さらなる注釈データを必要とするため困難 2 導入:テキスト埋め込み [1]Muennighoff et al.:Massive Text Embedding Benchmark (EACL’23) [2]Thakur et al.;BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models(NeurlPS’21)
et al.:Multitask Prompted Training Enables Zero-Shot Task Generalization(arXiv’22) [6]Zhou et al.: Prompt Consistency for Zero-Shot Task Generalization(arXiv’22)
{kind=link}
{kind=link}
![既存のテキスト埋め込み • 新しいタスクやドメインで評価すると性能が低下する[1][2] • 例)SimCSEだと…類似性タスク〇 検索タスク△ 対処 • タスクやドメインのデータセットでさらに追加学習すること →](https://files.speakerdeck.com/presentations/f2d4da1cb1574d3687345eb8cb2945a8/slide_2.jpg){kind=link}
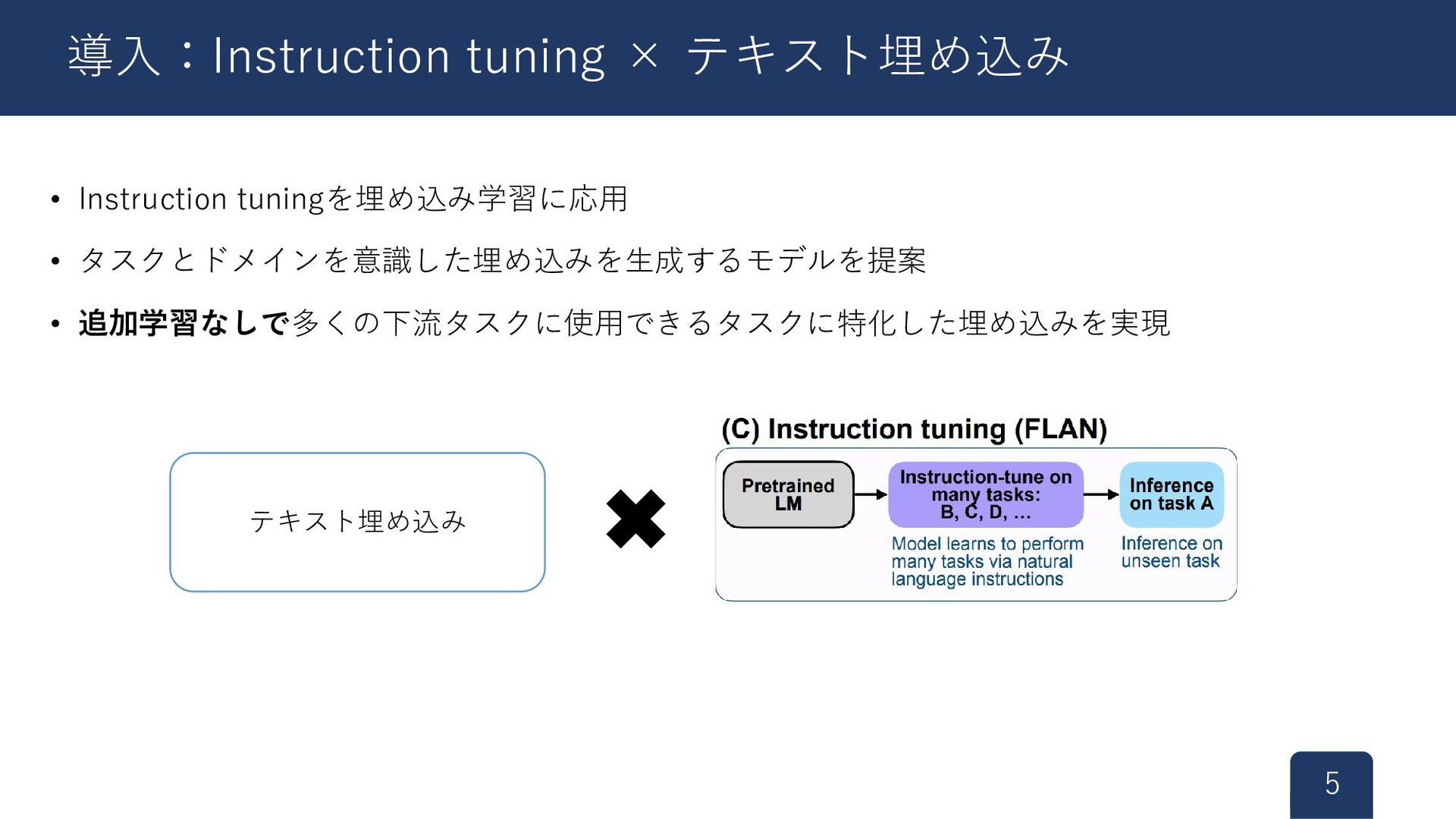
