Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[論文解説] Disentangled Learning with Synthetic Par...
Search
Reon Kajikawa
November 06, 2024
19
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[論文解説] Disentangled Learning with Synthetic Parallel Data for Text Style Transfer
Reon Kajikawa
November 06, 2024
More Decks by Reon Kajikawa
See All by Reon Kajikawa
[論文解説] mPLUG-DocOwl2: High-resolution Compressing for OCR-free Multi-page Document Understanding
reon131
0
21
[論文解説] Not All Negatives are Equal: Label Aware Contrastive Loss for Fine grained Text Classification
reon131
0
25
[論文解説] Large Language Models can Contrastively Refine their Generation for Better Sentence Representation Learning
reon131
0
26
[論文解説] SentiCSE: A Sentiment-aware Contrastive Sentence Embedding Framework with Sentiment-guided Textual Similarity
reon131
0
39
[論文解説] Text Embeddings Reveal (Almost) As Much As Text
reon131
0
150
[論文解説] OssCSE: Overcoming Surface Structure Bias in Contrastive Learning for Unsupervised Sentence Embedding
reon131
0
18
[論文解説] Sentence Representations via Gaussian Embedding
reon131
0
130
[論文解説] Unsupervised Learning of Style-sensitive Word Vectors
reon131
0
31
[論文解説] One Embedder, Any Task: Instruction-Finetuned Text Embeddings
reon131
0
53
Featured
See All Featured
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
