Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[論文解説] OssCSE: Overcoming Surface Structure Bia...
Search
Reon Kajikawa
April 24, 2024
18
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[論文解説] OssCSE: Overcoming Surface Structure Bias in Contrastive Learning for Unsupervised Sentence Embedding
表層構造におけるバイアスを対処するOssCSEを提案
Reon Kajikawa
April 24, 2024
More Decks by Reon Kajikawa
See All by Reon Kajikawa
[論文解説] mPLUG-DocOwl2: High-resolution Compressing for OCR-free Multi-page Document Understanding
reon131
0
21
[論文解説] Not All Negatives are Equal: Label Aware Contrastive Loss for Fine grained Text Classification
reon131
0
25
[論文解説] Disentangled Learning with Synthetic Parallel Data for Text Style Transfer
reon131
0
19
[論文解説] Large Language Models can Contrastively Refine their Generation for Better Sentence Representation Learning
reon131
0
26
[論文解説] SentiCSE: A Sentiment-aware Contrastive Sentence Embedding Framework with Sentiment-guided Textual Similarity
reon131
0
39
[論文解説] Text Embeddings Reveal (Almost) As Much As Text
reon131
0
150
[論文解説] Sentence Representations via Gaussian Embedding
reon131
0
130
[論文解説] Unsupervised Learning of Style-sensitive Word Vectors
reon131
0
31
[論文解説] One Embedder, Any Task: Instruction-Finetuned Text Embeddings
reon131
0
53
Featured
See All Featured
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
What's in a price? How to price your products and services
michaelherold
247
13k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
The Cult of Friendly URLs
andyhume
79
6.9k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Raft: Consensus for Rubyists
vanstee
141
7.6k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Become a Pro
speakerdeck
PRO
31
6k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
640
Transcript
OssCSE: Overcoming Surface Structure Bias in Contrastive Learning for Unsupervised
Sentence Embedding Zhan Shi, Guoyin Wang, Ke Bai, Jiwei Li, Xiang Li, Qingjun Cui, Belinda Zeng, Trishul Chilimbi, Xiaodan Zhu EMNLP 2023 URL:https://aclanthology.org/2023.emnlp-main.448/ 発表者:M1 梶川 怜恩
対照学習による教師なし文埋め込み • 表層のバイアス:類似した表層を持つ文は意味的に近いものになる • 言い換え文との類似度 < 否定文との類似度 本論文 • バイアスの検証
• バイアスを考慮した文埋め込み学習 1 概要
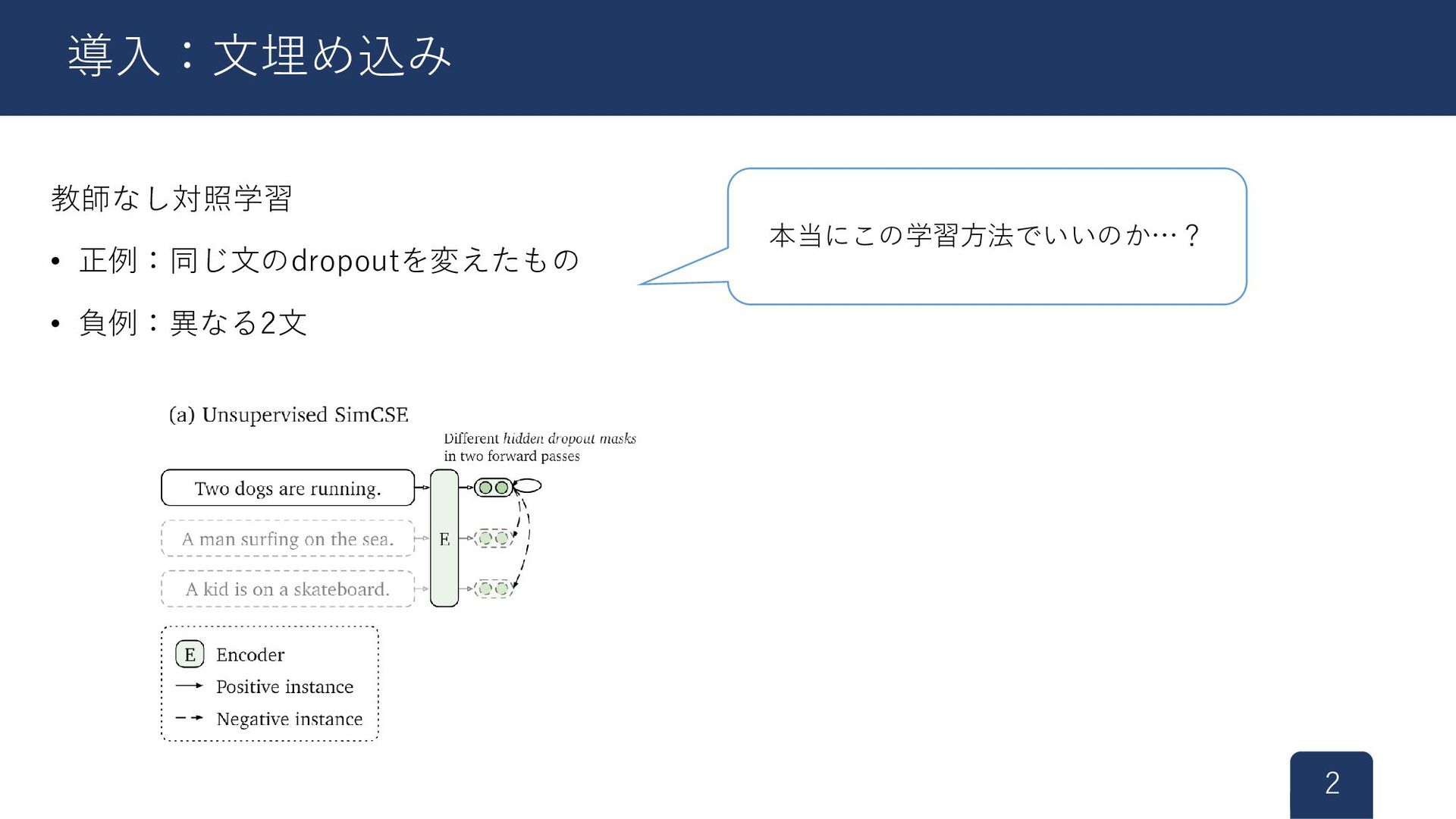
教師なし対照学習 • 正例:同じ文のdropoutを変えたもの • 負例:異なる2文 2 導入:文埋め込み 本当にこの学習方法でいいのか…?
