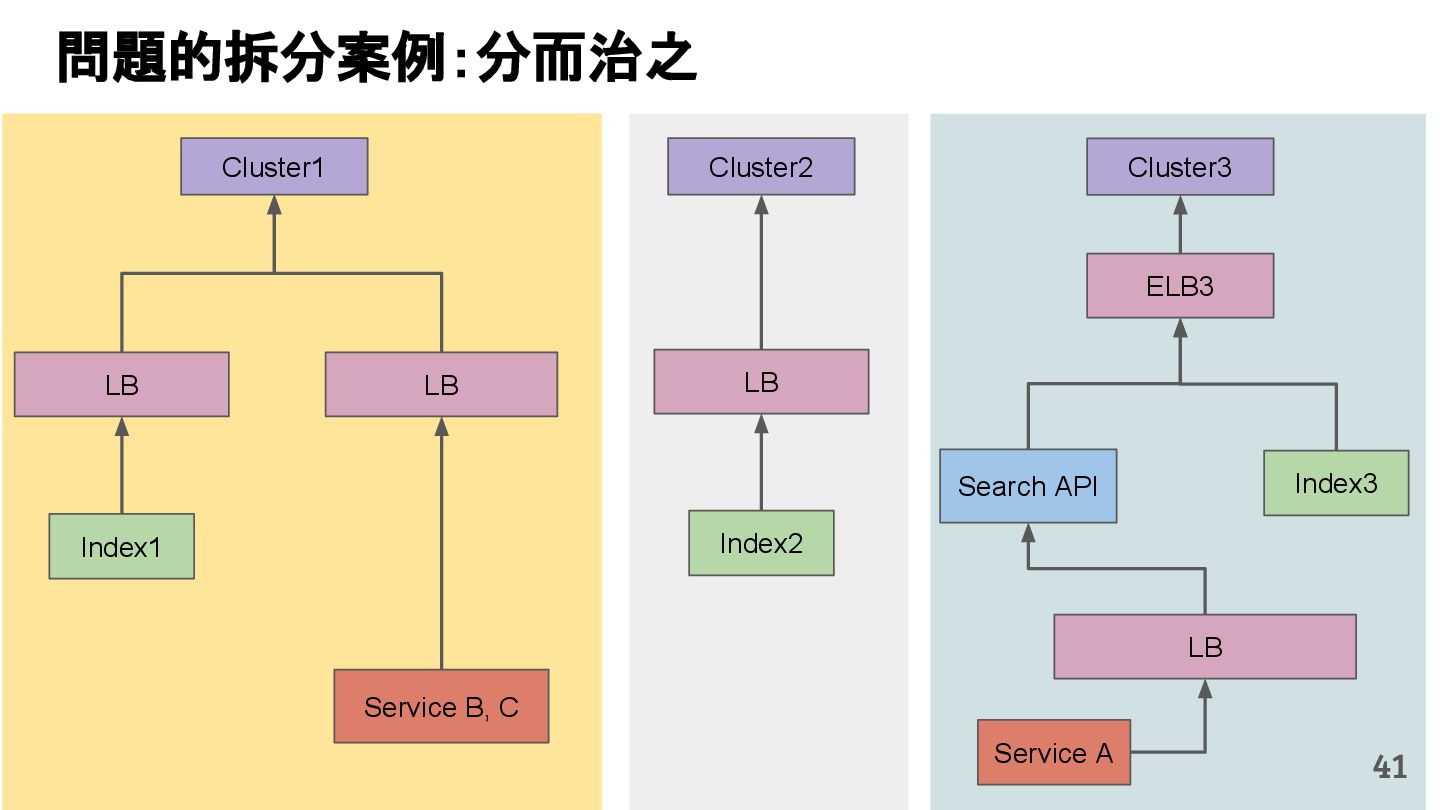
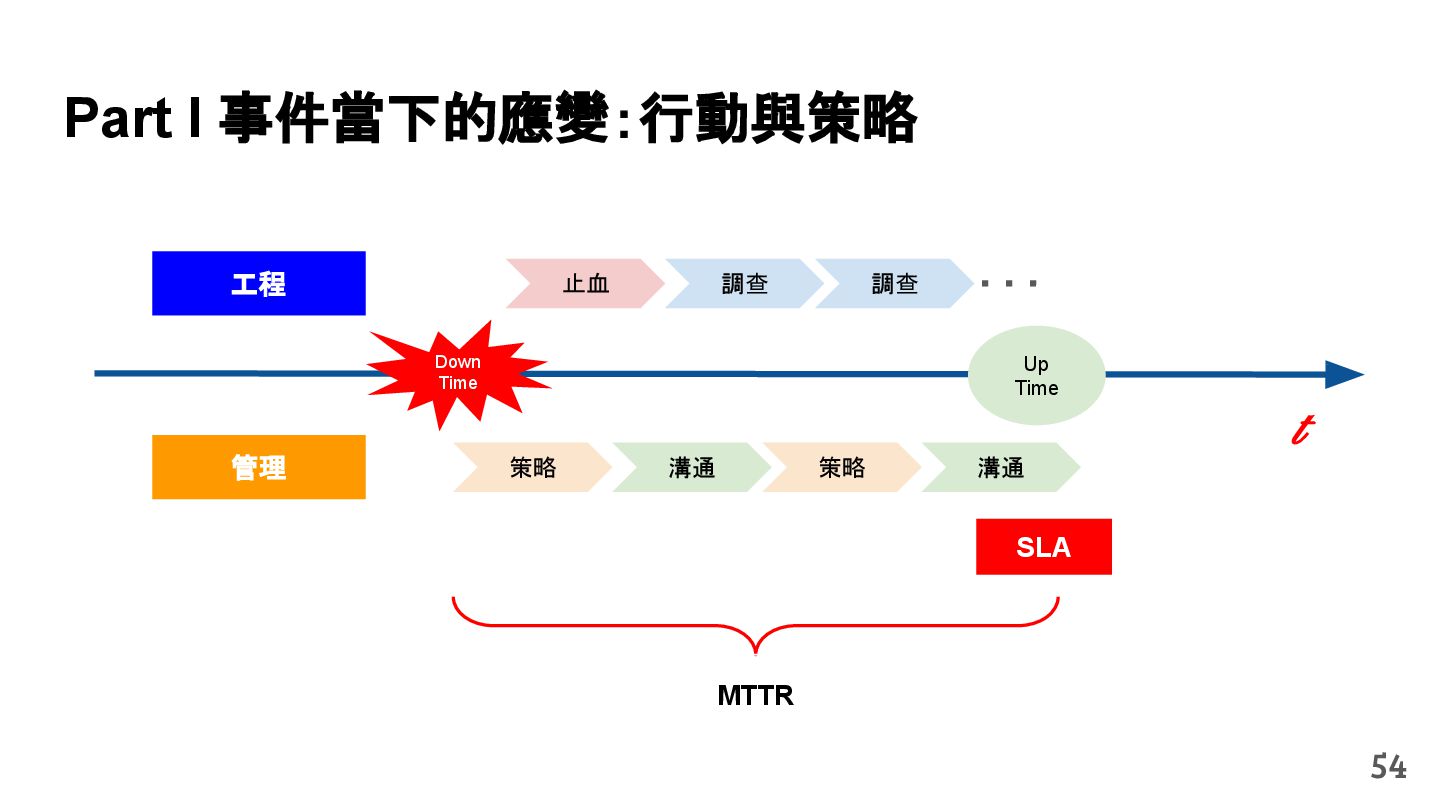
從現象,依據架構、指標,找問題點 (Part II) b. rollback, rollback, rollback c. 用最簡單的方法:加資源、移除有問題的節點、增加新節點、蓋防火巷 • 同步 a. 聯繫相關的人:Backend、Frontend、DBA、Networking b. 蒐集現象、指標 30