410
How to Think Like a Performance Engineer
csswizardry
28
2.7k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Automating Front-end Workflow
addyosmani
1370
210k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
New Earth Scene 8
popppiees
3
2.4k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
AI: The stuff that nobody shows you
jnunemaker
PRO
8
790
Utilizing Notion as your number one productivity tool
mfonobong
4
360
Transcript
Disentangled Learning with Synthetic Parallel Data for Text Style Transfer
Jingxuan Han, Quan Wang, Zikang Guo, Benfeng Xu,Licheng Zhang, Zhendong Mao ACL 2024 URL:https://aclanthology.org/2024.acl-long.811/ 発表者:M1 梶川 怜恩
スタイル変換の課題 • 学習データが不足している • 教師なし学習手法として分離学習 • 教師信号がない → 意味の保持ができていないことが問題 提案手法
• 合成データを用いた分離学習の提案 • 合成データ:パラレルコーパスをLLMで生成 • 分離学習 :意味の保持とスタイル制御を目的とする損失の設計 1 概要
スタイル変換とは • 意味を変えずに文のスタイルを変更する技術 • 感情、性別、形式、ユーモアなど 特徴 • パラレルデータが不足している • 教師なし手法が多く提案されてきた
2 背景:スタイル変換
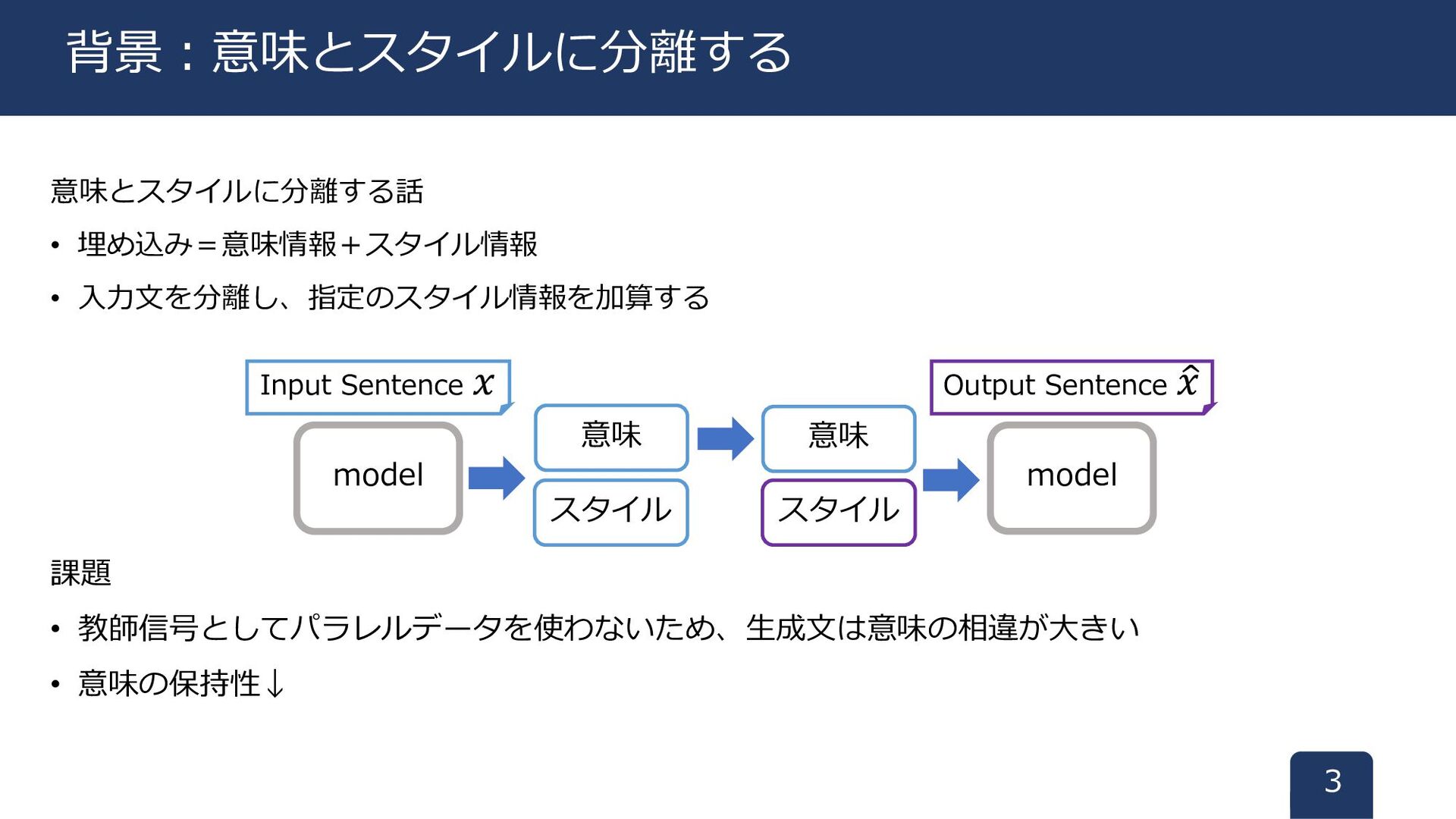
意味とスタイルに分離する話 • 埋め込み=意味情報+スタイル情報 • 入力文を分離し、指定のスタイル情報を加算する 課題 • 教師信号としてパラレルデータを使わないため、生成文は意味の相違が大きい • 意味の保持性↓
3 背景:意味とスタイルに分離する スタイル Input Sentence 𝑥 model 意味 スタイル 意味 Output Sentence ො 𝑥 model
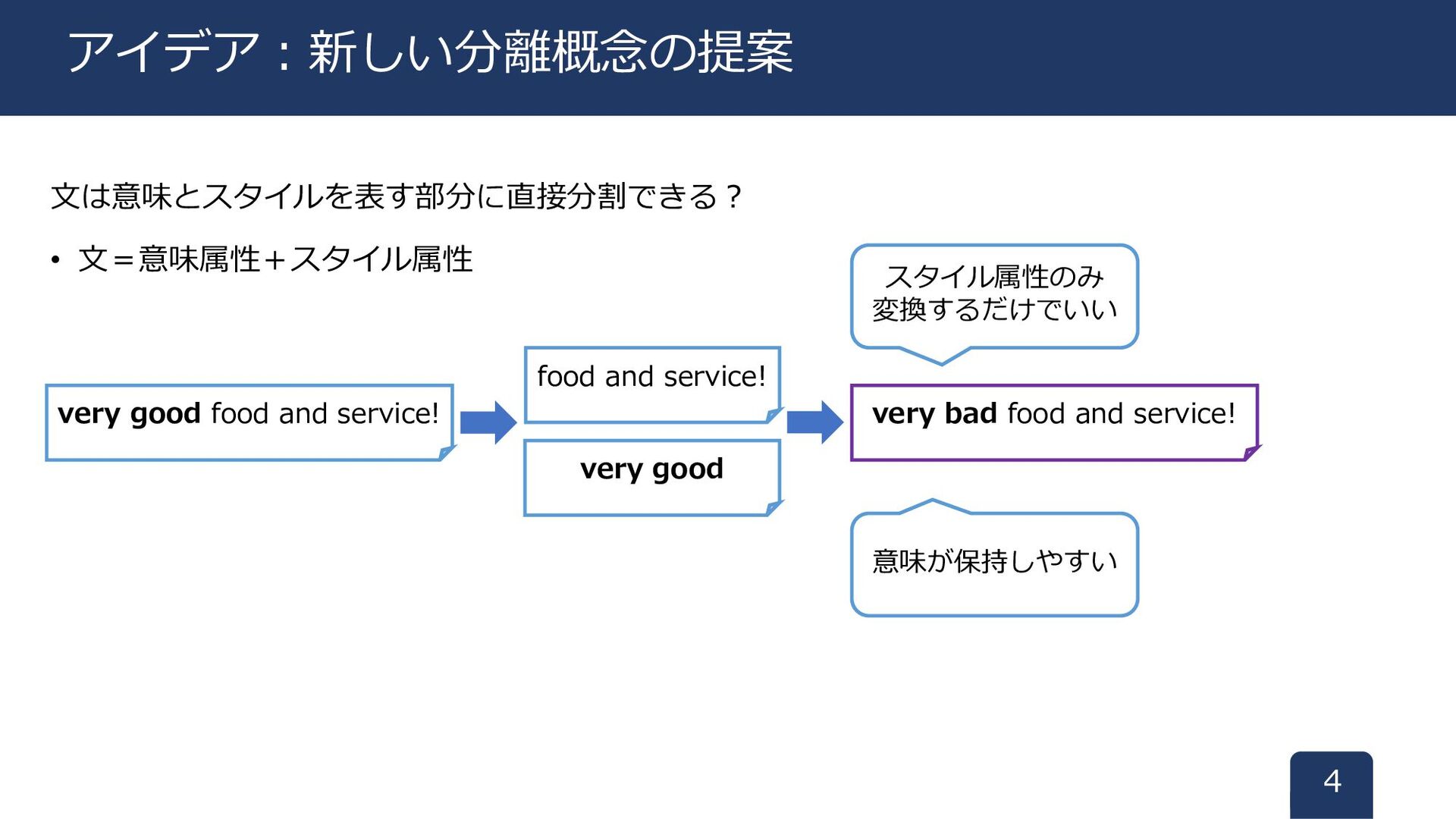
文は意味とスタイルを表す部分に直接分割できる? • 文=意味属性+スタイル属性 4 アイデア:新しい分離概念の提案 very good food and service!
