Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Understanding and Improving Sequence-to-Sequenc...
Search
hajime kiyama
August 31, 2023
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Understanding and Improving Sequence-to-Sequence Pretraining for Neural Machine Translation
Japanese explanation
hajime kiyama
August 31, 2023
More Decks by hajime kiyama
See All by hajime kiyama
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
330
Idiosyncrasies in Large Language Models
rudorudo11
0
63
People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text
rudorudo11
0
280
Analyzing Continuous Semantic Shifts with Diachronic Word Similarity Matrices.
rudorudo11
0
230
Using Synchronic Definitions and Semantic Relations to Classify Semantic Change Types
rudorudo11
0
110
Analyzing Semantic Change through Lexical Replacements
rudorudo11
0
370
意味変化分析に向けた単語埋め込みの時系列パターン分析
rudorudo11
1
210
Bridging Continuous and Discrete Spaces: Interpretable Sentence Representation Learning via Compositional Operations
rudorudo11
0
340
Word Sense Extension
rudorudo11
0
160
Featured
See All Featured
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
Design in an AI World
tapps
1
260
Amusing Abliteration
ianozsvald
1
220
Making the Leap to Tech Lead
cromwellryan
135
10k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
920
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
280
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
For a Future-Friendly Web
brad_frost
183
10k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
490
Transcript
論文紹介 ACL2022 発表者 : B4 木山 朔 発表日 : 10/24
1 Understanding and Improving Sequence-to-Sequence Pretraining for Neural Machine Translation
Introduction • Seq2Seqを事前学習したモデル(mBART [Liu+2020])がMTでSOTA • Seq2Seqの事前学習の性質の理解と改良 ◦ Seq2Seqの事前学習 vs Encoderのみの事前学習の分析
▪ Decoderを同時に学習する上での影響を調査 ◦ 新たな手法の提案 ▪ in-domain pretraining:ドメインに特化した事前学習 ▪ input adaptation in fine-tuning:原文にノイズを加え原文を出力させるよう微調整 2
Understanding Seq2Seq Pretraining • baseline:Transformer-Big • model:mBART25 [Liu+2020] ◦ パラメータ更新の有無で
