•The store doesn't know anything about the the key or value •The store doesn't know anything about the insides of the value •Operations • Set, get, or delete a key-value pair
Documents are made up of named fields • Fields may or may not have type definitions • e.g. XSDs for XML stores, vs. schema-less JSON stores •Can create "secondary indexes" • These provide the ability to query on any document field(s) •Operations: • Insert and delete documents • Update fields within documents
data for a column is kept together • An index provides a means to get a column value for a record •Operations: • Get, insert, delete records; updating fields • Streaming column data in and out of Hadoop
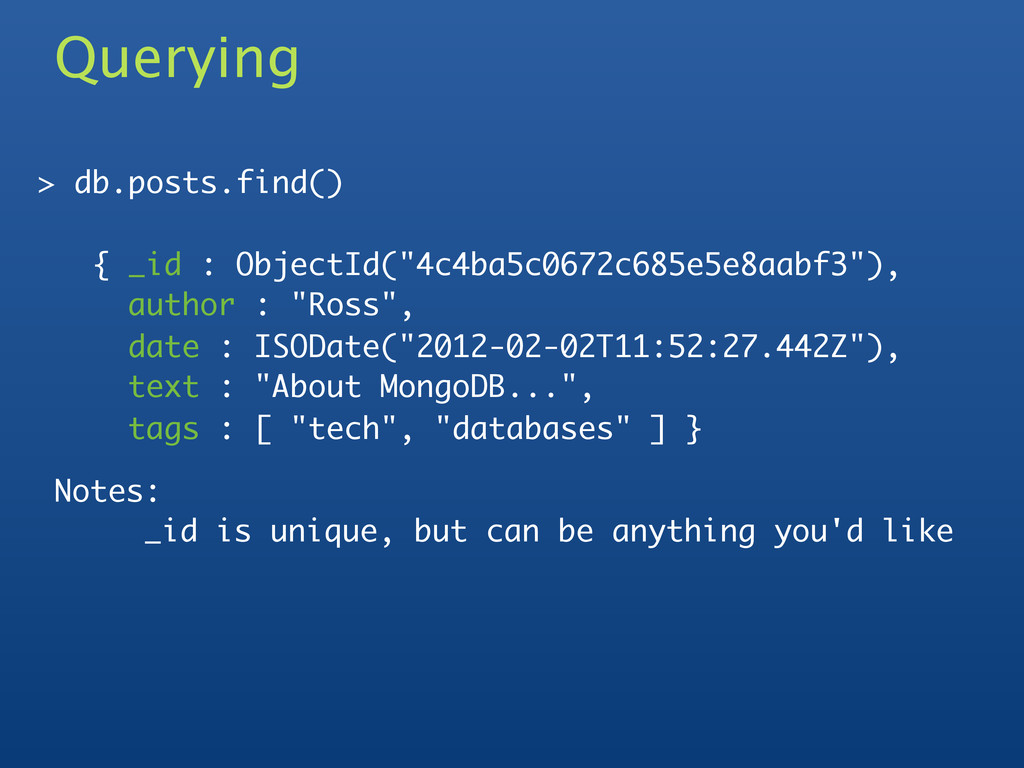
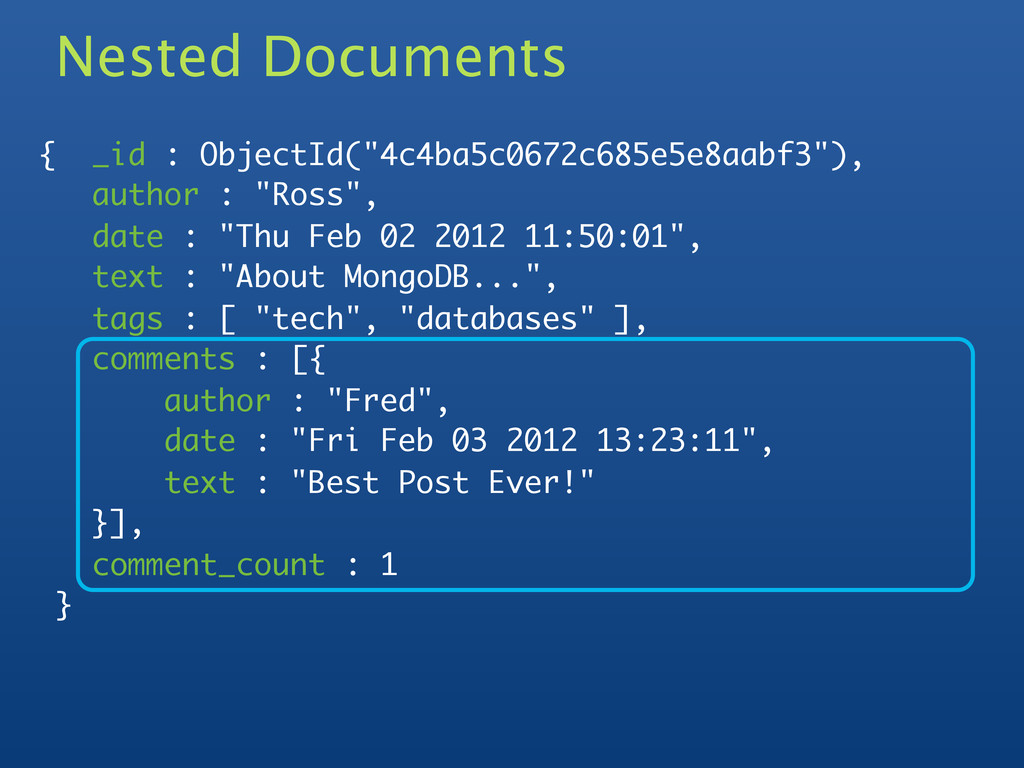
: ISODate("2012-02-02T11:52:27.442Z"), text : "About MongoDB...", tags : [ "tech", "databases" ] } Querying Notes: _id is unique, but can be anything you'd like
