Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Learning Semantic Textual Relatedness using Nat...
Search
Atom
January 29, 2019
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Learning Semantic Textual Relatedness using Natural Deduction Proofs
Presenting literature
Atom
January 29, 2019
More Decks by Atom
See All by Atom
YouTubeのチャット欄の配置変更 / Changing the layout of the YouTube chat field
roraidolaurent
0
13
文献紹介 / Structure-based Knowledge Tracing: An Influence Propagation View
roraidolaurent
0
120
文献紹介 / Knowledge Tracing with GNN
roraidolaurent
0
110
文献紹介 / Non-Intrusive Parametric Reduced Order Models withHigh-Dimensional Inputs via Gradient-Free Active Subspace
roraidolaurent
0
69
ニューラルネットワークのベイズ推論 / Bayesian inference of neural networks
roraidolaurent
2
2.9k
Graph Convolutional Networks
roraidolaurent
0
260
文献紹介 / A Probabilistic Annotation Model for Crowdsourcing Coreference
roraidolaurent
0
96
文献紹介Deep Temporal-Recurrent-Replicated-Softmax for Topical Trends over Time
roraidolaurent
0
140
文献紹介/ Bayesian Learning for Neural Dependency Parsing
roraidolaurent
0
140
Featured
See All Featured
Fireside Chat
paigeccino
42
4k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
KATA
mclloyd
PRO
35
15k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
Prompt Engineering for Job Search
mfonobong
0
370
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
Agile that works and the tools we love
rasmusluckow
331
22k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Context Engineering - Making Every Token Count
addyosmani
9
1k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Transcript
自然演繹に基づく論理推論の 文間類似度学習・含意関係認識への応用 自然言語処理 Vol.25 No.3 p.295-324, 2018 文献紹介 2019/1/29 長岡技術科学大学
自然言語処理研究室 吉澤 亜斗武
1. 概要 ・本研究では,文間の含意関係を高階論理の推論によって判定す るシステムの実行過程から,文間の関連性に寄与する特徴を抽 出し,文間の関連性を学習させる手法を提案 ・文書間類似度学習と含意関係認識のタスクに関して提案手法の 評価を行った結果,いずれのタスクにおいても精度が向上した ・含意関係認識用データセットの1つであるSICKによる評価で は最高精度を達した 2