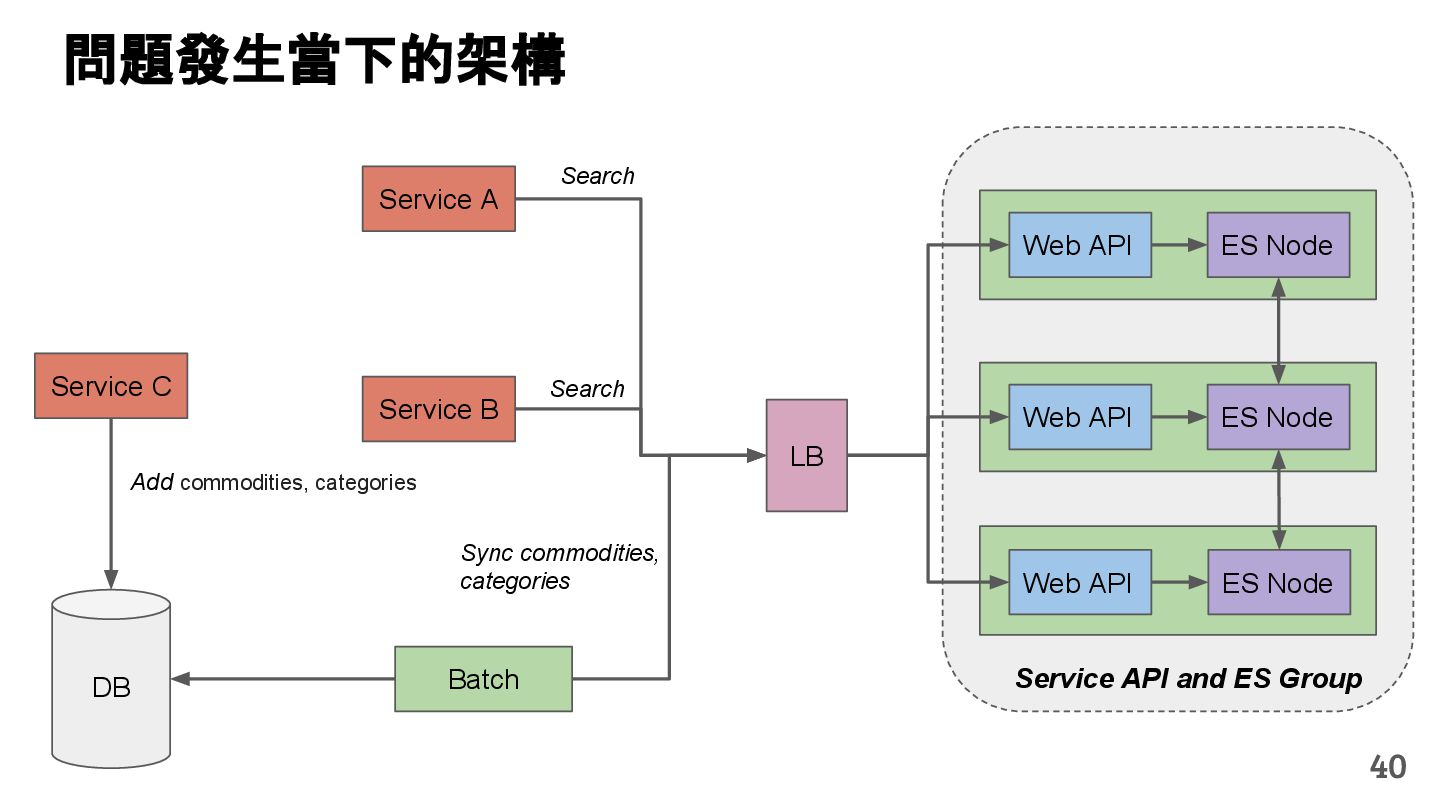
Batch DB Sync commodities, categories Service A Search Service C Add commodities, categories Web API ES Node Web API ES Node Service B Search 40 問題發生當下的架構