![• 命令の追加学習(Instruction tuning)[3] • タスク全般を解決できるようにする訓練形式 3 導入:Instruction tuning [3]Wei et](https://files.speakerdeck.com/presentations/f2d4da1cb1574d3687345eb8cb2945a8/slide_3.jpg){kind=link}
![• 命令の追加学習(Instruction tuning)[3] • タスク全般を解決できるようにする訓練形式 4 導入:Instruction tuning [3]Wei et](https://files.speakerdeck.com/presentations/f2d4da1cb1574d3687345eb8cb2945a8/slide_4.jpg){kind=link}
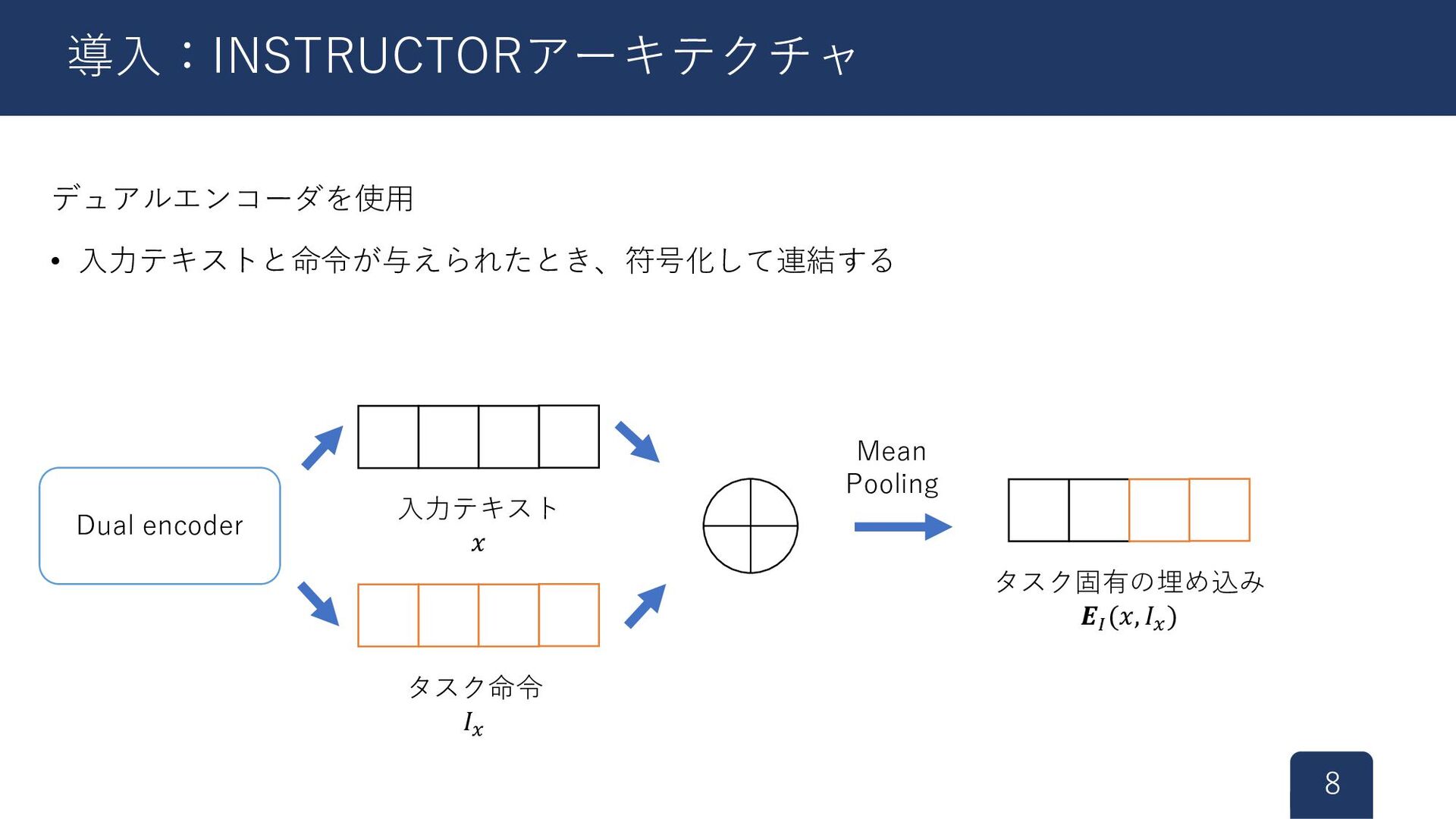
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
