Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Word Sense Extension
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
hajime kiyama
January 23, 2024
Research
160
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Word Sense Extension
Japanese explanation
hajime kiyama
January 23, 2024
More Decks by hajime kiyama
See All by hajime kiyama
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
330
Idiosyncrasies in Large Language Models
rudorudo11
0
63
People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text
rudorudo11
0
280
Analyzing Continuous Semantic Shifts with Diachronic Word Similarity Matrices.
rudorudo11
0
230
Using Synchronic Definitions and Semantic Relations to Classify Semantic Change Types
rudorudo11
0
110
Analyzing Semantic Change through Lexical Replacements
rudorudo11
0
370
意味変化分析に向けた単語埋め込みの時系列パターン分析
rudorudo11
1
210
Bridging Continuous and Discrete Spaces: Interpretable Sentence Representation Learning via Compositional Operations
rudorudo11
0
340
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
rudorudo11
0
230
Other Decks in Research
See All in Research
コーディングエージェントとABNを再考
hf149
2
760
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
230
Fukui Shibiten 39 - AI Art
butchi
0
150
Cross-Media Information Spaces and Architectures
signer
PRO
0
310
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
300
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
240
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
610
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
630
LLM の Attention 機構まとめ — 数式・計算量・メモリ
puwaer
8
2.2k
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
kobayashi31
1
170
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
4.3k
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
440
Featured
See All Featured
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
Evolving SEO for Evolving Search Engines
ryanjones
0
240
The browser strikes back
jonoalderson
0
1.4k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Typedesign – Prime Four
hannesfritz
42
3.1k
Between Models and Reality
mayunak
4
370
Deep Space Network (abreviated)
tonyrice
0
220
How to Talk to Developers About Accessibility
jct
2
340
The Pragmatic Product Professional
lauravandoore
37
7.4k
Transcript
木山朔 M1 論文紹介 ACL2023 11/1 1
