Spark may have taken the big data world by storm by being super fast and easy to use. However, by design, Spark is not a datastore and only supports a limited number of sources for data. So how can you integrate your datasource with Spark? In this talk we’ll look at how to successfully write your own Spark connector. We’ll look in depth at the the lessons learnt writing a new Spark Connector for MongoDB, and how you can apply those lessons to any potential data source as you build your own connector. At the core of Spark is the RDD, so the first step in building your connector is being able to create an RDD and partition data efficiently. Initially, it’s easiest to focus on Scala, but we’ll look at how to expand and support Java at the same time, and why it’s a good idea. We’ll look at how you can test the code and prove the connector works before expanding it to other Spark features. The next step is to expose the connector to Spark’s fastest growing features; Spark Streaming and Spark SQL. Once we have a fully functioning Spark Connector for the JVM, we’ll look at how easy it is to extend it to support Python and R.
{kind=link}
{kind=link}
{kind=link}
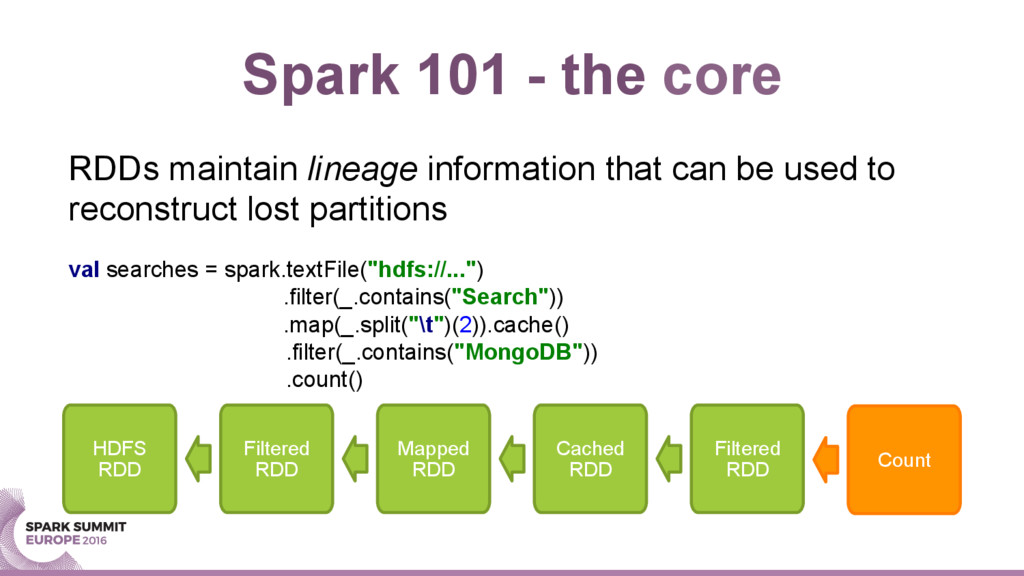{kind=link}
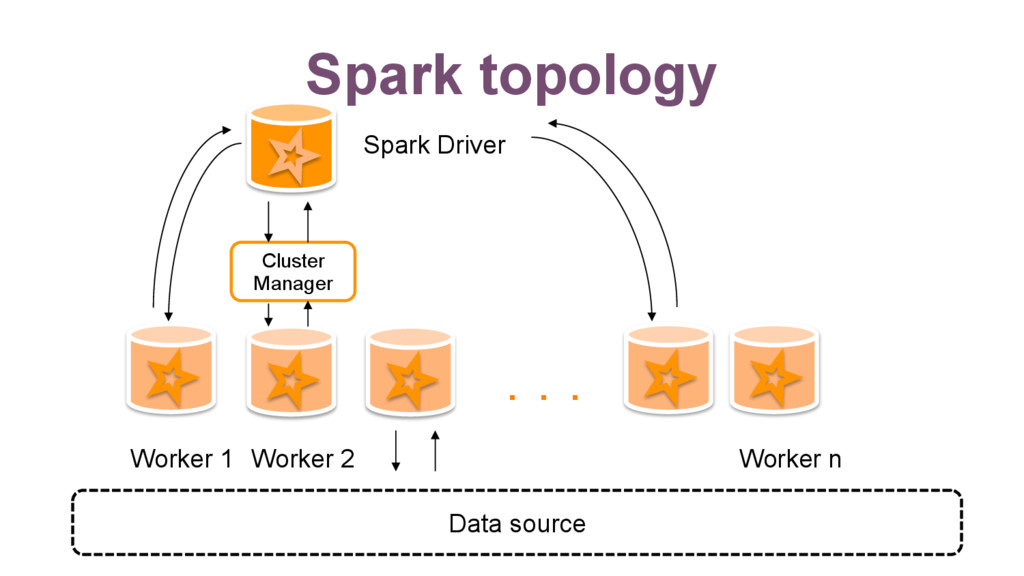{kind=link}
{kind=link}
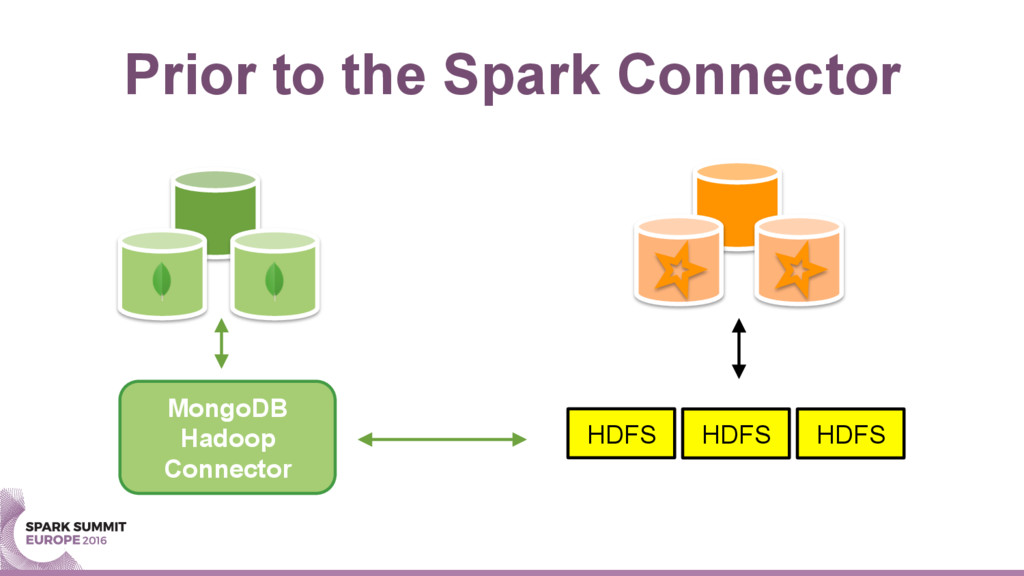{kind=link}
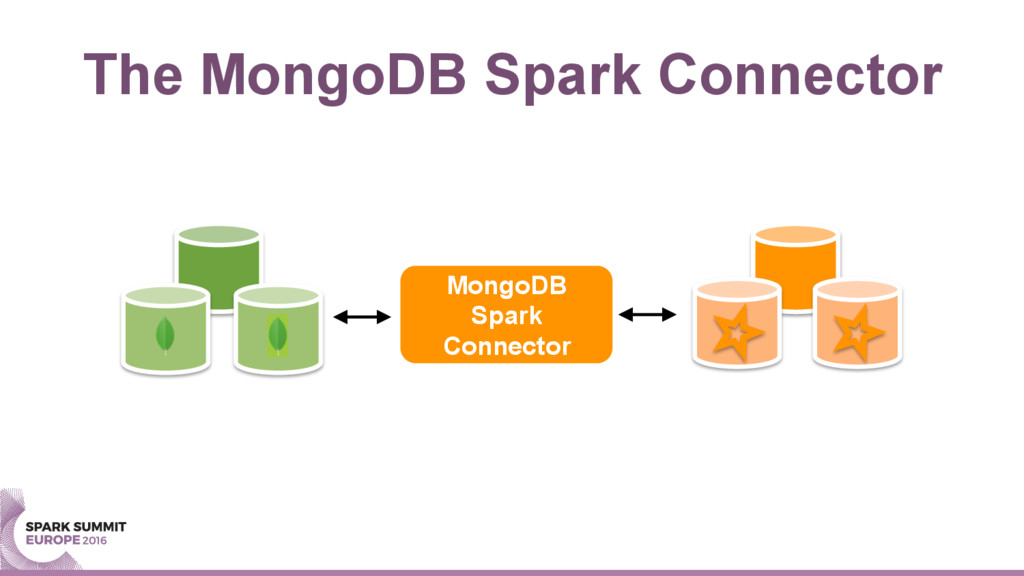{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Implement RDD[T] class • Partition the collection • Optionally provide](https://files.speakerdeck.com/presentations/1bdddfb6cf214472b8c4248f40c1d138/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Reads under the hood MongoSpark.load(sparkSession).count() 1. Create a MongoRDD[Document] 2.](https://files.speakerdeck.com/presentations/1bdddfb6cf214472b8c4248f40c1d138/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
