Neste workshop apresentado na Python Sul de 2018, realizada em Florianópolis, executei alguns exemplos de scrap de dados utilizando o framework Scrapy. A ideia do workshop é apresentar as principais aplicações do Scrapy e como começar a utilizar a ferramenta.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
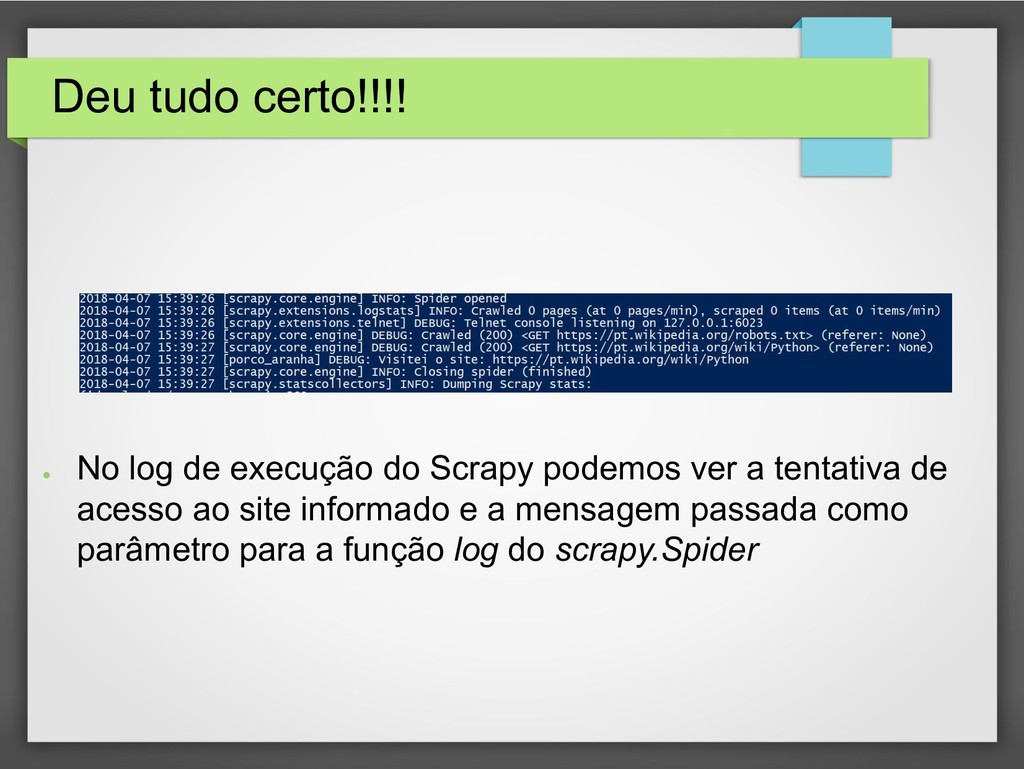{kind=link}
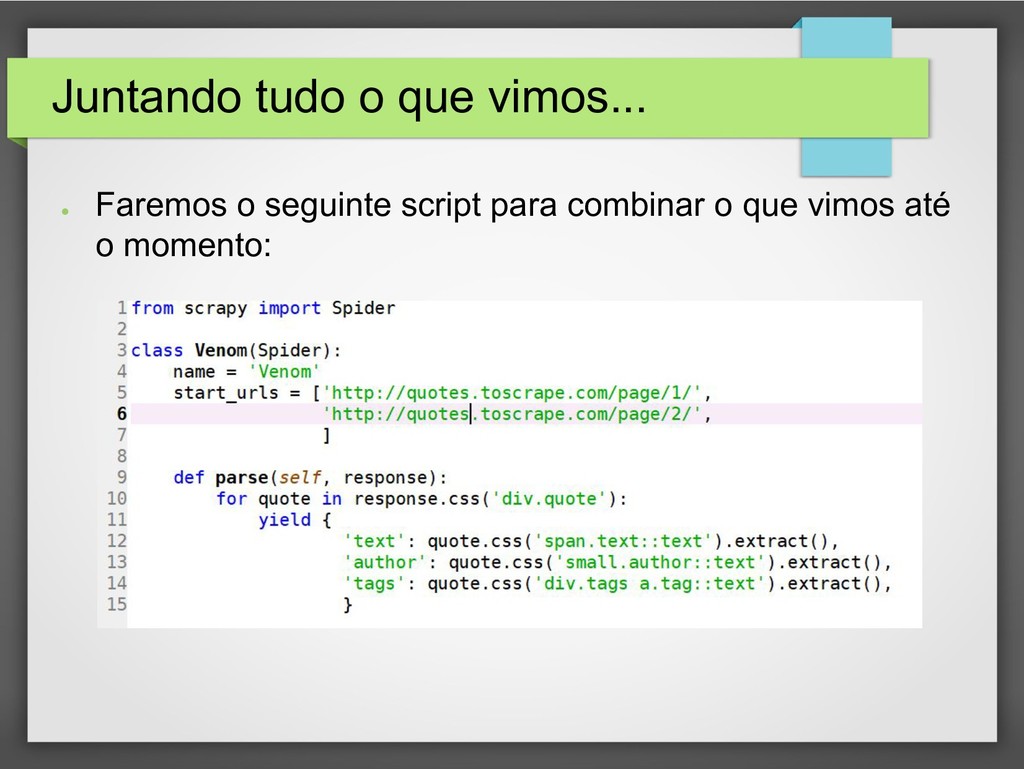{kind=link}
{kind=link}
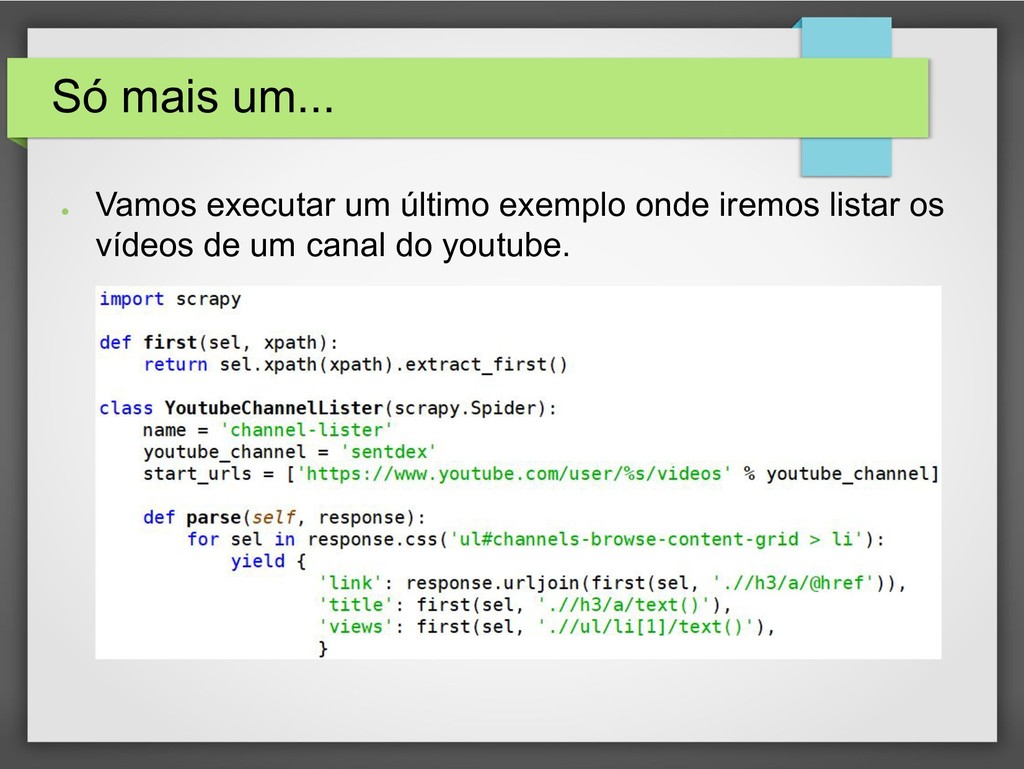{kind=link}
{kind=link}
{kind=link}