Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
小さく始めるデータ基盤
Search
Reiji Kainuma
February 07, 2022
Programming
1.5k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
小さく始めるデータ基盤
https://github.com/reizist/slide/tree/master/datatech_casual%231
Reiji Kainuma
February 07, 2022
More Decks by Reiji Kainuma
See All by Reiji Kainuma
Airflow1=>Airflow2へのupgrade 事例紹介
reizist
0
910
lambdaのソース管理@meguro.dev#5/infrastructure as code of lambda
reizist
0
300
Other Decks in Programming
See All in Programming
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
kishida
12
4.4k
Make SRE Operations Easier with Azure SRE Agent
kkamegawa
0
8.2k
トークンをケチるな、設計しろ:GitHub Copilotを賢く使うコンテキスト戦略
ochtum
0
190
コンテキストの使い捨てをやめる — ビジネスルール駆動開発と miko —
ioki
0
240
技術記事、 専門家としてのプログラマ、 言語化
mizchi
13
6.5k
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
840
はてなアカウント基盤 State of the Union
cockscomb
1
860
LLMによるContent Moderationの本番運用の裏側と品質担保への挑戦
suikabar
3
780
Oxlintのカスタムルールの現況
syumai
6
1.2k
Hunting Vulnerabilities in Symfony with LLMs
vinceamstoutz
0
560
エージェンティックRAGにAWSで入門しよう!
har1101
9
1.8k
JavaDoc 再入門
nagise
1
420
Featured
See All Featured
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
140
Optimising Largest Contentful Paint
