Kiyama1 Taichi Aida1 Mamoru Komachi2 Toshinobu Ogiso3 Hiroya Takamura4 Daichi Mochihashi3,5 1Tokyo Metropolitan University 2Hitotsubashi University 3National Institute for Japanese Language and Linguistics 4National Institute of Advanced Industrial Science and Technology 5The Institute of Statistical Mathematics
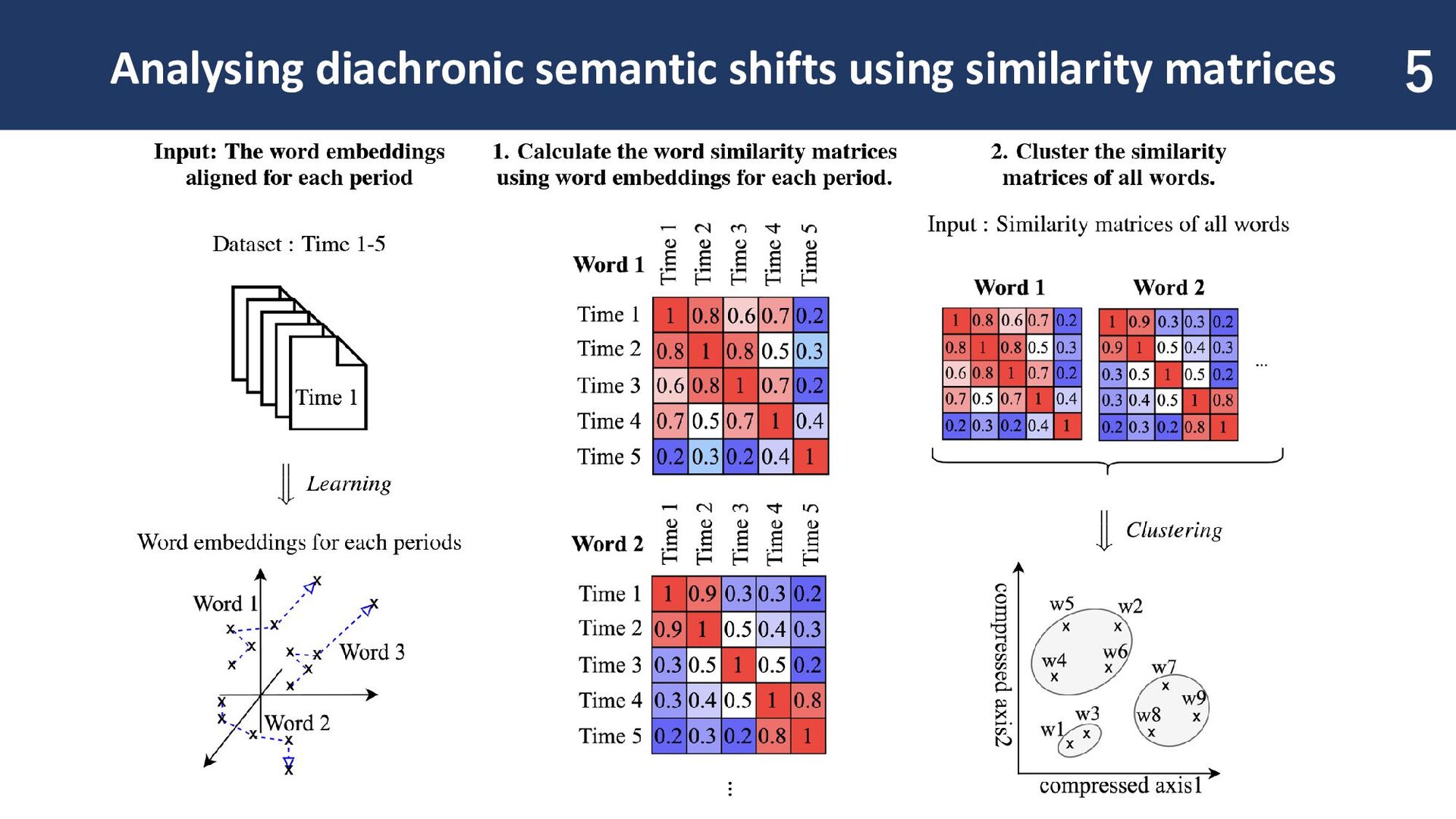
change over time. Our Contributions ◼ Analyzing semantic shifts using diachronic word similarity matrices ◼ Considering arbitrary time periods and using lightweight word embeddings ◼ Words with similar patterns are grouped in an unsupervised setting 2
words change over time ◼ The task of analyzing changes in word embeddings ◼ Based on the distributional hypothesis, a word’s meaning is determined by its surrounding words 3 Quoted from [Hamilton+, 2016]
Shift in two periods [Cassotti+, 2023][Periti and Tahmasebi, 2024a][Aida and Bollegala, 2024][Periti+, 2024] ◼ What word change? ◼ Measure the degree of semantic shift between two time periods ◼ Datasets annotated with the degree of semantic change are available ◼ Semantic Shift in multiple periods [Kulkarni+, 2015] [Hu+, 2019] [Giulianelli+, 2020] ◼ How