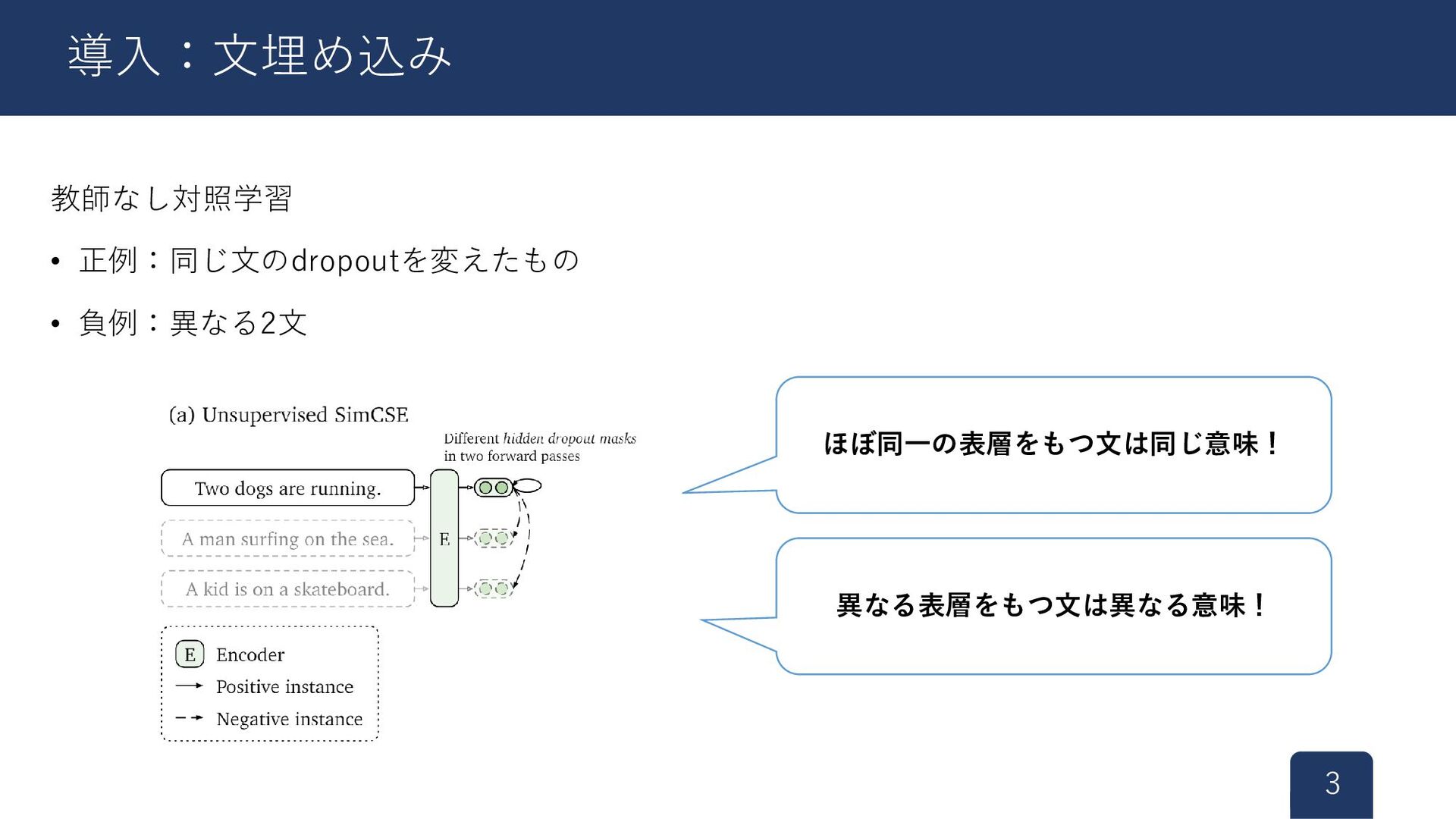
教師なし対照学習 • 正例:同じ文のdropoutを変えたもの • 負例:異なる2文 3 導入:文埋め込み ほぼ同一の表層をもつ文は同じ意味! 異なる表層をもつ文は異なる意味!
文の構造 • 深層構造:文の意味 • 表層構造:文の見た目 4 導入:文の構造 I purchased some
beautiful clothes Some beautiful clothes were bought by me I didn’t purchase some beautiful clothes 見た目は違うが、意味は似ている (言い換え文が該当) 見た目は似ているが、意味は異なる (否定文が該当)
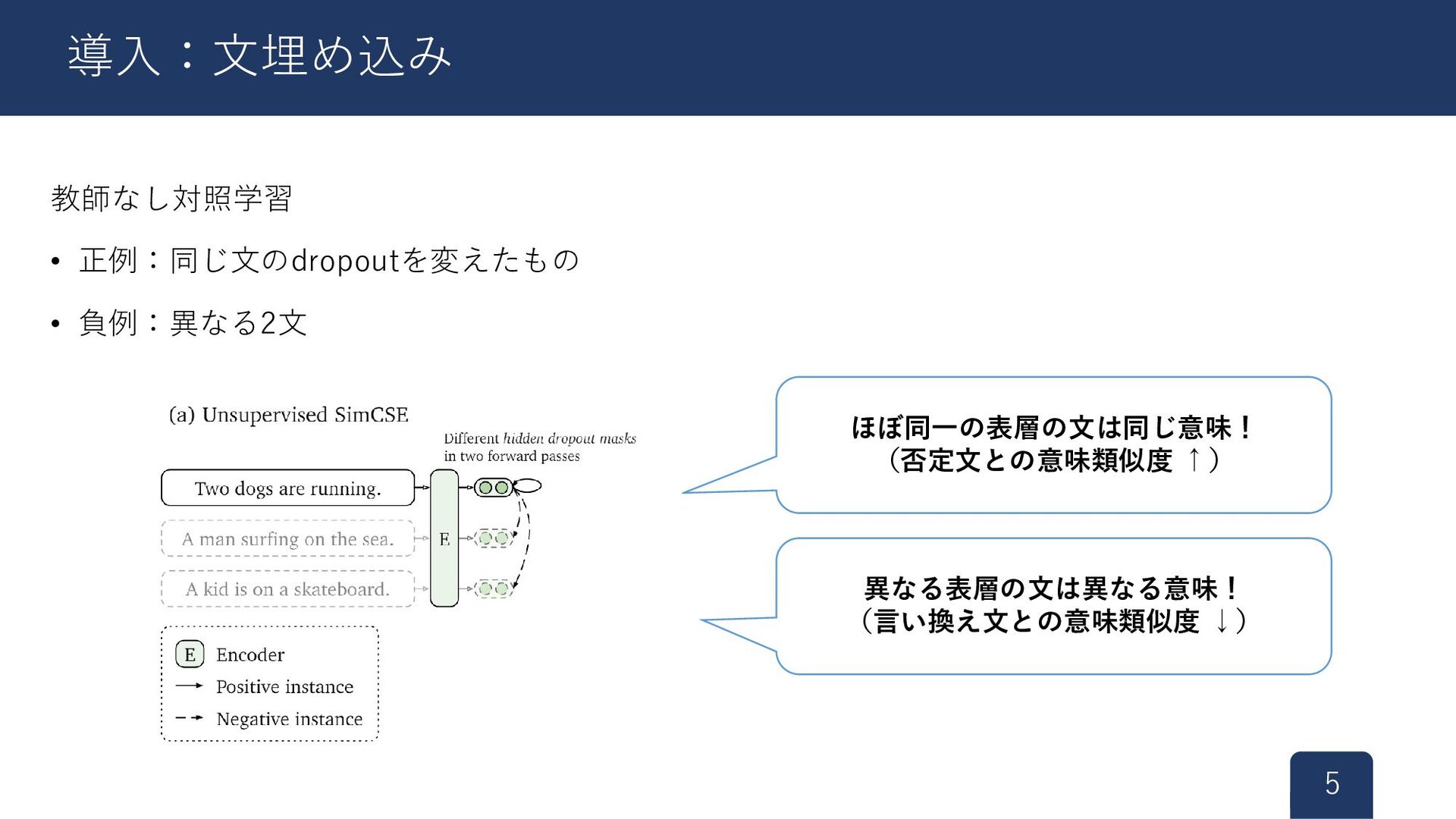