food and service! very good very bad food and service! スタイル属性のみ 変換するだけでいい 意味が保持しやすい
分離ベースのフレームワークDisenTransを提案する • 合成パラレルコーパスを構築 LLMで合成文を生成する • 分離学習手法を提案 意味の保持とスタイル制御を目的とする損失の設計 5 提案手法:合成データで分離学習しよう
LLMで合成データ 6
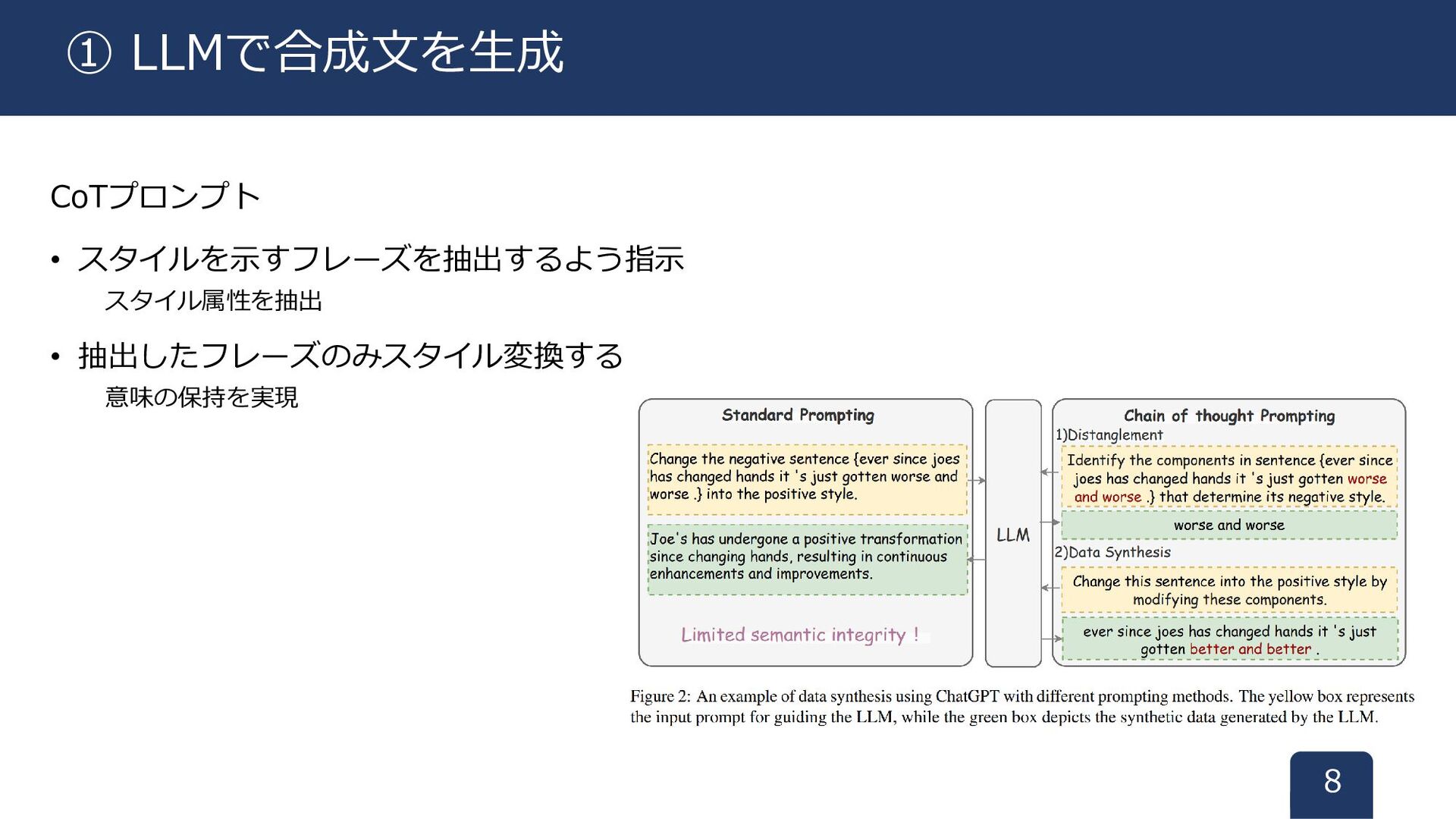
以下の手順で作成する ① LLMで合成文を生成する CoTプロンプトを利用。意味を保持しながら生成するように指示 ② 合成文をフィルタリングし、品質を確保するためのエラー検出器を設計 7 合成パラレルデータの作成手順
CoTプロンプト • スタイルを示すフレーズを抽出するよう指示 スタイル属性を抽出 • 抽出したフレーズのみスタイル変換する 意味の保持を実現 8 ① LLMで合成文を生成
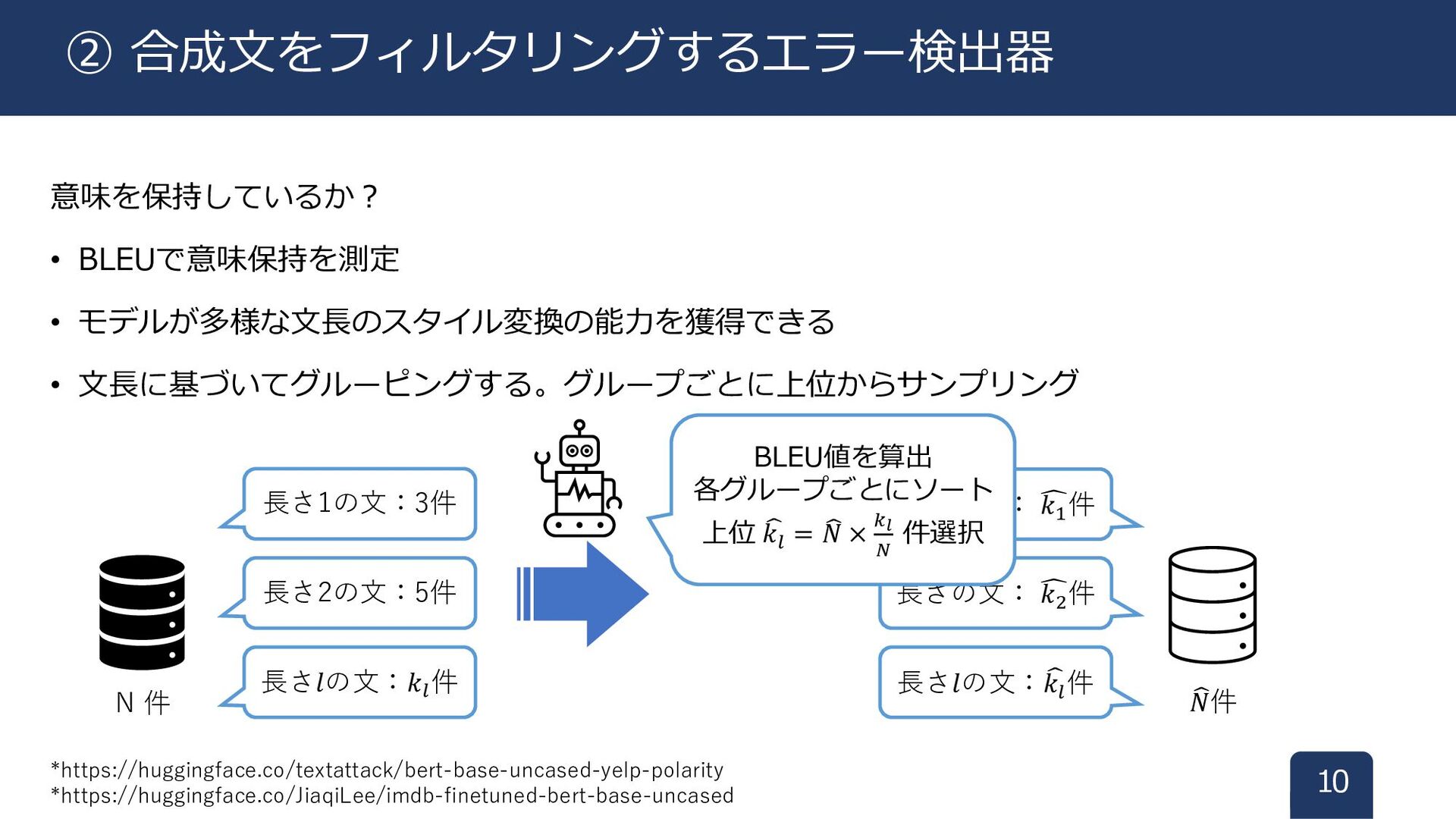
指定したスタイルになっているか? • 分類器*を用いて、スタイルが不正確な文をフィルタリング 意味を保持しているか? • BLEUで意味保持を測定 9 ② 合成文をフィルタリングするエラー検出器 *https://huggingface.co/textattack/bert-base-uncased-yelp-polarity
*https://huggingface.co/JiaqiLee/imdb-finetuned-bert-base-uncased 97.0%と91.0%の精度
長さ𝑙の文: 𝑘𝑙 件 長さの文: 𝑘2 件 長さの文:
𝑘1 件 k 意味を保持しているか? • BLEUで意味保持を測定 • モデルが多様な文長のスタイル変換の能力を獲得できる • 文長に基づいてグルーピングする。グループごとに上位からサンプリング 10 ② 合成文をフィルタリングするエラー検出器 *https://huggingface.co/textattack/bert-base-uncased-yelp-polarity *https://huggingface.co/JiaqiLee/imdb-finetuned-bert-base-uncased BLEU値を算出 各グループごとにソート 上位 𝑘𝑙 = 𝑁 × 𝑘𝑙 𝑁 件選択 長さ1の文:3件 長さ2の文:5件 長さ𝑙の文:𝑘𝑙 件 N 件 𝑁件
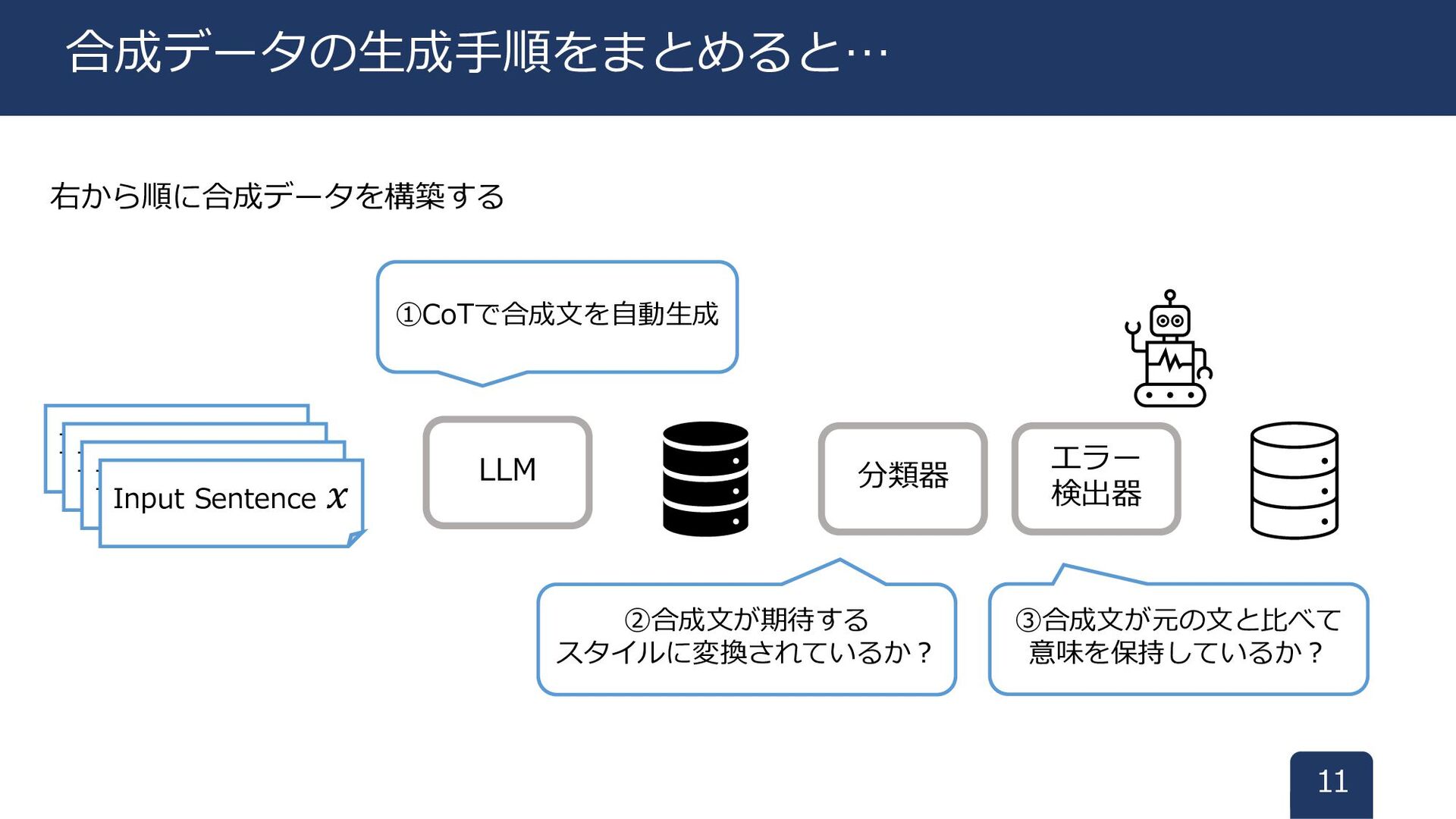
右から順に合成データを構築する 11 合成データの生成手順をまとめると… LLM 分類器 エラー 検出器 Input Sentence 𝑥
Input Sentence 𝑥 Input Sentence 𝑥 Input Sentence 𝑥 ①CoTで合成文を自動生成 ②合成文が期待する スタイルに変換されているか? ③合成文が元の文と比べて 意味を保持しているか?