does a word change? ◼ change points detection and measure the proportion of word senses ◼ No annotated Dataset ◼ Does not reveal specific semantic transitions ◼ Computationally expensive, limiting the number of target words 4 [Periti and Tahmasebi, 2024b]
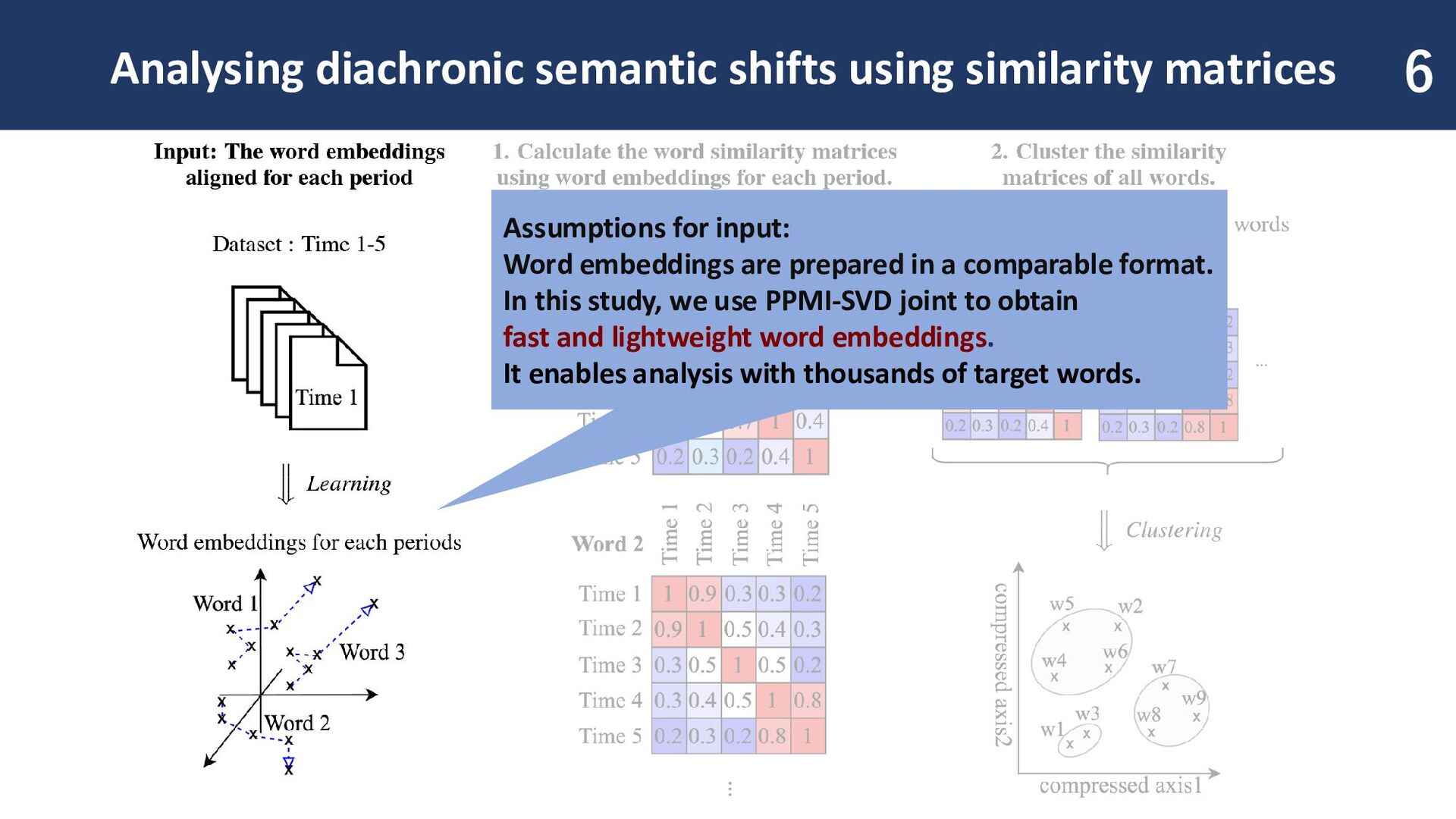
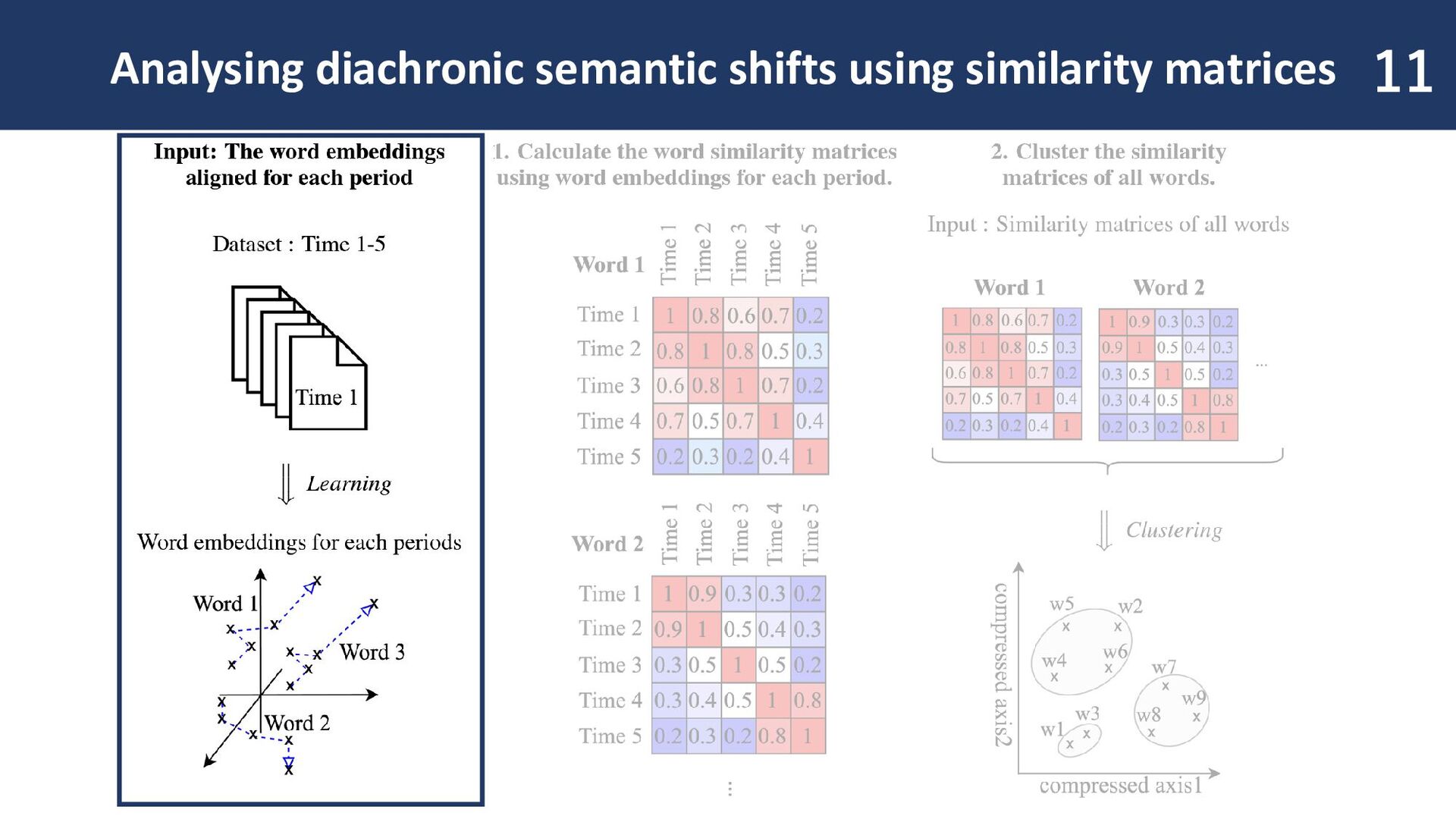
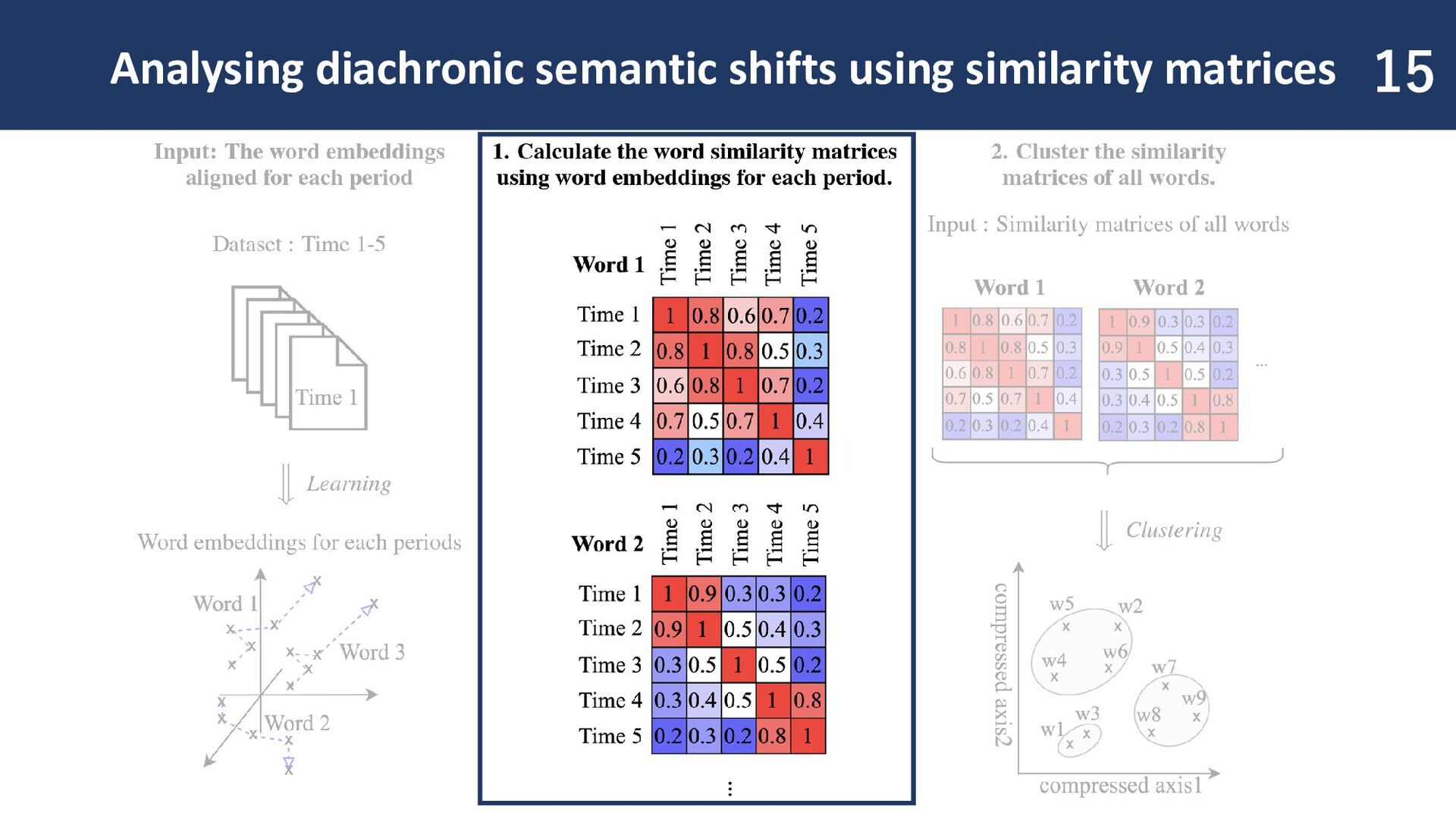
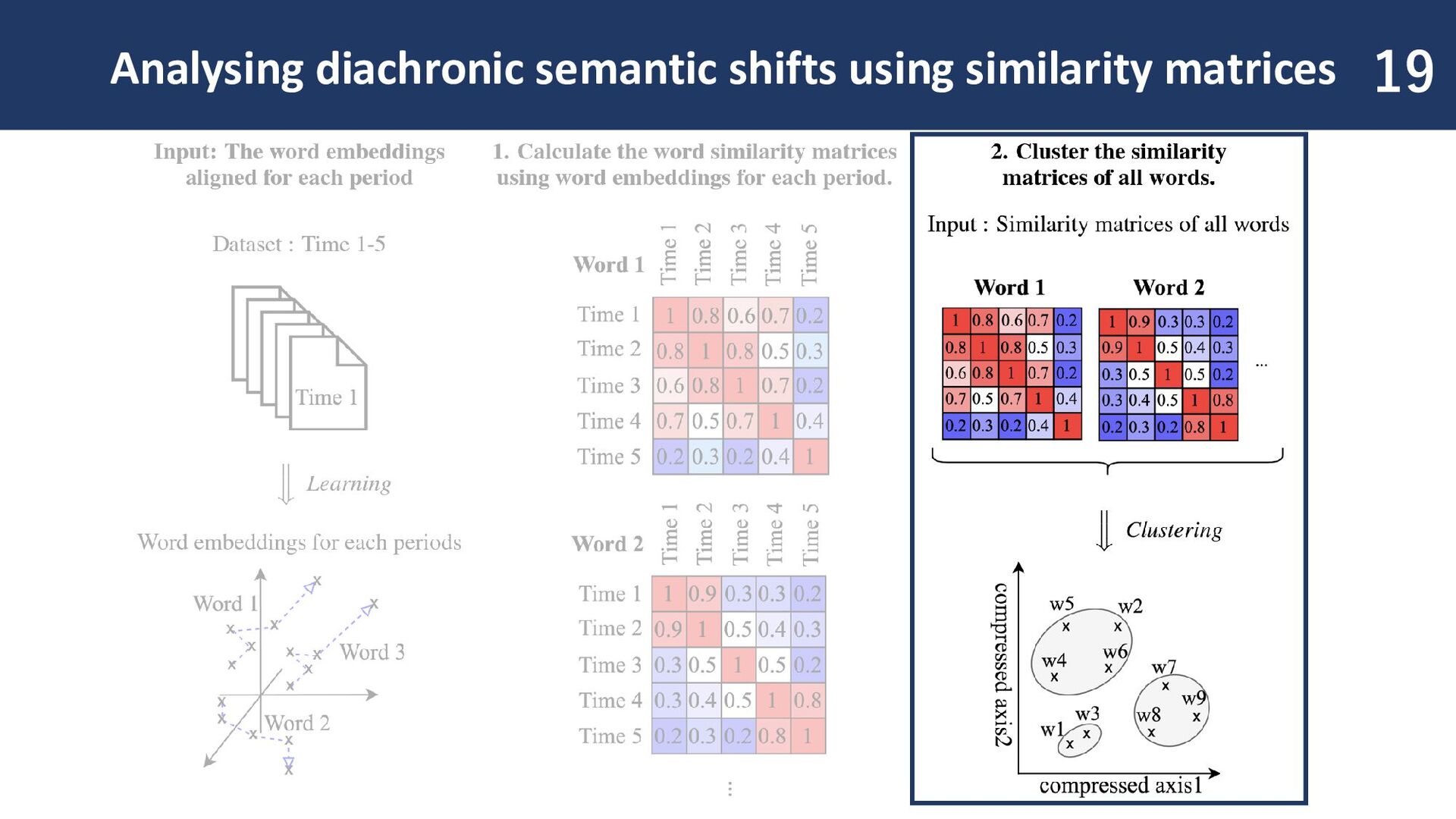
input: Word embeddings are prepared in a comparable format. In this study, we use PPMI-SVD joint to obtain fast and lightweight word embeddings. It enables analysis with thousands of target words.
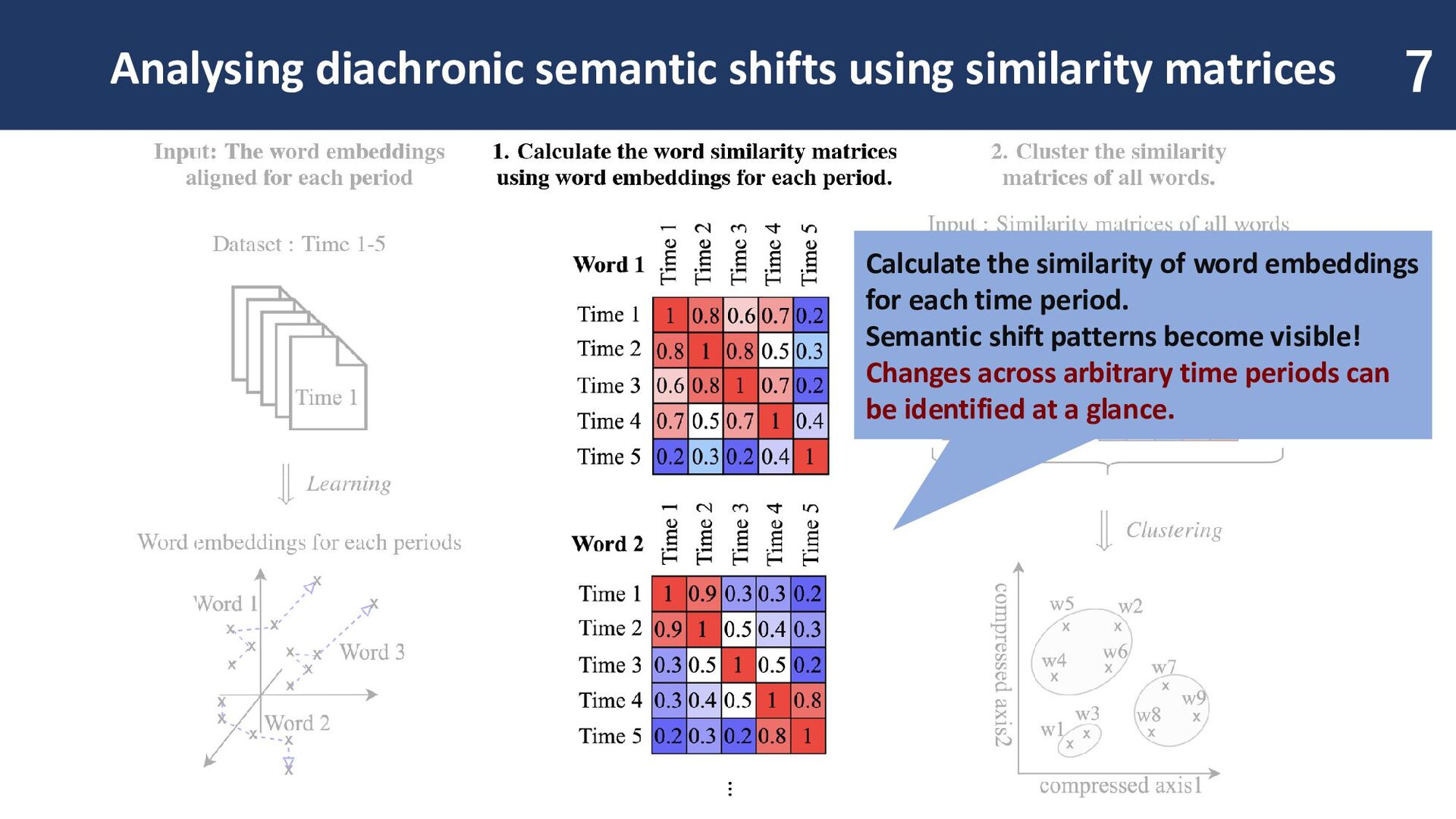
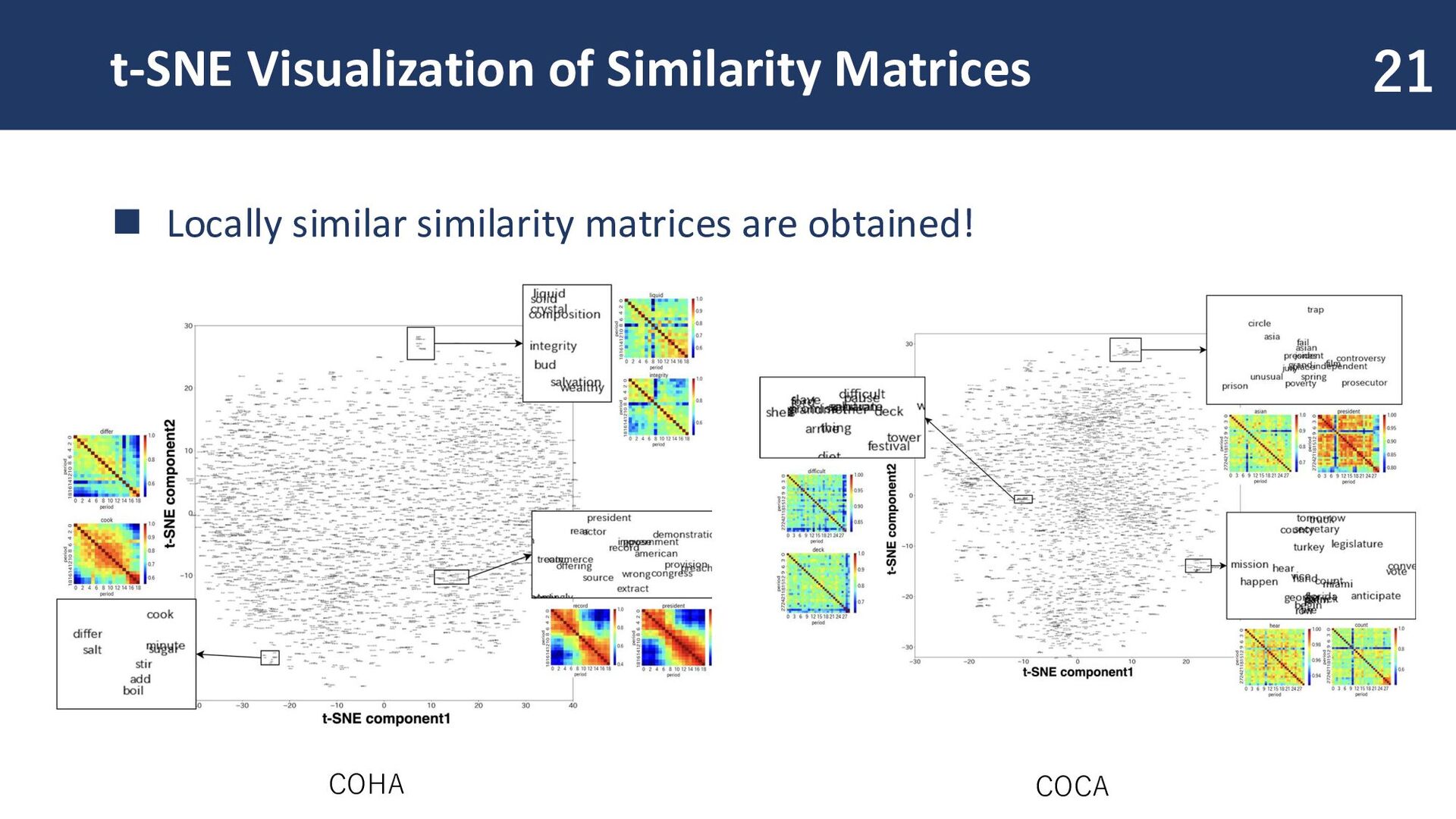
similarity of word embeddings for each time period. Semantic shift patterns become visible! Changes across arbitrary time periods can be identified at a glance.
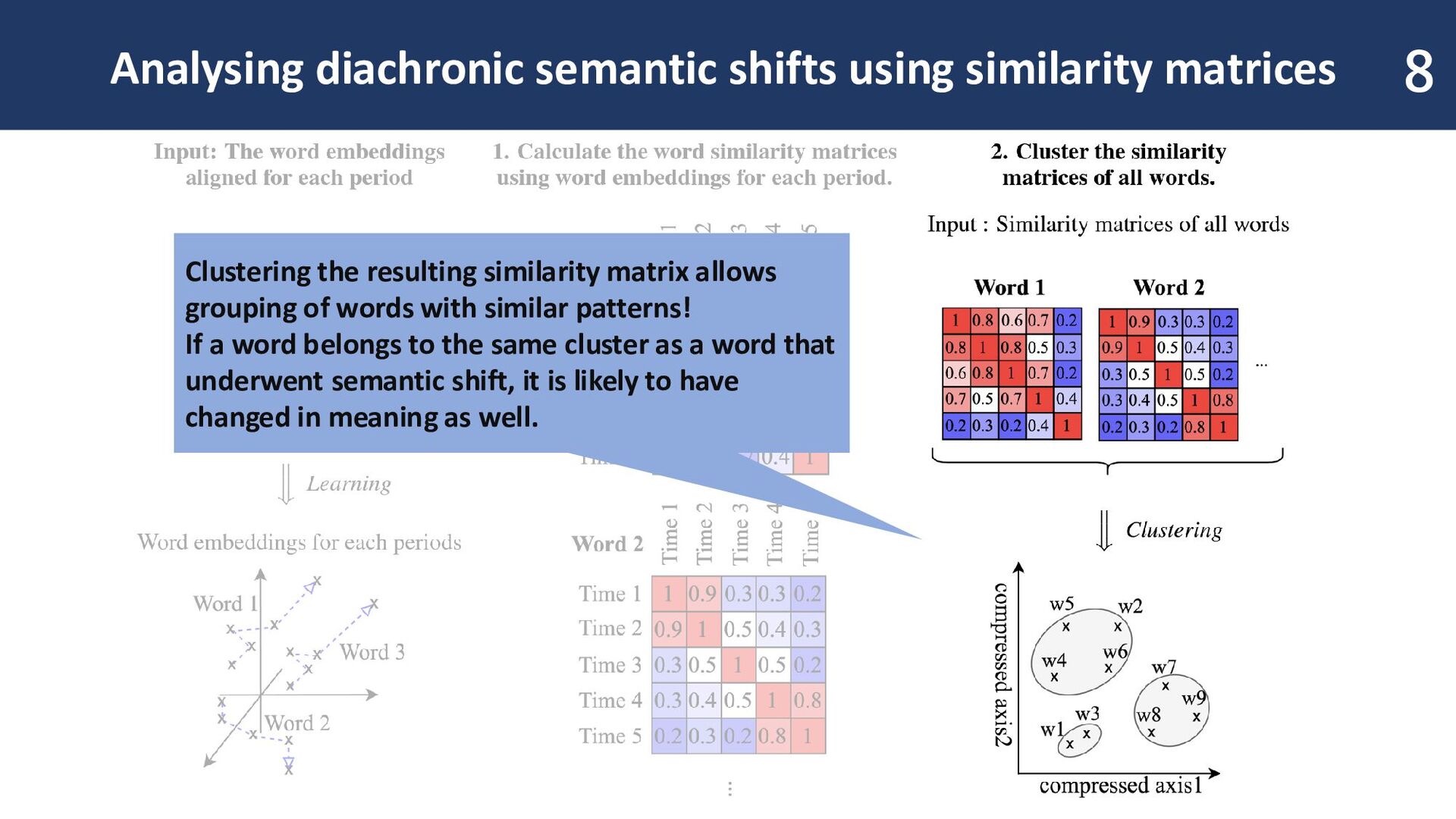
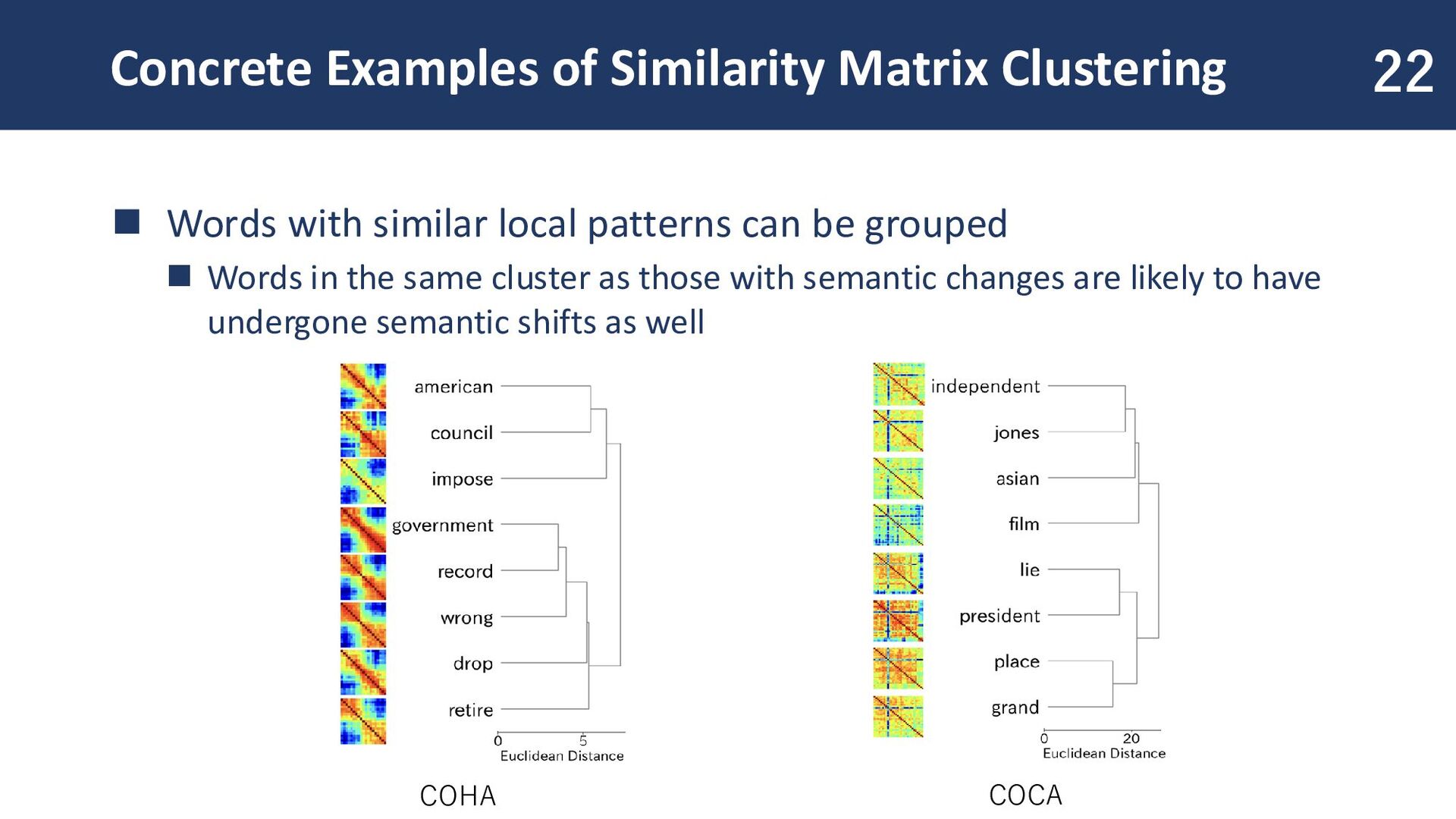
resulting similarity matrix allows grouping of words with similar patterns! If a word belongs to the same cluster as a word that underwent semantic shift, it is likely to have changed in meaning as well.