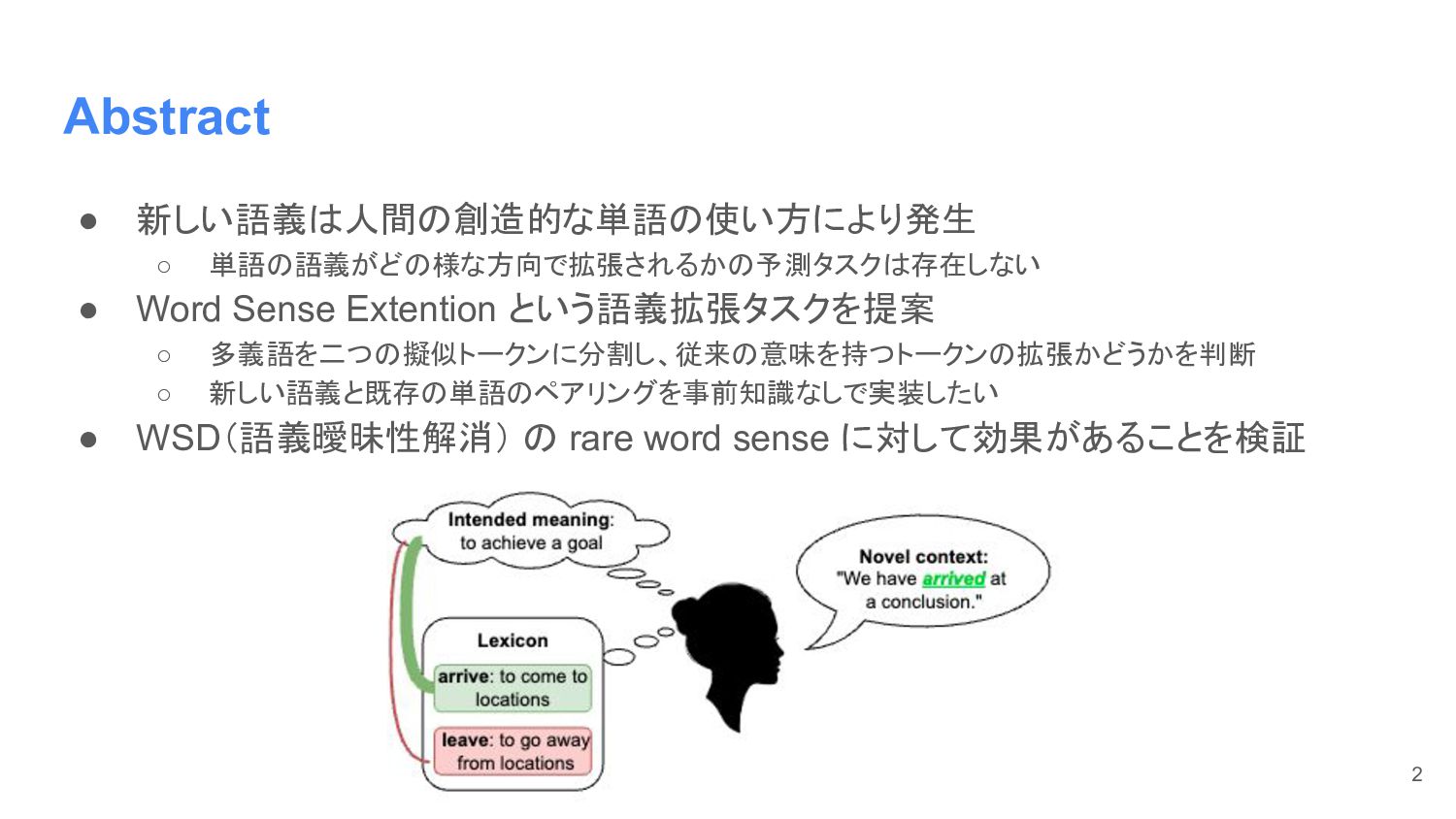
Abstract • 新しい語義は人間の創造的な単語の使い方により発生 ◦ 単語の語義がどの様な方向で拡張されるかの予測タスクは存在しない • Word Sense Extention という語義拡張タスクを提案
◦ 多義語を二つの擬似トークンに分割し、従来の意味を持つトークンの拡張かどうかを判断 ◦ 新しい語義と既存の単語のペアリングを事前知識なしで実装したい • WSD(語義曖昧性解消) の rare word sense に対して効果があることを検証 2
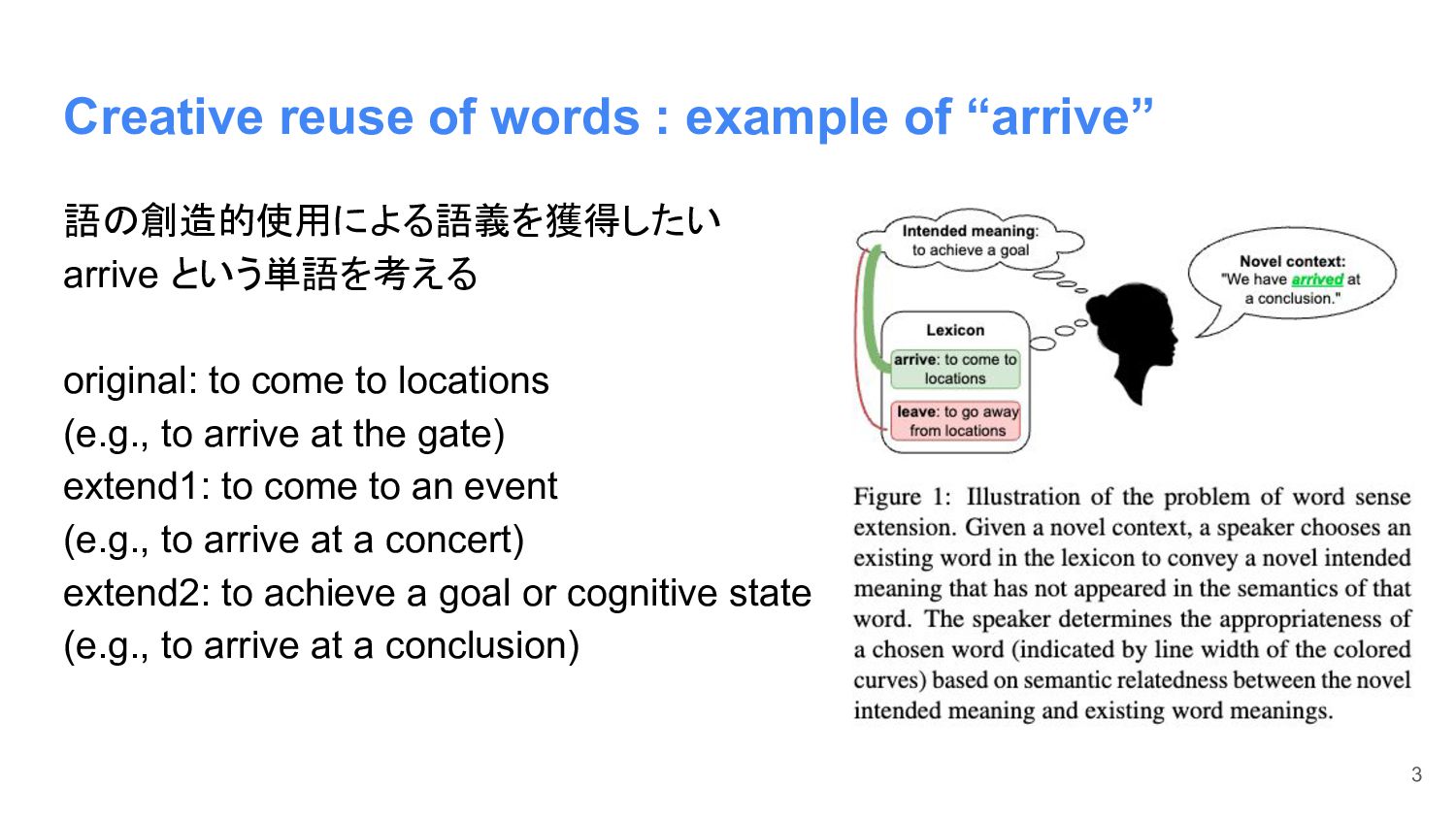
Creative reuse of words : example of “arrive” 語の創造的使用による語義を獲得したい arrive
という単語を考える original: to come to locations (e.g., to arrive at the gate) extend1: to come to an event (e.g., to arrive at a concert) extend2: to achieve a goal or cognitive state (e.g., to arrive at a conclusion) 3
Related work • Models of word meaning extension ◦ lexical
semantics と cognitive linguistic の観点から語義拡張が議論 ◦ Chaining (連鎖) による認知的理論をもとにフレームワークを構築 • Models of word sense disambiguation ◦ WSD(語義曖昧性解消)ではデータスパースネスの問題 ◦ 低頻度語に関するWSDシステムの精度向上を狙う • Contextualized semantic representations ◦ 多義語を文脈化埋め込みで扱う ◦ 言い換えの研究は存在するが、意味拡張の研究は行われていない 4
Chaining:example of “grasp” and “get” • Chaining(連鎖)という現象とは? ◦ 既存の語義間の意味関係を識別し、その関係を一般化し新たな語義を生成すること •
grasp の例 ◦ 意味1「ものを掴む」 ◦ 意味2「アイデアを理解する」 ▪ この様な拡張が別の単語でもみられる • get の例 ◦ 意味1「車を手に入れる」 ◦ 意味2「誰かのアイデアを手に入れる」 ▪ 抽象化が grasp の場合と同じ! 5
