Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[論文解説] Large Language Models can Contrastively ...
Search
Reon Kajikawa
October 29, 2024
26
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[論文解説] Large Language Models can Contrastively Refine their Generation for Better Sentence Representation Learning
対照学習に特化した合成データを構成する3段階フレームワークMultiCSRを提案した論文
Reon Kajikawa
October 29, 2024
More Decks by Reon Kajikawa
See All by Reon Kajikawa
[論文解説] mPLUG-DocOwl2: High-resolution Compressing for OCR-free Multi-page Document Understanding
reon131
0
21
[論文解説] Not All Negatives are Equal: Label Aware Contrastive Loss for Fine grained Text Classification
reon131
0
25
[論文解説] Disentangled Learning with Synthetic Parallel Data for Text Style Transfer
reon131
0
19
[論文解説] SentiCSE: A Sentiment-aware Contrastive Sentence Embedding Framework with Sentiment-guided Textual Similarity
reon131
0
39
[論文解説] Text Embeddings Reveal (Almost) As Much As Text
reon131
0
150
[論文解説] OssCSE: Overcoming Surface Structure Bias in Contrastive Learning for Unsupervised Sentence Embedding
reon131
0
18
[論文解説] Sentence Representations via Gaussian Embedding
reon131
0
130
[論文解説] Unsupervised Learning of Style-sensitive Word Vectors
reon131
0
31
[論文解説] One Embedder, Any Task: Instruction-Finetuned Text Embeddings
reon131
0
53
Featured
See All Featured
Designing for humans not robots
tammielis
254
26k
Discover your Explorer Soul
emna__ayadi
2