2. はじめに ・文の意味表現では,ベクトル空間モデルや深層学習を用いる手 法があるが,例えば”some”と”any”がほぼ同じ単語として扱わ れるなど,文の意味の違いをどのように捉えるかが課題である ・一方,論理推論は含意関係認識のタスクでは高精度であるが, 部分的・段階的な含意関係や類似関係を扱うことが困難である ・本研究では,機械学習と論理推論とを組み合わせることで, 文の関連性を学習する方法を提案 3
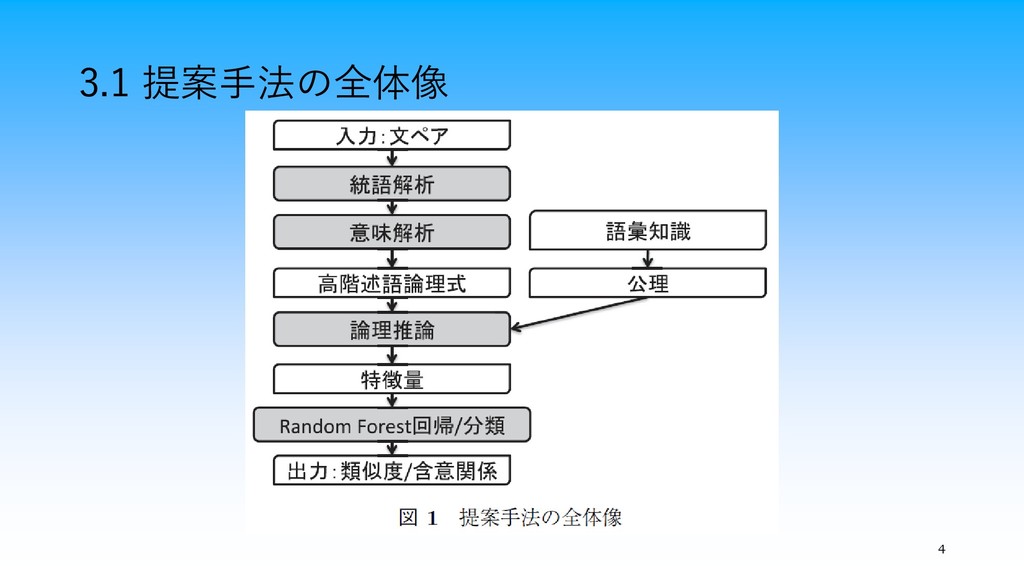
3.1 提案手法の全体像 4
・3種類のCCGパーザ(C&C, EasyCCG, depccg)おいて統語解 析により英語の自然言語文をCCGの導出木に変換し,3種類 のパーズ結果を用いて意味合成と推論を行い,適切なパーズ結 果を選択する ・トレーニングデータから特徴量を抽出する際は,含意関係の 正解ラベルと同じ結果を導出するパーズ結果を優先. 複数ある場合は精度順(depccg, EasyCCG,
C&C)で採用 5 3.2 組合せ範疇文法 (CCG) に基づく意味表現
6 3.2 組合せ範疇文法 (CCG) に基づく意味表現
定理証明器Coqとccg2lambdaを用いる 1. 文A, B を論理式A’, B’ と変換し,′ ⇒ ′, ′
⇒ ′ を行う 2. 1.の証明に失敗したら, ′ ⇒ ¬′, ′ ⇒ ¬′ を行う 3. 2.の証明も失敗したら,後述する定理の生成を行う 4. 1.および2.を生成された公理の下で行う 5. 4.の証明すらも失敗したら,強制終了する 6. 5.までにおける推論の情報をCoqの出力結果から抽出 7 3.5 自然演繹による証明戦略
1. WordNetを用いて前提と結論中の述語間の意味的関係(例:形態 変化)をチェックし,マッチすれば確信度(共通する上位概念へ の最短経路の長さ)つきの公理を作成 2. WordNetに述語間の関係が存在しない場合は,Word2Vecの200次 元単語ベクトル(Google News Corpus (約30億語)で学習済み)
