Model for Malware Detection Muhammad Najmi bin Ahmad Zabidi [email protected] IAS 2011, Universiti Teknikal Melaka (UTEM) 6th December 2011 Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 1/25
Teknologi Malaysia, Skudai • Employed by International Islamic University Malaysia, Gombak Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 2/25
‘‘undecidable’’[Cohen, 1986] • Means 100 percent detection for all time is impossible • But there’s still room for highest detection accuracy Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 3/25
detection depends on features to generate signatures • Some features could be redundant, hence computation time is more expensive • Features could be weak, not relevant • There is possibility that strong features are enough, and discard the weaker ones • This, could be reduce by dimesion reduction method Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 4/25
• Classification here refers to classification between malicious, suspicious and benign software • Tackling the problem of false positive, false negative and increase precision Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 5/25
• Unknown malware is the problem • No prior knowledge • Suggesting unsupervised categorization Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 6/25
based: • [Chouchane et al., 2007, Saudi et al., 2010, Merkel et al., 2010] Data mining and machine learning: • [Sun et al., 2010, Komashinskiy and Kotenko, 2009, Komashinskiy and Kotenko, 2010] • [Elovici et al., 2007, Gavrilut et al., 2009, Firdausi et al., 2010, Golovko et al., 2010] Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 7/25
classifier at first to segregate malware and non malware • Use specific classifier secondly to segregate special traits of malware (trojan, worm, virus) • Supervised categorization is needed, to classify known malware features • In recent literatures, the term semi-supervised learning is coined to represent the ‘‘assisted’’ unsupervised categorization • Ensemble classification helps, since base weak learner could be boosted • Unsupervised categorization (clustering) needed, to categorization unknown malware Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 9/25
hence the new malware which previously unknown can be taught as known, hence will be discarded at early phase Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 10/25
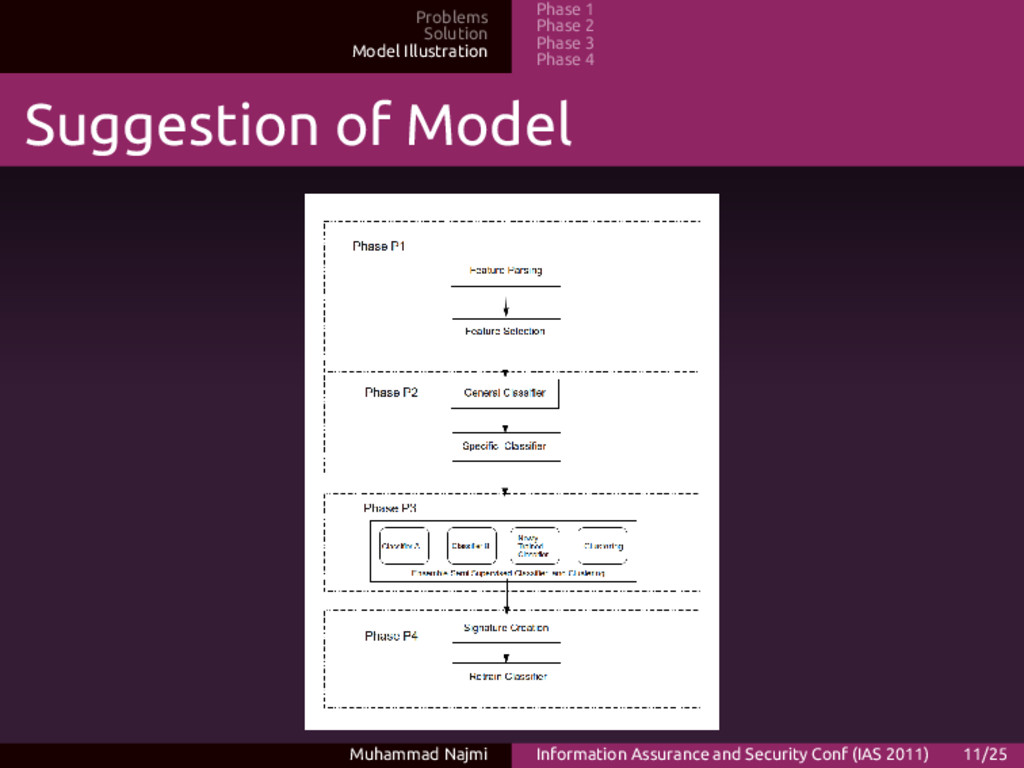
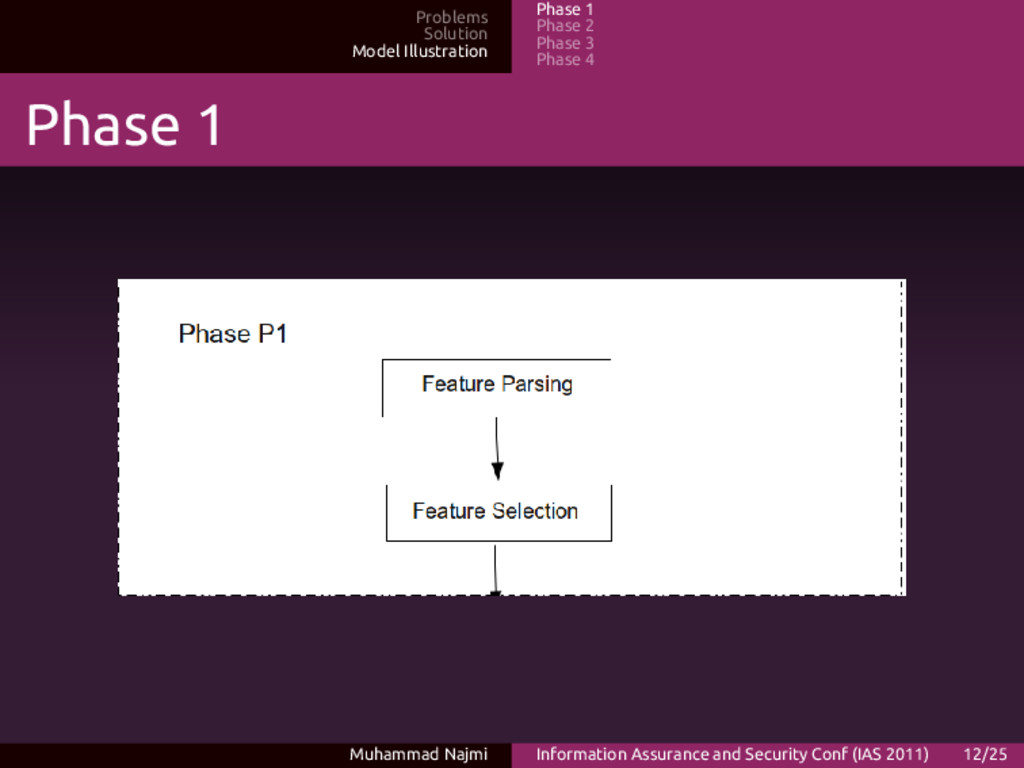
Phase 4 P1 descriptions • Preprocessing work includes ripping API calls, or any other useful information from the malware binaries • The process of feature selection is being done here Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 13/25