> db.posts.find({author: 'Ross'}) { _id : ObjectId("4c4ba5c0672c685e5e8aabf3"), author: "Ross", ... } Secondary Indexes Create index on any Field in Document
Find points near a given point • Find points within a polygon/sphere // geospatial index > db.posts.ensureIndex( "author.location": "2d" ) > db.posts.find( "author.location" : { $near : [22, 42] } )
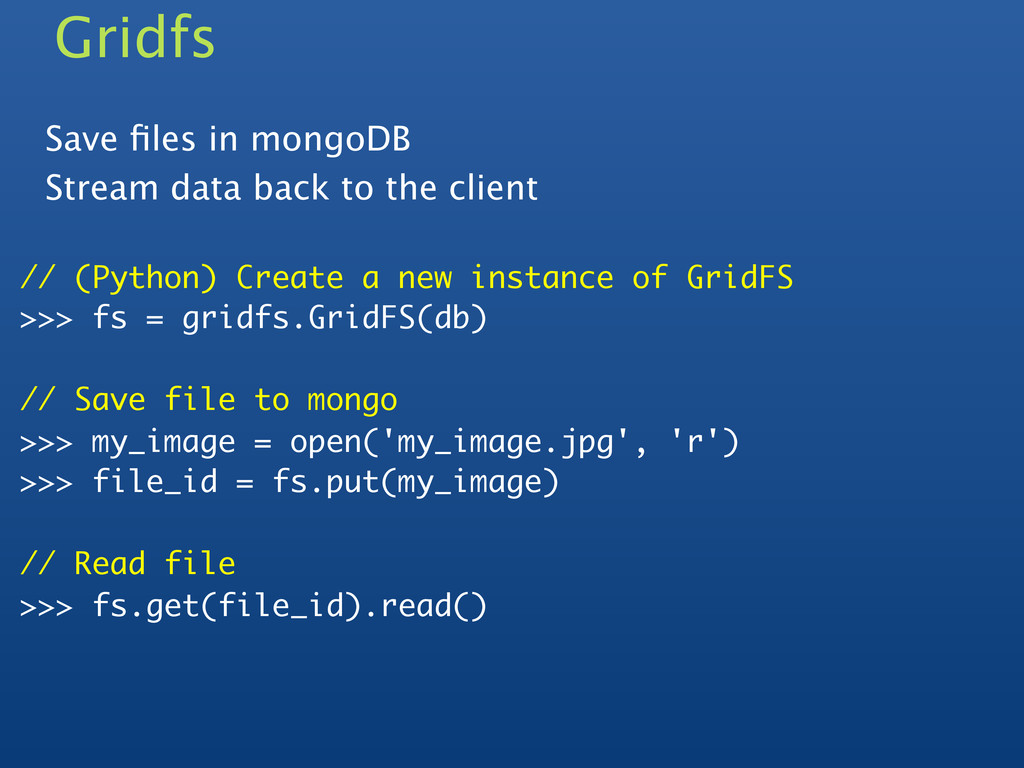
= gridfs.GridFS(db) // Save file to mongo >>> my_image = open('my_image.jpg', 'r') >>> file_id = fs.put(my_image) // Read file >>> fs.get(file_id).read() Gridfs Save files in mongoDB Stream data back to the client
• Sharding – Read and write scalability • Collections are sharded • Each shard is served by its own replica set • Shard key ranges are automatically balanced
![Ross Lawley - [email protected] @rossc0 Introduction](https://files.speakerdeck.com/presentations/4f30411d2ed25800220039ff/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}