◼ 1830-2010, 19 period, each spanning 10 years ◼ Target words:3231 ◼ COCA (Corpus of contemporary American English) ◼ 1991-2019, 30 period, each spanning 1 years ◼ Target words:2805 ◼ Word Embedding ◼ PPMI-SVD joint [Aida+, 2021] ◼ Similarity ◼ Cosine similarity 12 • Comparison across different time slices • More than 100 target words per period (appearing words) • A very large number of words.
◼ 1830-2010, 19 period, each spanning 10 years ◼ Target words:3231 ◼ COCA (Corpus of contemporary American English) ◼ 1991-2019, 30 period, each spanning 1 years ◼ Target words:2805 ◼ Word Embedding ◼ PPMI-SVD joint [Aida+, 2021] ◼ Similarity ◼ Cosine similarity 13 This method is CPU-based and computationally fast
◼ PPMI : positive pointwise mutual information ◼ SVD : singular value decomposition ◼ Context words are shared and compressed simultaneously [Aida+, 2021] 14 Quoted from [Aida+, 2021] M : PPMI matrix
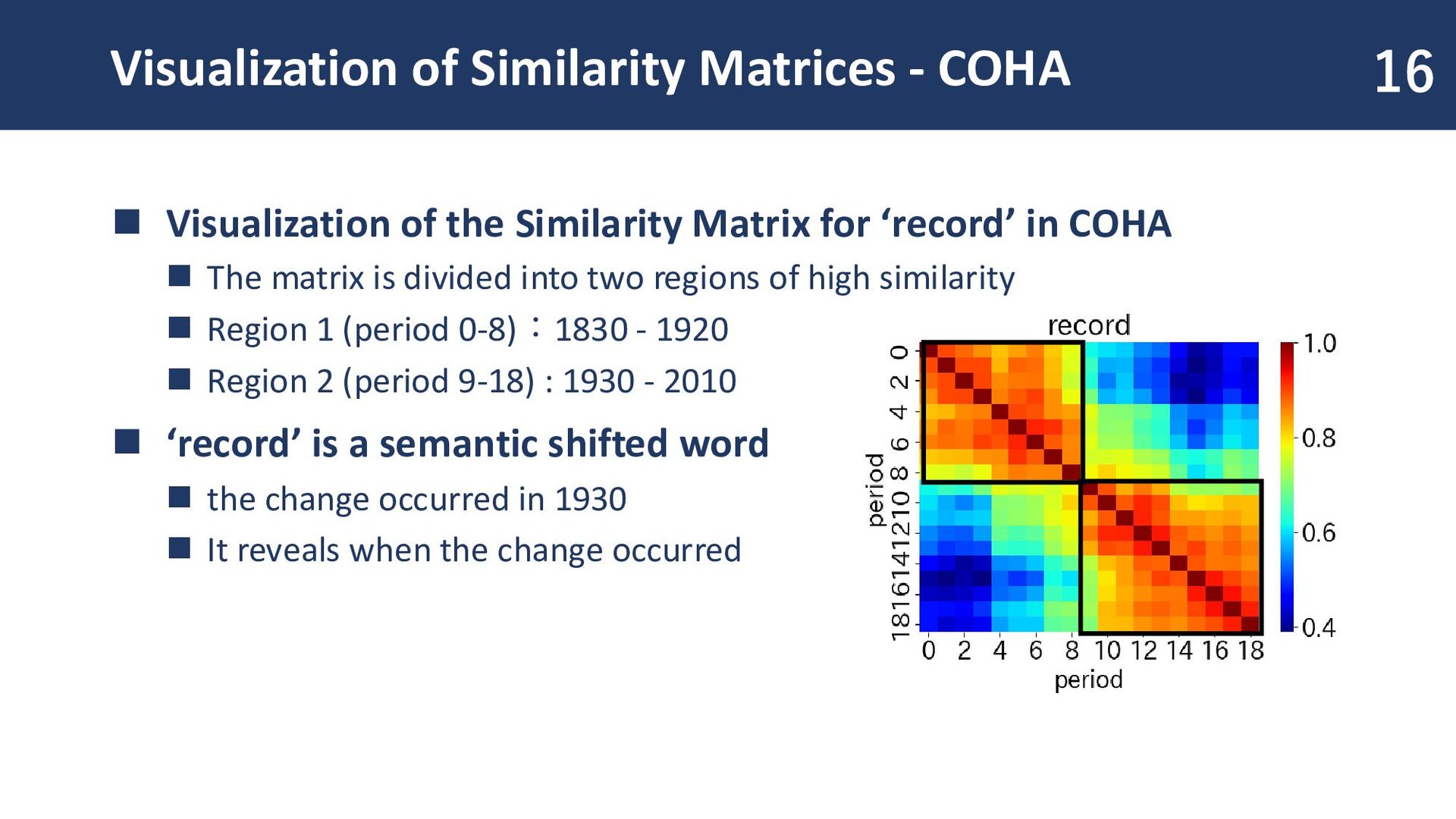
Similarity Matrix for ‘record’ in COHA ◼ The matrix is divided into two regions of high similarity ◼ Region 1 (period 0-8):1830 - 1920 ◼ Region 2 (period 9-18) : 1930 - 2010 ◼ ‘record’ is a semantic shifted word ◼ the change occurred in 1930 ◼ It reveals when the change occurred 16
