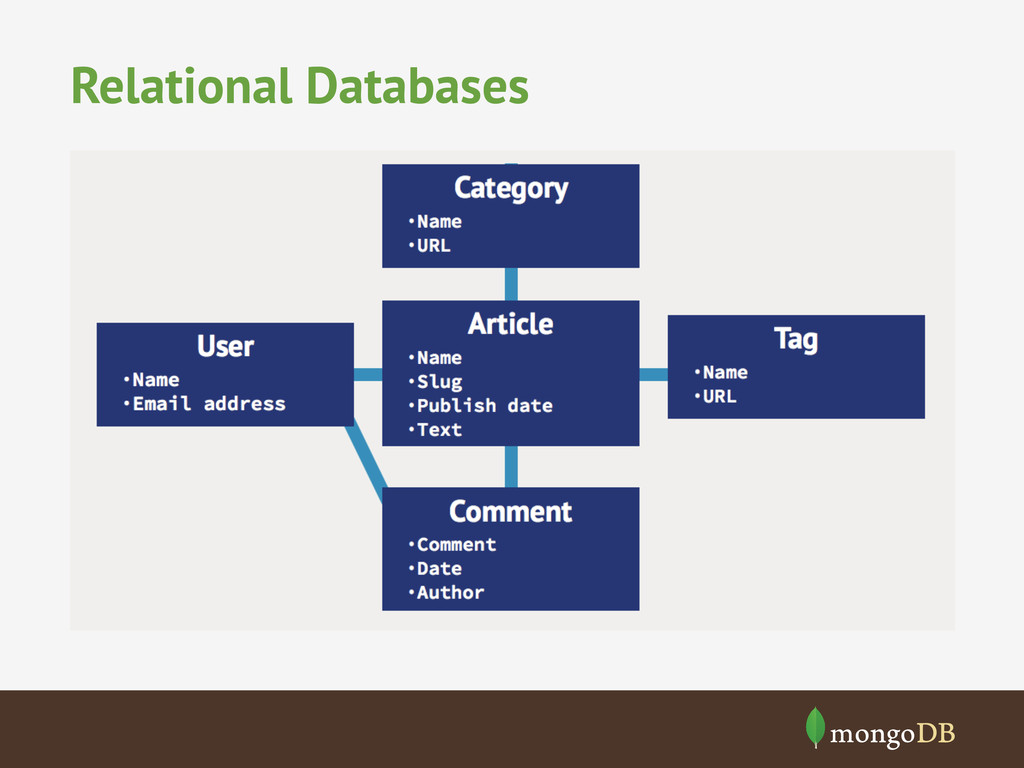
schemas have led to powerful query capabilities • Data is optimised for joins and storage • Robust ecosystem of tools, libraries, integrations • 40+ years old!
Volume – Vast amounts of data being collected • Variety – Evolving data – Uncontrolled formats, no single schema – Unknown at design time • Velocity – Inbound data speed – Fast read/write operations – Low latency
data formats • Scaling via big iron or custom data marts/partitioning schemes • Schema must be known at design time • Impedance mismatch with agile development and deployment techniques • Doesn’t map well to native language constructs