を用いて前提と結論中の述語間の類似度を計算し,確信度(コサ イン類似度)つきの公理を作成する 確信度は0.0~1.0の値をとし,0.25未満は公理として採用しない 8 3.5 語彙知識を用いた公理の生成
特徴量(いずれも0.0から1.0の範囲に正規化する) ・証明の実行過程と結果から導出した9種類の特徴量を用いる 例)証明の結果,証明のステップ数,公理の数と確信度 ・表層情報と外部知識から導出した10種類の特徴量を用いる 例)文の長さ,品詞の一致率,概念間の距離 ランダムフォレスト回帰/分類を学習モデルとする. ハイパーパラメータはグリッドサーチを用いて最適化. 9 3.6 特徴量の設計と文の関連度学習
4.1 データセット ・SemEval2014 Task1 SICK データセット 文の意味的類似度と含意関係認識の評価用データセット 類似度:1.0~5.0, 訓練データ:4,500件, 開発データ:500件
テストデータ:4,927件 ・SemEval2012 MSR-videoデータセット 文の意味的類似度の評価用データセット 類似度:0.0~5.0, 開発データ, テストデータが750件ずつ 10
4.1 データセット 11 一文あたりの平均単語数は10単語
4.1 データセット 12 一文あたりの平均単語数は6単語
4.2 既存手法との比較評価(類似度) 13 ・SICKの単語はほぼWordNetに含まれているので,WordNetと WordNet+Word2Vecの手法の精度はほぼ変わらない ・SICKの方が平均単語数が多く,フレーズレベルでの言い換えが多いため, SICKではWord2Vecによって誤った公理の過剰生成がおこり,γが低い ・MSR-videoではWord2Vecを用いて単語間の語彙知識を拡充し精度が向上
4.2 既存手法との比較評価(含意関係) 14 適合率:yes, noと予測した文ペアに対して,正解ラベルと同じ結果だったケースの割合 再現率:正解ラベルがyes, noである文ペアに対して正解ラベルと予測ラベルが同じだった ケースの割合 正答率:yes, no,
unknownのすべての文ペアに対して正解ラベルと予測ラベルが同じだった ケースの割合 既存の最高精度モデル→