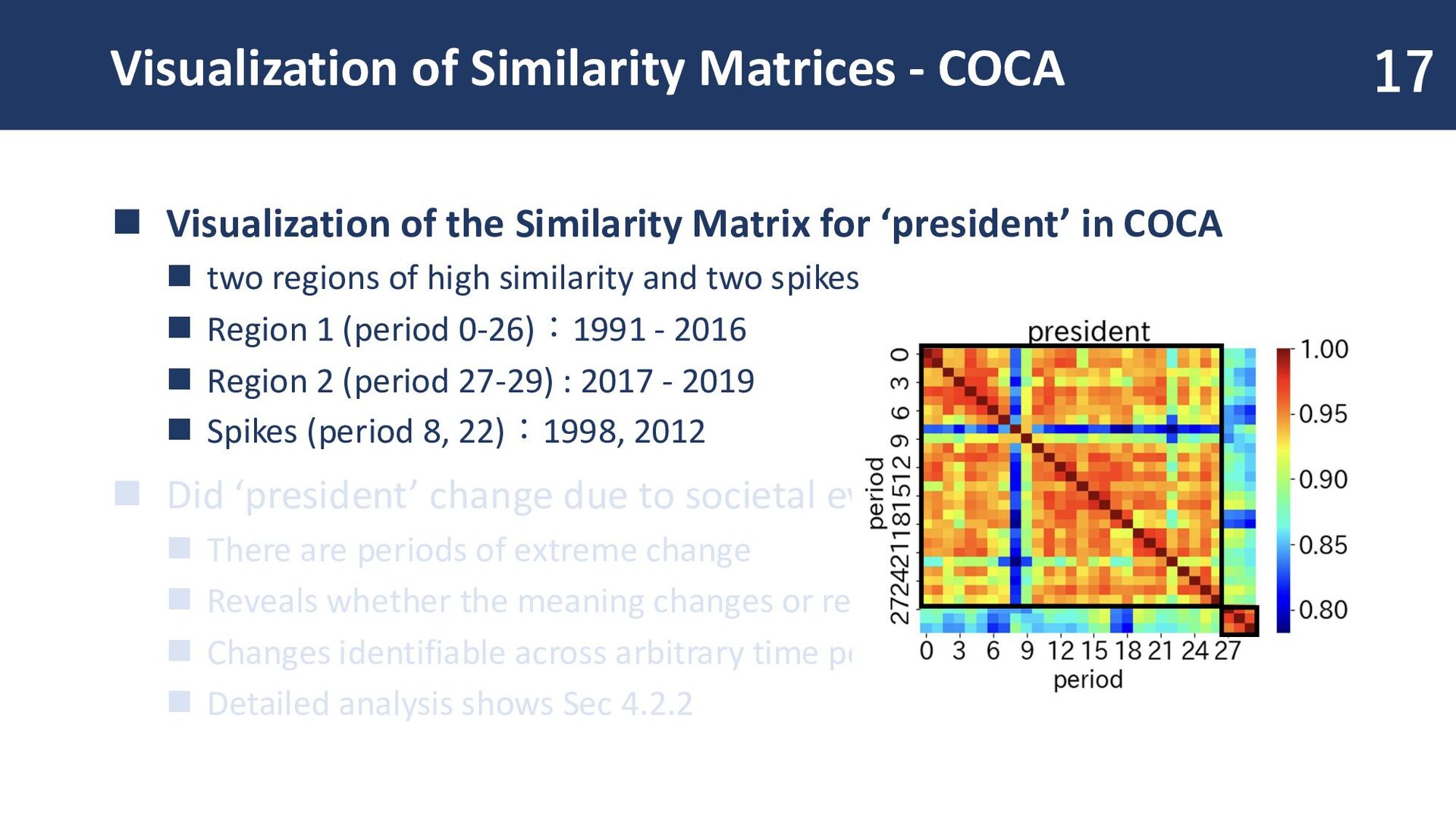
Similarity Matrix for ‘president’ in COCA ◼ two regions of high similarity and two spikes ◼ Region 1 (period 0-26):1991 - 2016 ◼ Region 2 (period 27-29) : 2017 - 2019 ◼ Spikes (period 8, 22):1998, 2012 ◼ Did ‘president’ change due to societal events? ◼ There are periods of extreme change ◼ Reveals whether the meaning changes or reverts ◼ Changes identifiable across arbitrary time periods! ◼ Detailed analysis shows Sec 4.2.2 17
Similarity Matrix for ‘president’ in COCA ◼ two regions of high similarity and two spikes ◼ Region 1 (period 0-26):1991 - 2016 ◼ Region 2 (period 27-29) : 2017 - 2019 ◼ Spikes (period 8, 22):1998, 2012 ◼ Did ‘president’ change due to societal events? ◼ Yes! -> Detailed analysis shows Sec 4.2.2 ◼ Reveals whether the meaning changes or reverts ◼ Changes identifiable across arbitrary time periods! 18
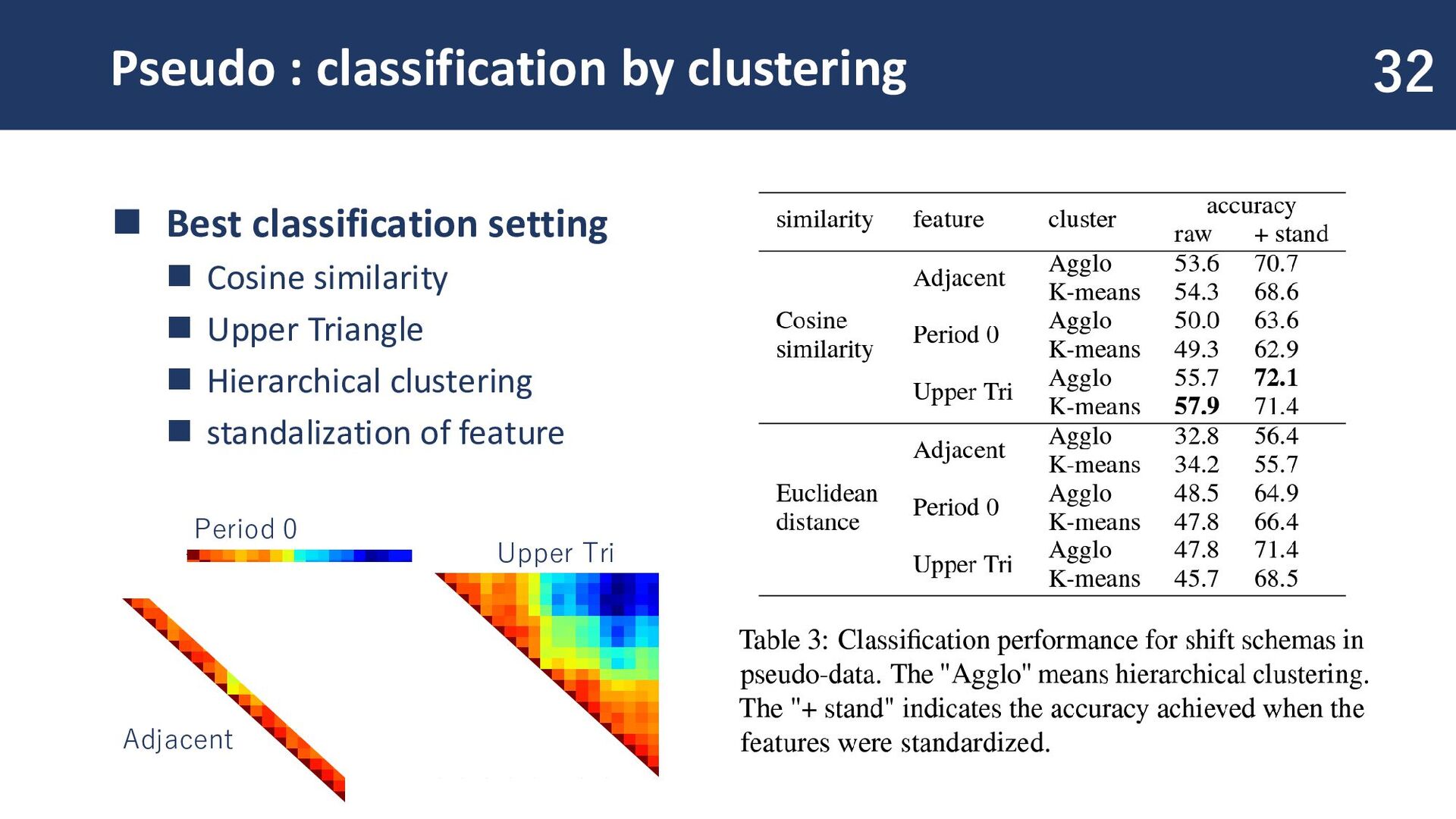
triangular components ◼ clustering:Hierarchical clustering ◼ normalization:Standardizing the feature ◼ How were these parameters chosen? ◼ The configuration that performed best in experiments on pseudo-data was adopted. ◼ See → Sec 5: Experiment in Pseudo Data 20 Upper triangular components