分離学習手法 12
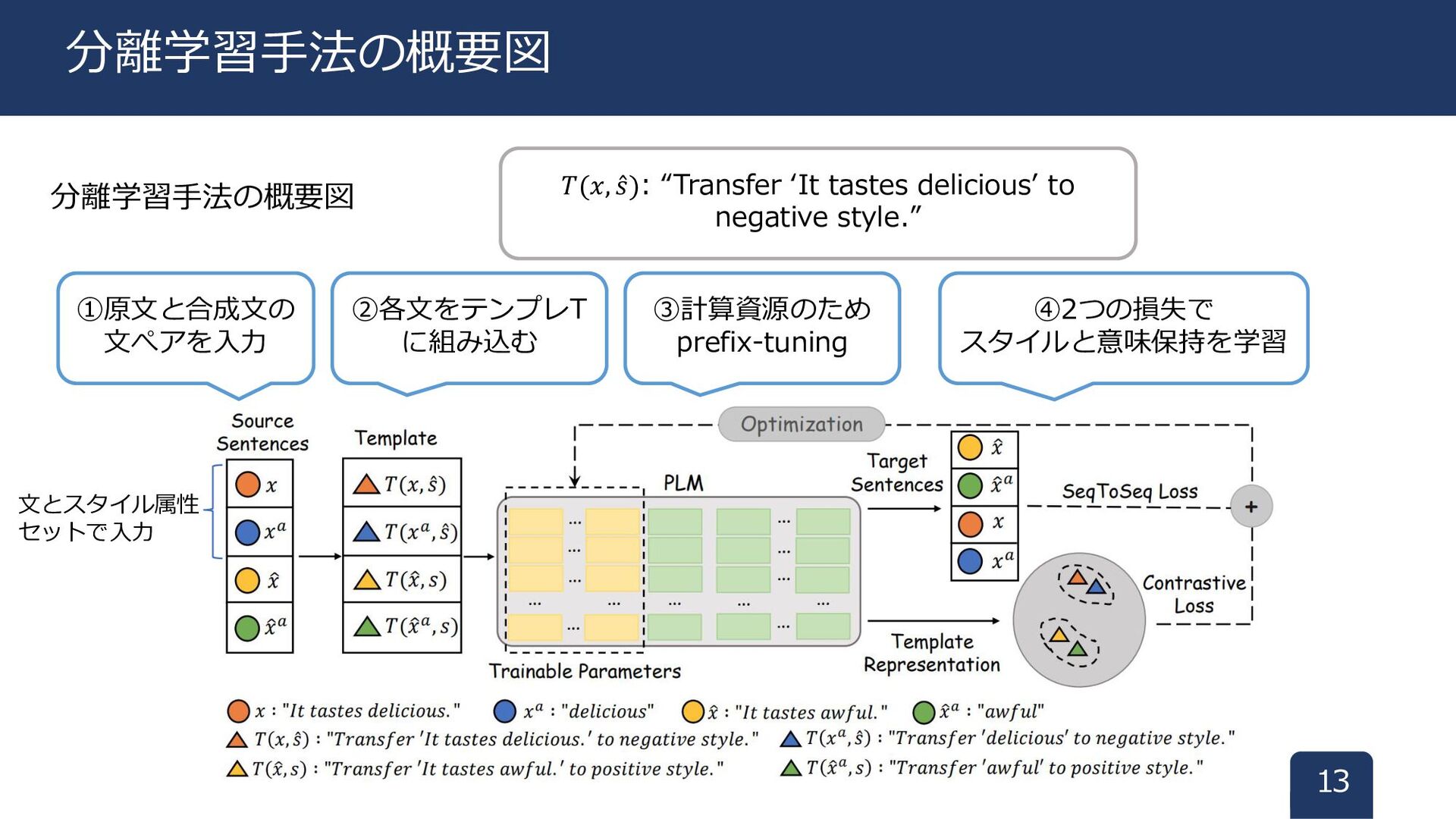
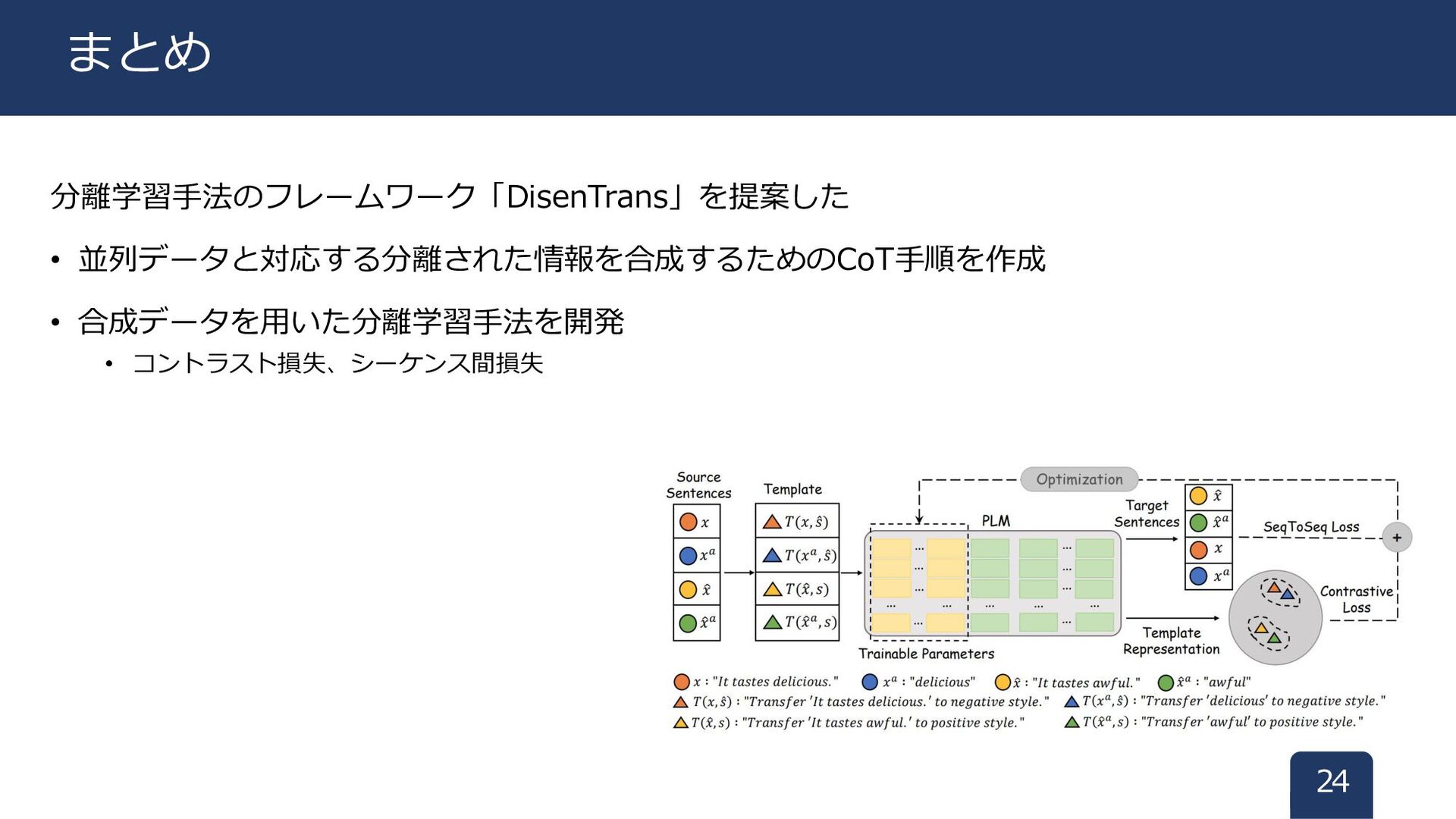
分離学習手法の概要図 13 分離学習手法の概要図 ①原文と合成文の 文ぺアを入力 ②各文をテンプレT に組み込む 𝑇(𝑥, Ƹ 𝑠):
“Transfer ‘It tastes delicious’ to negative style.” ③計算資源のため prefix-tuning ④2つの損失で スタイルと意味保持を学習 文とスタイル属性 セットで入力
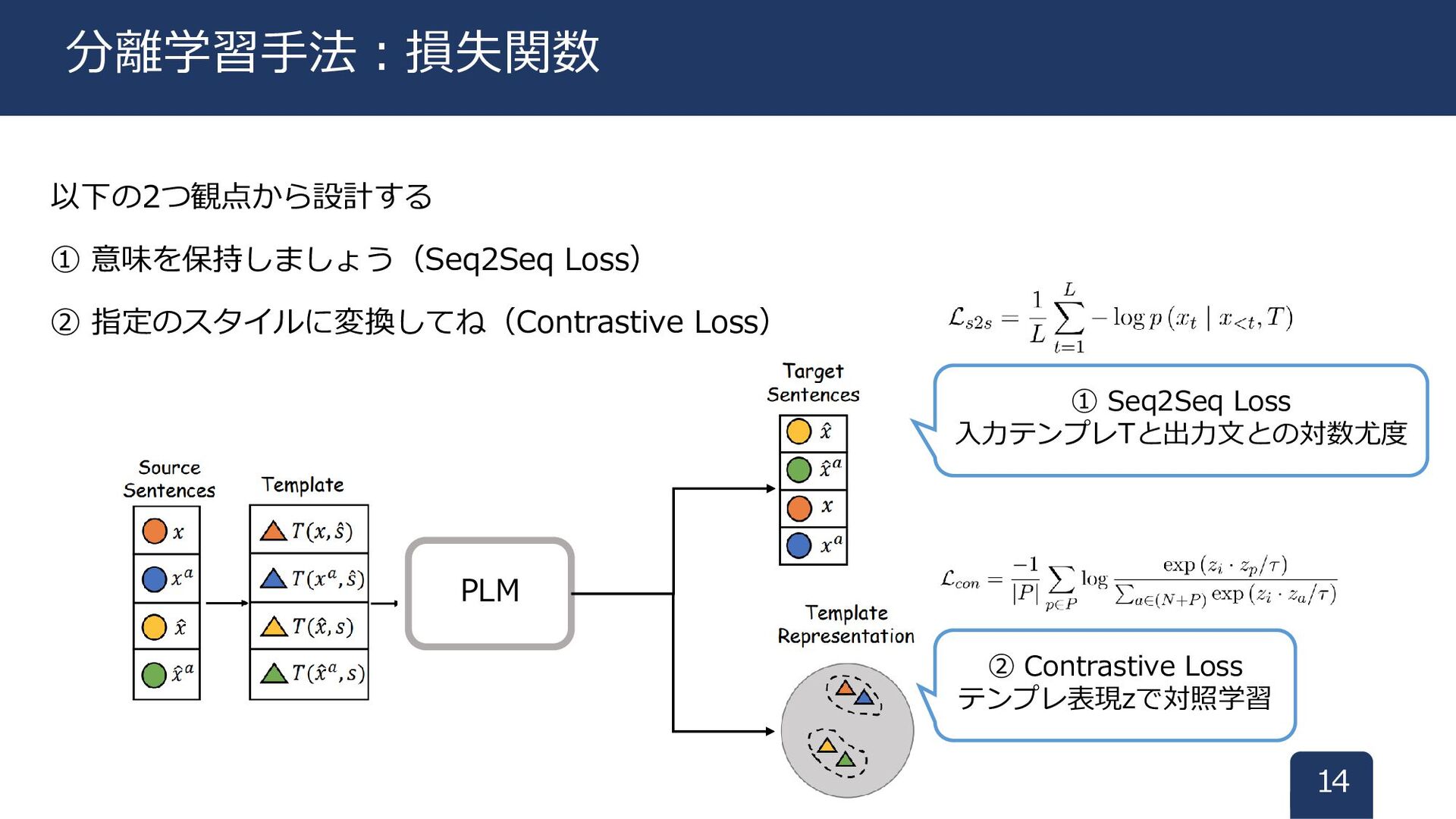
以下の2つ観点から設計する ① 意味を保持しましょう(Seq2Seq Loss) ② 指定のスタイルに変換してね(Contrastive Loss) 14 分離学習手法:損失関数 PLM