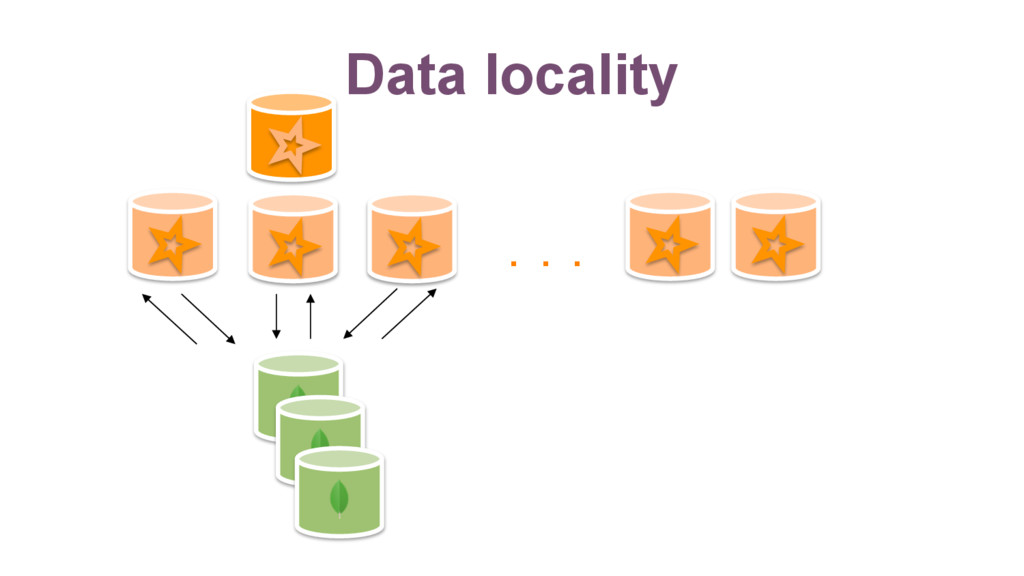{kind=link}
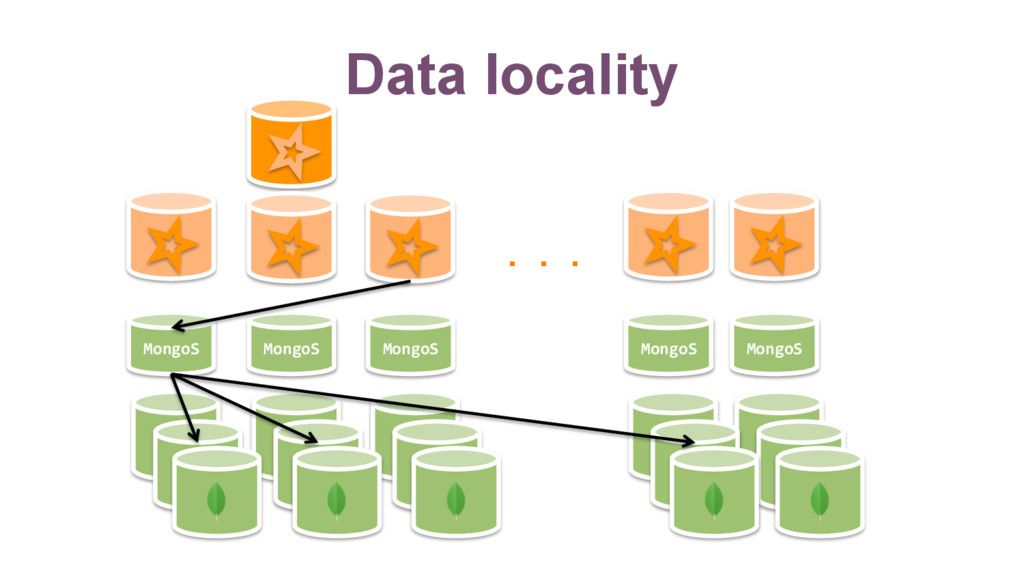{kind=link}
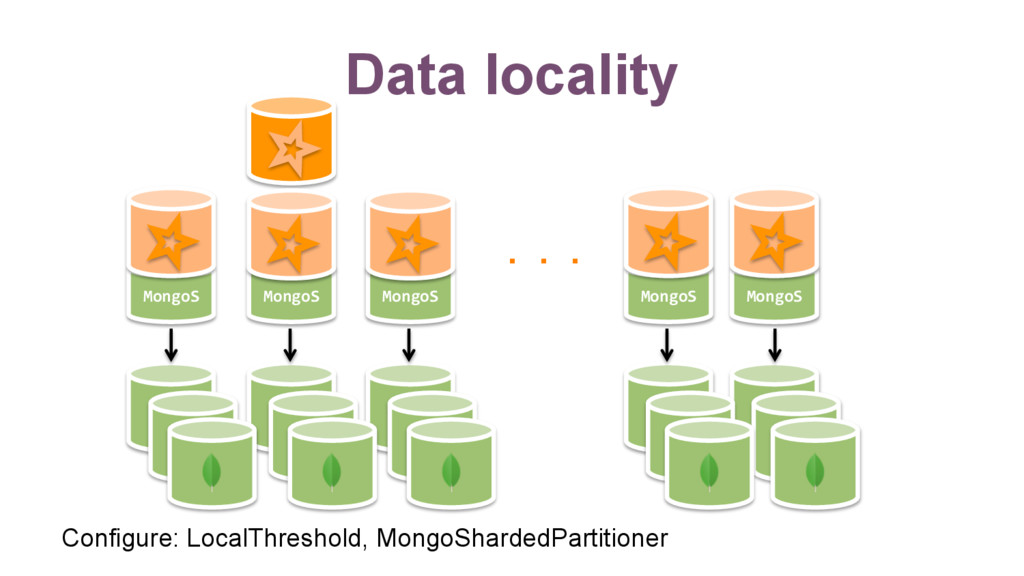{kind=link}
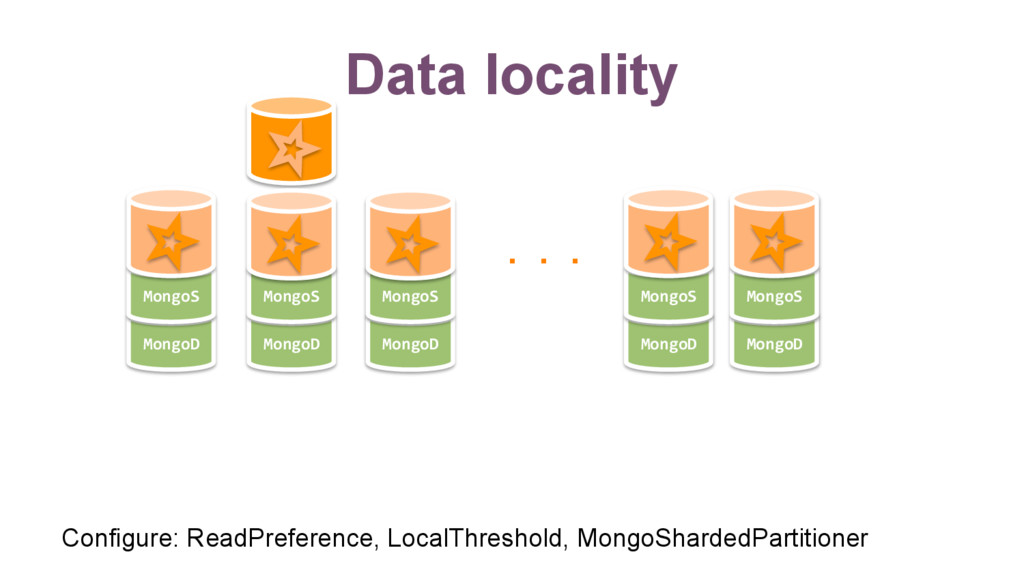{kind=link}
{kind=link}
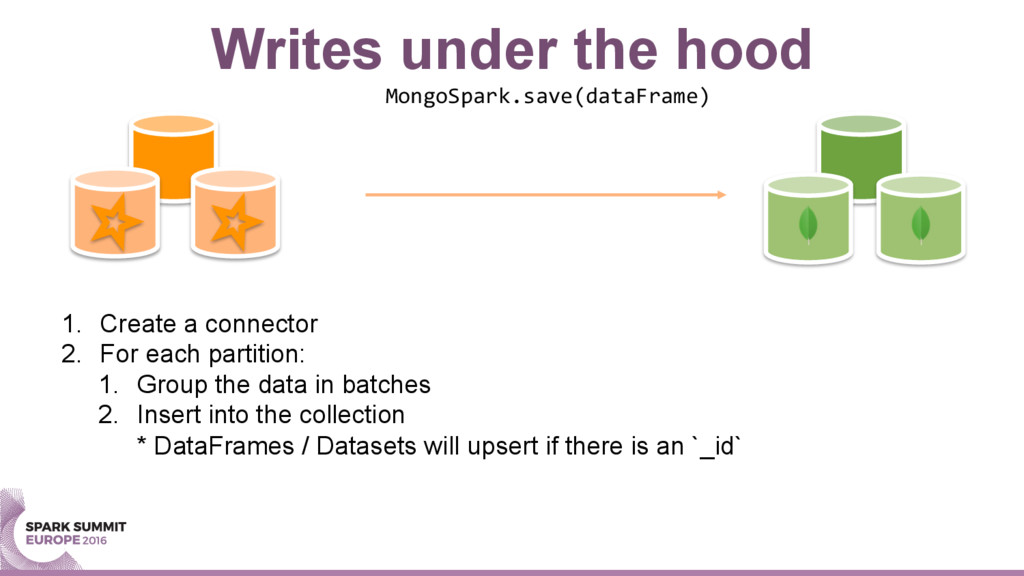{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Structured data in Spark • DataFrame == Dataset[Row] – RDD[Row]](https://files.speakerdeck.com/presentations/1bdddfb6cf214472b8c4248f40c1d138/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}