csswizardry
37
3.7k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Deep Space Network (abreviated)
tonyrice
0
210
Site-Speed That Sticks
csswizardry
13
1.2k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
YesSQL, Process and Tooling at Scale
rocio
174
15k
Product Roadmaps are Hard
iamctodd
PRO
55
12k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
150
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.2k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Transcript
小さく始めるデータ基盤 @reizist 1 / 18
自己紹介 @reizist Web Backend / Infra / Data (Infra) R
なんとかという会社で データエンジニア 最近CloudComposer2 と戯れています 2 / 18
背景 データ基盤はもはや大規模サービスにのみ必要なものではない スタートアップでもデータ基盤の需要は増えてきている 今回 副業で enpay.Inc で構築した事例を紹介します 3 / 18
事前制約 外部にダッシュボードを埋め込みで提供したい Looker を採用したい 4 / 18
重要視した方針 汎用化 エンハンス/ リプレイスしやすい技術を採用 作り込まない Airflow, Argo Workflow 等ワークフローエンジンの採用を見送る リスク最小化
DWH には個人情報を一切入れない「全部なし戦略」 5 / 18
どんなデータを集める? 1. クライアントログ 2. DB 3. 各SaaS(kintone) 6 / 18
どこにデータを集める? BigQuery エコシステムが整って枯れているBigQuery に不満がなかった 権限周り/cli 周りの取り回し Snowflake のtrial してみたいと思いつつ.. 7
/ 18
Q. どうやってデータを集める? 真っ先にtrocco をtrial で導入し検討した あらゆるデータソースに対応していて要件(DB, SaaS からのデー タ取り込み) は満たせた
が要件に対してはコストが見合わなかったので断念 Embulk on CloudRun を採用 コンテナベースなので安心 8 / 18