Computational framework 3つの構成要素が存在 1. 多義語を異なる語義に対応する擬似トークンに分割 2. 語義選択のために、確率的な連鎖に基づいて語義拡張を定式化 3. 語義拡張の学習のための意味空間学習アルゴリズム 6
Sense-based word type partitioning (1/2) 文字の定義 • 多義語の集合: • 語義集合:
• 文脈と語義のペア: • トークン: ◦ 既存の語義集合内のトークン: ◦ 拡張された語義のトークン: ▪ 単語 w が既存の語義から拡張される新しい語義 s* を表す 7
Sense-based word type partitioning (2/2) ある多義語 w の特定の語義 s* を知らない状況で、語義
s を表現するシナリオ • 多義語 w を二つのトークンに分割 ◦ 既存の語義集合内のトークン: ◦ 拡張された語義のトークン: ▪ 単語 w が既存の語義から拡張される新しい語義 s* を表す • 文脈化された言語モデルを0から学習 ◦ MLM で学習 ◦ マスクされたトークンを埋める際に確率が最大となるように学習 8
Probabilistic formulation of WSE • 単語 w を t*, t0
に置き換えた文脈と語義のペア集合を C*,C0 とする ◦ 既存の語義集合内のトークン: ◦ 拡張された語義のトークン: • WSEタスクの具体的な内容 ◦ w = arrive ◦ s* = “to achieve a goal” ◦ c = “They finally t* at a conclusion after a long debate” ◦ t* としてソーストークン t = arrive が得られるか ◦ m(-) : - を入力とした際のモデルの表現 9
Chaining-based models of WSE • 用語の整理 ◦ h(-):文脈化埋め込み ◦ H(-):文脈化埋め込みの集合
• 従来の語義とターゲットの語義の類似度が高い場合にWSEと判定 ◦ 類似度の計算方法として二つ紹介 10
WSE-Prototype model and WSE-Exemplar model • WSE-Prototype model • WSE-Examplar
model 11 要はどこで平均をとるかの違い d(-,-)はドット積を表す
Learning sense-extensional semantic space • 言語モデルの埋め込み空間をWSE向けに変換したい • Chaining に対応するために、episode learning