① Seq2Seq Loss 入力テンプレTと出力文との対数尤度 ② Contrastive Loss テンプレ表現zで対照学習
評価実験 15
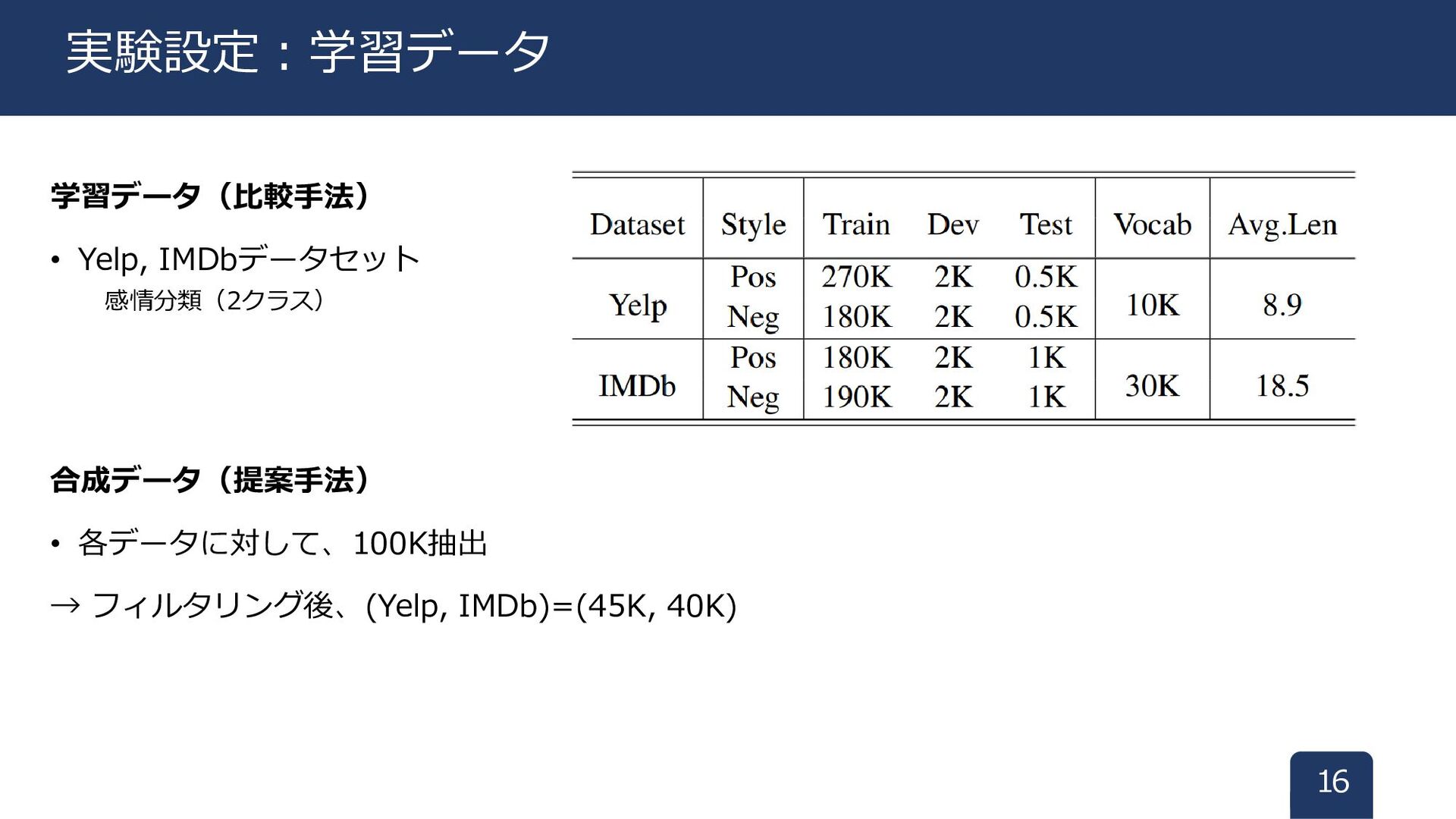
学習データ(比較手法) • Yelp, IMDbデータセット 感情分類(2クラス) 合成データ(提案手法) • 各データに対して、100K抽出 → フィルタリング後、(Yelp,
IMDb)=(45K, 40K) 16 実験設定:学習データ
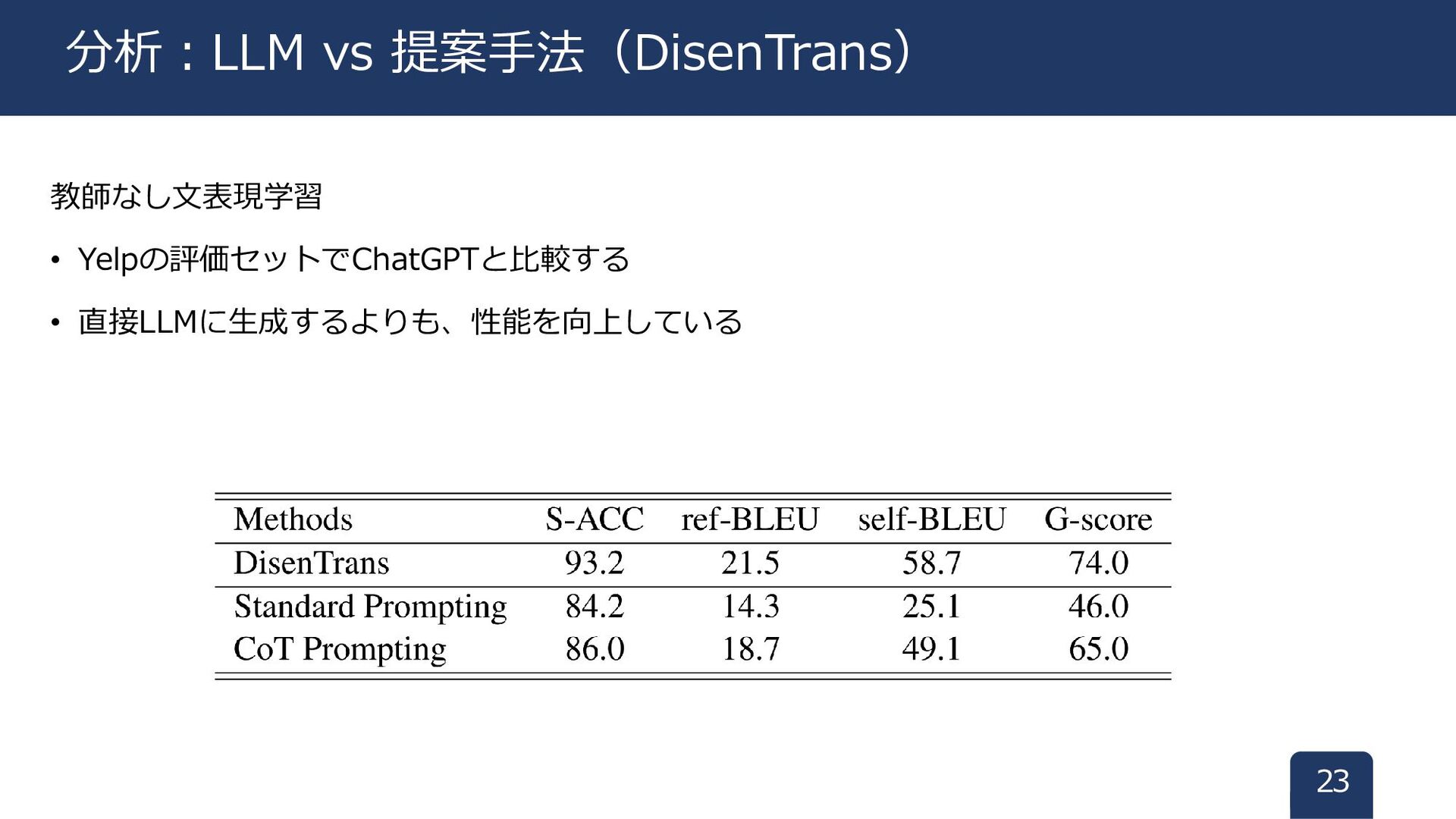
自動評価 • スタイル制御 • S-ACC:訓練データで感情分類器を構成。出力ラベルを正解ラベルとする。 • 意味保持 • ref-BLEU :出力文と参照文との類似度(=BLEU)