教師なし対照学習 • 正例:同じ文のdropoutを変えたもの • 負例:異なる2文 5 導入:文埋め込み ほぼ同一の表層の文は同じ意味! (否定文との意味類似度 ↑)
異なる表層の文は異なる意味! (言い換え文との意味類似度 ↓)
本研究の疑問点 • モデルはどの程度バイアスの影響を受けている? • バイアスを対処してモデルの性能を向上させるには? 6 導入:表層構造のバイアス
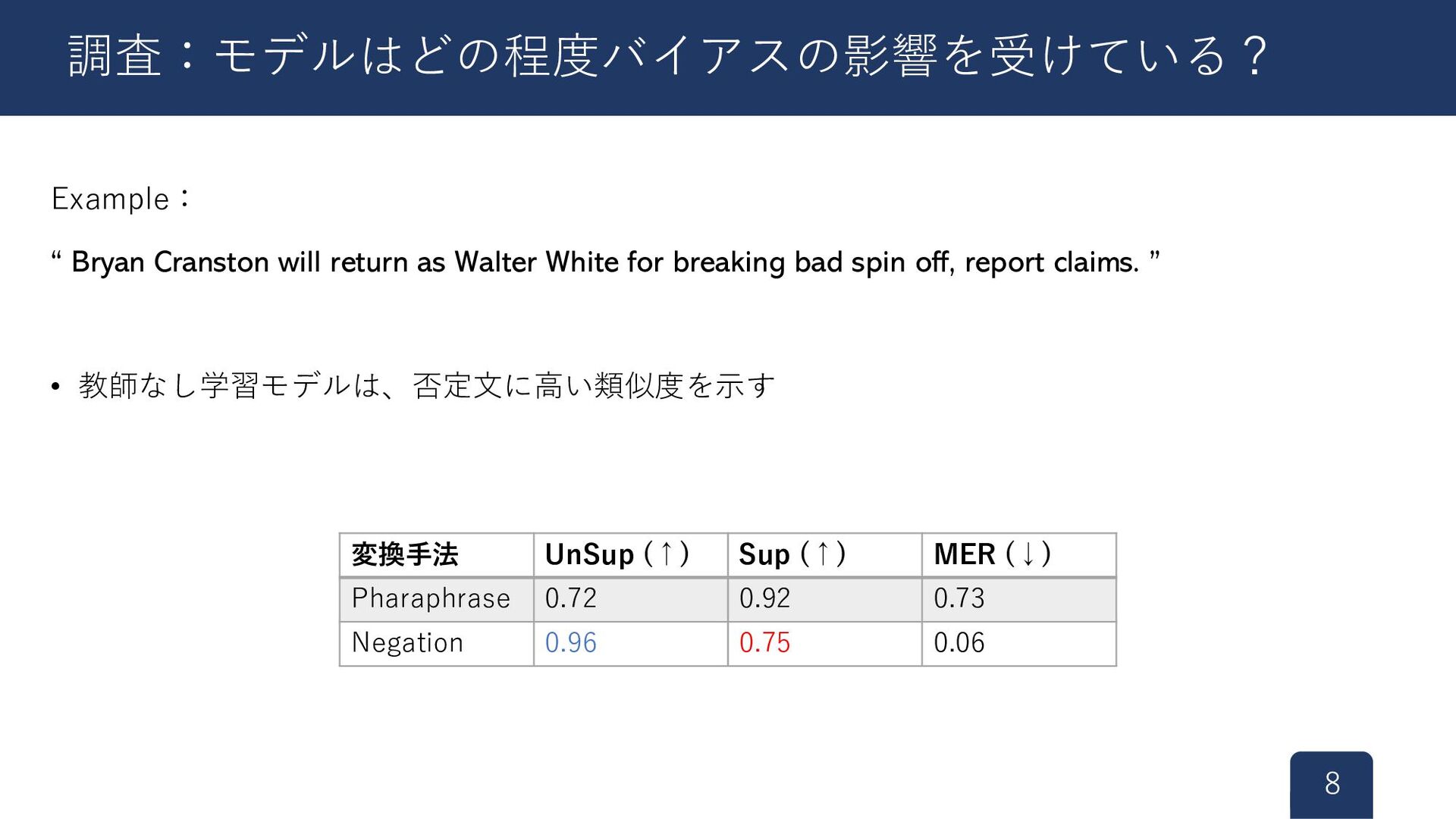
SimCSEの教師あり・なしモデルで検証 1. 文に対して変換を行う • 言い換え、否定(+置換、削除、挿入、ランダム) 2. 変換した文に対して、元の文との類似度を計算 • 意味的な類似度:コサイン類似度 ↑
• 表層的な類似度:MER ↓(削除、置換、挿入された単語の割合) 7 調査:モデルはどの程度バイアスの影響を受けている?