more than understanding how a system is supposed to work. Expertise is gained by investigating why a system doesn’t work. -- Brian Redman SRE CH12 Effective Troubleshooting
(網路沒有延遲) • Bandwidth is infinite (頻寬是無限的) • The network is secure (網路是安全的) 計算計科學家 Peter Deutsch 在九零年代就提出 Fallacies of distributed computing (分散式系統的謬論),點出以下容易被忽略、或者輕忽的觀點: 分散式系統的謬論 96 • Topology doesn’t change (網路拓墣不會改變) • There is one administrator (網路上有個管理員) • Transport cost is zero (傳輸沒有成本) • The network is homogeneous (網路是同質的)
being an expert is more than understanding how a system is supposed to work. Expertise is gained by investigating why a system doesn’t work. -- Brian Redman SRE CH12 Effective Troubleshooting
{kind=link}
{kind=link}
{kind=link}
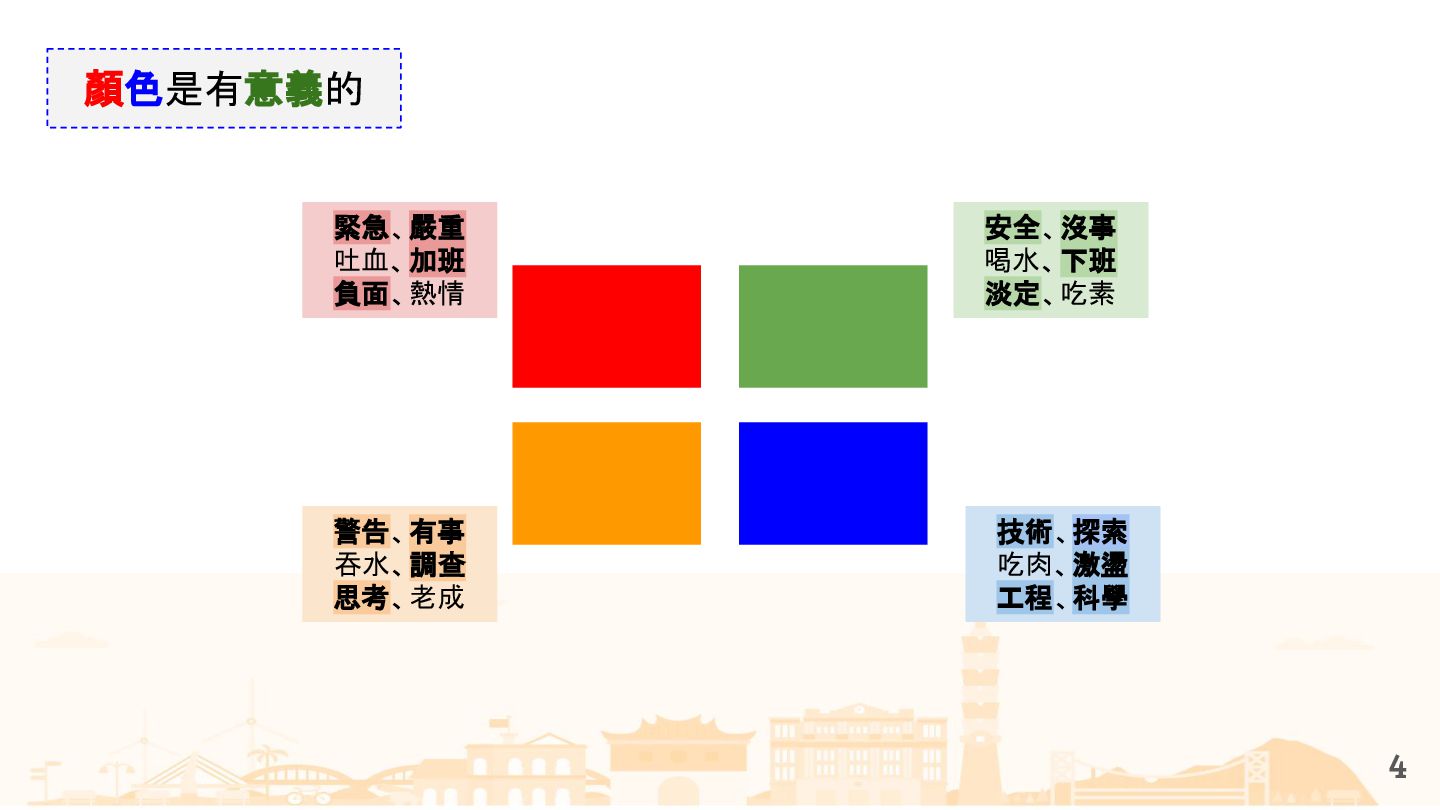{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
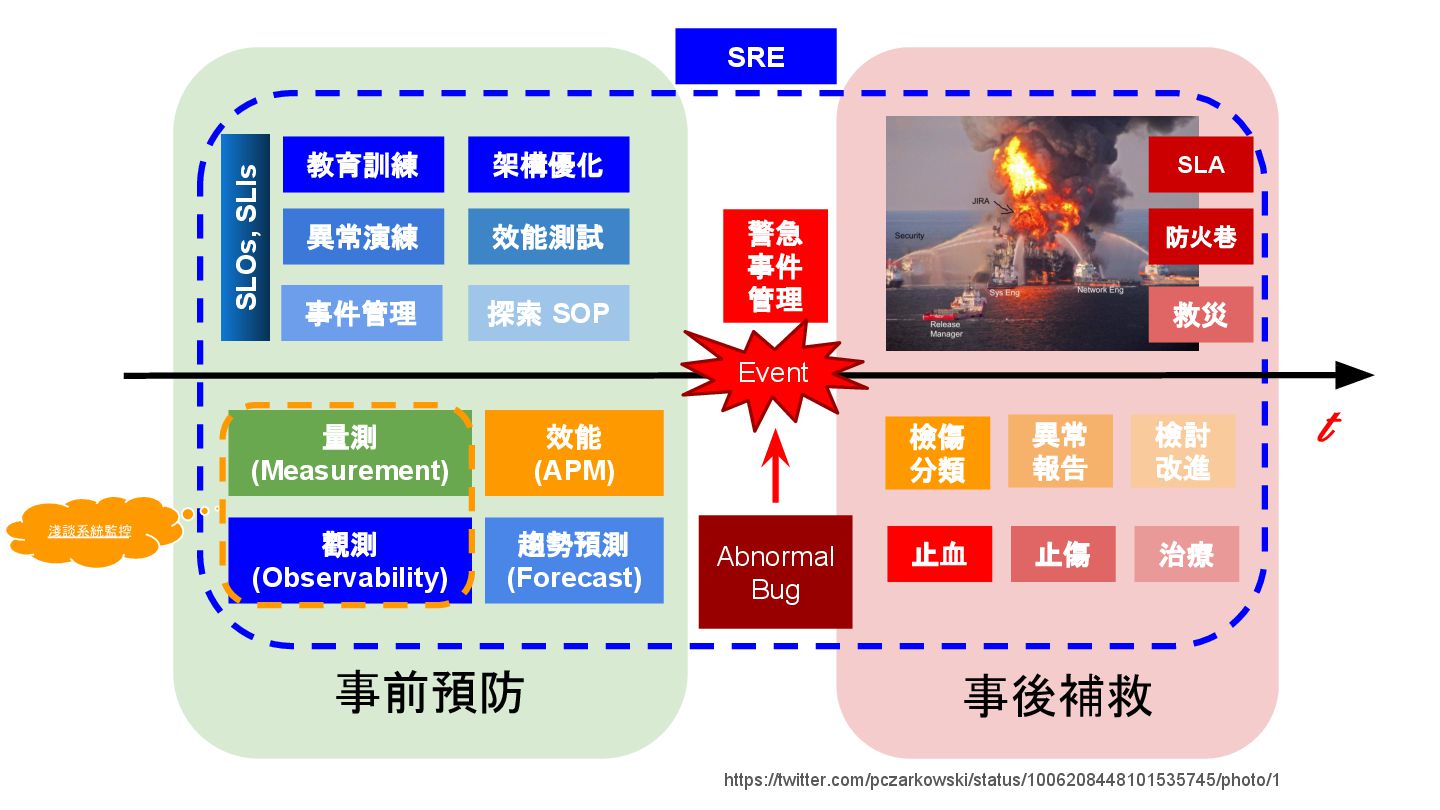{kind=link}
{kind=link}
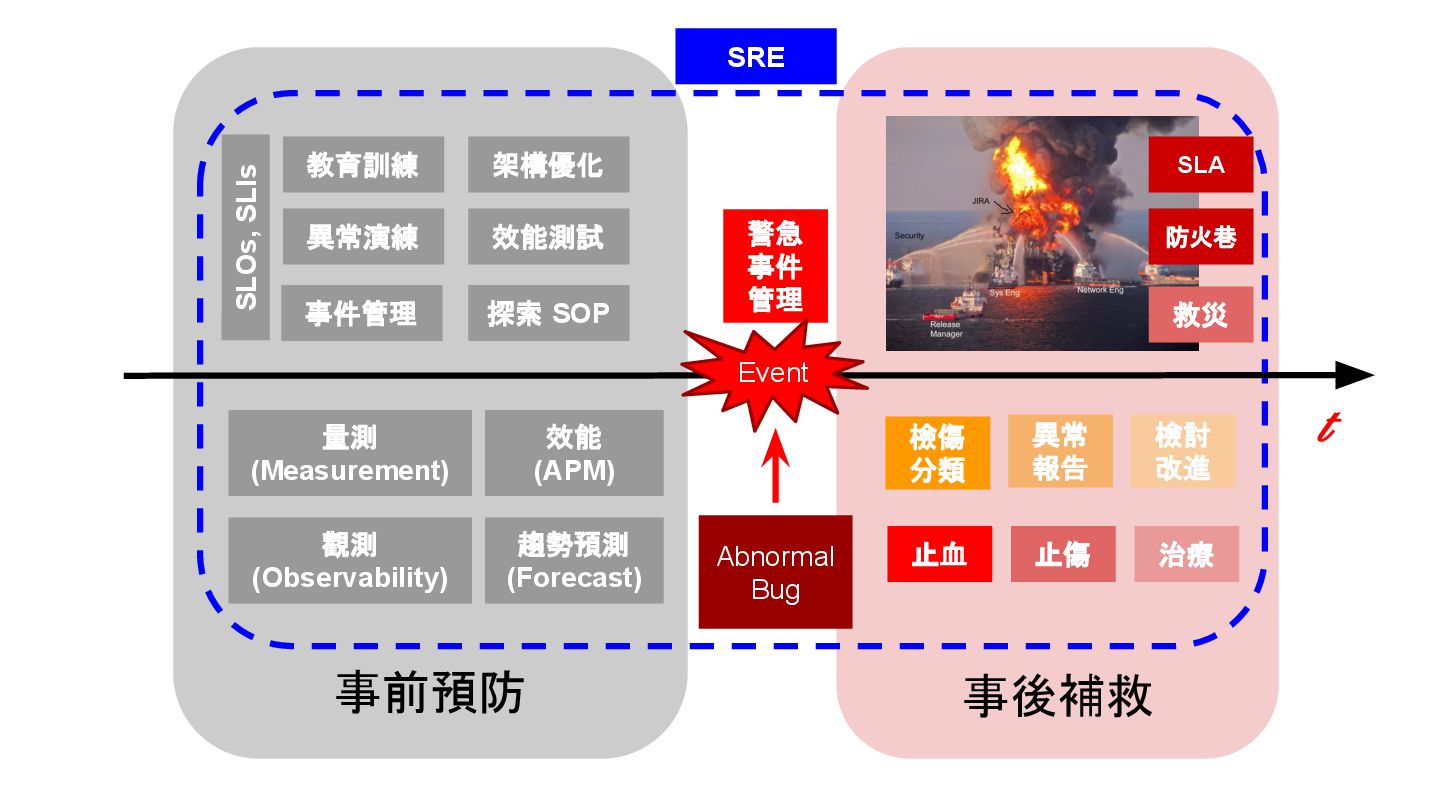{