local patterns can be grouped ◼ Words in the same cluster as those with semantic changes are likely to have undergone semantic shifts as well 22 COHA COCA
◼ Considering arbitrary time periods and using lightweight word embeddings ◼ Words with similar patterns are grouped in an unsupervised setting 23 Similarity matrices are good for analyzing arbitrary time periods!
point detection in adjacent time periods [Kulkarni+, 2015] ◼ Measures the degree of semantic change between consecutive time periods ◼ A natural extension of semantic change analysis between two periods ◼ Does not reveal specific semantic transitions ◼ When there are multiple changes, does the meaning revert to its original state? ◼ Or does it fully shift to a different sense? 25 Considering information across arbitrary time periods is needed Quoted from [Periti and Tahmasebi, 2024b]
word senses using BERT-based methods [Hu+, 2019][Giulianelli+, 2020] ◼ Clusters embeddings of target words to analyze the proportion of word senses ◼ Allows analysis of the temporal transitions of word senses ◼ Computationally expensive, limiting the number of target words ◼ Requires computation for each word multiplied by the number of examples. 26 A scalable method using lightweight word embeddings is needed Quoted from [Hu+, 2019]
Changes in similarity are likely caused by changes in co-occurring words ◼ Analyze the words that appear exclusively in that period ◼ :PPMI matrix at period t ◼ :Top-k words that appear only in period t1 27
‘record’ in COHA ◼ Semantic change is clearly observable! ◼ 1840 : the meaning of preserving events or objects. ◼ 1940 : media for playing back sound. 28
‘president’ in COCA ◼ Changes driven by societal factors can be analyzed! ◼ Related to presidential elections and documentaries ◼ Changes during the Trump administration were also observed. 29
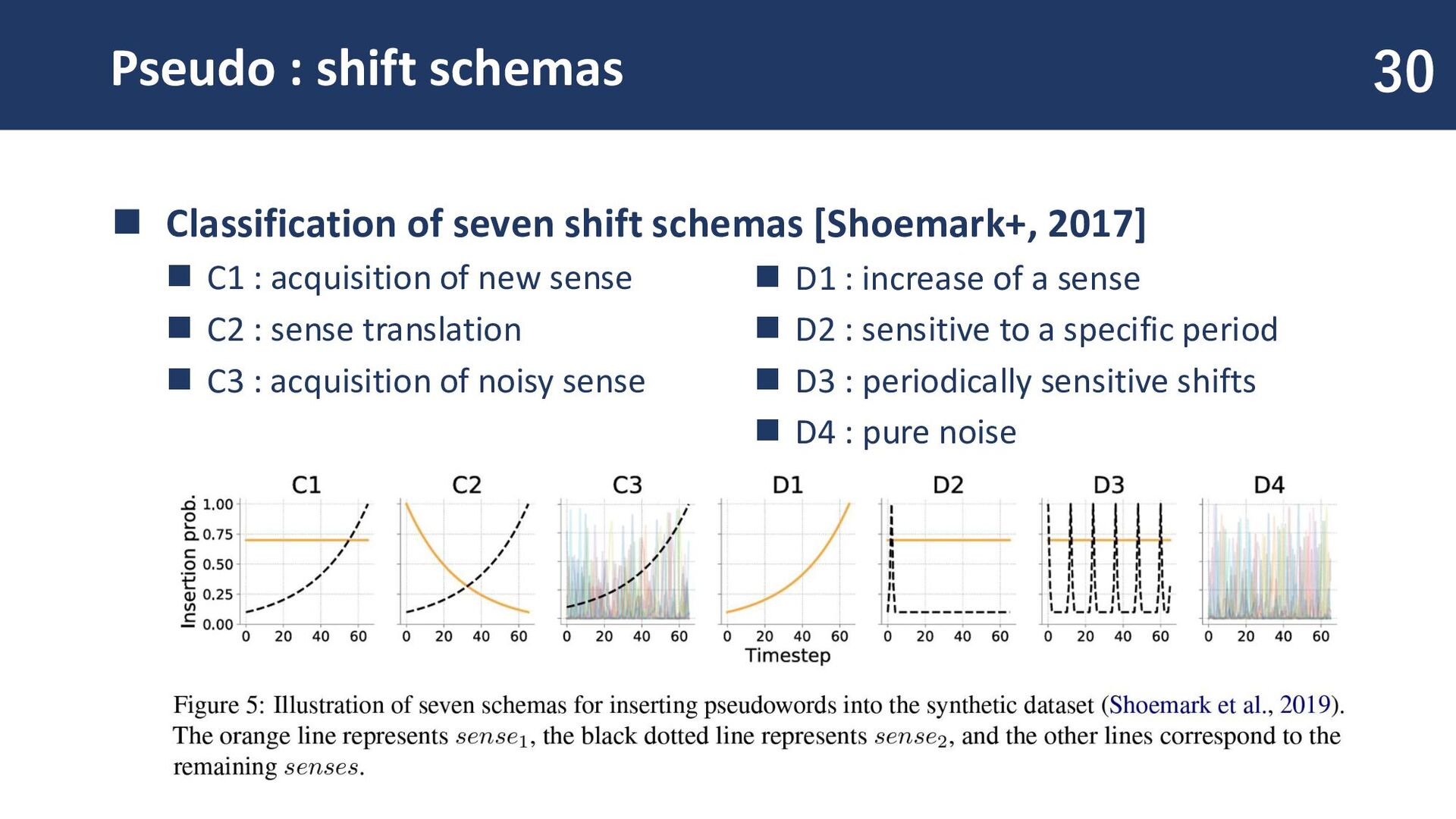
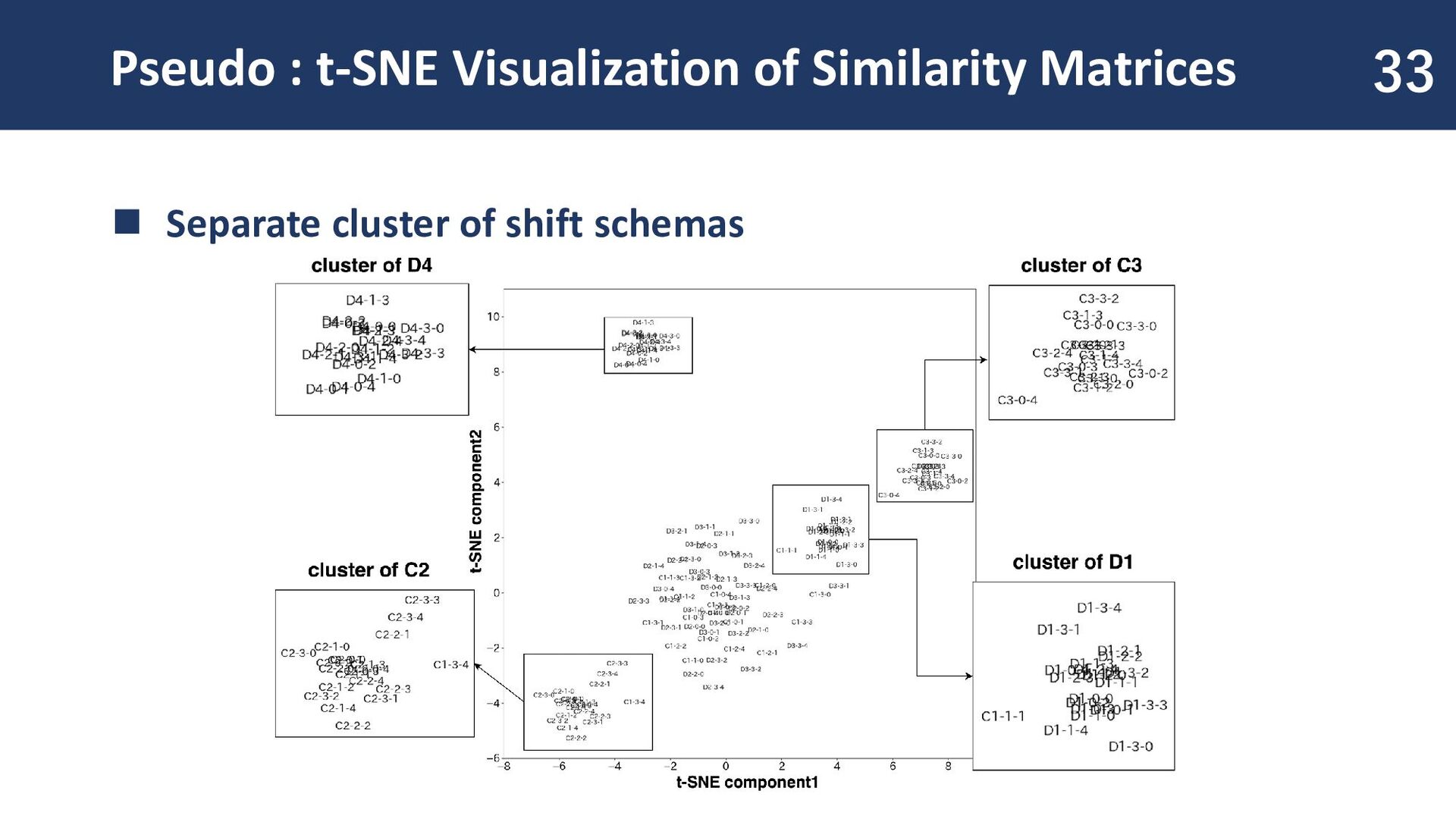
schemas [Shoemark+, 2017] ◼ C1 : acquisition of new sense ◼ C2 : sense translation ◼ C3 : acquisition of noisy sense ◼ D1 : increase of a sense ◼ D2 : sensitive to a specific period ◼ D3 : periodically sensitive shifts ◼ D4 : pure noise