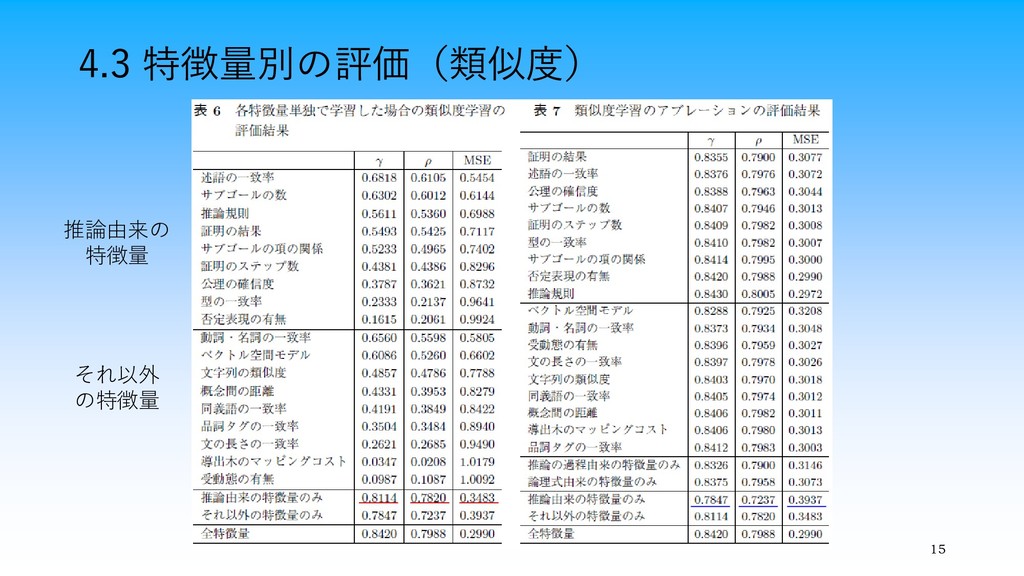
4.3 特徴量別の評価(類似度) 15 推論由来の 特徴量 それ以外 の特徴量
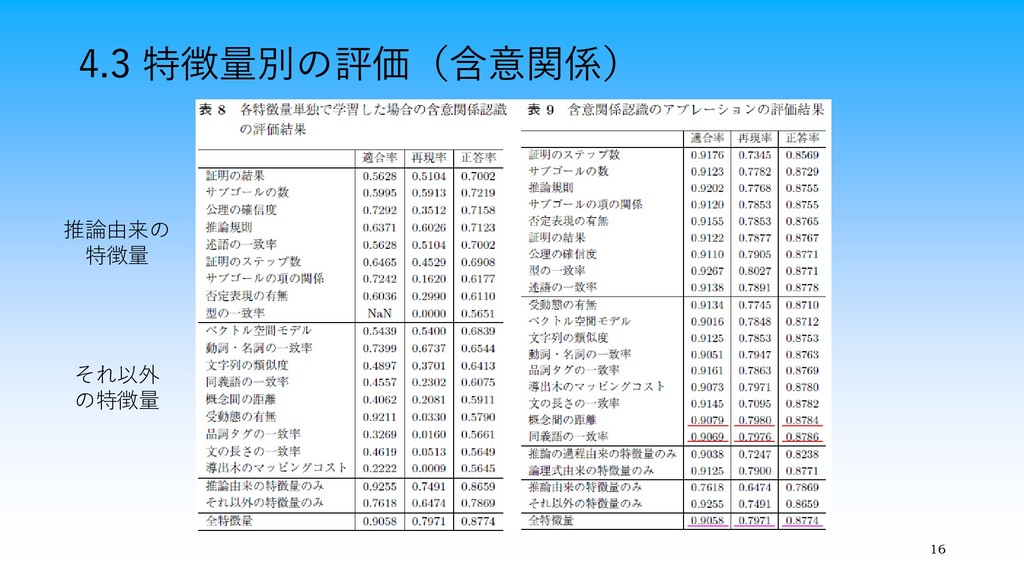
16 4.3 特徴量別の評価(含意関係) 推論由来の 特徴量 それ以外 の特徴量
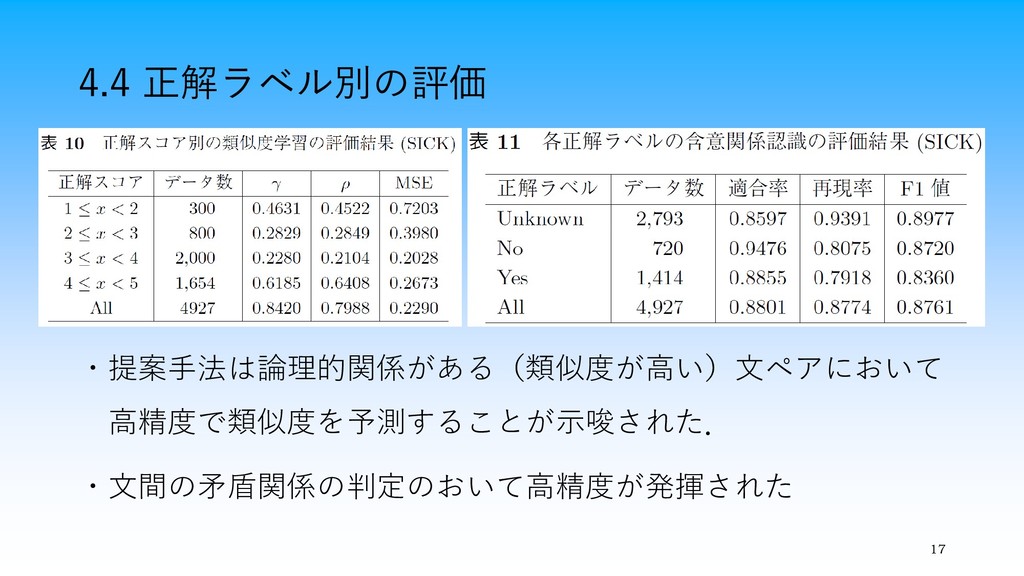
4.4 正解ラベル別の評価 17 ・提案手法は論理的関係がある(類似度が高い)文ペアにおいて 高精度で類似度を予測することが示唆された. ・文間の矛盾関係の判定のおいて高精度が発揮された
4.5 本研究の手法と深層学習による手法の比較 18 ・提案手法とMueller and Thyagarajan 2016 による予測類似度 との比較すると,4,927件中 2,666件は提案手法の方が正解スコ
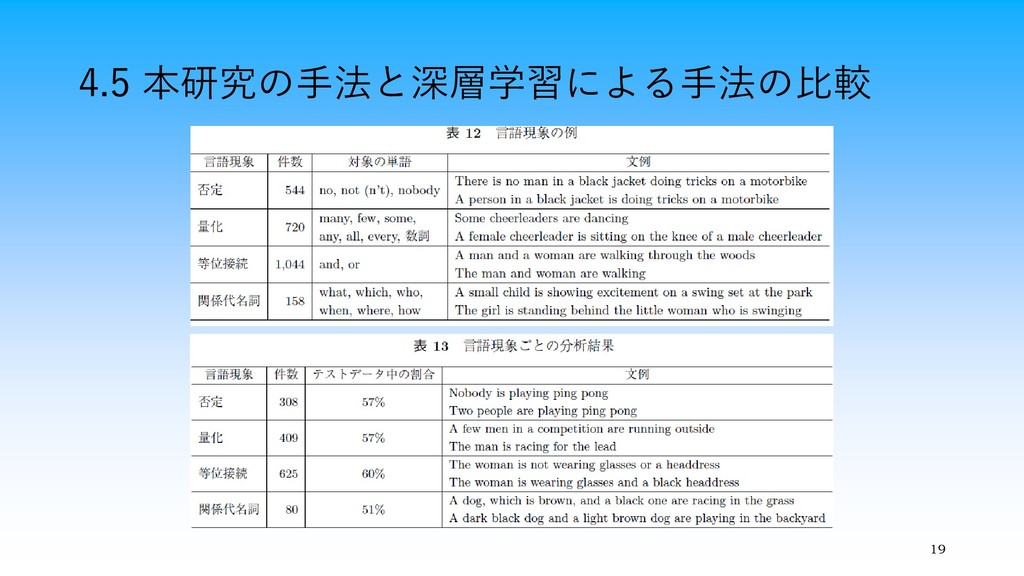
アに近い類似度を予測していた ・2,666件について,言語現象の傾向を分析(表12) ・提案手法が高精度で予測した文例数とテストデータ中の割合を 計算した結果を表13に示す.
4.5 本研究の手法と深層学習による手法の比較 19
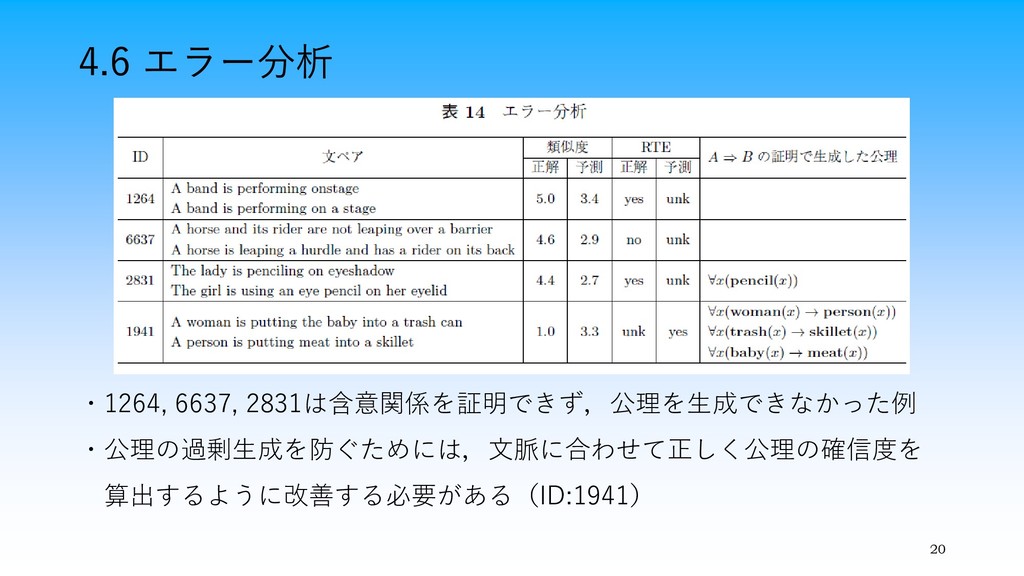
4.6 エラー分析 20 ・1264, 6637, 2831は含意関係を証明できず,公理を生成できなかった例 ・公理の過剰生成を防ぐためには,文脈に合わせて正しく公理の確信度を 算出するように改善する必要がある(ID:1941)
5. まとめ ・本研究では,文を高階述語論理式に変換し,文間の含意関係を 高階論理の推論過程に関する情報から文間の関連性に寄与する 特徴量を抽出し,文間の関連性を学習する手法を提案した. ・SICKデータセットでの評価では最高精度を達成した ・統語解析,意味合成,論理推論において改善策を検討していく ・質問応答などの自然言語処理タスクへの適用が期待される 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}