Amazon S3 Amazon RDS Cloud Build Cloud Storage db-importer Cloud
Run Push AWS Step Functions workflow rds-exporter Create DBClusterSnapshot StartExportTask EventBridge run-embulk Cloud Run BigQuery DB SaaS ClientLog 9 / 18
DB Aurora instance から個人情報をすべてマスク済のsnapshot を作成 snapshot からS3 にParquet でexport S3
に DB のデータがリスクのない状態で配置 CloudRun 上で実行されるbq load によりS3 のParquet をBQ にimport 10 / 18
SaaS Embulk on CloudRun CloudRun のroot endpoint にアクセスすると実装済のすべての embulk config
をsequential にembulk run する 環境変数によって個別に実行可能 SaaS 毎のendpoint を作る等自由に拡張可能 11 / 18
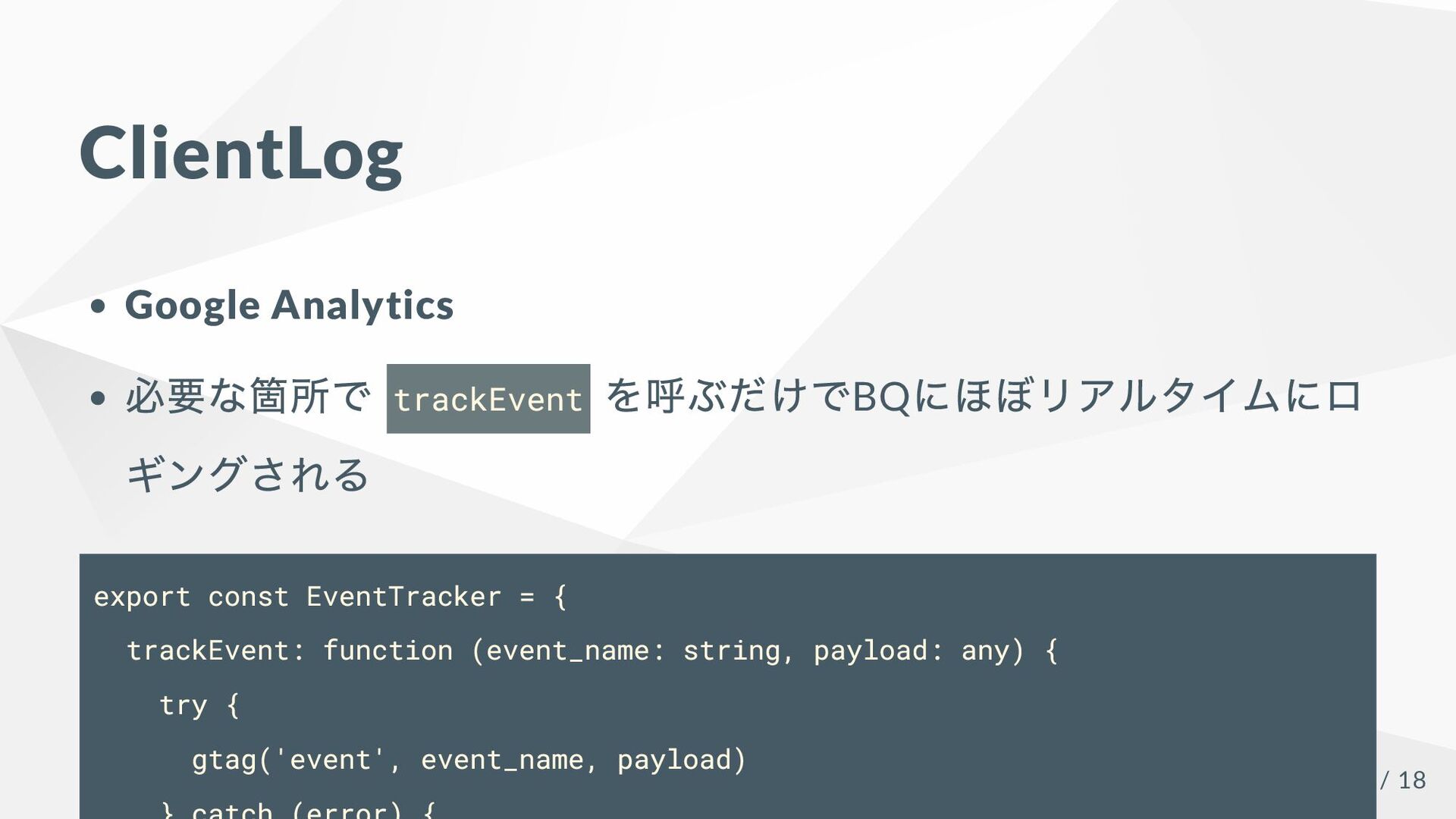
ClientLog Google Analytics 必要な箇所で trackEvent を呼ぶだけでBQ にほぼリアルタイムにロ ギングされる export const
EventTracker = { trackEvent: function (event_name: string, payload: any) { try { gtag('event', event_name, payload) 12 / 18
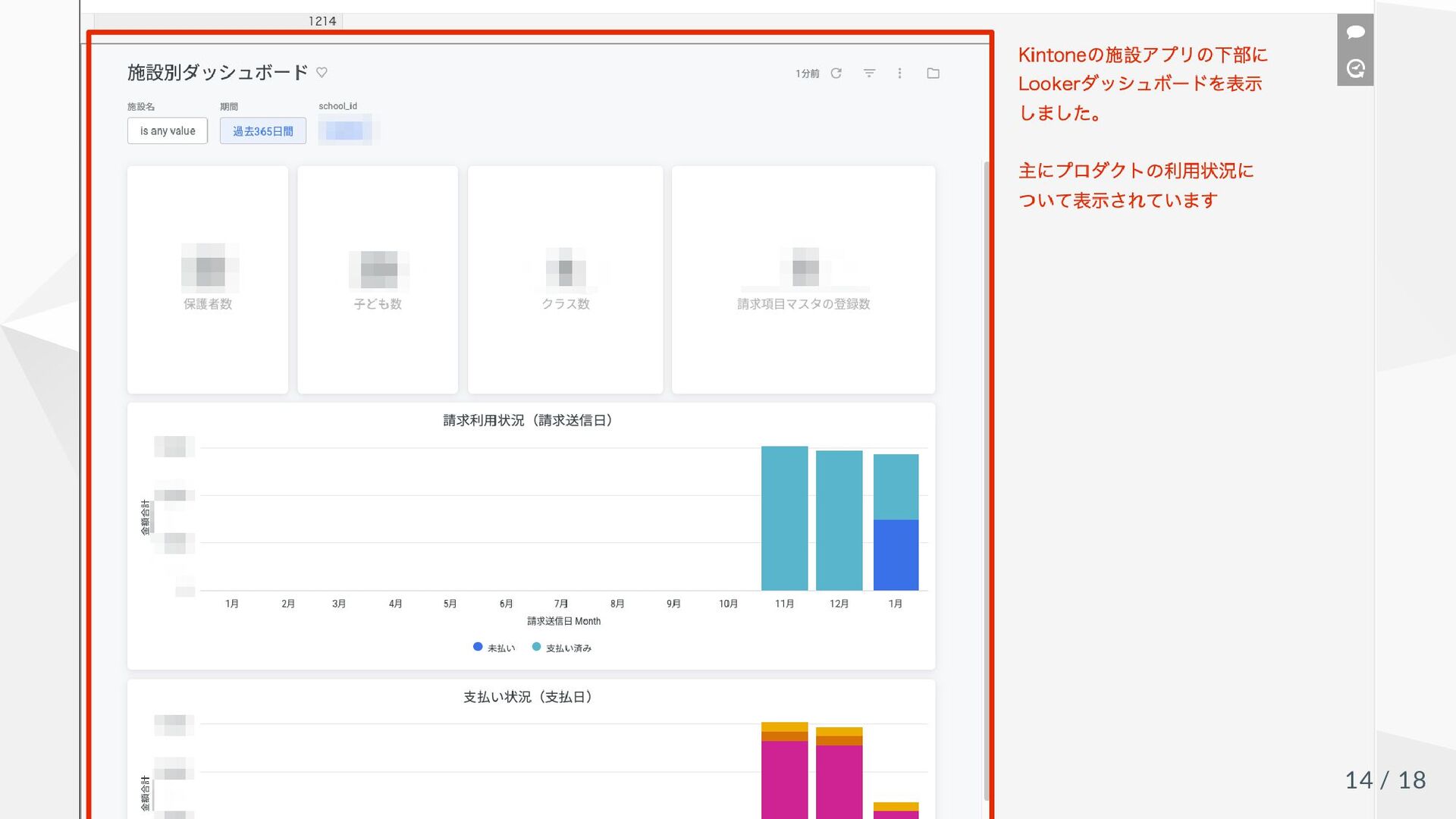
どうやって使っている? まずはsales/cs メンバー向けのkintone ダッシュボード上でLooker ダ ッシュボードを埋め込み表示 今後エンドユーザーに便利ダッシュボードを公開予定 13 / 18
14 / 18
稼働状況 StepFunction, CloudRun 共に daily job は実装完了後一度も落ちていない 15 / 18
ランニングコスト 実質無料 CloudRun & BQ (& CloudBuild) で200 円くらい CloudRun
最高! 16 / 18
enpay のプロダクト/ データに興味がある方はこちらへどうぞ! Looker 採用決定したCTO がカジュアルにトークします 17 / 18
まずは小さく始めよう 18 / 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}