Example: “ Bryan Cranston will return as Walter White for
breaking bad spin off, report claims. ” • 教師なし学習モデルは、否定文に高い類似度を示す 8 調査:モデルはどの程度バイアスの影響を受けている? 変換手法 UnSup (↑) Sup (↑) MER (↓) Pharaphrase 0.72 0.92 0.73 Negation 0.96 0.75 0.06
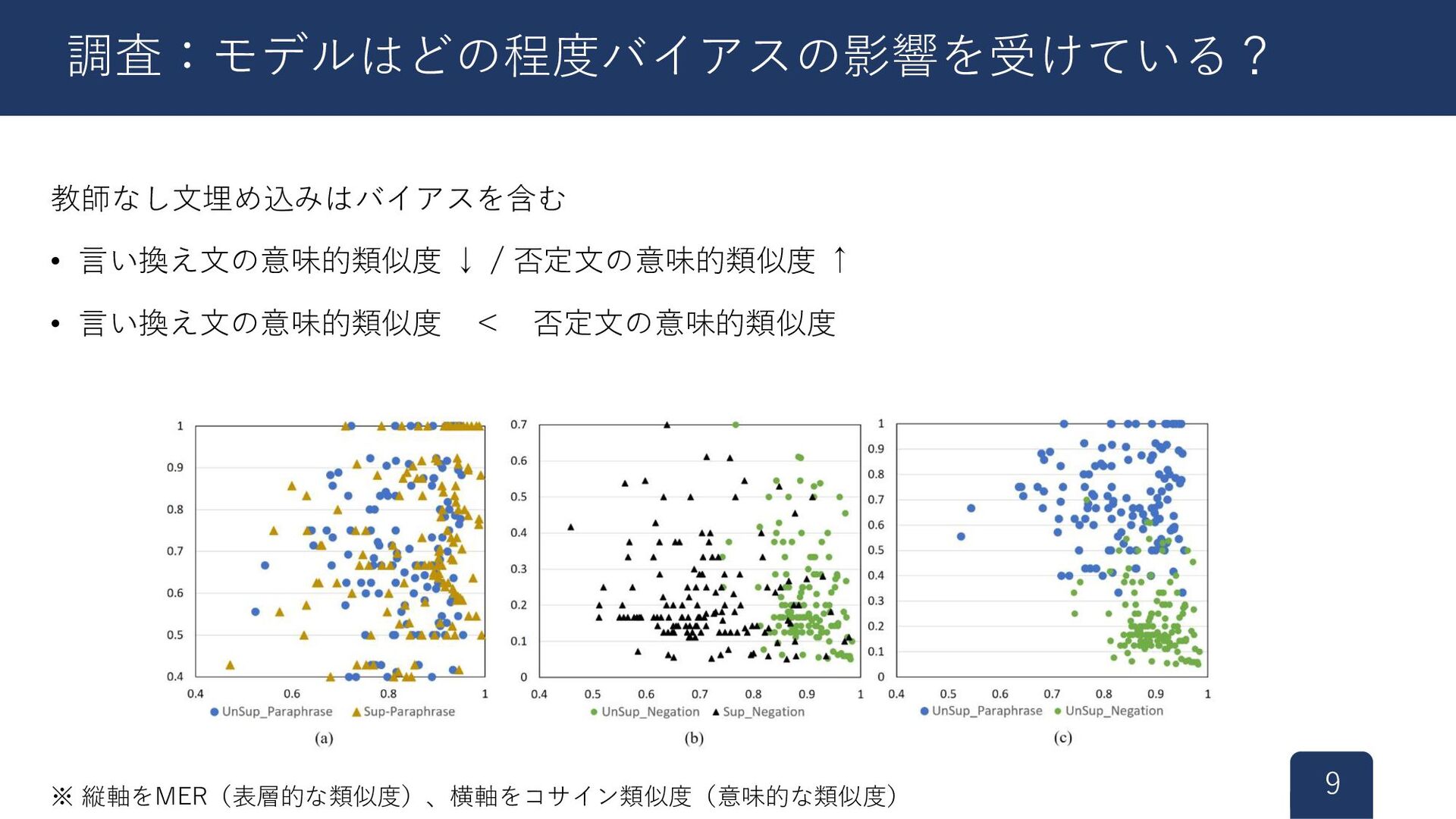
教師なし文埋め込みはバイアスを含む • 言い換え文の意味的類似度 ↓ / 否定文の意味的類似度 ↑ • 言い換え文の意味的類似度 <
否定文の意味的類似度 9 調査:モデルはどの程度バイアスの影響を受けている? ※ 縦軸をMER(表層的な類似度)、横軸をコサイン類似度(意味的な類似度)
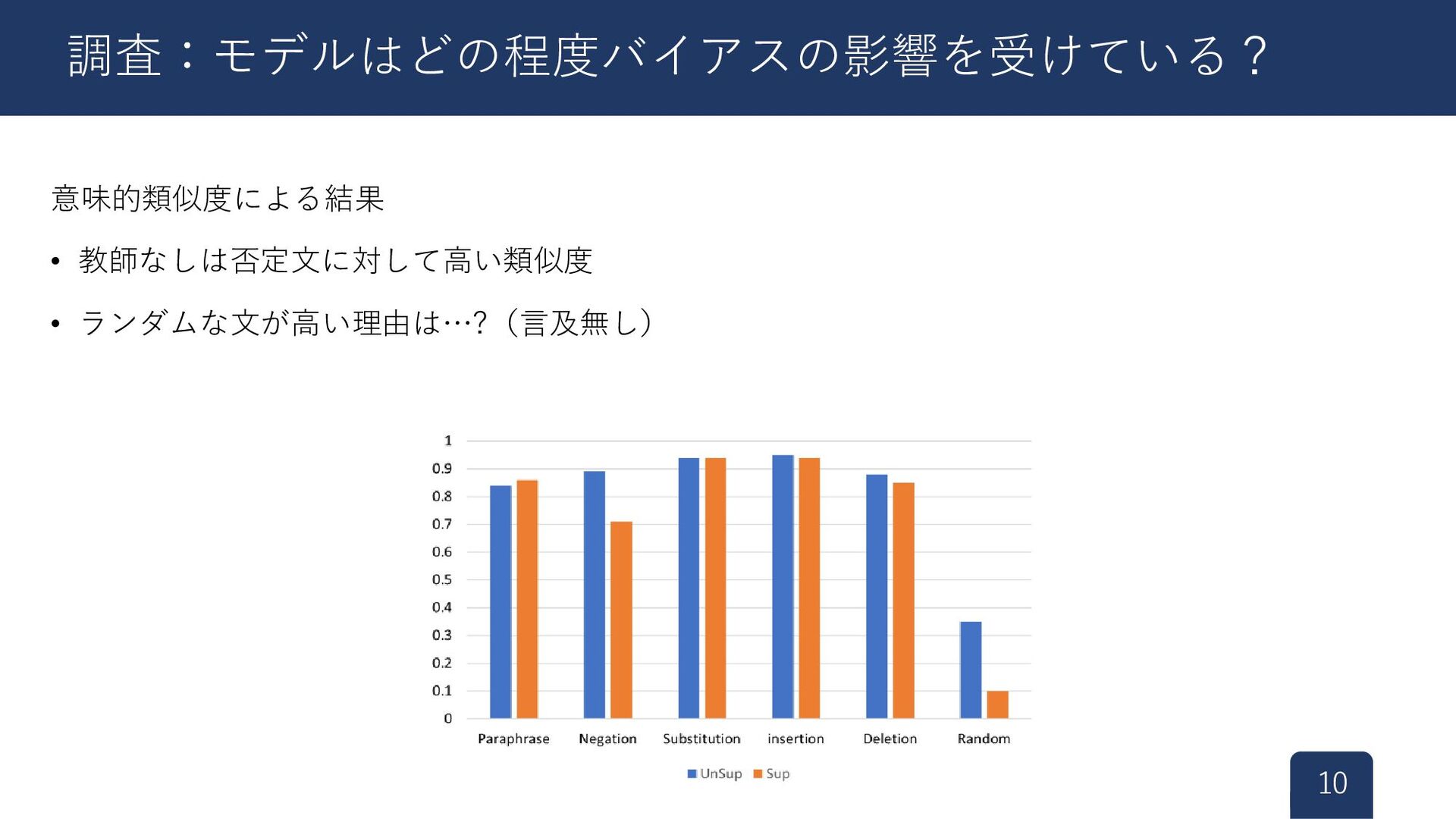
意味的類似度による結果 • 教師なしは否定文に対して高い類似度 • ランダムな文が高い理由は…?(言及無し) 10 調査:モデルはどの程度バイアスの影響を受けている?