1.2k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Statistics for Hackers
jakevdp
799
230k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.5k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
Transcript
Large Language Models can Contrastively Refine their Generation for Better
Sentence Representation Learning Huiming Wang, Zhaodonghui Li, Liying Cheng, De Wen Soh, Lidong Bing NAACL 2024 URL:https://aclanthology.org/2024.naacl-long.436/ 発表者:M1 梶川 怜恩
文埋め込み • LLMによる生成文で文埋め込み対照学習する話 • 品質の良い学習データにする3段階のプロセス(MultiCSR)を提案 • 文生成、文ペアの構築、バッチ内学習 評価実験の結果 • 既存の対照学習フレームワークよりも性能が高い
1 概要
文埋め込み • 対照学習ベースの手法が主流になりつつある • 実装がシンプルかつ効果的 • 文ペアの品質に大きく左右される [1] • 大量かつ高品質な文ペアを取得するコスト高
LLMの登場 • NLPタスクで優れた性能を発揮している → 文表現学習にLLMを活用しようとする動きが 2 背景:文埋め込みとLLMの登場 [1] Generate, Discriminate and Contrast: A Semi-Supervised Sentence Representation Learning Framework(EMNLP’22)
LLMs as generators [2] • NLIの前提文に対して仮説文(含意、矛盾)を生成 → NLI(合成)データで対照学習する LLMs as
annotators [3] • 文ペアに対して意味的類似度スコアを注釈 → そのスコアを模倣するように学習する 3 背景:文表現にLLMを活用する先行研究がある GPT 前提文 含意文 矛盾文 0.28 Similarity score GPT 文1, 2 [2] Improving Contrastive Learning of Sentence Embeddings from AI Feedback(ACL’23) [3] Contrastive Learning of Sentence Embeddings from Scratch (EMNLP’23)
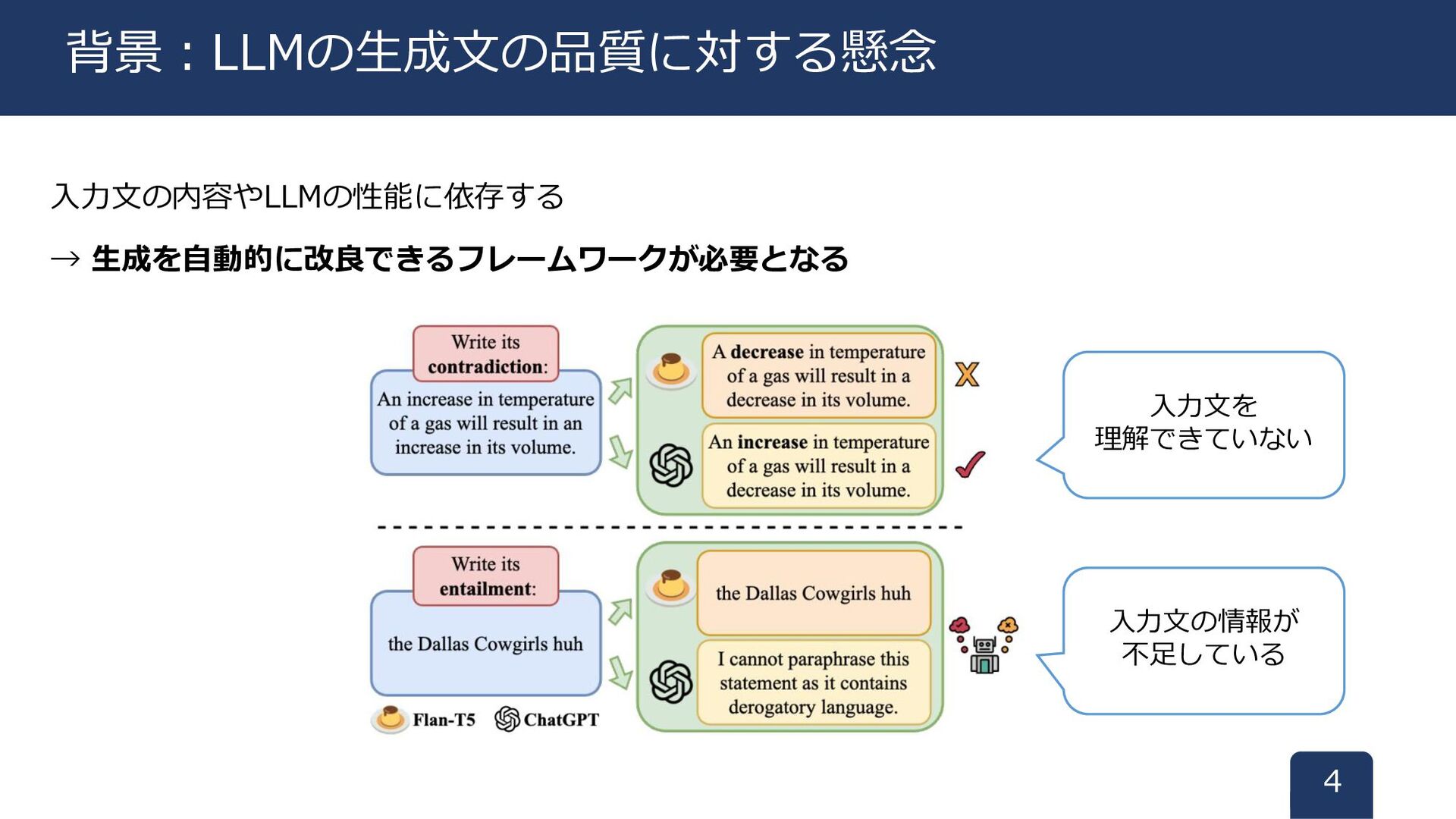
入力文の内容やLLMの性能に依存する → 生成を自動的に改良できるフレームワークが必要となる 4 背景:LLMの生成文の品質に対する懸念 入力文を 理解できていない 入力文の情報が 不足している
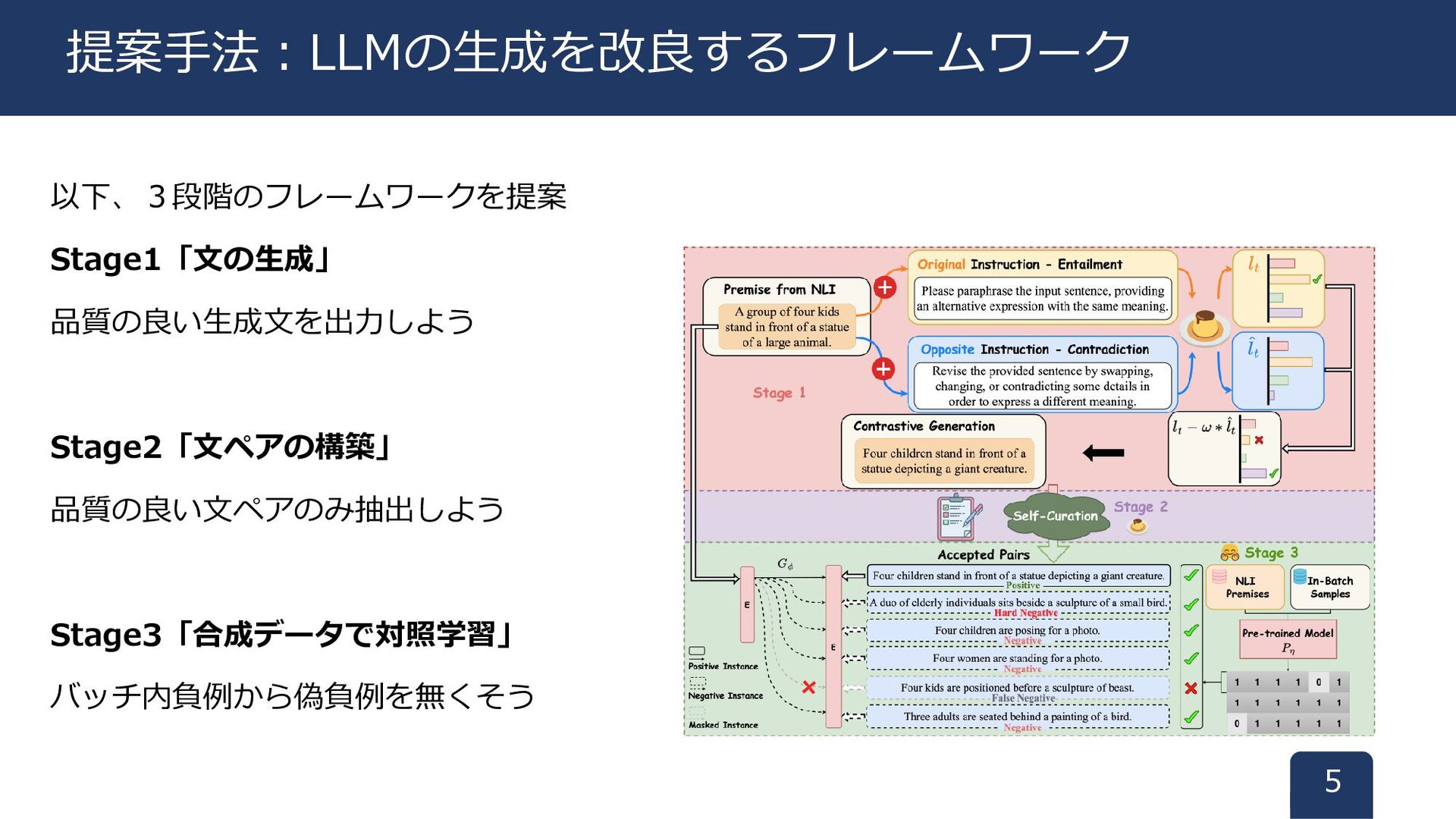