Phase 4 Features • Features, in this case is API calls: • The less API calls could be used, the better • Dimension reduction method is being used to handle this • Future work, we considering adding entropy analysis of packed binary body, apart from the API calls profiling Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 14/25
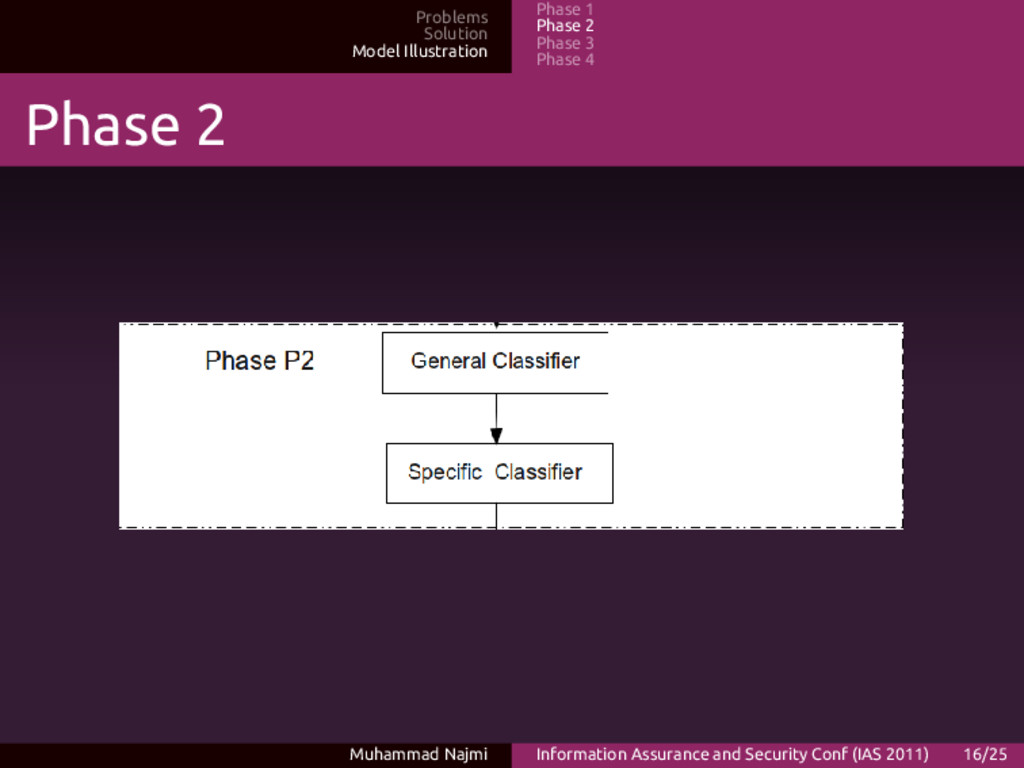
Phase 4 P2 Descriptions • Malware being categorized according to common traits of generic malware • Next, specific symptom according to the classes of malware (worm, trojan, virus) being done • Malware could have all the packages together, but usually there is dominant feature Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 17/25
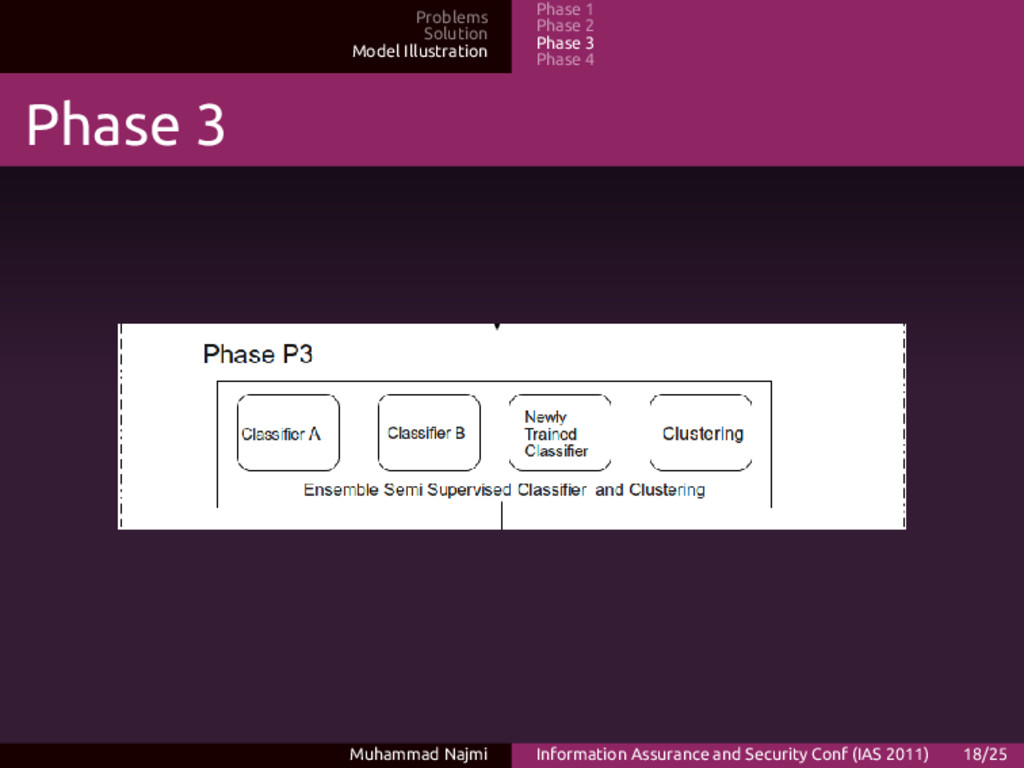
Phase 4 P3 Descriptions • Use ensemble based classification, using weak learners • Many weak learners, via voting could represent more accurate results • If there is unknown class, it will go into into clustering phase Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 19/25
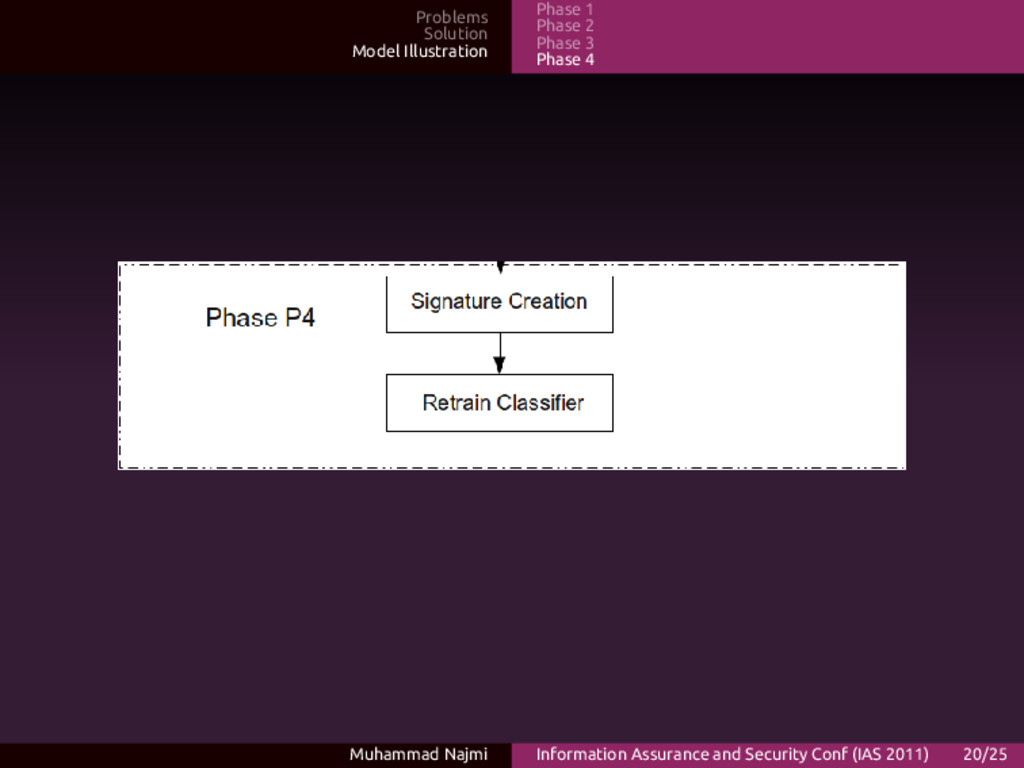
Phase 4 P4 Descriptions • A signature being created, if the malware is new • The new signature will be added to the current categorization • This will minimize the next detection cycle for the next malware Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 21/25