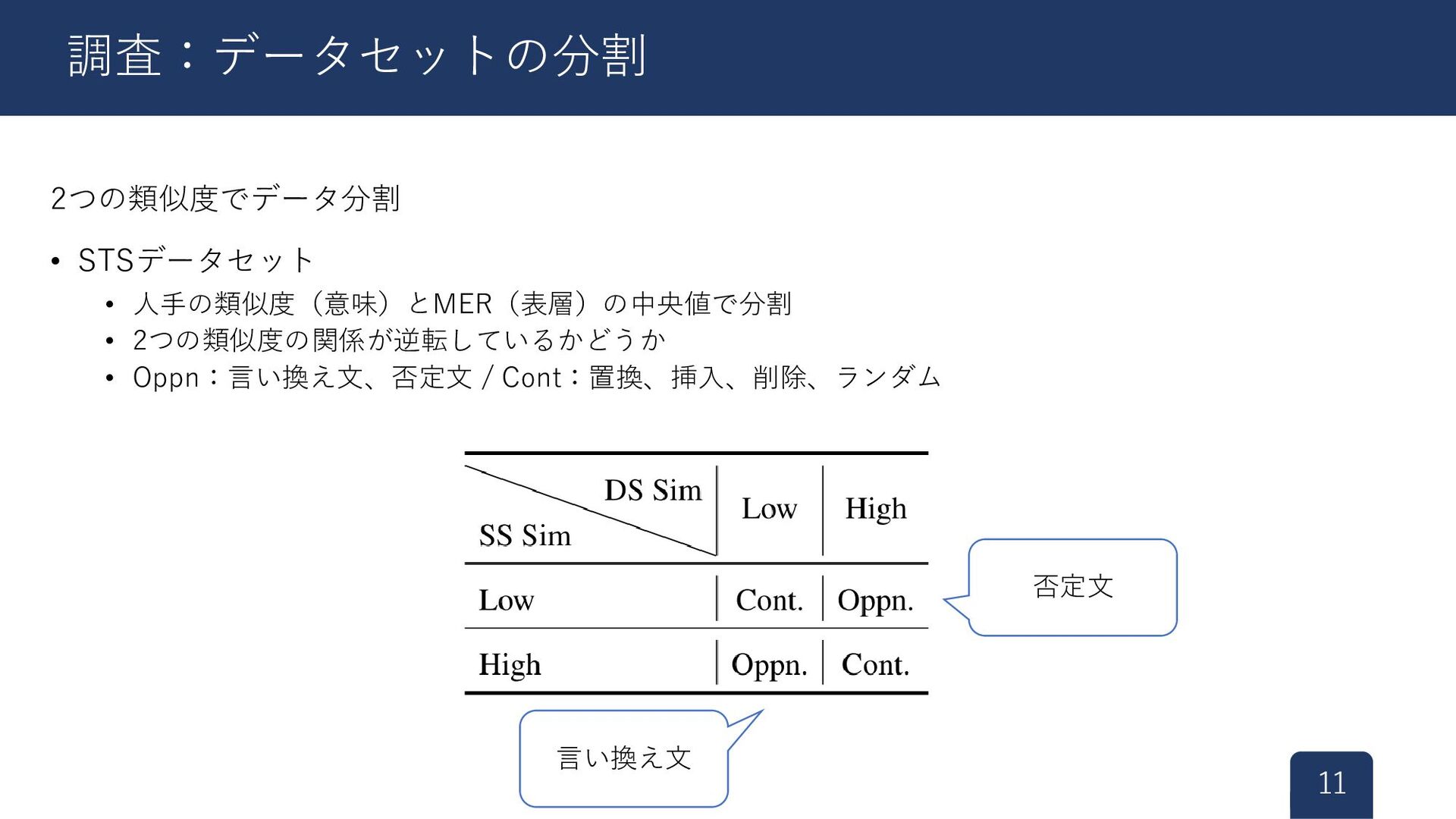
2つの類似度でデータ分割 • STSデータセット • 人手の類似度(意味)とMER(表層)の中央値で分割 • 2つの類似度の関係が逆転しているかどうか • Oppn:言い換え文、否定文 /
Cont:置換、挿入、削除、ランダム 11 調査:データセットの分割 否定文 言い換え文
人手の類似度とコサイン類似度の相関を計算 • Oppn(意味的な類似度と表層的な類似度の関係が逆)は低い • 言い換え文、否定文との類似度をうまく捉えられない • Oppnに特化した学習をしたい! 12 調査:データセットの分割
提案手法 / Methodology 13
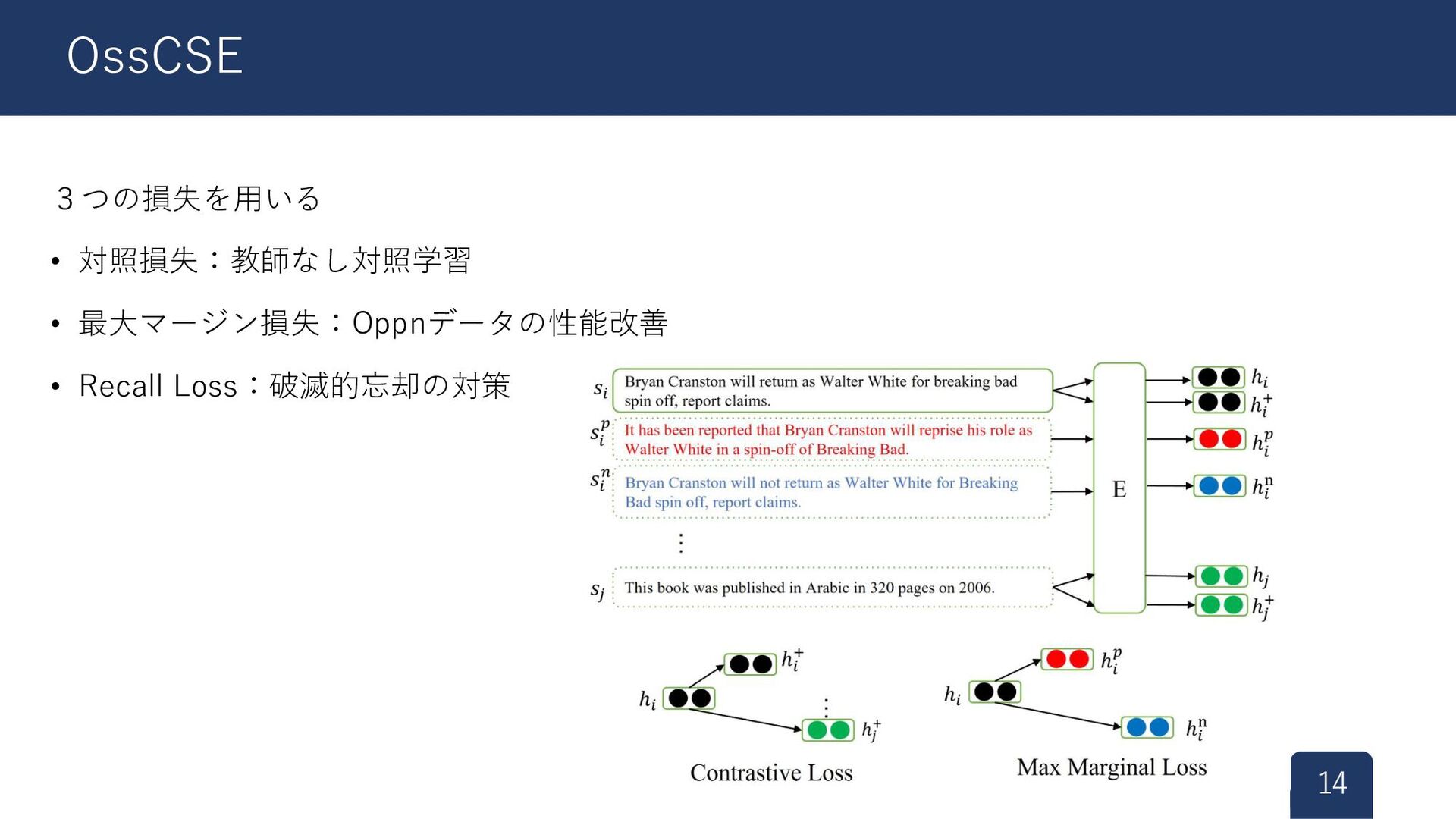
3つの損失を用いる • 対照損失:教師なし対照学習 • 最大マージン損失:Oppnデータの性能改善 • Recall Loss:破滅的忘却の対策 14 OssCSE
教師なし対照学習 • 正例:同じ文 • 異なるプロンプトを設定、<mask>を文表現 [1] • “This sentence :
“𝑠𝑖 ” means <mask>” • “This sentence of “𝑠𝑖 ” means <mask>” • 負例:異なる2文 • バッチ内負例 対照損失 15 対照損失 [1] Jiang