以下、3段階のフレームワークを提案 Stage1「文の生成」 品質の良い生成文を出力しよう Stage2「文ペアの構築」 品質の良い文ペアのみ抽出しよう Stage3「合成データで対照学習」 バッチ内負例から偽負例を無くそう 5 提案手法:LLMの生成を改良するフレームワーク
提案手法 6
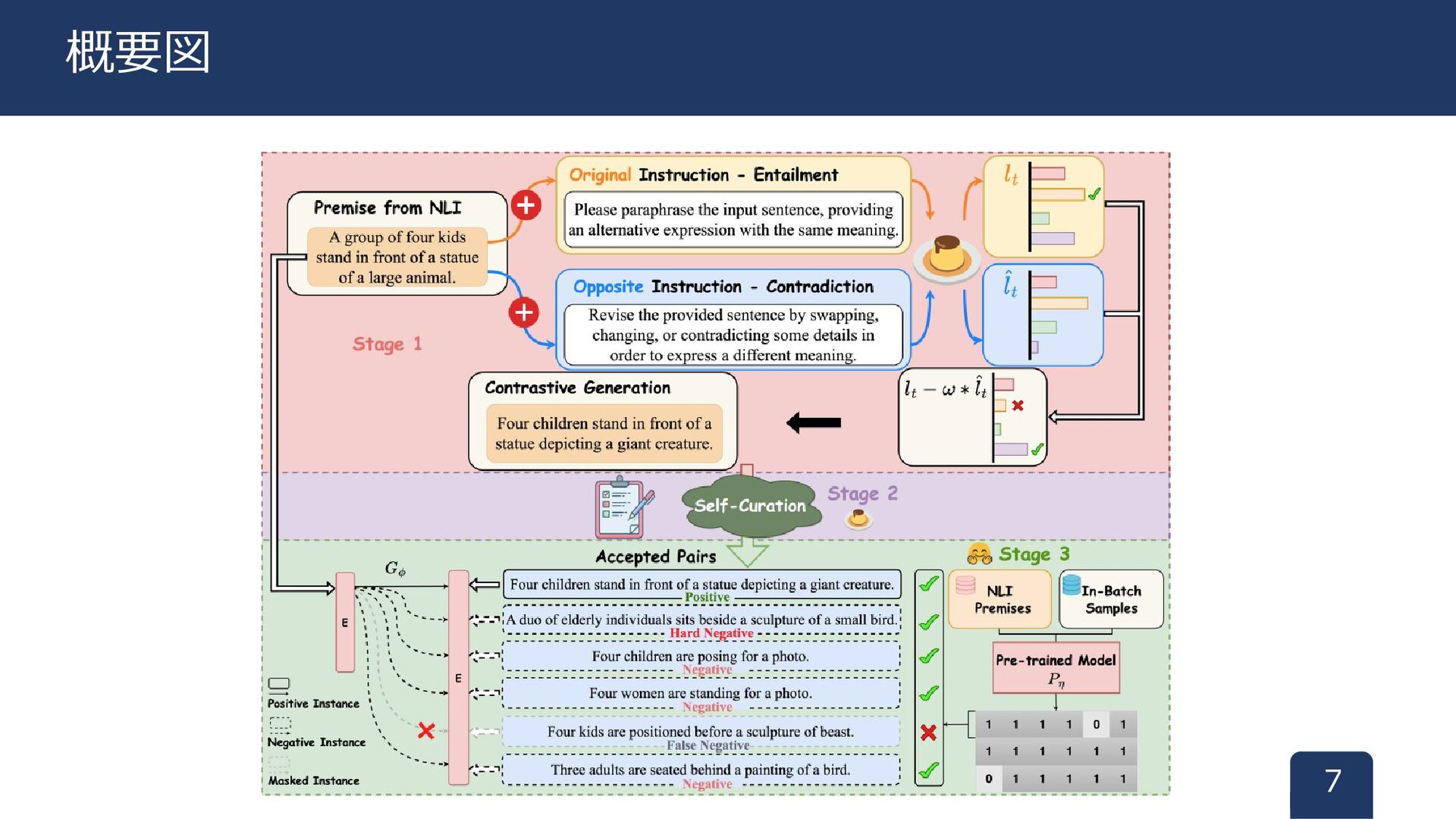
7 概要図
• Input: 命令𝐼、入力文𝑥 • Output: 入力文に対する仮説文(含意、矛盾) 出力文𝑦の確率𝑝𝜃 は以下の通り ロジット𝑙𝑡 は以下の通り
8 Stage1: 文の生成 softmaxをロジット𝐼𝑡 に適用して得られた 次のトークン𝑦𝑡 の正規化確率
品質の良い生成文を出力する手法 元の命令𝑰 とノイズ命令 𝑰とのロジットを比較 [4] → どの部分が本来の意図とずれたかを検出できる → より洗練された生成を実現 9
Stage1: 文の生成(対比生成) ノイズの命令መ 𝐼として 矛盾文を生成する命令を採用 最終的なロジット(= 𝑙𝑡 − 𝜔 ∗ መ 𝑙𝑡 ) の確率分布からサンプリング [4] INSTRUCTIVE DECODING: INSTRUCTION-TUNED LARGE LANGUAGE MODELS ARE SELF-REFINER FROM NOISY INSTRUCTIONS(ICLR’24)
文ペアの関係は不確実のままである • 対照学習では、空間内の文ペア間の距離がモデルを訓練するのに適しているか • 要は正例と負例に相応しいかどうか 文ペアを自己選別(Self-Curation) • 3つ組に対して、意味的類似度をLLMで注釈する • 閾値を設けてフィルタリング