◼ Create pseudo shifts across 20 time periods ◼ Generate 20 pseudo-words for each shifts ◼ Embedding method ◼ PPMI-SVD joint 31 A total of 140 pseudo-words are generated. A classification task is performed on these 140 words, categorizing them into seven shifts.
◼ Embedding ◼ Dynamic embedding is good for analysis? ◼ Pseudo schemas ◼ these seven schemas do not necessarily cover all types of semantic shifts ◼ Application ◼ How to select target words for analysis? ◼ changes in similarity do not always correspond to semantic shifts 34
Semantic Change [Cassotti+, 2023] XL-LEXEME: WiC Pretrained Model for Cross-Lingual LEXical sEMantic changE [Periti and Tahmasebi, 2024a] A Systematic Comparison of Contextualized Word Embeddings for Lexical Semantic Change [Periti and Tahmasebi, 2024b] Towards a Complete Solution to Lexical Semantic Change: an Extension to Multiple Time Periods and Diachronic Word Sense Induction [Aida and Bollegala, 2024] A Semantic Distance Metric Learning approach for Lexical Semantic Change Detection 36
[Kulkarni+, 2015] Statistically Significant Detection of Linguistic Change [Hu+, 2019] Diachronic Sense Modeling with Deep Contextualized Word Embeddings: An Ecological View [Giulianelli+, 2020] Analysing Lexical Semantic Change with Contextualised Word Representations 37
for Measuring Semantic Differences. [Levy and Goldberg, 2014] Neural Word Embedding as Implicit Matrix Factorization [Shoemark+, 2017] Room to Glo: A Systematic Comparison of Semantic Change Detection Approaches with Word Embeddings [Nulund+, 2024] Time is Encoded in the Weights of Finetuned Language Models 38
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![PPMI-SVD joint [Aida+, 2021] ◼ PPMI-SVD [Levy and Goldberg, 2014]](https://files.speakerdeck.com/presentations/a7c3555e719e4e5caac9a0af1e3e3094/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References 1 [Hamilton+,2016] Diachronic Word Embeddings Reveal Statistical Laws of](https://files.speakerdeck.com/presentations/a7c3555e719e4e5caac9a0af1e3e3094/slide_36.jpg){kind=link}
![References 2 [Periti+, 2024] Analyzing Semantic Change through Lexical Replacements](https://files.speakerdeck.com/presentations/a7c3555e719e4e5caac9a0af1e3e3094/slide_37.jpg){kind=link}
![References 3 [Aida+, 2021] A Comprehensive Analysis of PMI-based Models](https://files.speakerdeck.com/presentations/a7c3555e719e4e5caac9a0af1e3e3094/slide_38.jpg){kind=link}