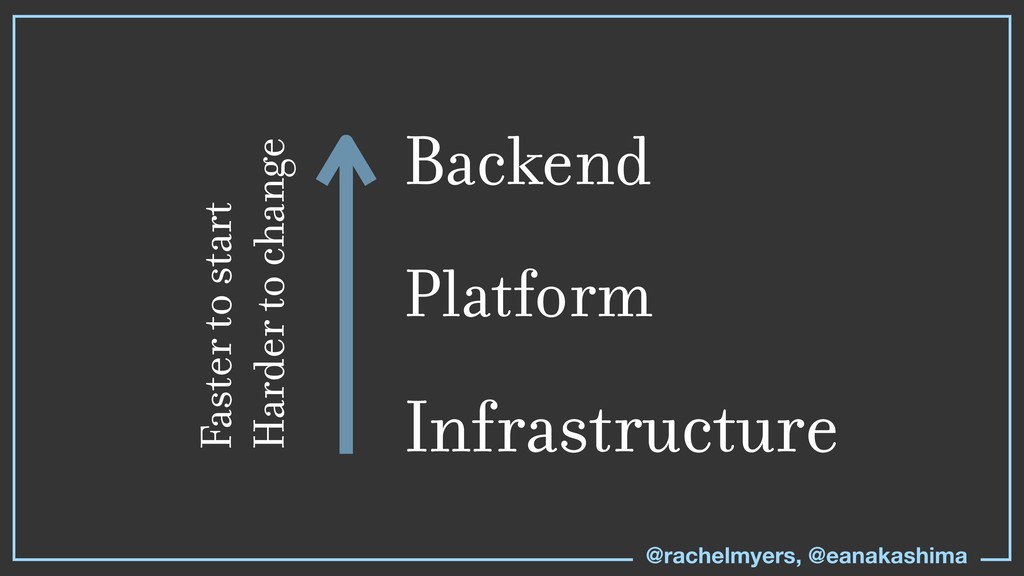
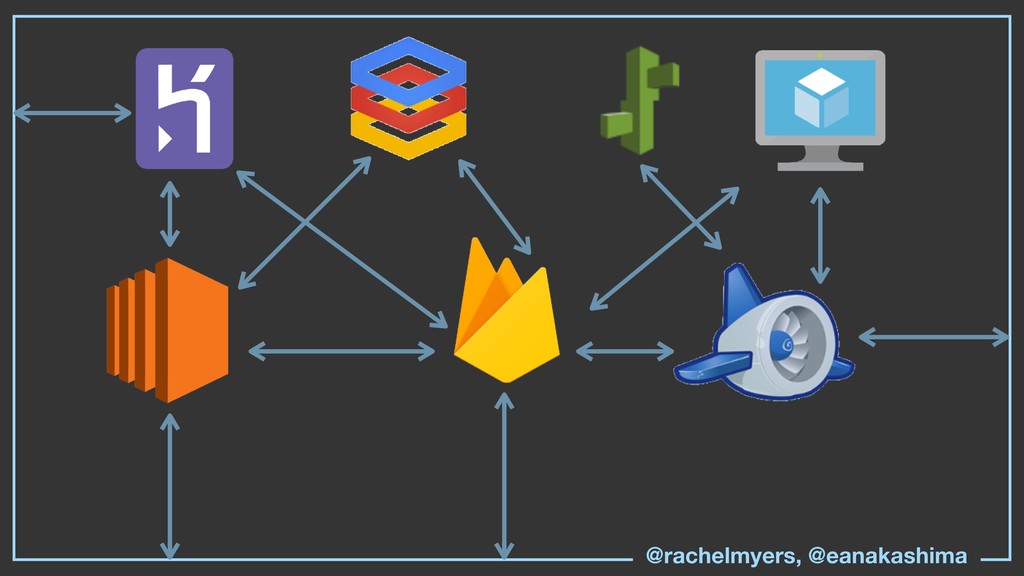
* We’ll give you the flight manual for when to use Bass, PaaS, IaaS, and the checklist of what to do if you’re already in flight with them.
* We’ll walk through the Operational consequences with war stories of surprise distributed systems problems at three different companies.