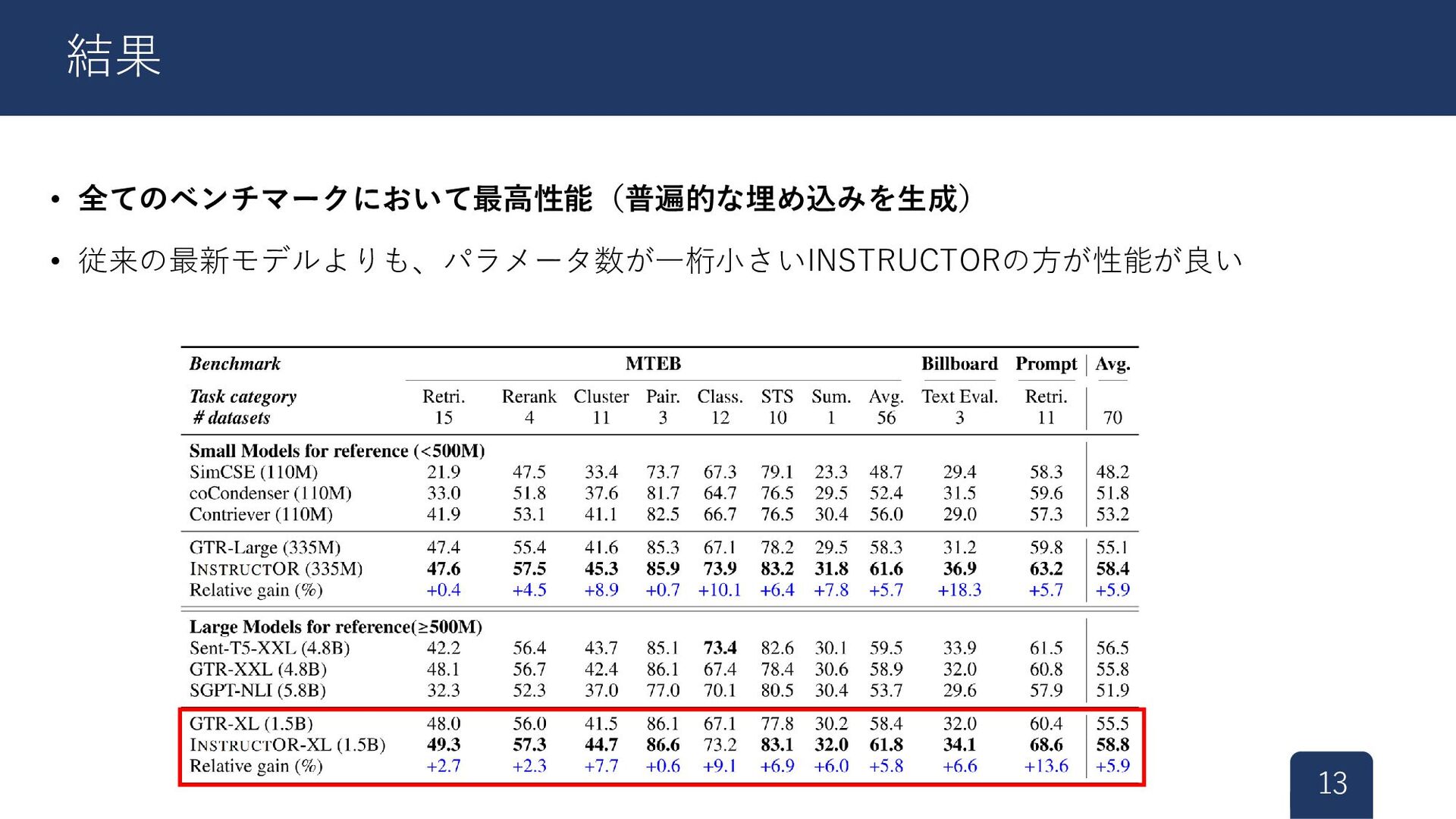{kind=link}
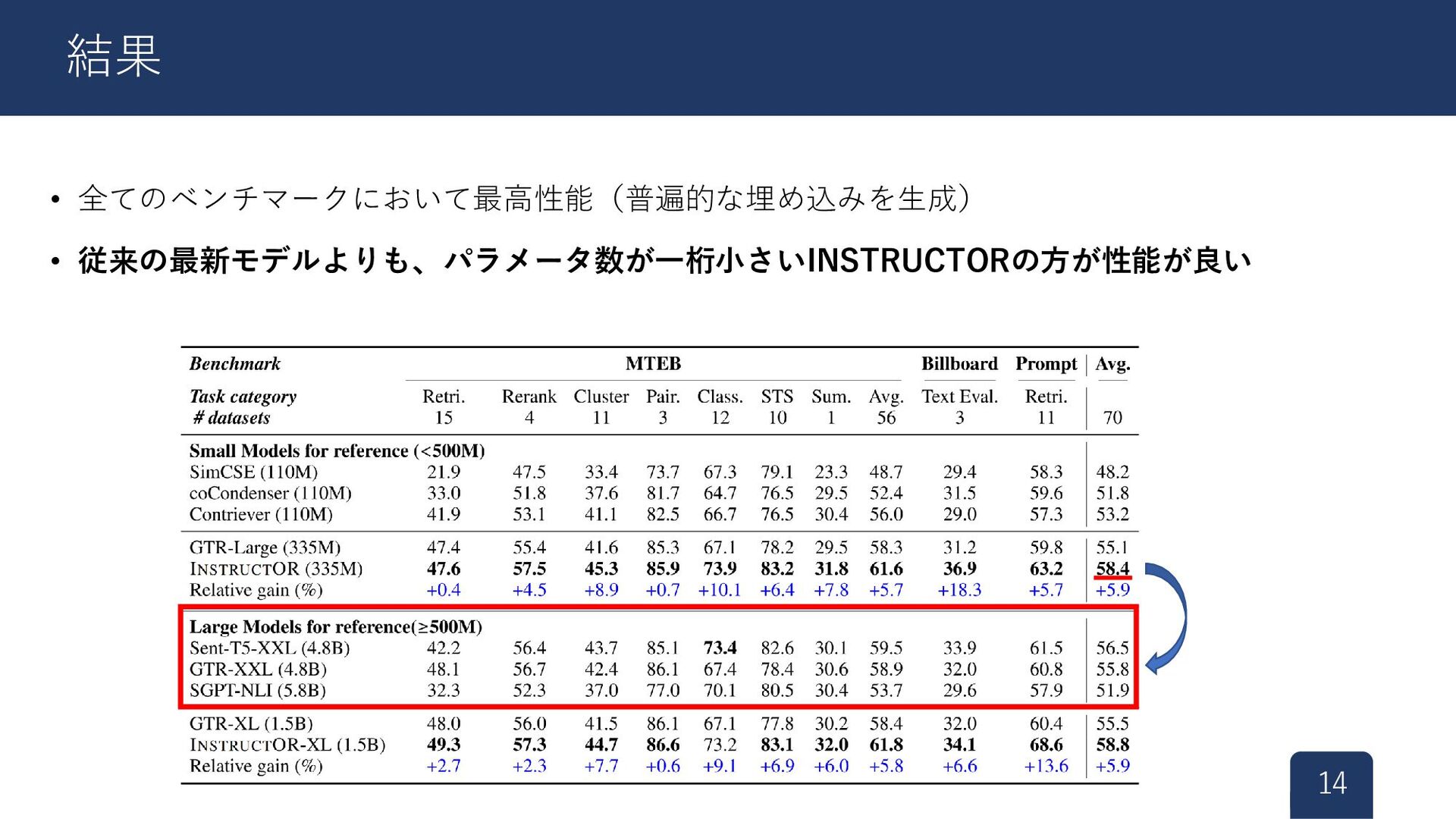{kind=link}
{kind=link}
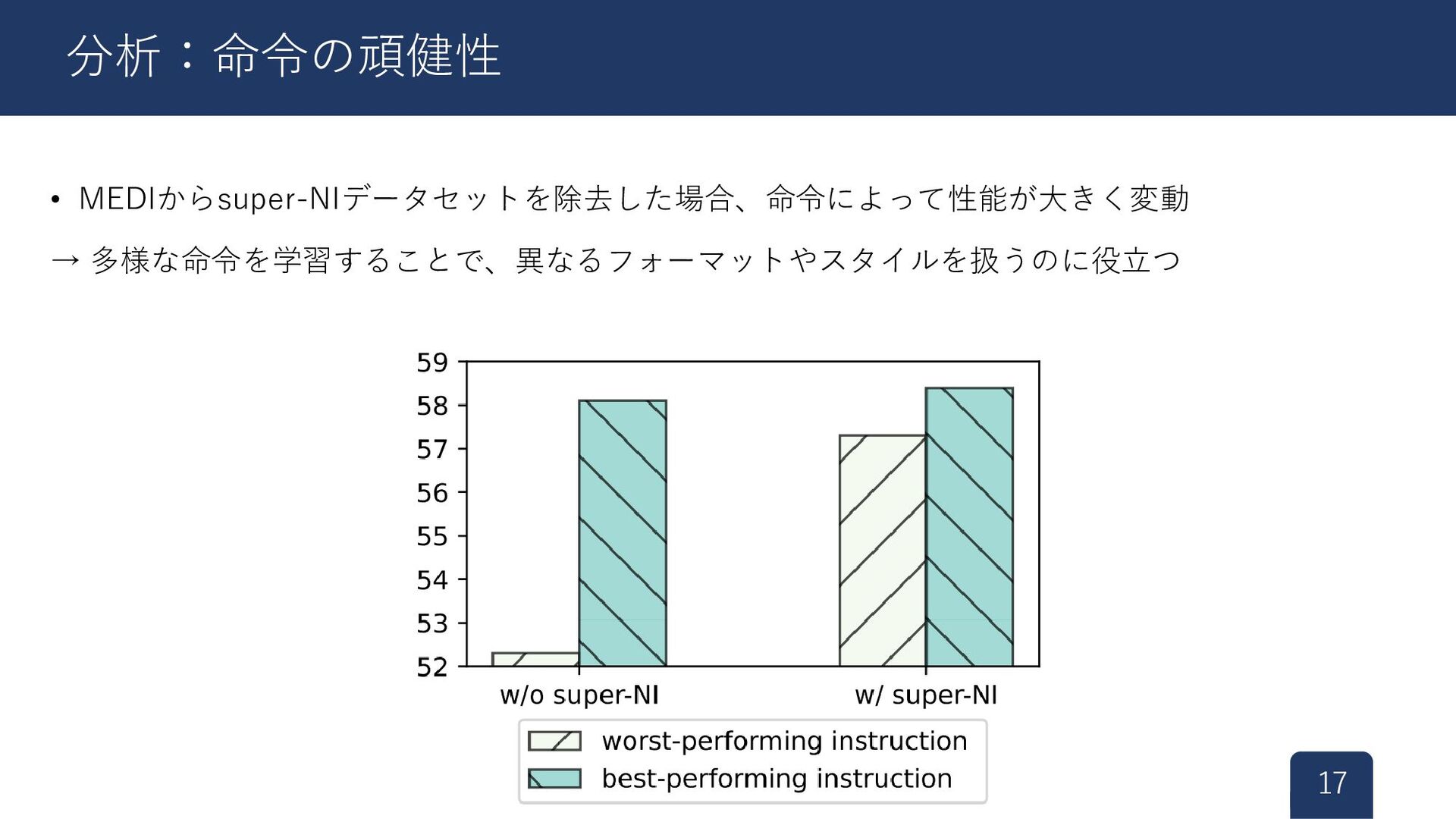
![• Instruction