3種類を比較 ▪ Encoder, Decoderともにfreeze ▪ Decoderのみfreeze ▪ freezeなし ◦ 語彙サイズは同じ ◦ pretrain data:ComonCrawl (CC) • dataset:WMT19 En-De, WMT16 En-Ro, IWSLT17 En-Fr ◦ En-Deに関してはEn-Ro, En-Frのサイズに合わせた小規模なものも使用 ▪ En-De(S)と表記 3
Impact of Jointly Pretrained Decoder 1/4 • translation performance ◦
Enc:×,Dec:×はvocab-sizeが大きいため学習が困難 ◦ 大規模なデータでは Decoderの事前学習が効いていない ▪ 「事前学習は大規模データにはあまり効果的でない」 という共通認識と一致 ◦ 小規模なデータでは Decoderの事前学習が効いている 4
Impact of Jointly Pretrained Decoder 2/4 • example ◦ Decoderも事前学習したモデル
▪ 良い翻訳だが語順が refと異なる • BLEUが高くない原因? • 大規模データでの上がり幅に関係 ▪ 翻訳ミスの減少 • 特に小規模データにみられる 5 empiricalに上記二つを検証
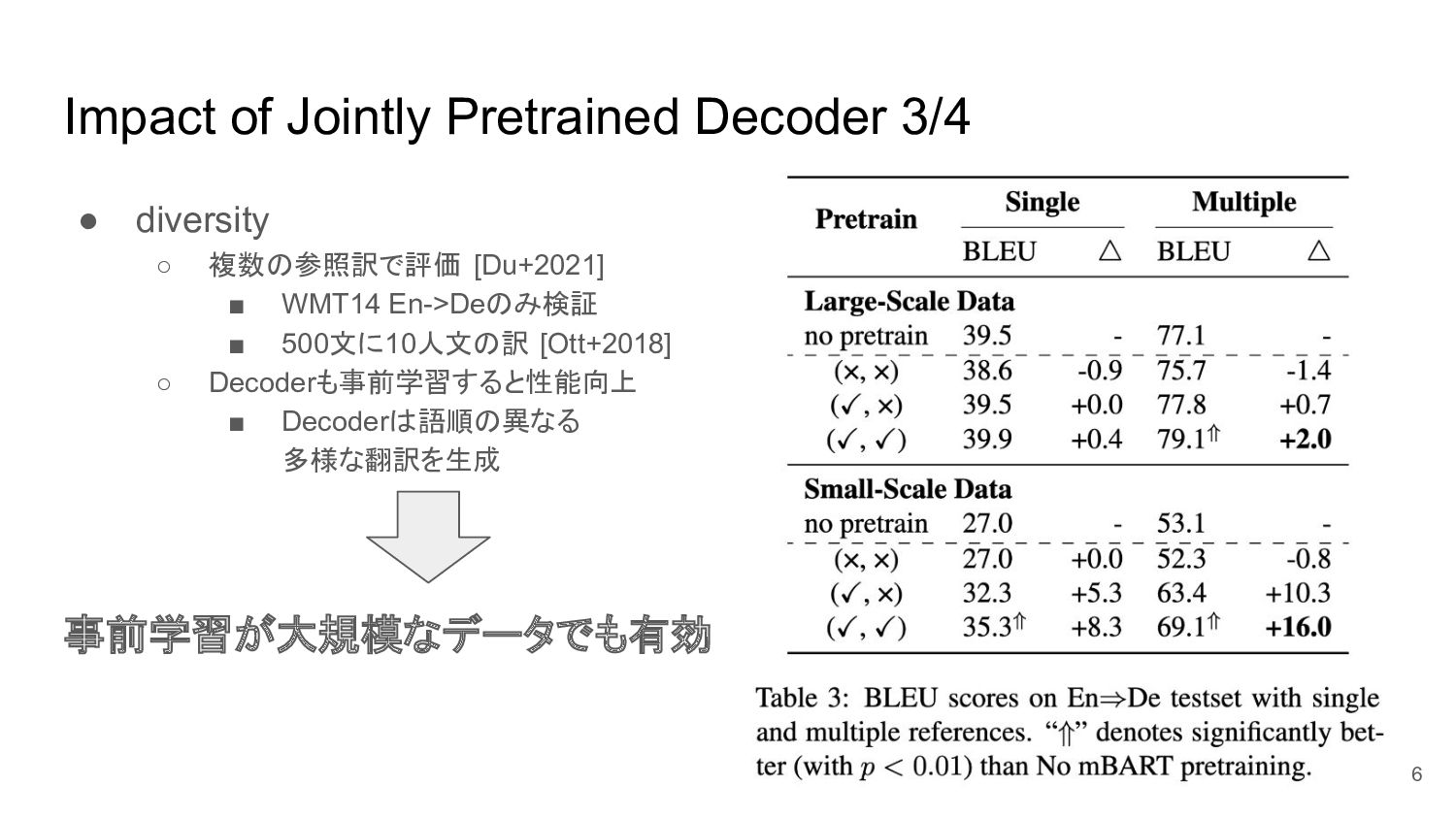
Impact of Jointly Pretrained Decoder 3/4 • diversity ◦ 複数の参照訳で評価
[Du+2021] ▪ WMT14 En->Deのみ検証 ▪ 500文に10人文の訳 [Ott+2018] ◦ Decoderも事前学習すると性能向上 ▪ Decoderは語順の異なる 多様な翻訳を生成 6 事前学習が大規模なデータでも有効
Impact of Jointly Pretrained Decoder 4/4 • adequacy ◦ 二人のアノテータに人手評価
▪ WMT19 De->En の100文に対し実施 • Under translation • Mis translation • Over translation ◦ 小規模データでのEncoderのみ事前学習 ▪ Over translationが発生 ▪ ソースの文脈の影響が大きすぎる? ◦ 大規模データでは発生しない ▪ in-domainデータが多いため 7
