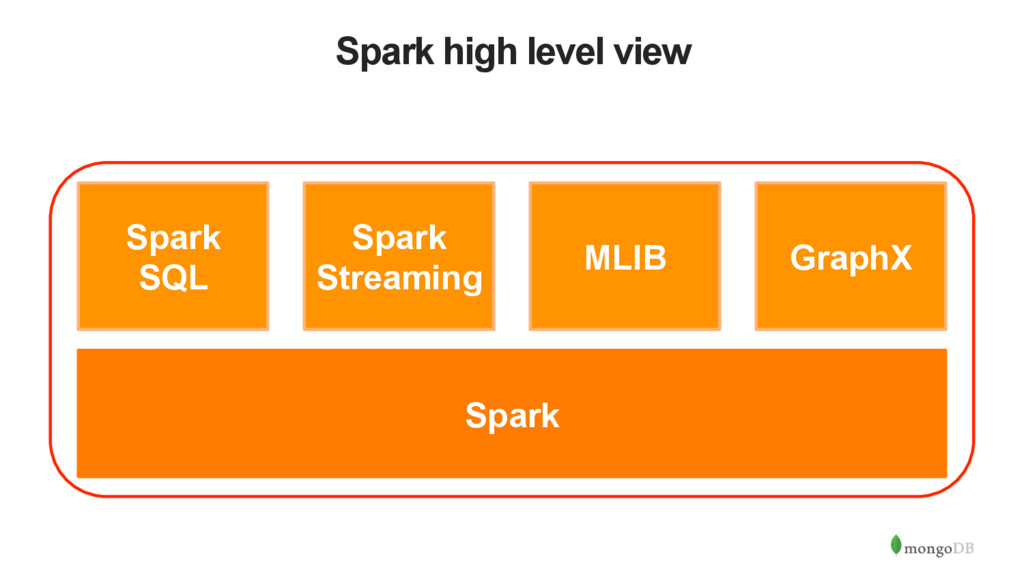
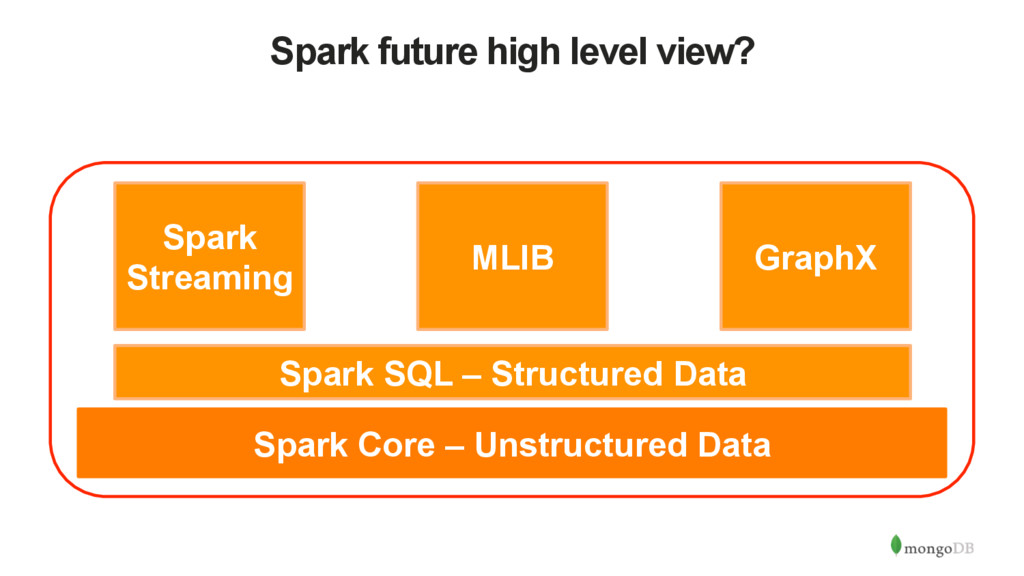
clusters • Makes it easy and fast to process large datasets • APIs in Scala, Python, Java, R • Libraries for SQL, streaming, machine learning, … • It’s fundamentally different to what’s come before
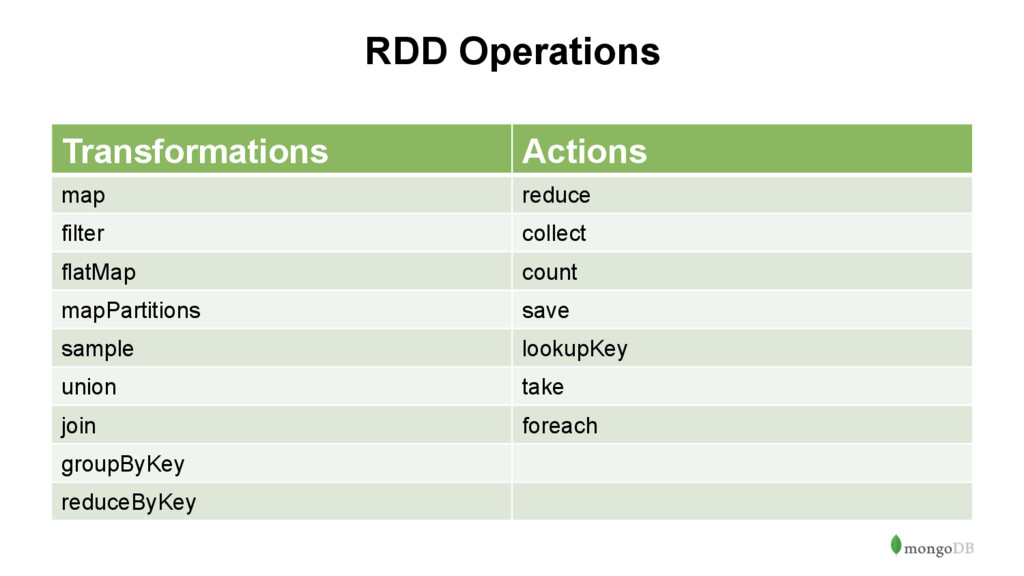
a collection of elements that is immutable, distributed and fault-tolerant. • Transformations can be applied to a RDD, resulting in new RDD. • Actions can be applied to a RDD to obtain a value. • RDD is lazy.
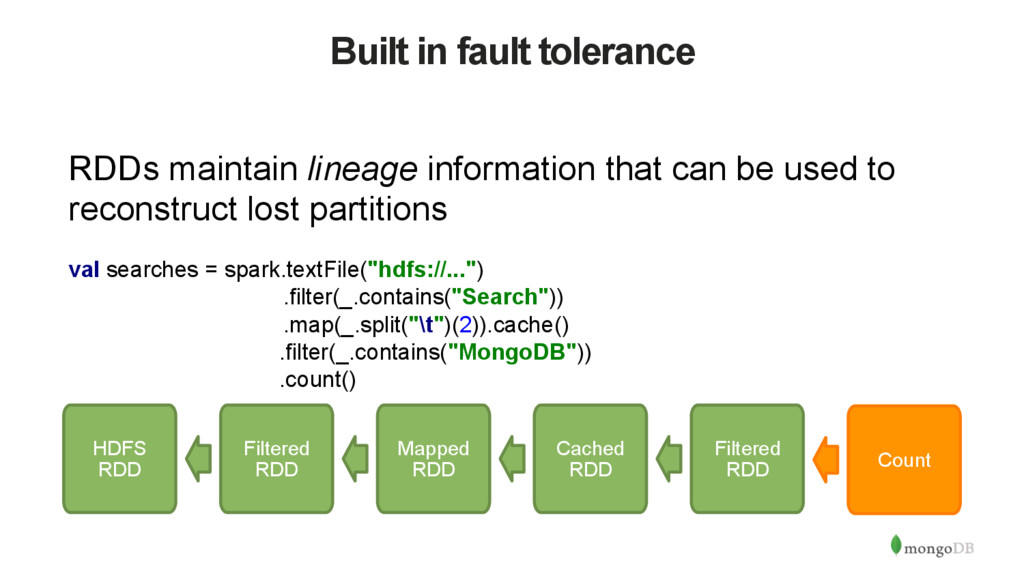