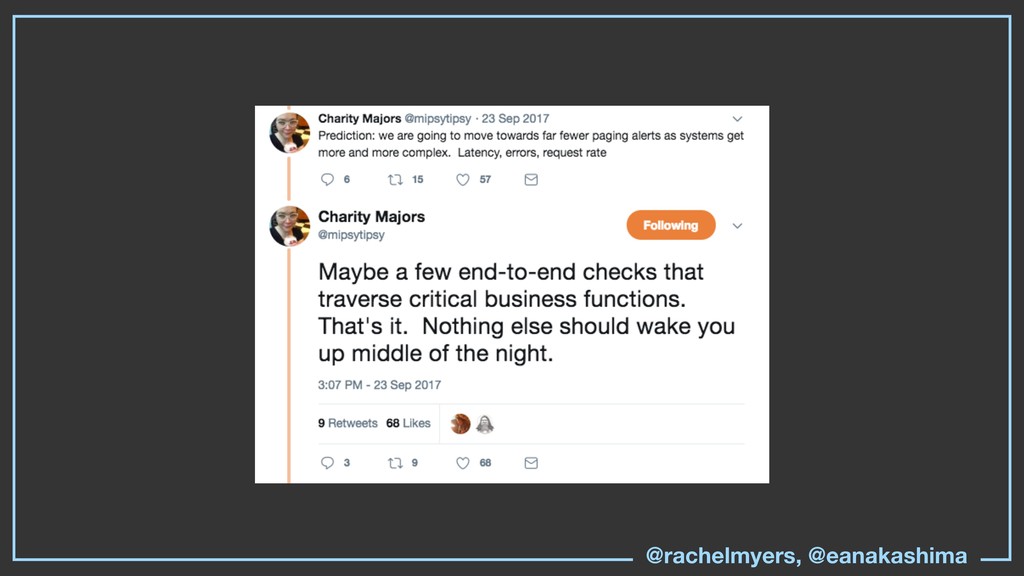
* How do you use existing tools (monitoring, tracing, alerts, logging, paging, etc) to reduce operator load, in particular for non-SRE's
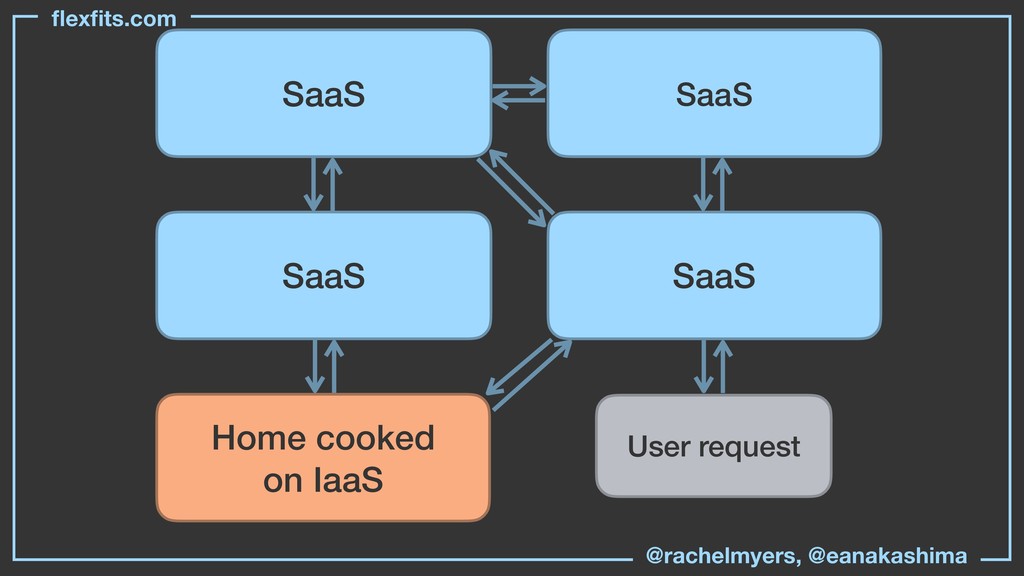
* Tools for gaining visibility into the different parts of your stack (database, app, background jobs, queues, lambda and event-based compute).
* Criteria for when the cost to own a part of your stack is worth it.
* I’m a web application engineer, how did this become part of my job again and what does it all mean???
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}