Pretraining and Finetuning Discrepancy 1/6 • Seq2Seqのside-effect ◦ 事前学習と微調整における不一致 ▪
Domain Discrepancy • 事前学習:general domain • 微調整:specific domain ◦ domainの適応が必要となる ◦ Seq2Seq事前学習とスクラッチ学習における不一致 ▪ Objective Discrepancy • 事前学習+微調整:入力文の再構築を学習 • スクラッチ学習:ある言語から別言語への文の翻訳を学習 ◦ 学習の目的が異なる • WMT19 En-De(S)のtest-dataの結果を報告 8
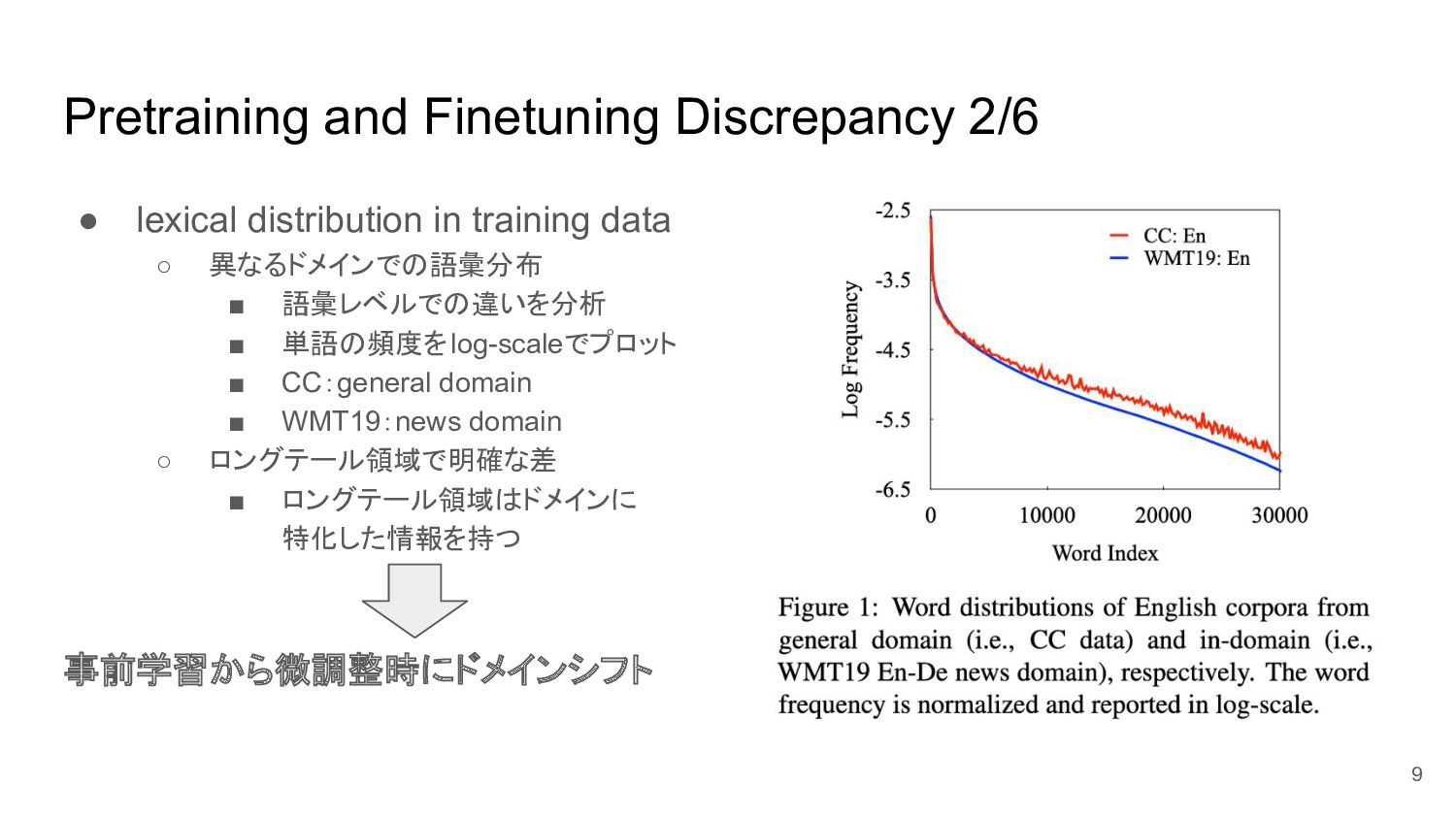
Pretraining and Finetuning Discrepancy 2/6 • lexical distribution in training
data ◦ 異なるドメインでの語彙分布 ▪ 語彙レベルでの違いを分析 ▪ 単語の頻度をlog-scaleでプロット ▪ CC:general domain ▪ WMT19:news domain ◦ ロングテール領域で明確な差 ▪ ロングテール領域はドメインに 特化した情報を持つ 事前学習から微調整時にドメインシフト 9
Pretraining and Finetuning Discrepancy 3/6 10 CC WMT news
domain • domain classifier for test data ◦ テストデータが学習データと同じドメインに従うか? ◦ ドメイン分類器を構築 ▪ WMT19 En-Deの学習データとCCがbase ▪ それぞれ1.0Mのサンプルを取り分類器を学習 ◦ ほとんどの文がnews domainと認識 ▪ 学習データとテストデータは同じドメイン
Pretraining and Finetuning Discrepancy 4/6 • model uncertainty [Ott+2018] ◦