be used to reconstruct lost partitions val searches = spark.textFile("hdfs://...") .filter(_.contains("Search")) .map(_.split("\t")(2)).cache() .filter(_.contains("MongoDB")) .count() Mapped RDD Filtered RDD HDFS RDD Cached RDD Filtered RDD Count
Oracle to MongoDB and Apache Spark to Support 100x performance improvement Problem Why MongoDB Results Problem Solution Results China Eastern targeting 130,000 seats sold every day across its web and mobile channels New fare calculation engine needed to support 20,000 search queries per second, but current Oracle platform supported only 200 per second Apache Spark used for fare calculations, using business rules stored in MongoDB Fare calculations written to MongoDB for access by the search application MongoDB Connector for Apache Spark allows seamless integration with data locality awareness across the cluster Cluster of less than 20 API, Spark & MongoDB nodes supports 180m fare calculations & 1.6 billion searches per day Each node delivers 15x higher performance and 10x lower latency than existing Oracle servers MongoDB Enterprise Advanced provided Ops Manager for operational automation and access to expert technical support
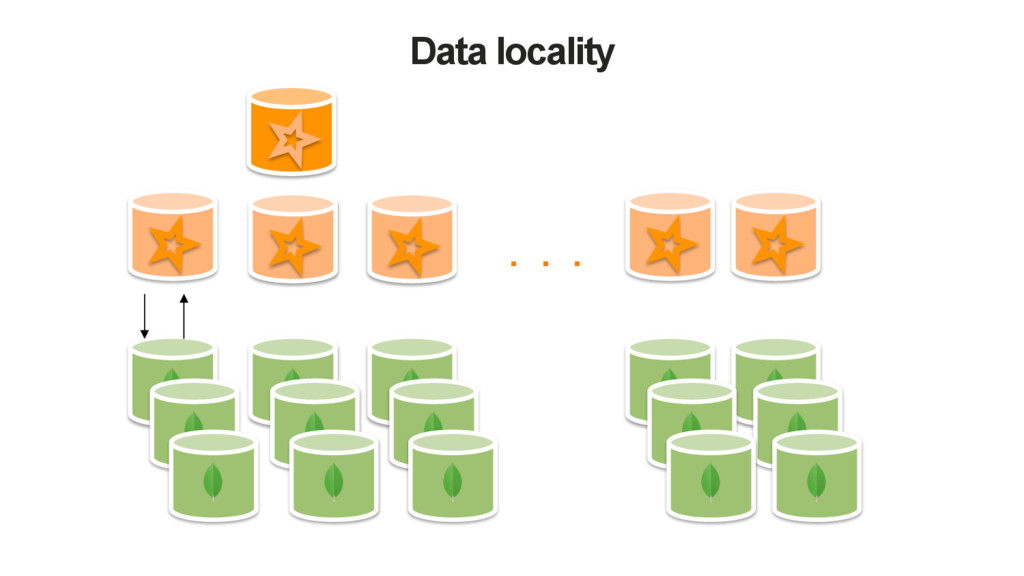
Partition the data 3. Calculate the Partitions . 4. Get the preferred locations and allocate workers 5. For each partition: i. Queries and returns the cursor ii. Iterates the cursor and sums up the data 6. Finally, the Spark application returns the sum of the sums.
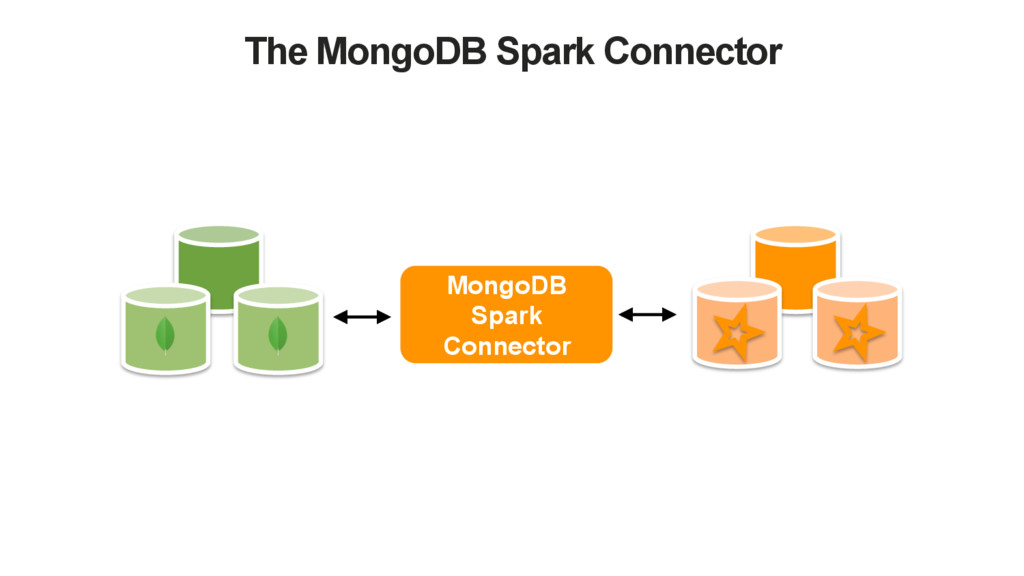
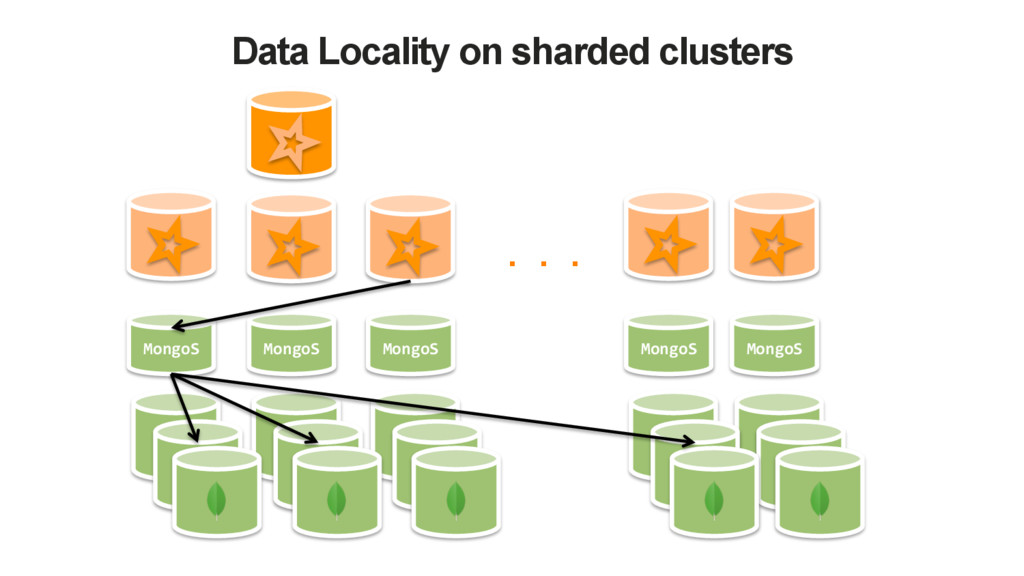
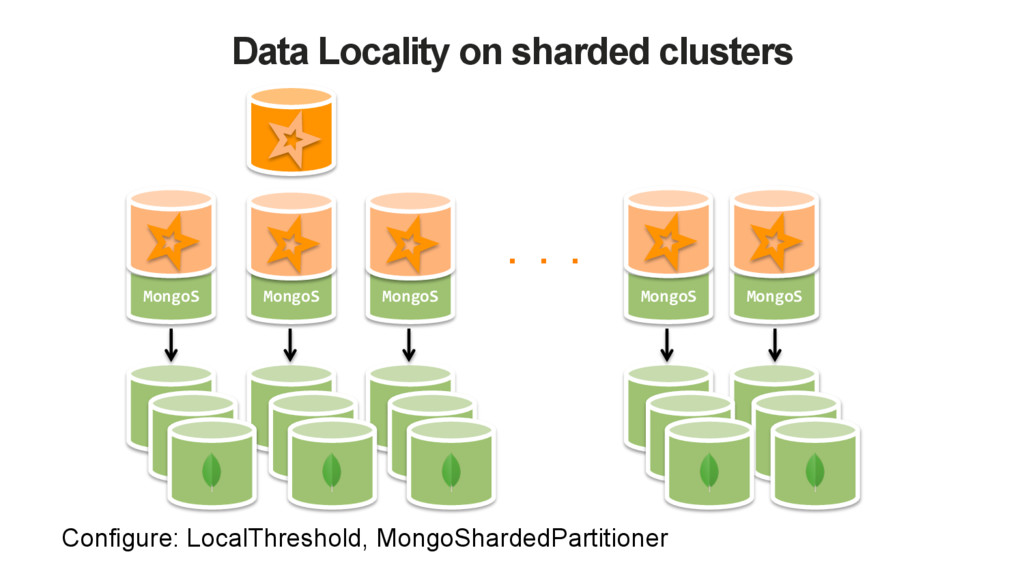
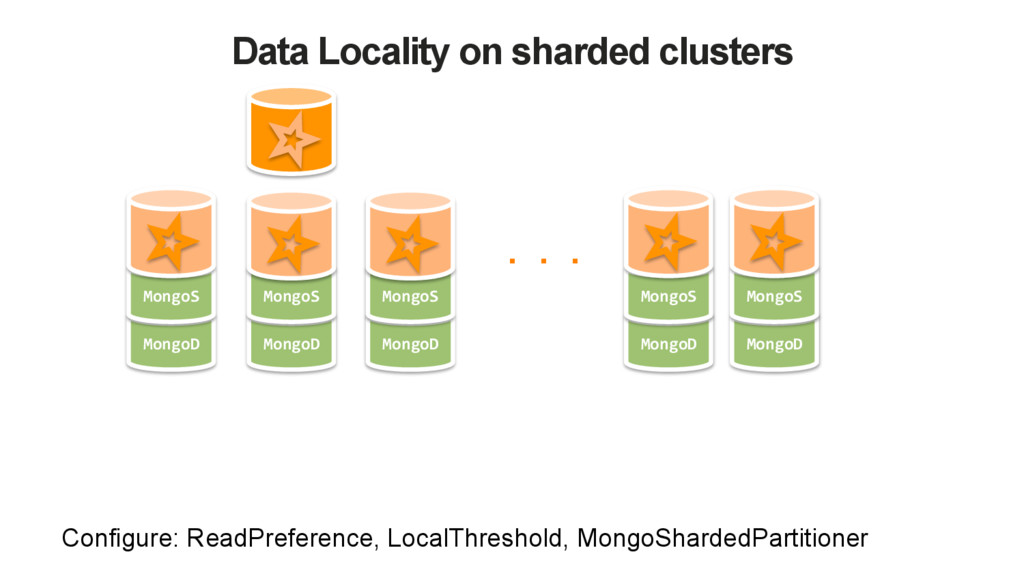
extendable. Configure via Spark Conf, Options or Read/WriteConfig instances • Read Configuration • URI, database name and