tuningモデルは,言い換えられた命令に対して頑健ではない[5][6] • 全ての評価セットに対して5つの言い換え命令を記述 • 最も良い命令と悪い命令の性能差をみる 16 分析:命令の頑健性 [5]Sanh](https://files.speakerdeck.com/presentations/f2d4da1cb1574d3687345eb8cb2945a8/slide_16.jpg){kind=link}
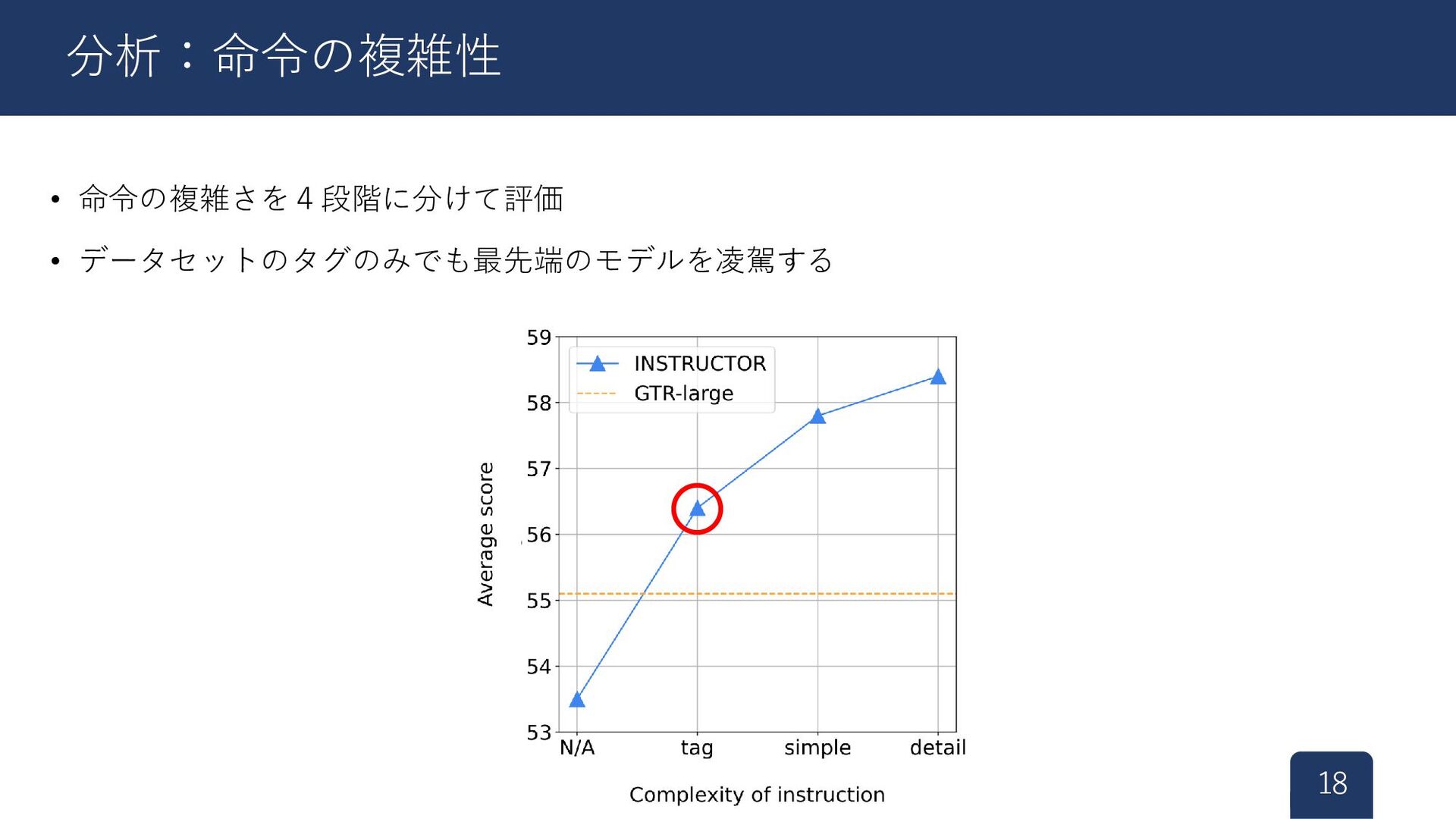