各time-stepにおける文対の平均確率を計算 ◦ distractor:CCデータからrefと長さが一致する文 ▪ 意味的にはソースと不一致 • Decoderの事前学習の影響 ◦ 最初の数stepでモデルの確らしさが大幅に向上 ▪ モデルがソースの文脈に大きく支配 ▪ over-estimation問題を誘発している? • distractorでも向上している... 11
Pretraining and Finetuning Discrepancy 5/6 • hallucination under Perturbation ◦
hallcination:入力とは無関係な流暢な出力 ◦ ノイズの多い入力下でのモデルを評価 [Lee+2018] ▪ FPI:ソース系列に単一の追加入力トークンを挿入 (First Position Insertion) ▪ RSM:ノイズの多い入力をシミュレート (Random Span Masking) ◦ hallcinationの割合をHUPとして算出 ▪ 参照訳と摂動されていない文の翻訳間での BLEUの差が5より大きく,摂動された文と されていない文の翻訳間の BLEUの差が3以下 ◦ 傾向 ▪ Decoderも同時に学習すると HUPが高い • hallcinationが多い 12
Pretraining and Finetuning Discrepancy 6/6 • beam search problem ◦
beam-sizeが大きくなるとモデル性能が低下 [Tu+2017] ◦ over-estimationがこの問題を引き起こしている [Ott+2018][Cohen+2019] • analysis ◦ Seq2Seq事前学習でもbeam-search-problemを検証 ◦ 異なるbeam-sizeにおける出力のcopy tokenの比率も検証 ▪ ソースを翻訳せずにターゲットにコピーする比率 ◦ Decoderも事前学習すると上記の傾向が増加 ▪ beam-sizeが上がるとcopyも増加 • 関連がある 13
Improving Seq2Seq Pretraining • In domain Pretraining ◦ in-domainの単言語データで学習を継続 ▪