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
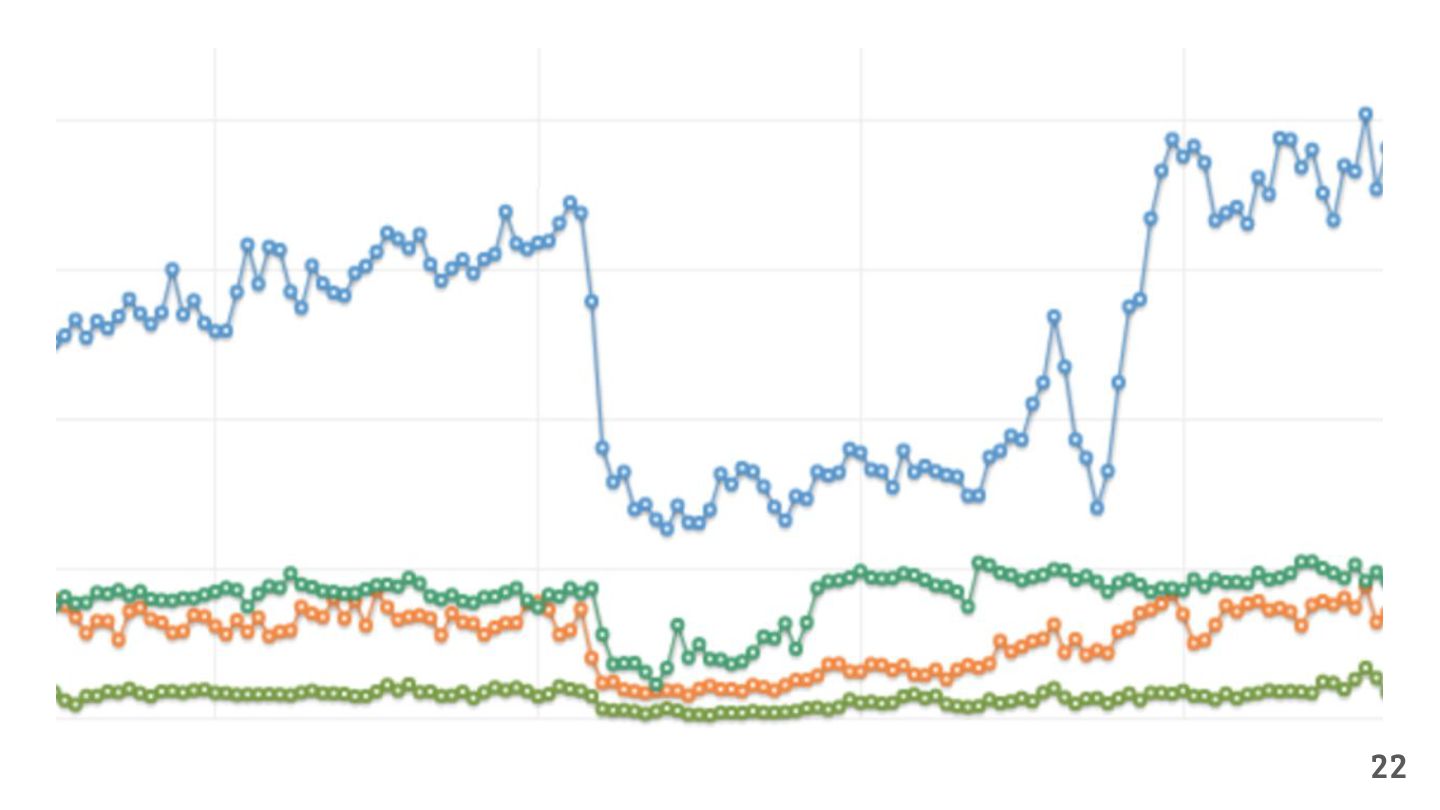{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
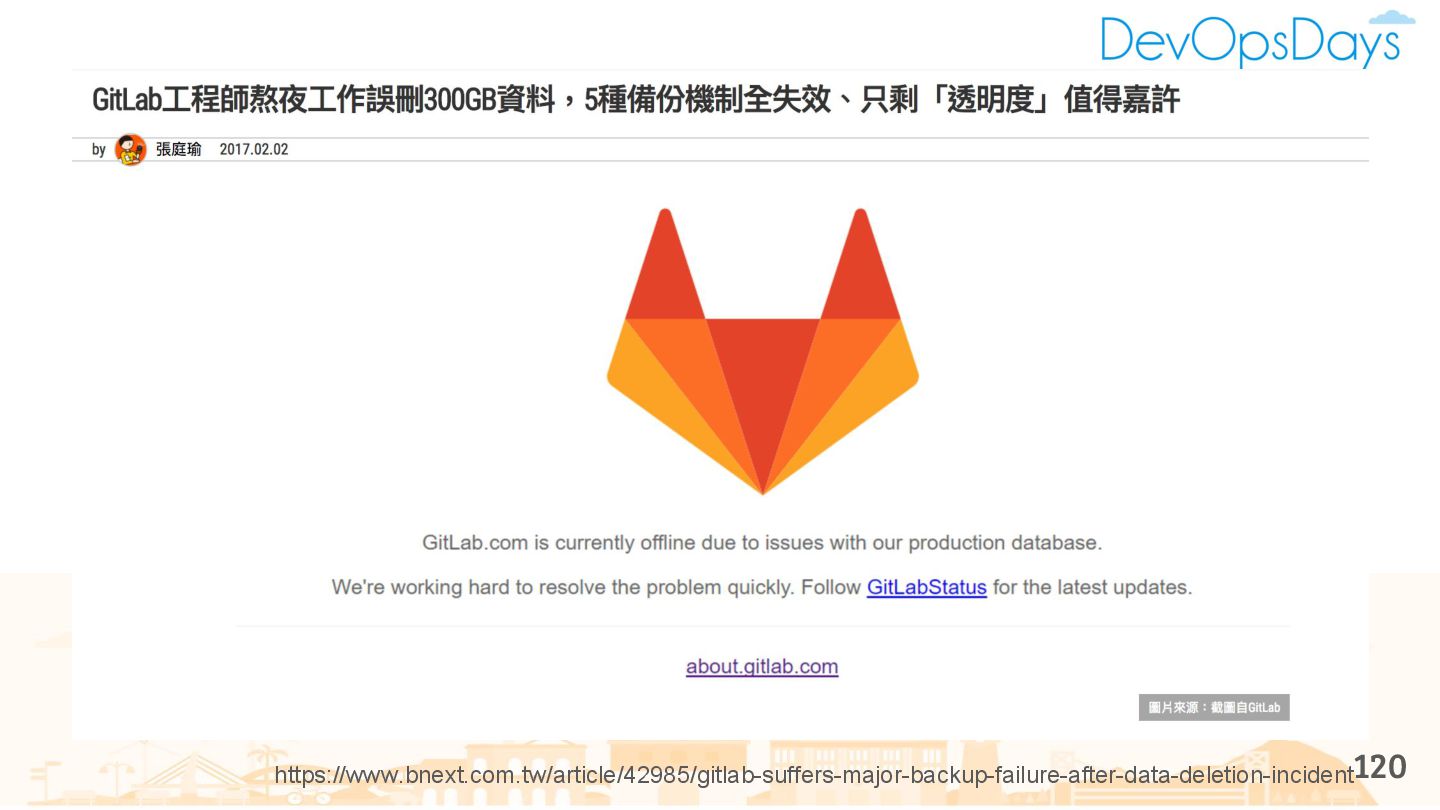{kind=link}