• self-BLEU:入出力文の類似度 • 総合評価 • G-Score:S-ACCとself-BLEUの幾何平均(n√a1*a2…an) 人手評価 • 出力文を評価 • スタイル制御(SC)、意味保持(SP)、流暢性(FL) • 5段階評価 • 3人の平均スコアを最終スコアにした 17 実験設定:評価について
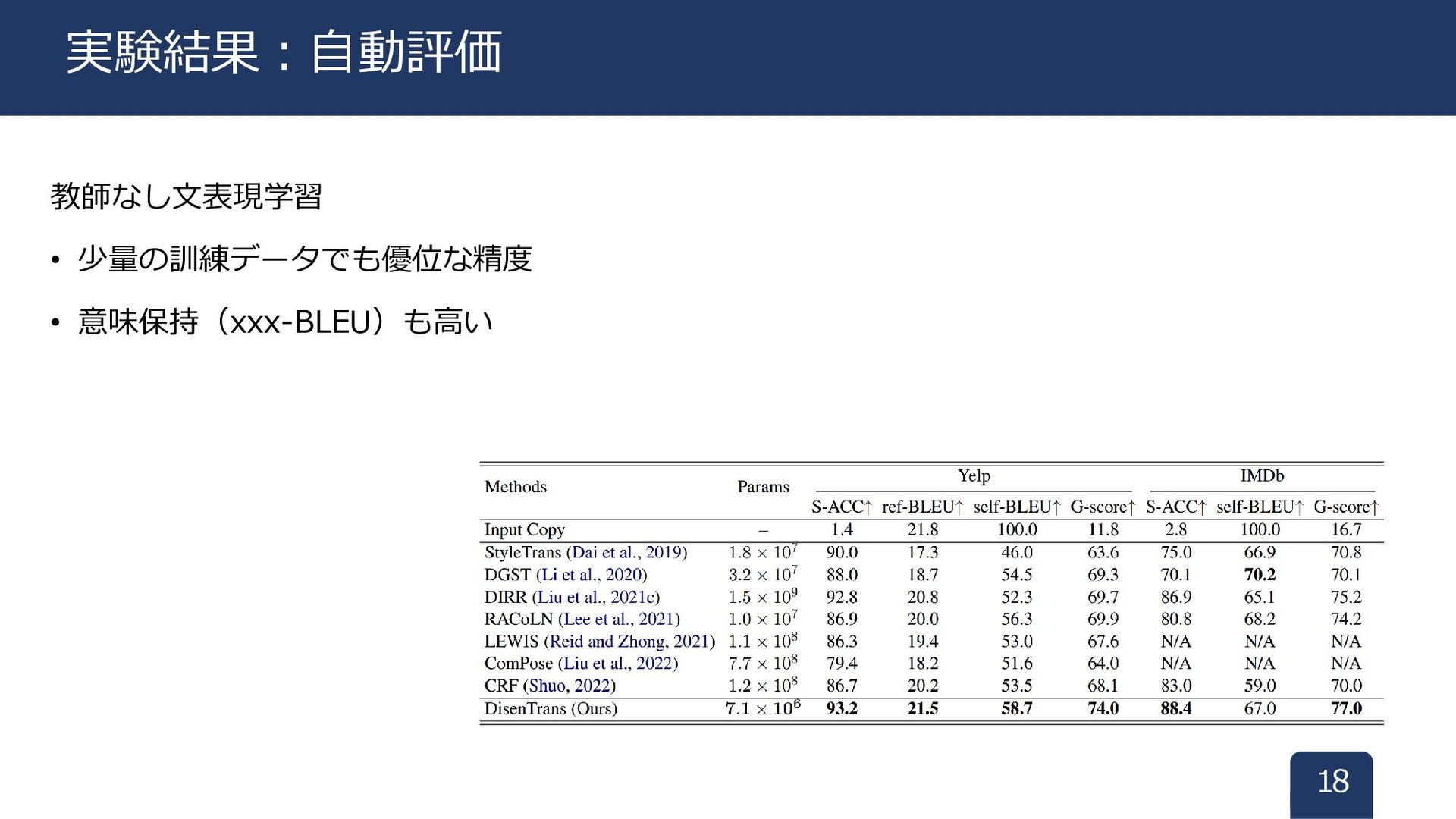
教師なし文表現学習 • 少量の訓練データでも優位な精度 • 意味保持(xxx-BLEU)も高い 18 実験結果:自動評価
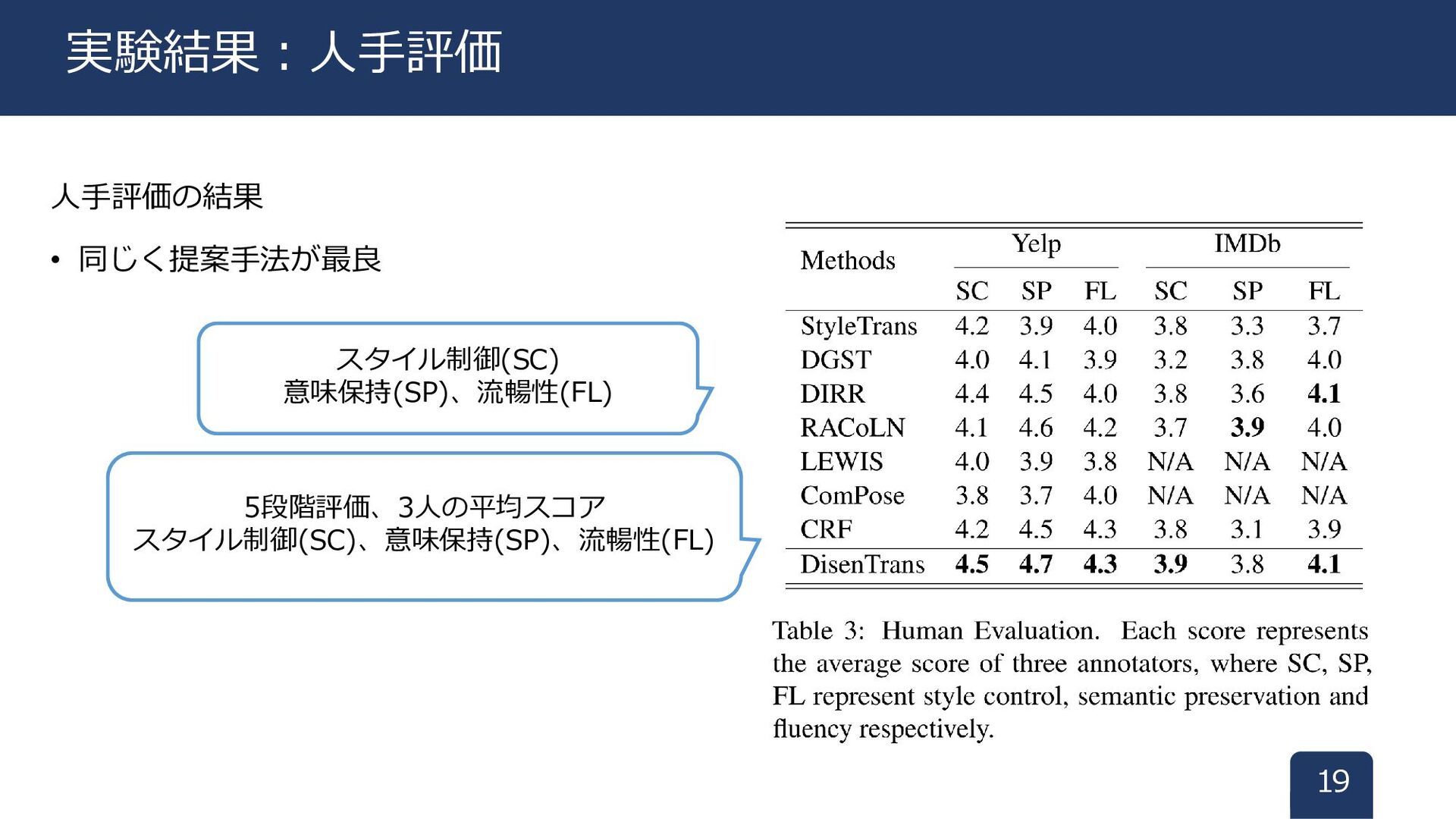