10 Stage2: 文ペアの構築(with Self-Curation)
文ペアの関係が成立した状態 • LLMで作成したデータを用いて、対照学習を行う バッチ内負例の問題 • 偽負例が含まれる可能性がある • 負例は意味的に遠いものでなければならない 11 Stage3:
合成データで対照学習
偽負例をマスクする バッチ内負例(𝑥, 𝑥𝑘)に対して以下の式 → 損失に対してマスキングする 12 Stage3: 合成データで対照学習(偽陰性をマスク) 事前訓練済みモデルの 埋め込み同士のcos
sim
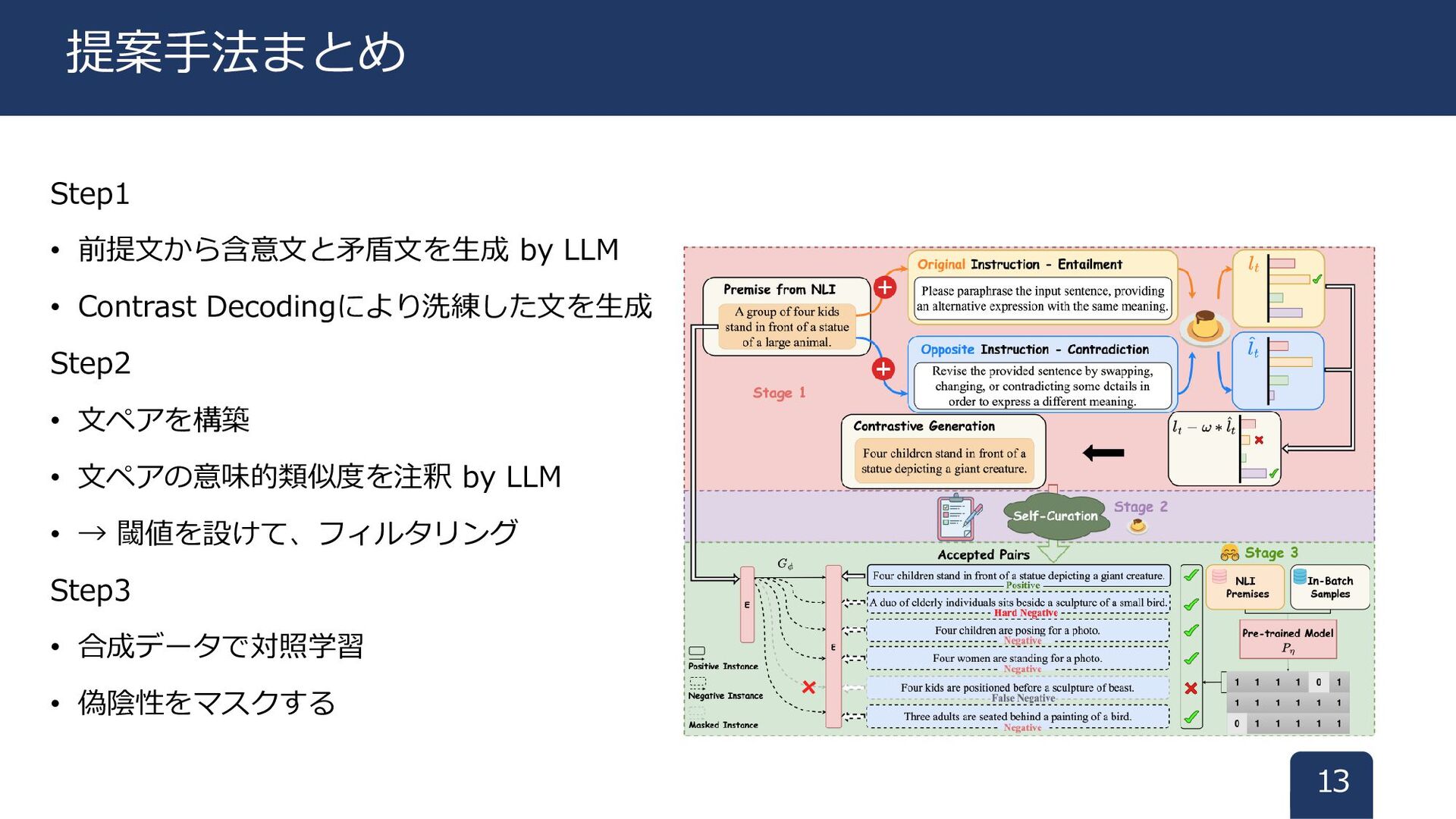
Step1 • 前提文から含意文と矛盾文を生成 by LLM • Contrast Decodingにより洗練した文を生成 Step2 •
文ペアを構築 • 文ペアの意味的類似度を注釈 by LLM • → 閾値を設けて、フィルタリング Step3 • 合成データで対照学習 • 偽陰性をマスクする 13 提案手法まとめ
評価実験 14
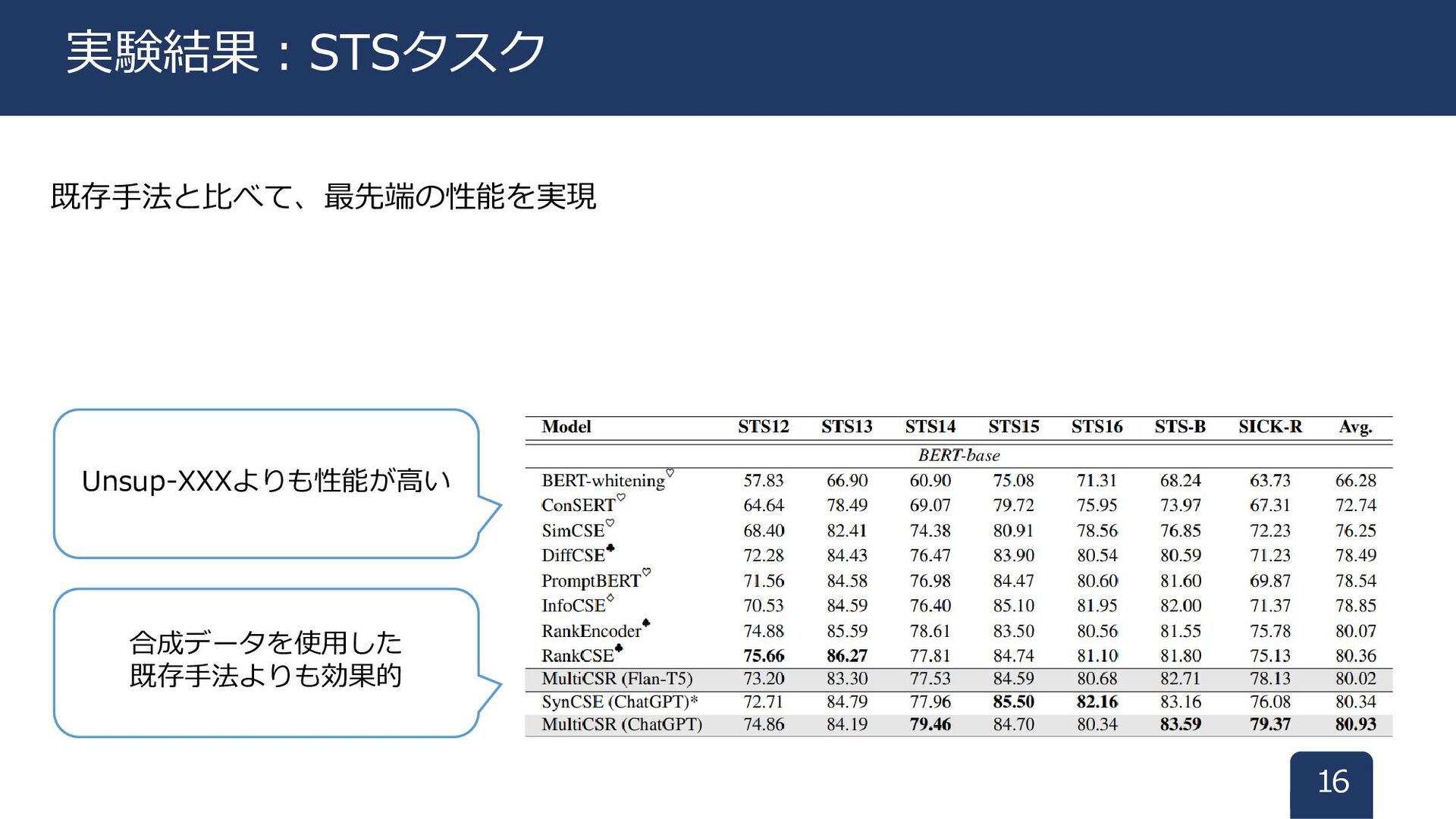
評価データセット • SentEval(STSタスクと転移タスク) • BEIR(ゼロショット情報検索タスク)← 省略します 学習データ • NLIデータの前提文+LLM(仮説文(含意と矛盾)) LLM
• Flan-T5-XL(3B), ChatGPT (gpt-3.5-turbo) 比較手法 • 教師なし対照学習モデル(SimCSEなど) • 同じく合成データを使用したSynCSE [5] 15 実験設定 対照学習フレームワークとして SimCSEを採用