Phase 4 The Dataset In malware research, there is no standard dataset, unlike Intrusion Detection area which usually relied on KDD/MIT Lincoln datasets. • We obtain malware samples from CyberSecurityMalaysia(CSM), consists of 2GB malware files, amounted around 30,000 malware binaries • We have to build our own dataset to extract the features • This, considered preprocessing work Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 22/25
Phase 4 Conclusion • Soft computing approach could assist in malware detection • Feature selection could assist in minimizing feature processing • Ensemble methods could help in increasing malware categorization • Adaptive learning could help in avoiding redundant retraining for the n next iteration Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 23/25
Phase 4 Bibliography Chouchane, M. R., Walenstein, A., and Lakhotia, A. (2007). Statistical signatures for fast filtering of instruction-substituting metamorphic malware. In Proceedings of the 2007 ACM workshop on Recurring malcode, WORM ’07, pages 31--37, New York, NY, USA. ACM. Cohen, F. B. (1986). Computer viruses. PhD thesis, Los Angeles, CA, USA. AAI0559804. Elovici, Y., Shabtai, A., Moskovitch, R., Tahan, G., and Glezer, C. (2007). Applying machine learning techniques for detection of malicious code in network traffic. Muhammad Najmi Information Assurance and Security Conf (IAS 2011) 25/25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}