人手評価の結果 • 同じく提案手法が最良 19 実験結果:人手評価 スタイル制御(SC) 意味保持(SP)、流暢性(FL) 5段階評価、3人の平均スコア 5段階評価、3人の平均スコア スタイル制御(SC)、意味保持(SP)、流暢性(FL)
分析 20
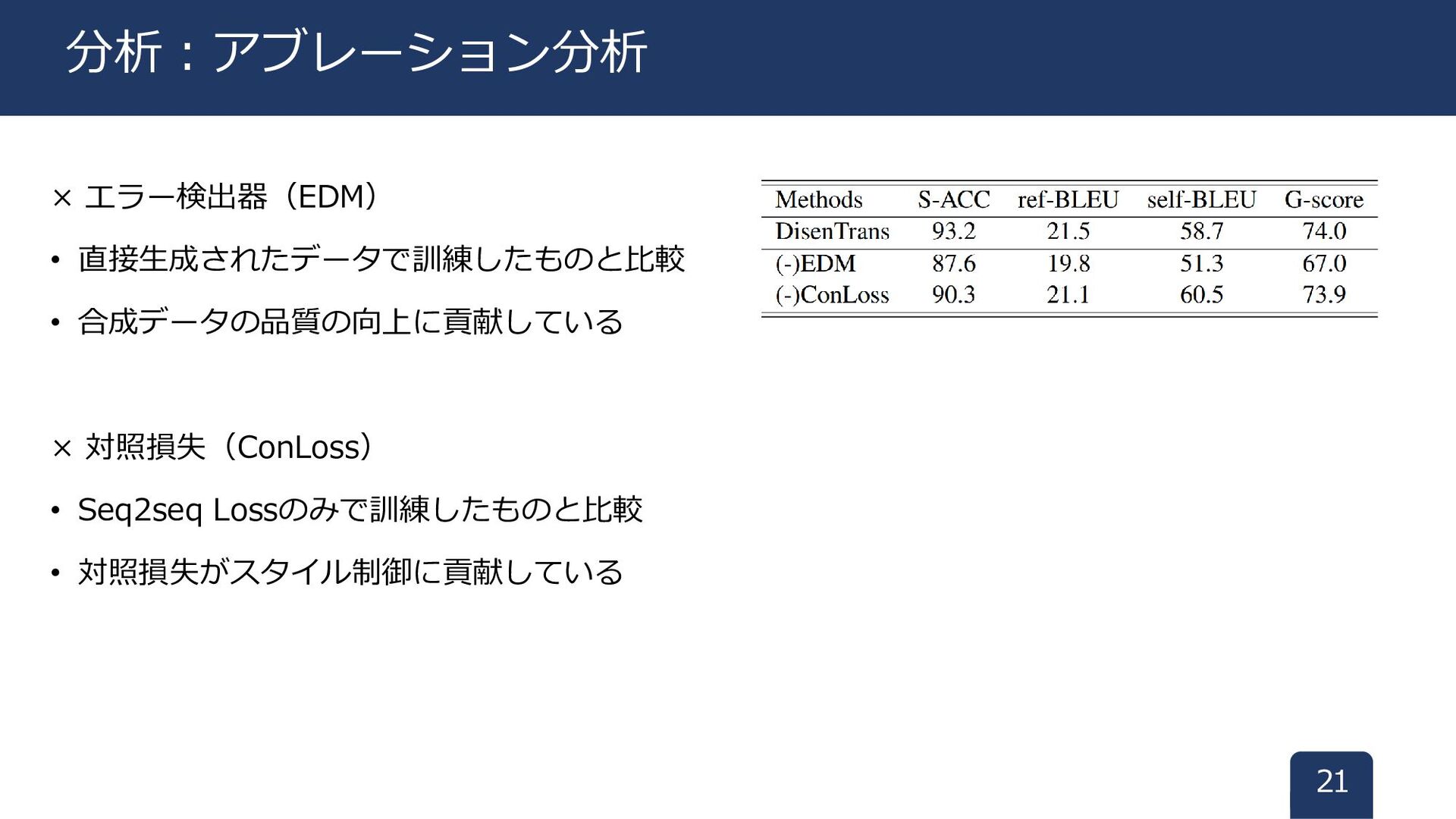
× エラー検出器(EDM) • 直接生成されたデータで訓練したものと比較 • 合成データの品質の向上に貢献している × 対照損失(ConLoss) • Seq2seq
Lossのみで訓練したものと比較 • 対照損失がスタイル制御に貢献している 21 分析:アブレーション分析
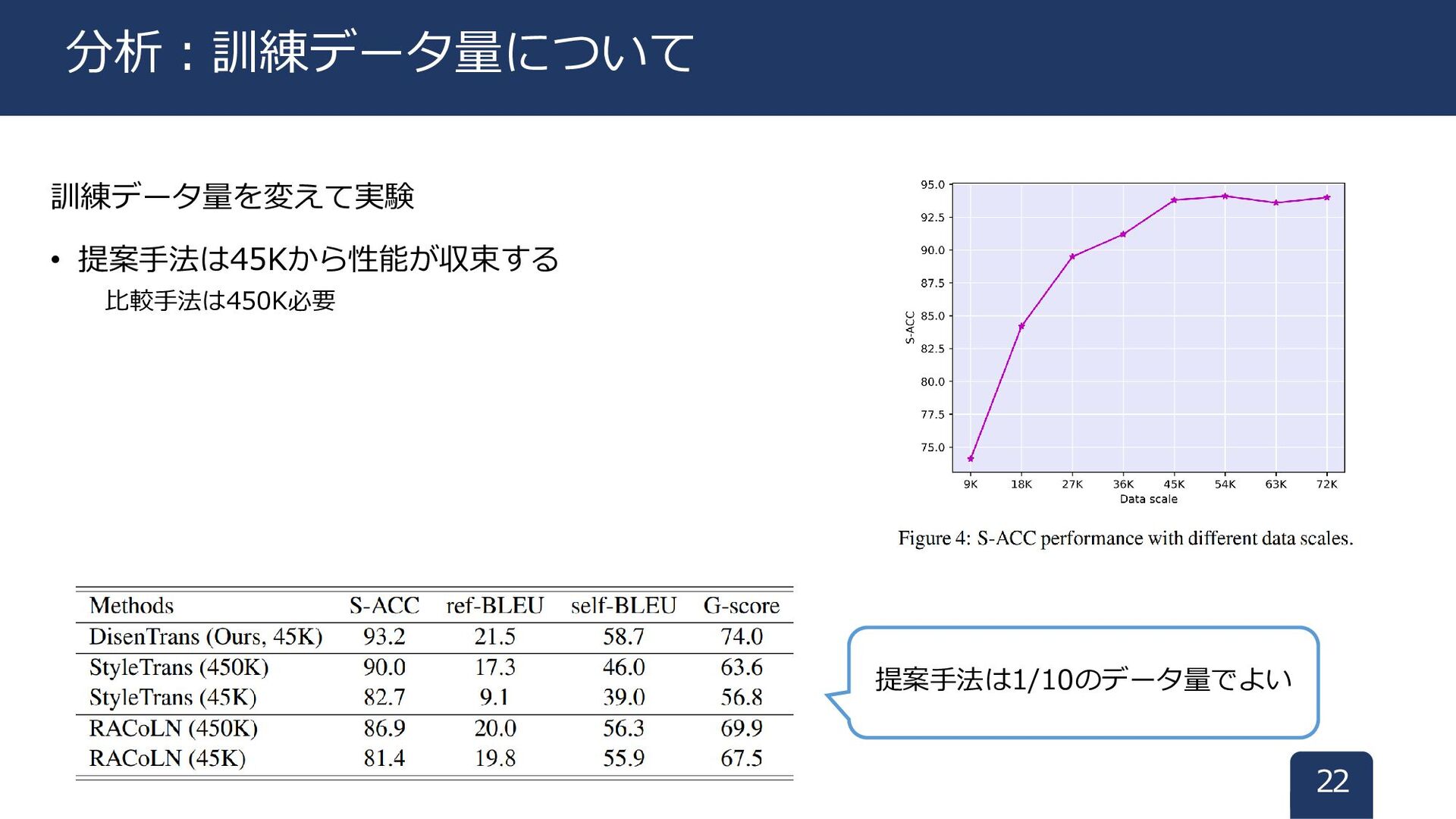
訓練データ量を変えて実験 • 提案手法は45Kから性能が収束する 比較手法は450K必要 22 分析:訓練データ量について 提案手法は1/10のデータ量でよい