テキストのスパンを削除しマスクトークンへ • ポアソン分布に従ってスパン長を randomにして35%の単語をマスク ▪ 各インスタンス内での文の順序を入れ替える ◦ ドメインシフトの軽減を期待 ◦ data:NewsCrawl, TED, OpenSubtitle • Input Adaptation in Finetuning ◦ 微調整時にソースにノイズを加え,ターゲットをソースそのままにする ▪ ソースの単語の10%にノイズを加える ▪ 1:9でノイズのある/ないデータを組み合わせ微調整 ◦ モデルの頑健性の向上を期待 ▪ 入力に摂動を加えover-estimationの緩和を狙う 14
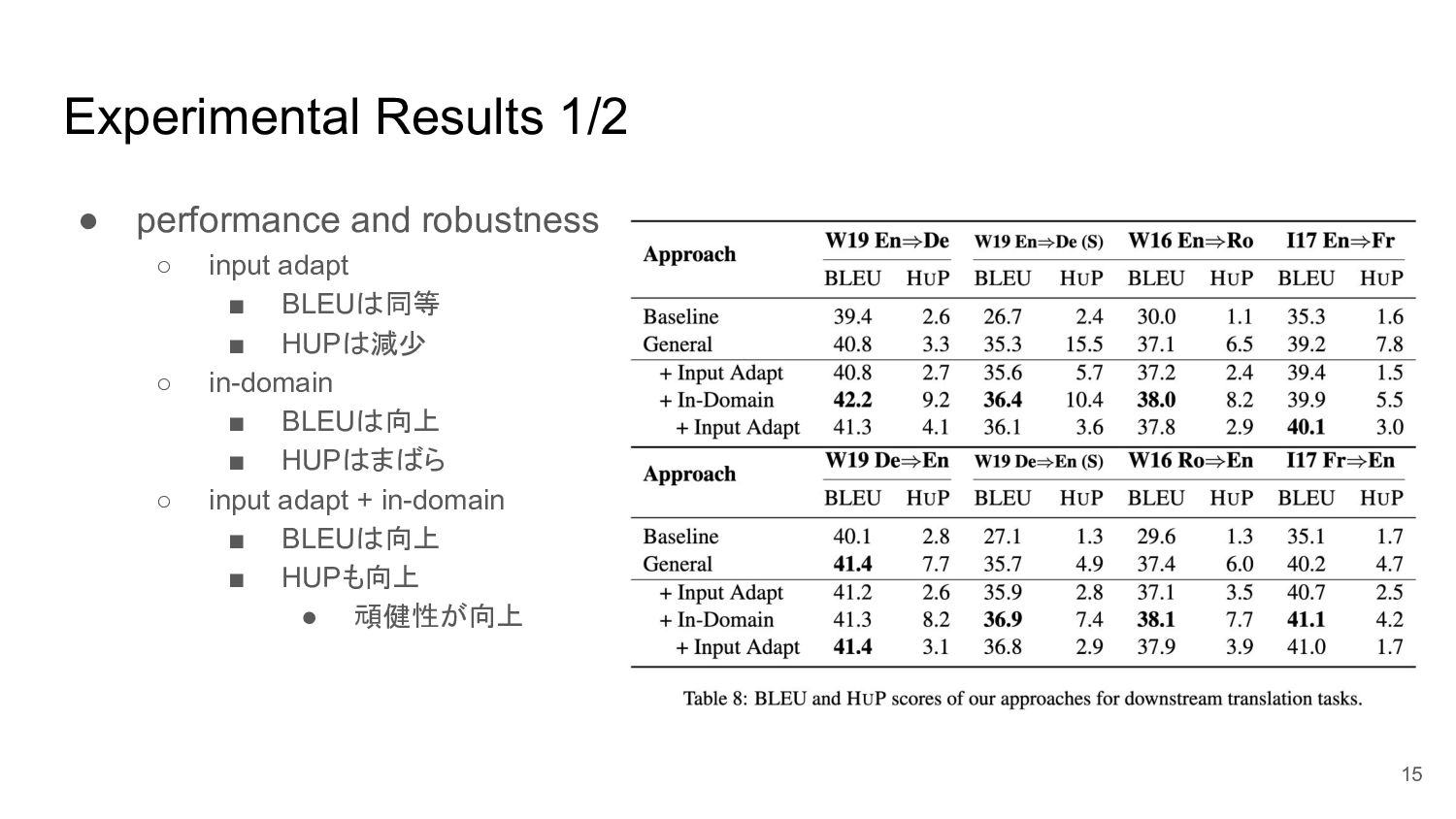
Experimental Results 1/2 • performance and robustness ◦ input adapt
▪ BLEUは同等 ▪ HUPは減少 ◦ in-domain ▪ BLEUは向上 ▪ HUPはまばら ◦ input adapt + in-domain ▪ BLEUは向上 ▪ HUPも向上 • 頑健性が向上 15
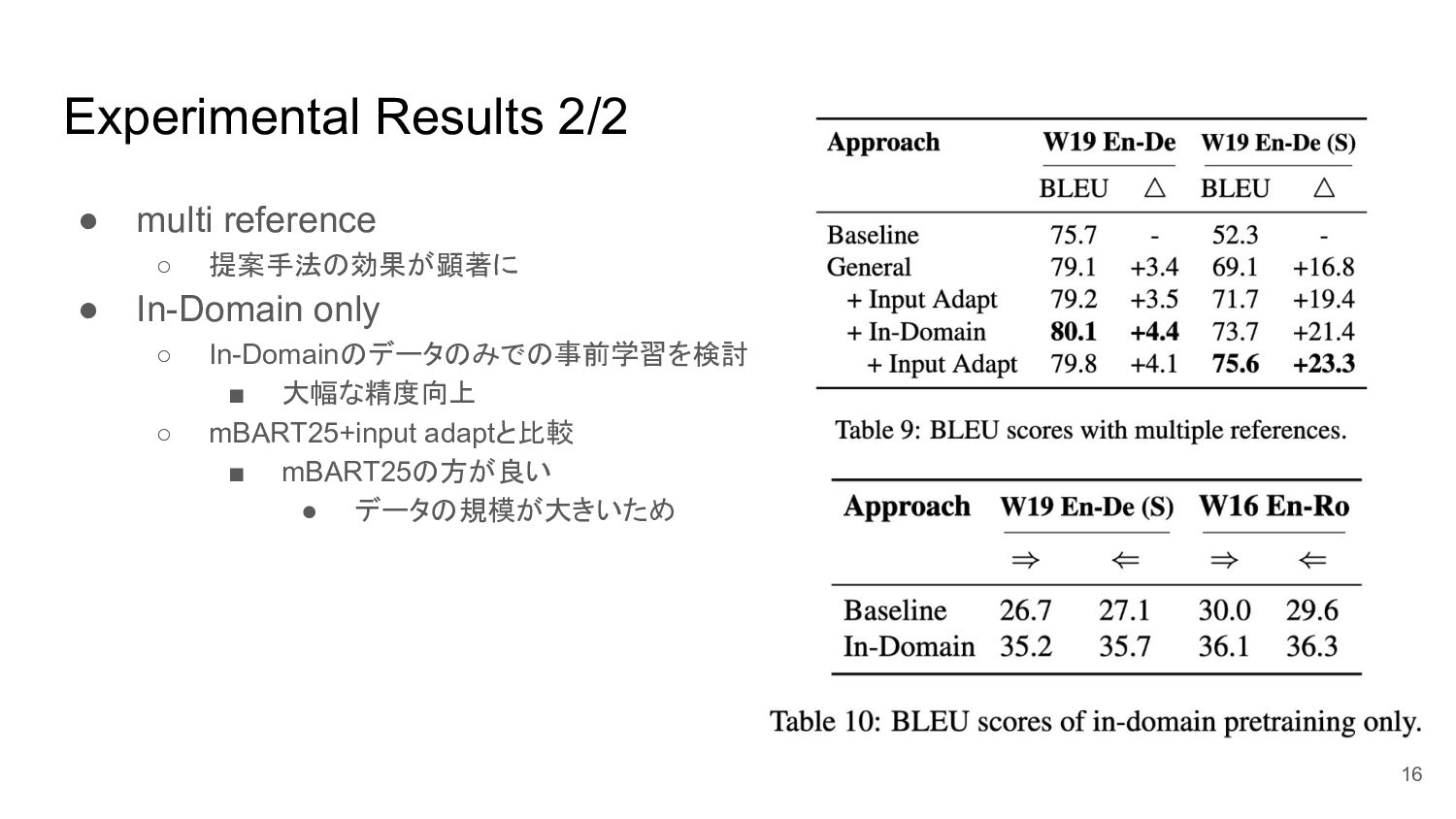
Experimental Results 2/2 • multi reference ◦ 提案手法の効果が顕著に • In-Domain
only ◦ In-Domainのデータのみでの事前学習を検討 ▪ 大幅な精度向上 ◦ mBART25+input adaptと比較 ▪ mBART25の方が良い • データの規模が大きいため 16
Analysis 1/2 • Narrowing domein gap ◦ ロングテール領域はドメインに特化した情報を持つ ▪ 低頻度語に対して効いているか検証
◦ 翻訳結果の単語の精度を計算 (compare-mt3) ◦ 頻度に基づく単語の三つのカテゴリ [Wang+2021] [Jiao+2021] ▪ high:上位3000語 ▪ med:上位3001-12000語 ▪ low:上位12001-語 ◦ 低頻度語に対してBLEUスコアの増加が確認 ▪ domain gapが縮まっている 17
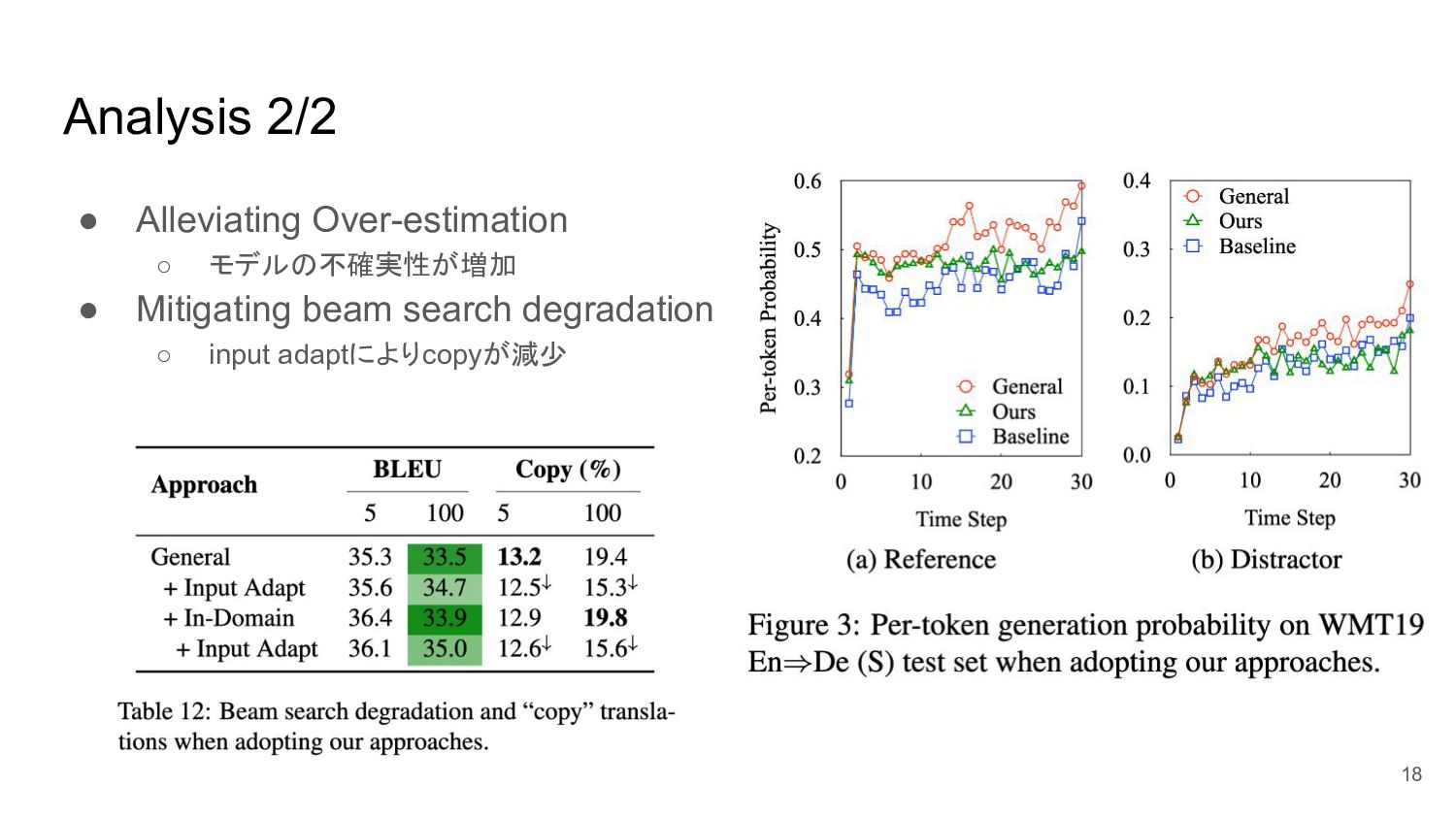
Analysis 2/2 • Alleviating Over-estimation ◦ モデルの不確実性が増加 • Mitigating beam