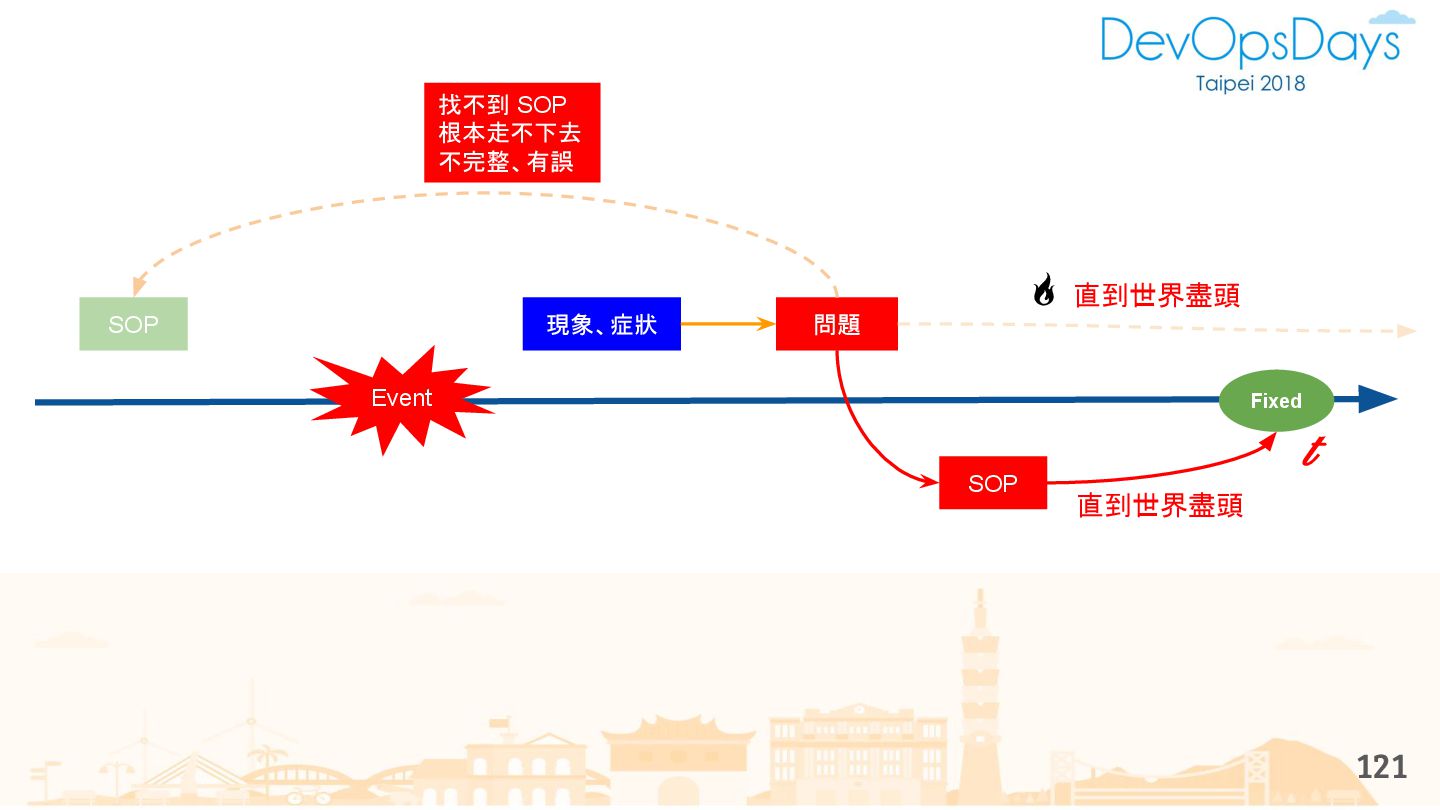{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
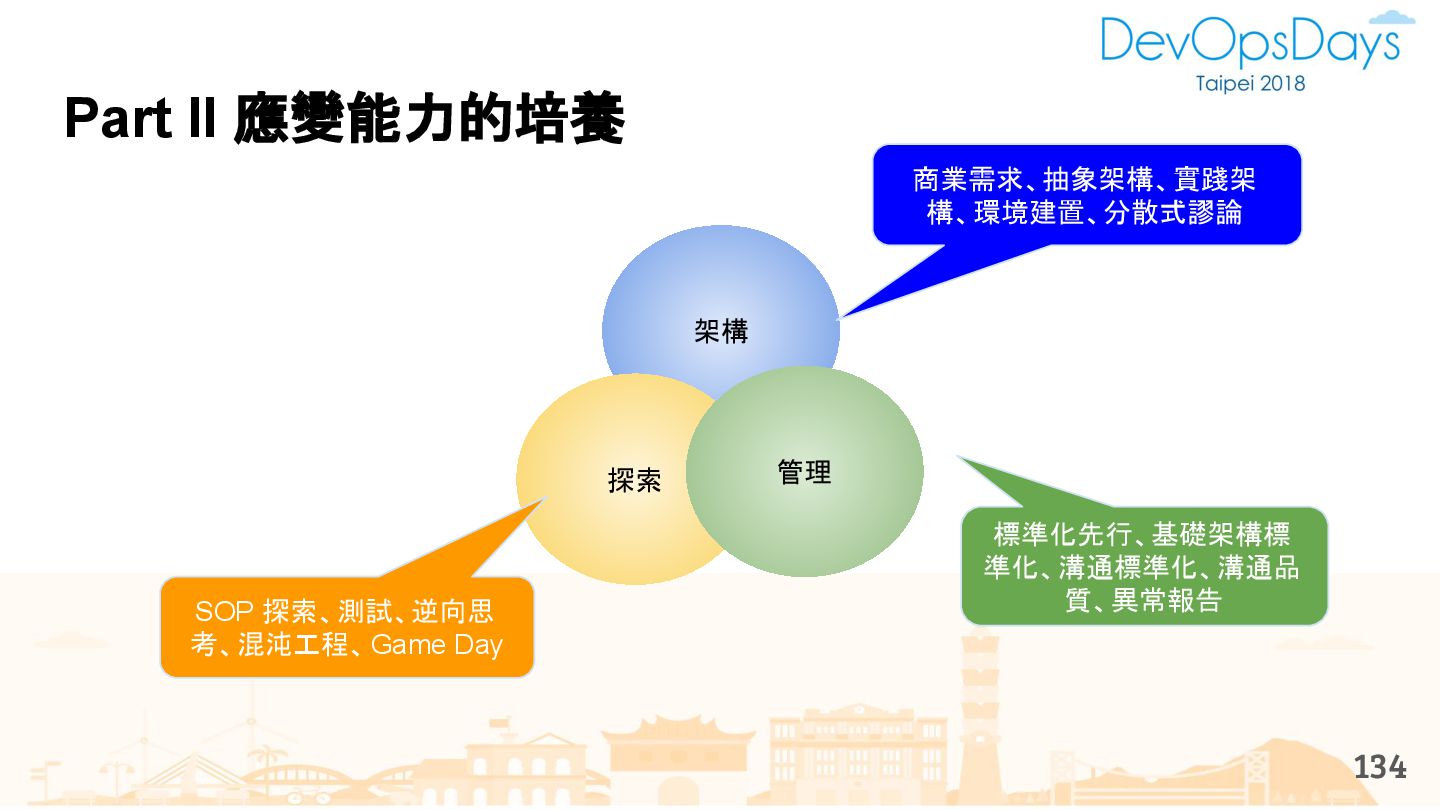{kind=link}
{kind=link}
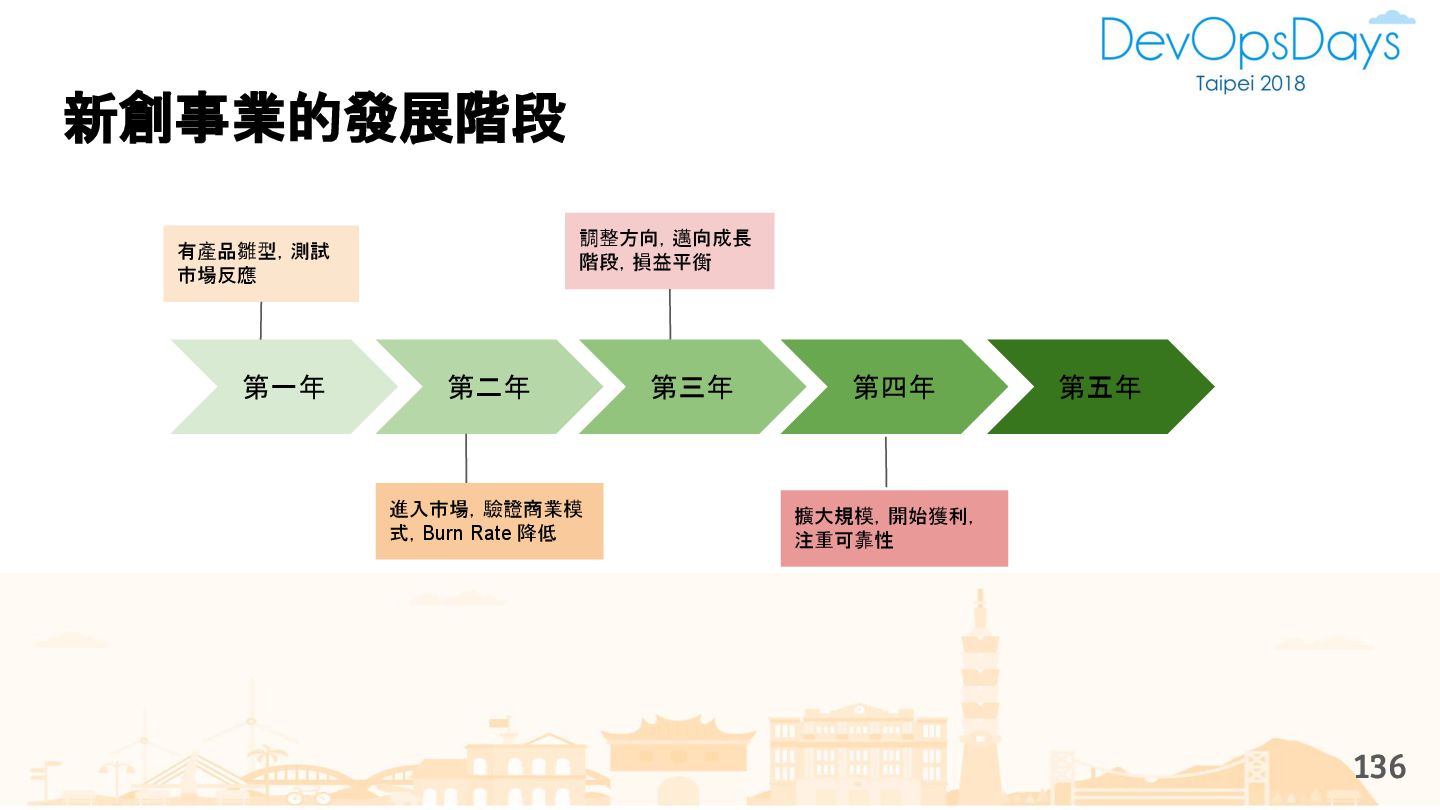{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}