collection name • Read Preference, Read Concern • Partitioner • Sample Size (for inferring the schema) • Local threshold (for choosing the MongoS) • Write Configuration • URI, database name and collection name • Write concern • Local threshold (for choosing the MongoS)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
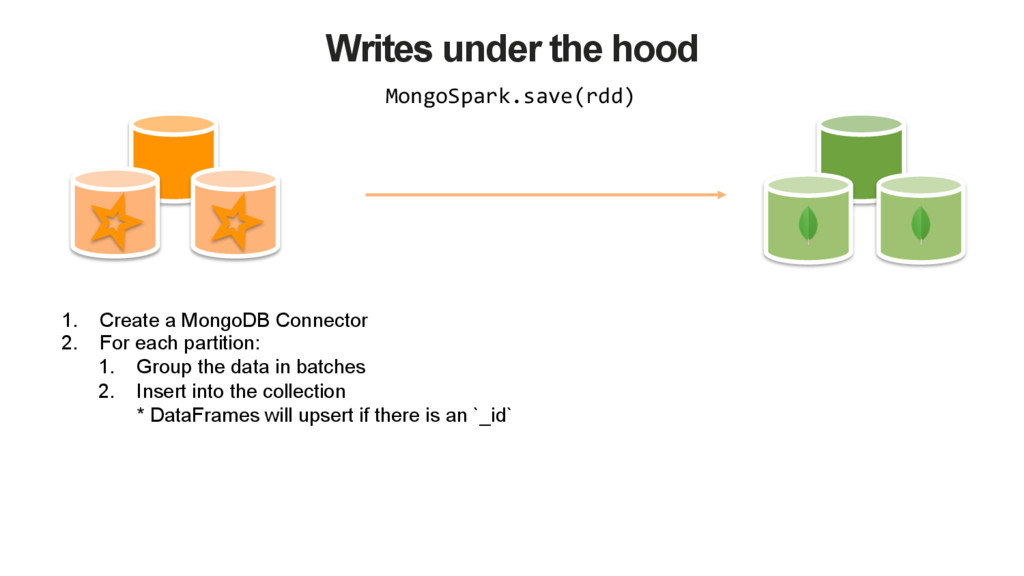
![Reads under the hood MongoSpark.load(sparkSession).count() 1. Create a MongoRDD[Document] 2.](https://files.speakerdeck.com/presentations/34e6c7d3d2094225a9ba63967984966f/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}