{kind=link}
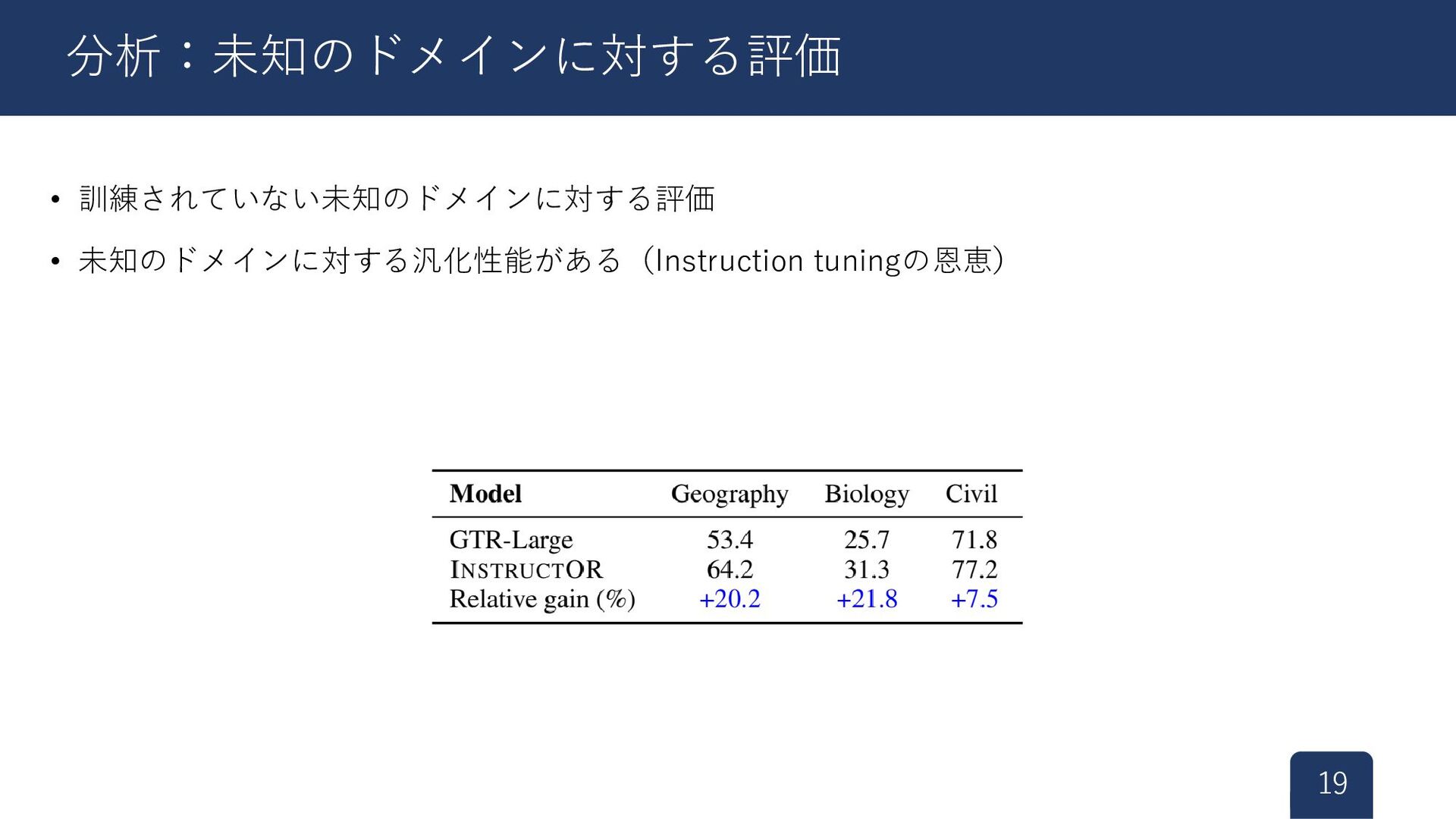
{kind=link}
{kind=link}
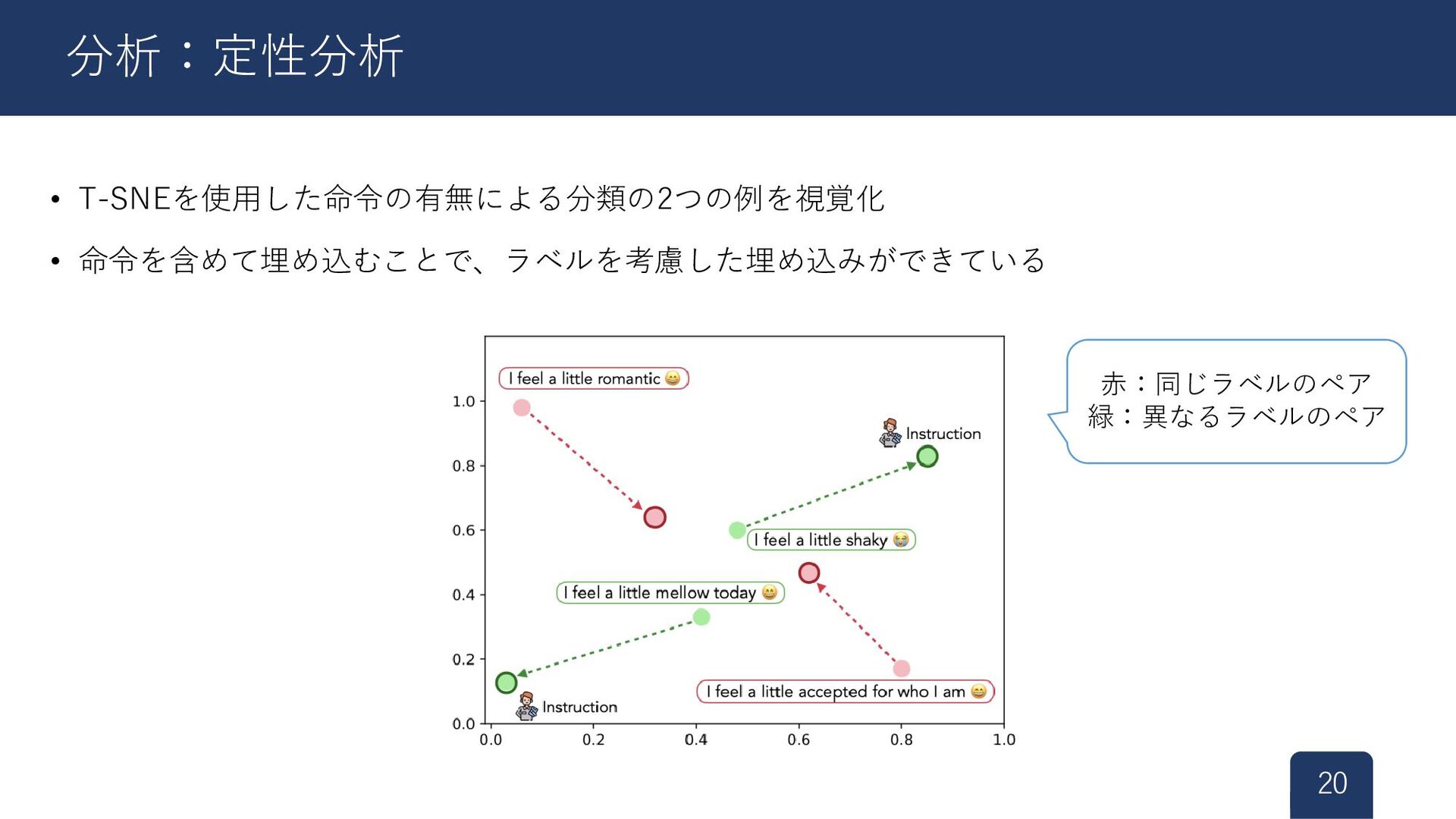{kind=link}
{kind=link}
{kind=link}
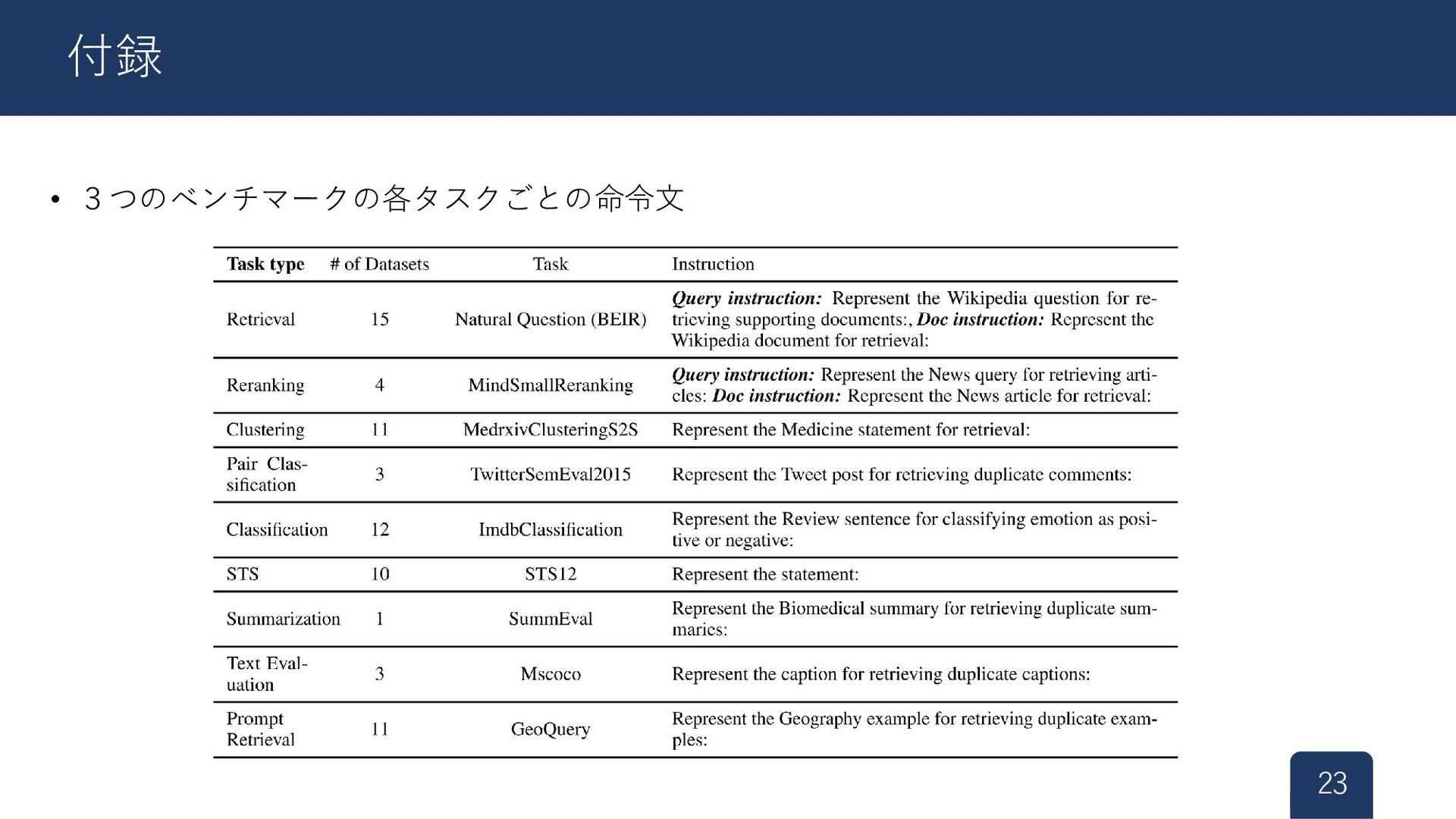{kind=link}