works for RDBMSs – Rich data models, ad-hoc queries, full indexes • Drop what doesn’t work well – Multi-row transactions, complex joins • Do not homogenize APIs • Match agile development and deployment workflows
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
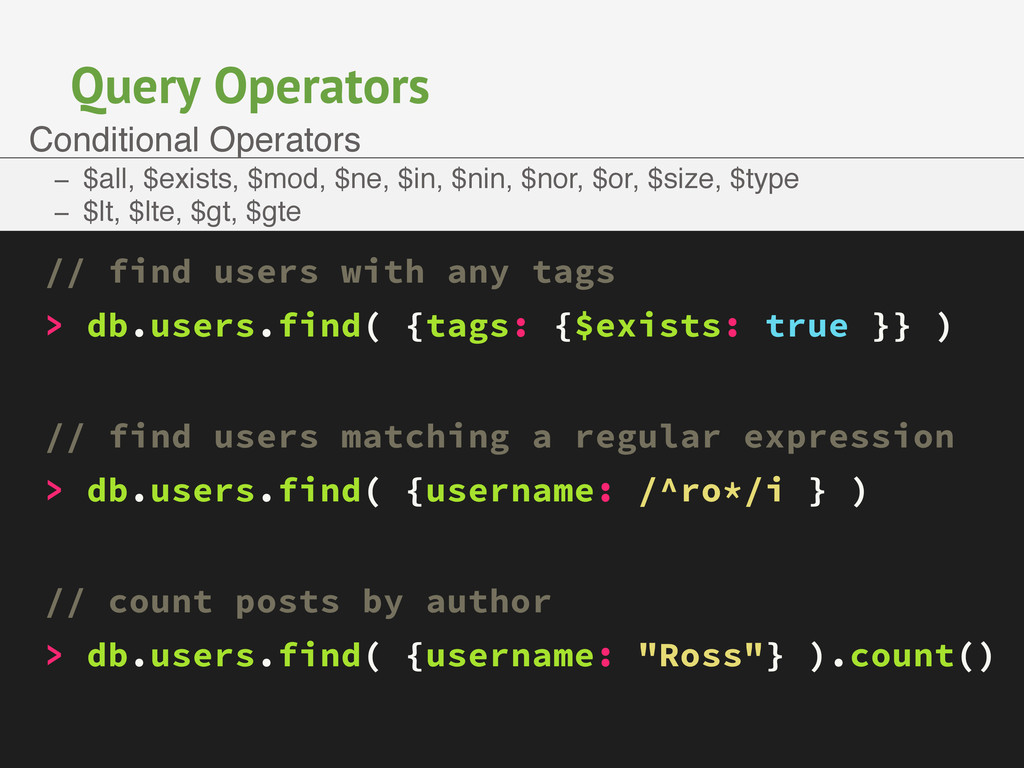{kind=link}
![> tags = ["superuser", "db_admin"] > address = { street:](https://files.speakerdeck.com/presentations/4f71fa3013c90131f9fe3aacfc01551e/slide_24.jpg){kind=link}
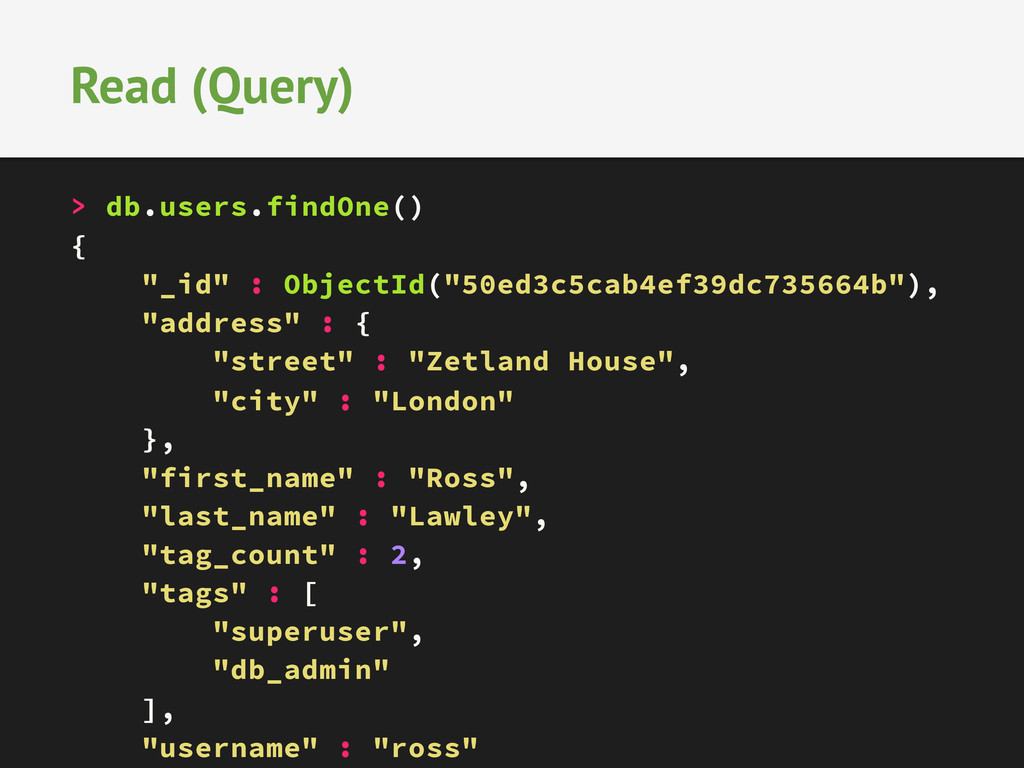{kind=link}
{kind=link}
{kind=link}
{kind=link}