既存手法と比べて、最先端の性能を実現 16 実験結果:STSタスク 合成データを使用した 既存手法よりも効果的 Unsup-XXXよりも性能が高い
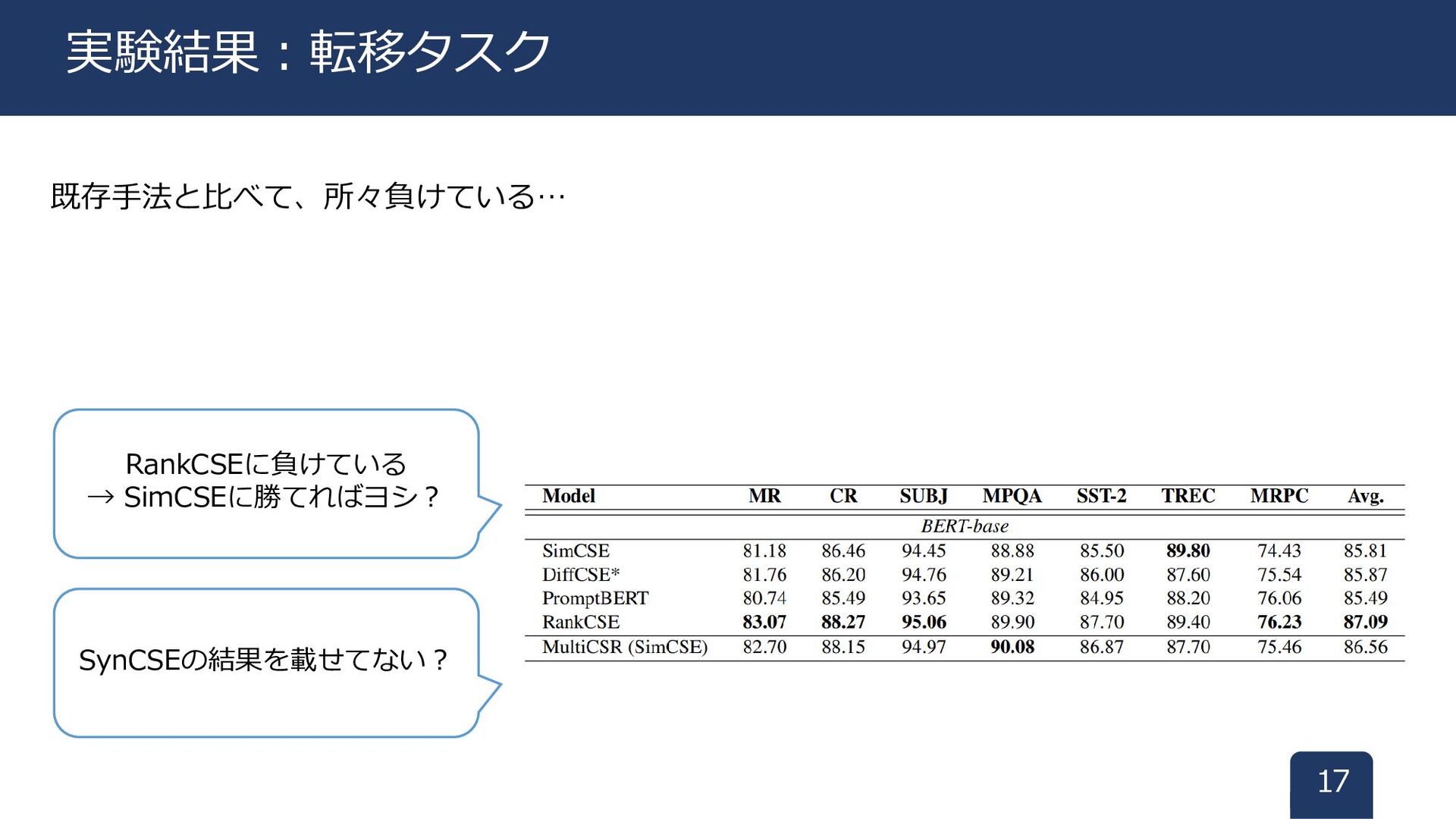
既存手法と比べて、所々負けている… 17 実験結果:転移タスク SynCSEの結果を載せてない? RankCSEに負けている → SimCSEに勝てればヨシ?
分析 18
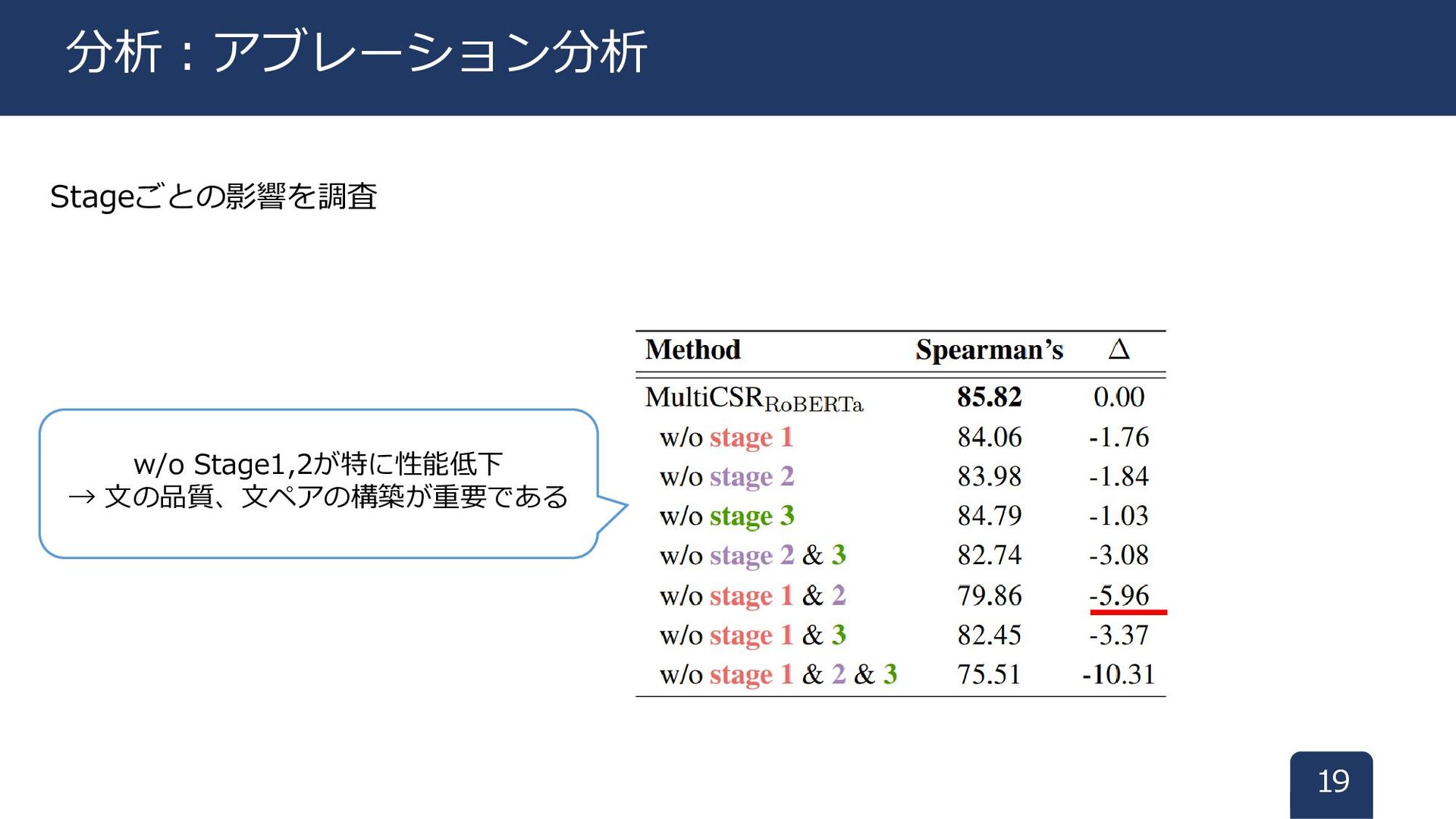
Stageごとの影響を調査 19 分析:アブレーション分析 w/o Stage1,2が特に性能低下 → 文の品質、文ペアの構築が重要である
• ラベルなしの文としてNLIの前提文を使用していた • NLIデータは高品質(語彙の重複が少ない) • ノイズの多い文に対しても有効性があるのか? • Wikipediaから10^6文を無作為抽出 STS 検証セットで評価
• SimCSEでは、NLI < Wikipedia • 質より量 • MultiCSRでは、 NLI > Wikipedia • Wikipediaの方が長いかつ生成するのに言語理解能力が必要 → Wikipediaの文では、含意、矛盾文を生成するのが難しい 20 分析:異なるデータで学習したとき
文埋め込み • LLMによる生成文で文埋め込み対照学習する話 • 品質の良い学習データにする3段階のプロセス(MultiCSR)を提案 • 文生成、文ペアの構築、バッチ内学習 Limitation • Stage1より、ロジットの獲得
→ Closed なLLMだとロジットを取得できない • Stage2より、自己選別 • ハードな選別(ルールベース)でフィルタリング • ソフトな(?)選別を提案したい 21 まとめ
{kind=link}
{kind=link}
![文埋め込み • 対照学習ベースの手法が主流になりつつある • 実装がシンプルかつ効果的 • 文ペアの品質に大きく左右される [1] • 大量かつ高品質な文ペアを取得するコスト高](https://files.speakerdeck.com/presentations/fb4ba4af38954964a10c3e443d5f8dc9/slide_2.jpg){kind=link}
![LLMs as generators [2] • NLIの前提文に対して仮説文(含意、矛盾)を生成 → NLI(合成)データで対照学習する LLMs as](https://files.speakerdeck.com/presentations/fb4ba4af38954964a10c3e443d5f8dc9/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![品質の良い生成文を出力する手法 元の命令𝑰 とノイズ命令 𝑰とのロジットを比較 [4] → どの部分が本来の意図とずれたかを検出できる → より洗練された生成を実現 9](https://files.speakerdeck.com/presentations/fb4ba4af38954964a10c3e443d5f8dc9/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}