search degradation ◦ input adaptによりcopyが減少 18
Conclusion • mBARTの分析と改良手法の提案 ◦ Decoderを同時に学習する上での影響 ▪ 利点:多様性のある翻訳と,妥当性に関連するエラーを軽減 • 特にsmall-scaleのデータに対して顕著 ▪
欠点:翻訳の質が制限され, over-estimationの問題が発生 ◦ 新たな手法の提案 ▪ in-domain pretraining:ドメインに特化した事前学習 • 翻訳性能の向上を確認 ▪ input adaptation in fine-tuning:原文にノイズを加え原文を出力させるよう微調整 • モデルの頑健性の向上を確認 19
{kind=link}
![Introduction • Seq2Seqを事前学習したモデル(mBART [Liu+2020])がMTでSOTA • Seq2Seqの事前学習の性質の理解と改良 ◦ Seq2Seqの事前学習 vs Encoderのみの事前学習の分析](https://files.speakerdeck.com/presentations/01b937d631ee4c1db36d1d449753c0e6/slide_1.jpg){kind=link}
![Understanding Seq2Seq Pretraining • baseline:Transformer-Big • model:mBART25 [Liu+2020] ◦ パラメータ更新の有無で](https://files.speakerdeck.com/presentations/01b937d631ee4c1db36d1d449753c0e6/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Pretraining and Finetuning Discrepancy 4/6 • model uncertainty [Ott+2018] ◦](https://files.speakerdeck.com/presentations/01b937d631ee4c1db36d1d449753c0e6/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}