et al.: PromptBERT: Improving BERT Sentence Embeddings with Prompts <mask>の隠れ層を利用 ※ Dropoutによる正例ではない
• Oppnデータの性能が低い → 言い換え文と否定文の学習データを拡張 • 言い換え文 𝑠 𝑖 𝑝 •
逆翻訳モデル(英⇔露、英⇔独) • 否定文 𝑠𝑖 𝑛 • 係り受け解析による自動追加 最大マージン損失 16 最大マージン損失 否定文との類似度 > 無関係な文との類似度 にしたいお気持ち 否定文との類似度 < 言い換え文との類似度 にしたいお気持ち
2種類の損失関数で学習すると • Oppn (STSB-dev)の性能が低下していく… • 事前学習時に得た知識(単語の意味)が忘却していく「破滅的忘却」 Recall Loss [2] 17
Recall Loss [2] Chen et al.: Recall and Learn: Fine-tuning Deep Pretrained Language Models with Less Forgetting 事前学習時に得た知識を思い出させる
実験 18
学習 • BERT, RoBERTaベース • 学習データ:Wikipedia100万文 • STSB-devの最高値となるハイパラで評価 タスク •
STSタスク • 転移学習ベンチマークタスク • テキスト分類などの下流タスク • 文埋め込みを入力とする分類器を訓練、分類性能から文埋め込みの質を評価 19 実験
結果 20
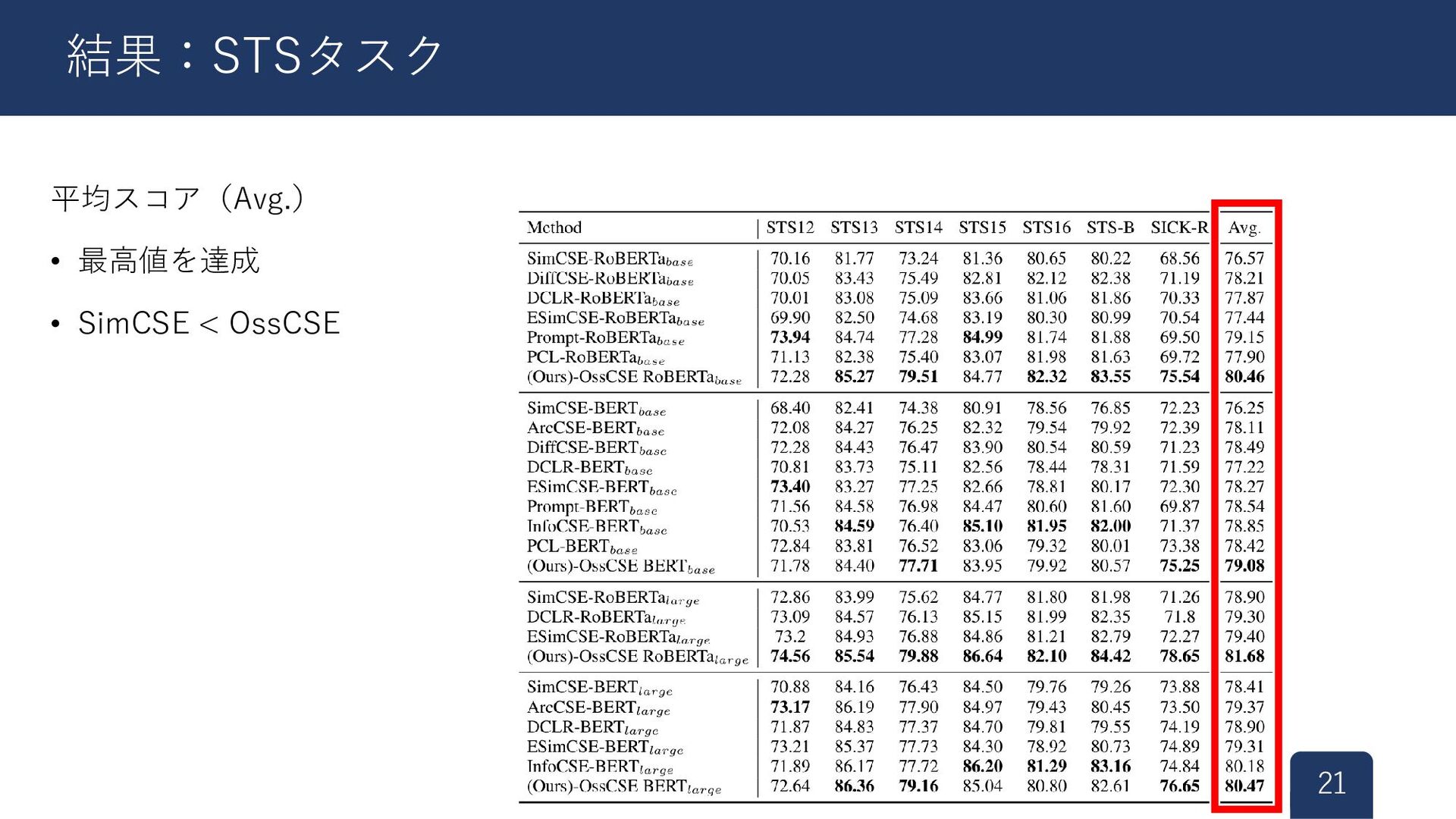
平均スコア(Avg.) • 最高値を達成 • SimCSE < OssCSE 21 結果:STSタスク
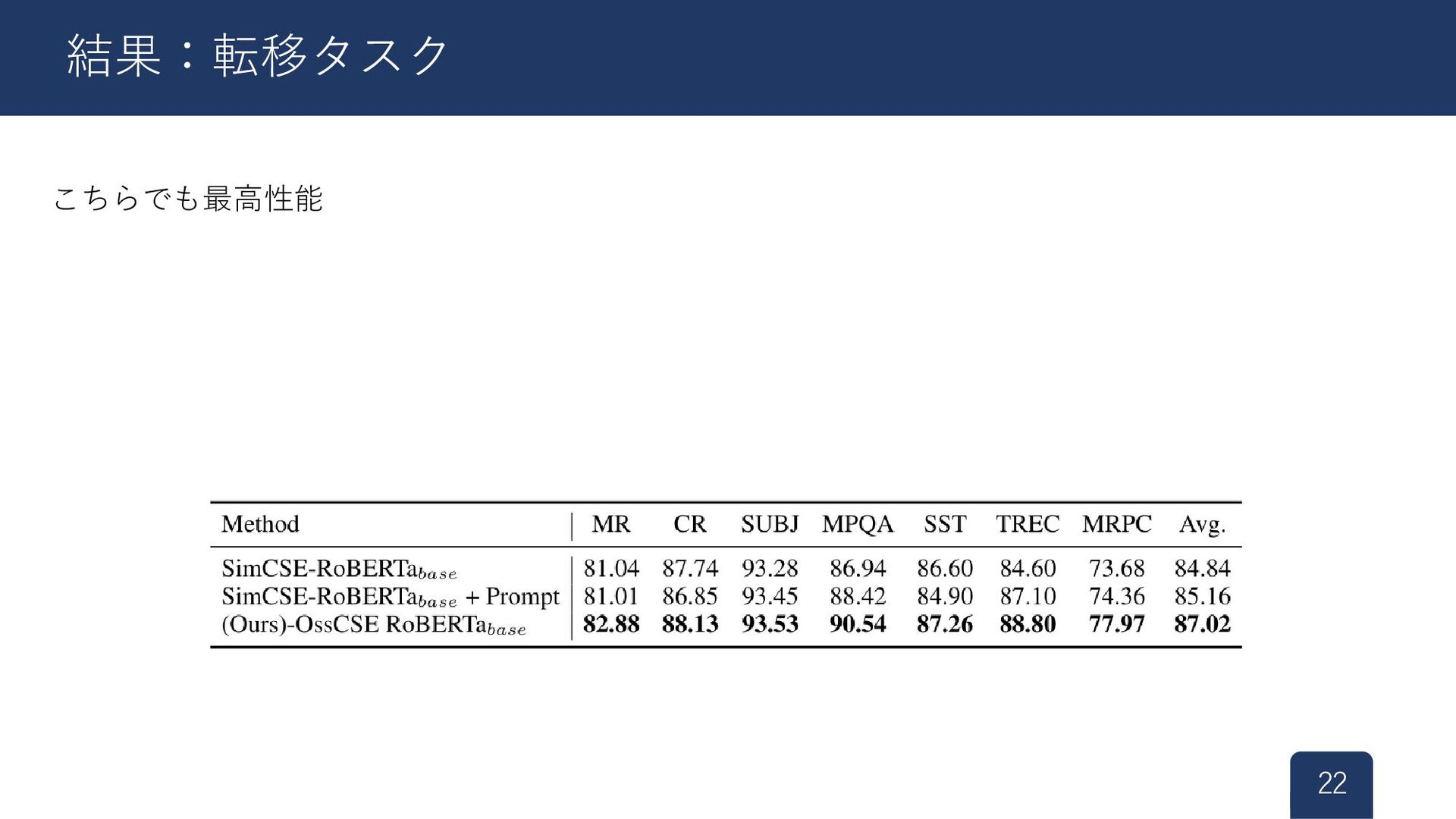
こちらでも最高性能 22 結果:転移タスク
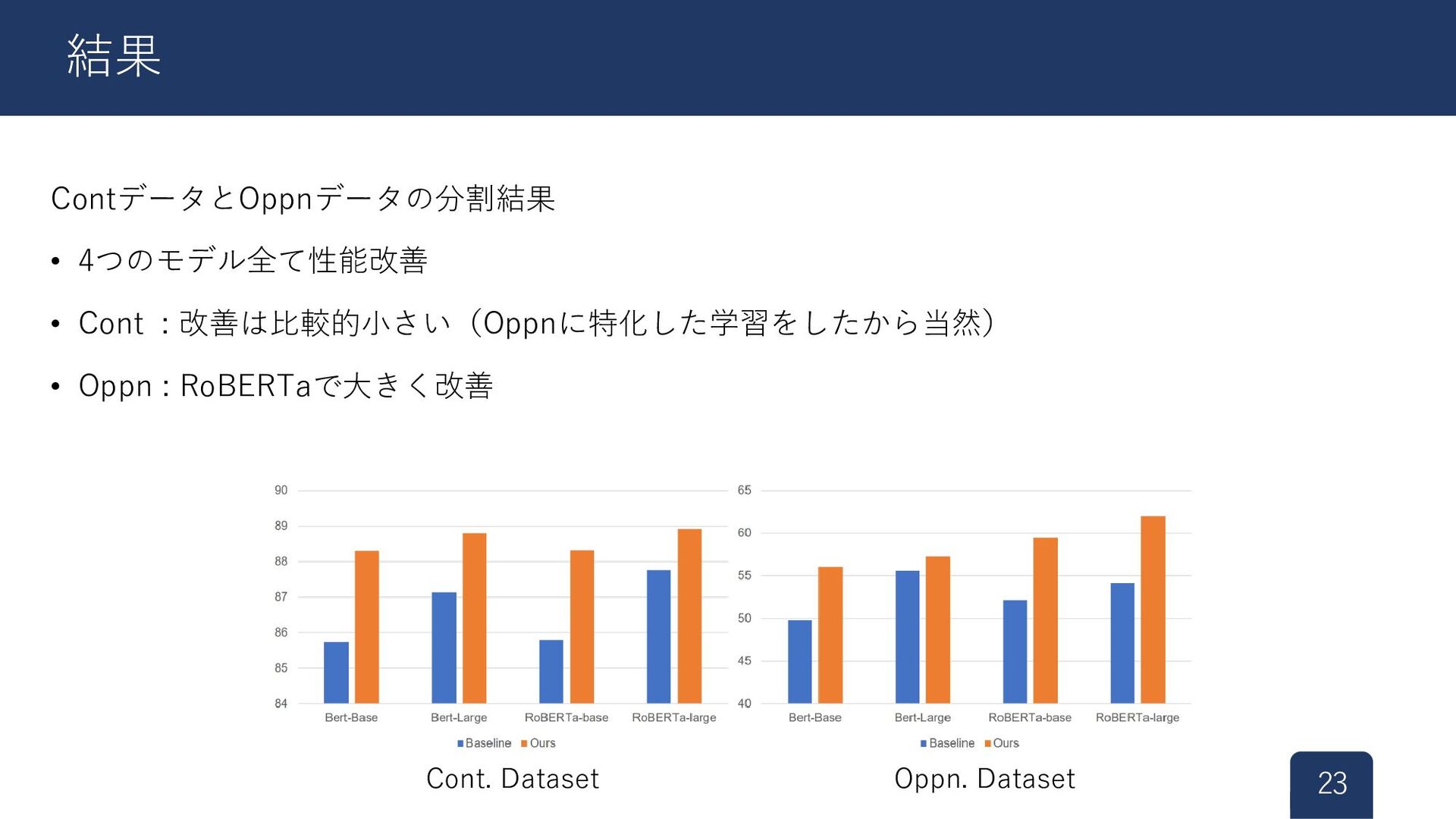
ContデータとOppnデータの分割結果 • 4つのモデル全て性能改善 • Cont : 改善は比較的小さい(Oppnに特化した学習をしたから当然) • Oppn :
RoBERTaで大きく改善 23 結果 Cont. Dataset Oppn. Dataset
分析 24
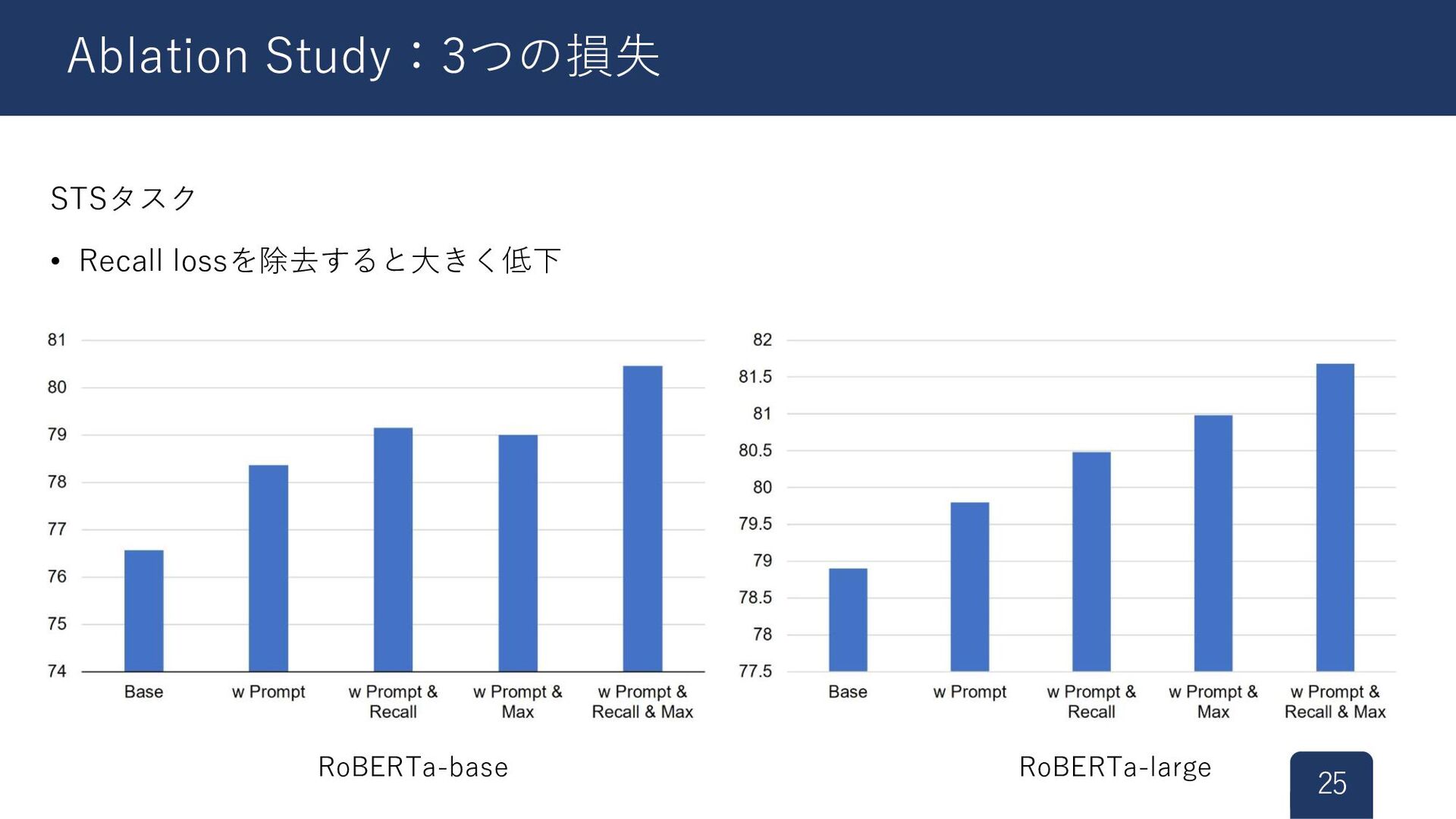
STSタスク • Recall lossを除去すると大きく低下 25 Ablation Study:3つの損失 RoBERTa-base RoBERTa-large
まとめ 26
• 教師なし文埋め込み学習における表層構造のバイアスを調査 • 最大マージン損失、recall lossの導入によるOppnに対する性能改善 限界 • 逆翻訳の品質 • 言い換え、否定以外の文に対して考慮せず学習
感想 • 最大マージン損失によるSTSタスクの性能改善が微妙… • 否定文との類似度 < 言い換え文との類似度になっているのかが不明瞭 • p.9 のようにプロットしてほしい 27 Conclusion and Limitations
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![教師なし対照学習 • 正例:同じ文 • 異なるプロンプトを設定、<mask>を文表現 [1] • “This sentence :](https://files.speakerdeck.com/presentations/7dd5d531695f4662aae32996ddda4f63/slide_15.jpg){kind=link}
{kind=link}
![2種類の損失関数で学習すると • Oppn (STSB-dev)の性能が低下していく… • 事前学習時に得た知識(単語の意味)が忘却していく「破滅的忘却」 Recall Loss [2] 17](https://files.speakerdeck.com/presentations/7dd5d531695f4662aae32996ddda4f63/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}