教師なし文表現学習 • Yelpの評価セットでChatGPTと比較する • 直接LLMに生成するよりも、性能を向上している 23 分析:LLM vs 提案手法(DisenTrans)
分離学習手法のフレームワーク「DisenTrans」を提案した • 並列データと対応する分離された情報を合成するためのCoT手順を作成 • 合成データを用いた分離学習手法を開発 • コントラスト損失、シーケンス間損失 24 まとめ
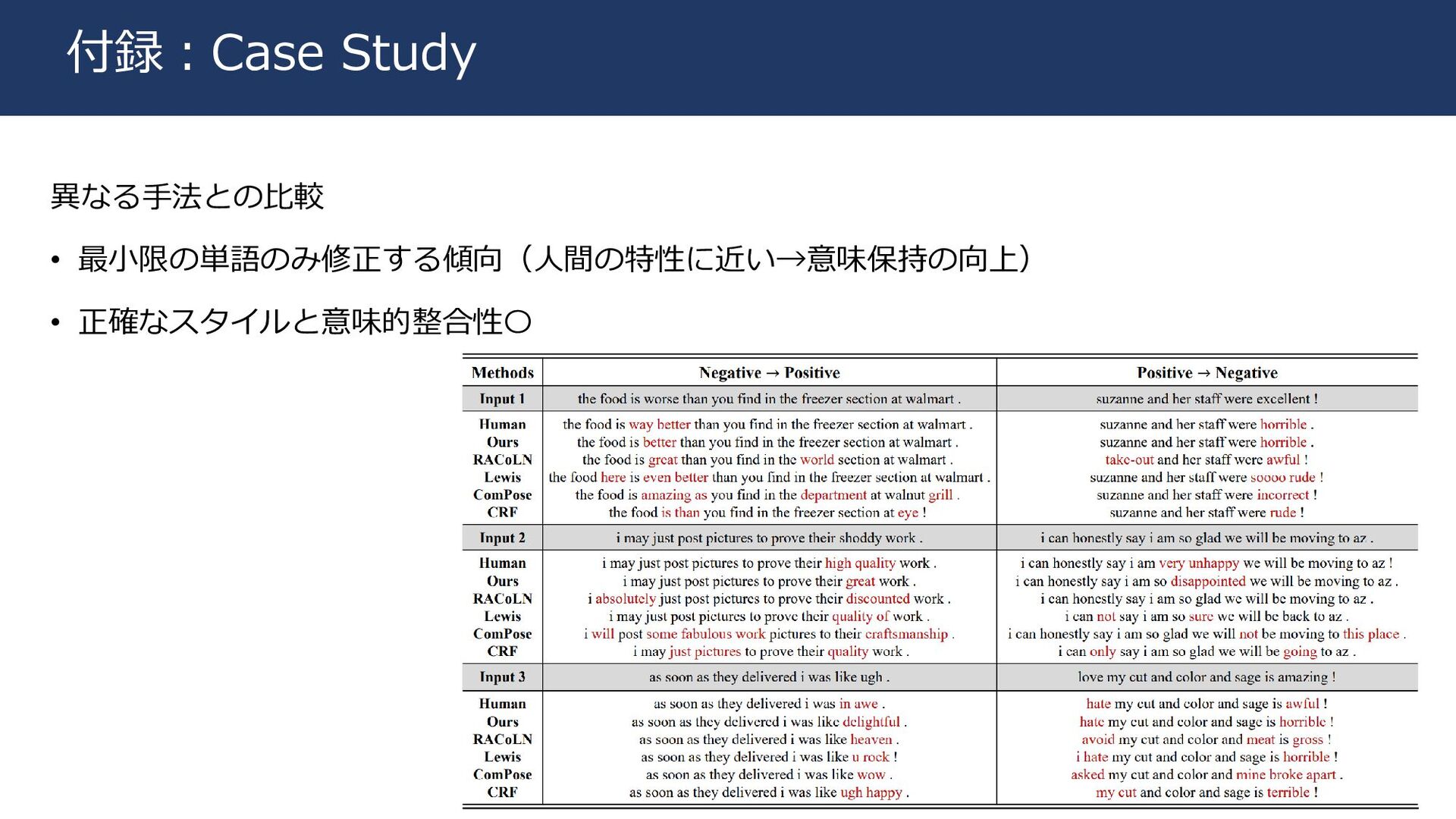
異なる手法との比較 • 最小限の単語のみ修正する傾向(人間の特性に近い→意味保持の向上) • 正確なスタイルと意味的整合性〇 25 付録:Case Study
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}