algorithm を提案 ◦ episode ごとに mini-batch でソースとターゲットトークンのペアを獲得 ◦ ターゲットトークンに対して最も適切なソーストークンを選択 ◦ negative log likelihood を計算 12
Data • Dataset:Wikitext-103 [Merityet al., 2016] ◦ SpaCy を用いて文を抽出しレンマタイズ ◦
WSD を適用し、各トークンに関連する wordnet synset ID を意味ラベルとして付与 ◦ 多義語の語彙リストは下記の条件を満たすものの集合 ▪ 単語タイプがコーパス内で少なくとも 2つの異なる意味を持つ ▪ SpaCy により、名詞、動詞、形容詞、副詞と判断されたもの • 多義語の単語タイプを擬似トークンペアに分割 ◦ ソースとターゲットのペアに分割 ◦ n個の語義に対し、ランダムに一つを選択肢、他はソーストークンとして扱う 13
Setup • モデル:BERT-base-uncased ◦ パラメータの重みはランダムに初期化( 0から学習) ◦ 多義語を含む場合は置換し、擬似トークンを使用 ◦ BERT
埋め込み層と最終分類層を追加 • 学習方法 ◦ 多義語の70%を学習に ◦ 30%をテストに使う 14
Baseline models Chaining ベースの推論機構を持たないモデルをベースラインとする • BERT-MLM ◦ マスクされた文脈における t0 の確率
• BERT-STS ◦ t0 と t* でコサイン類似度 15
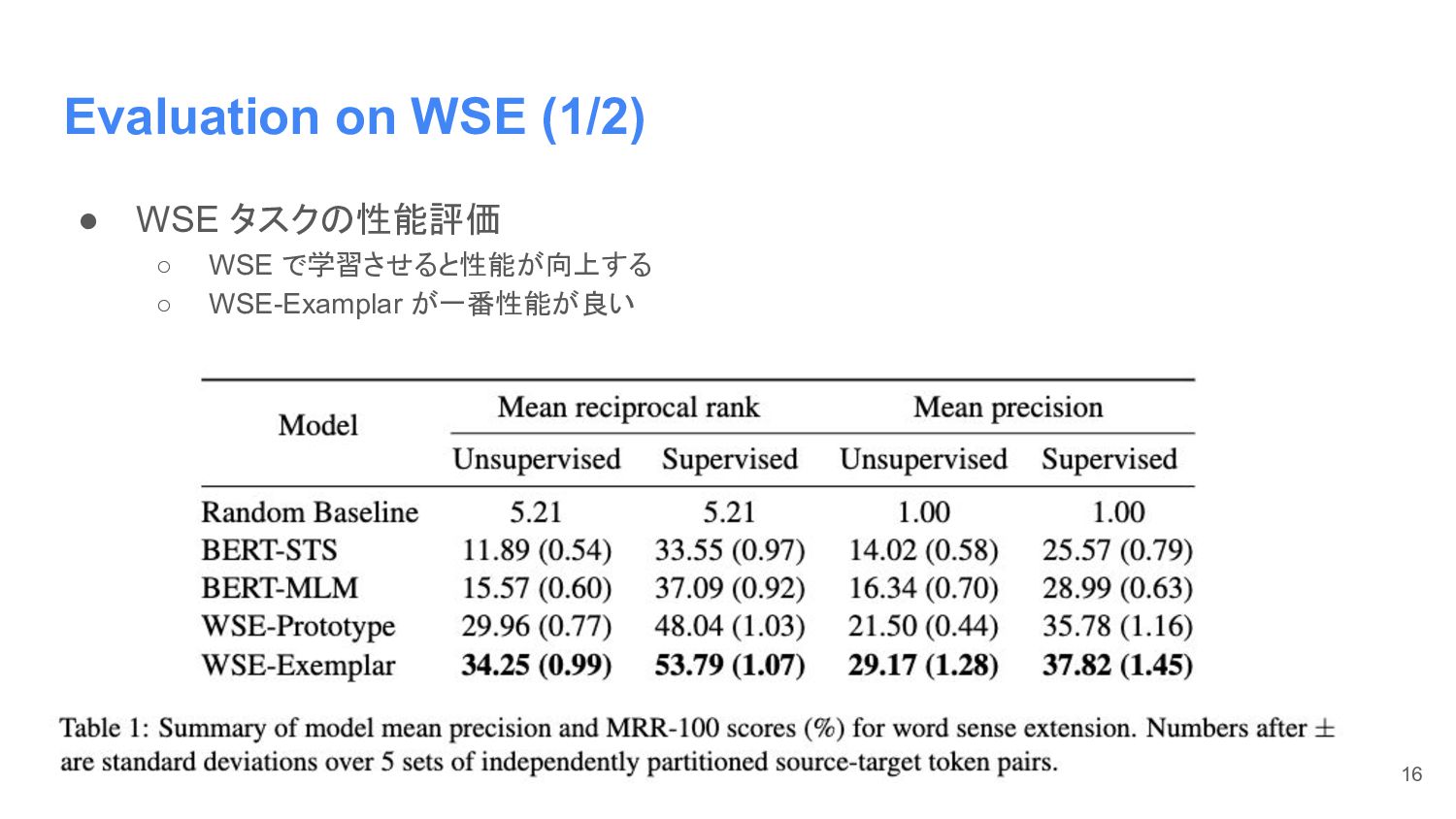
Evaluation on WSE (1/2) • WSE タスクの性能評価 ◦ WSE で学習させると性能が向上する
◦ WSE-Examplar が一番性能が良い 16
Evaluation on WSE (2/2) • 予測例 ◦ 動詞や名詞の場合を WSE モデルでは予測できている
◦ BERT-MLM は言い換えを予測する傾向 ◦ 強い非リテラルな意味拡張をする用例はどのモデルでも性能が低い 17
Sense relatedness and model predictability • 関連度の高い語義を知っていれば 新しい語義は容易に予測可能では? ◦ 答えは
YES ◦ WSE のモデルが人間の様な感度を 持つかどうかを検証 ◦ Wu-Palmer semantic distance ▪ t* と t0 の意味的距離 ◦ 距離が小さいメトニミーは予測できる ◦ 強いメタファーなどは困難 18
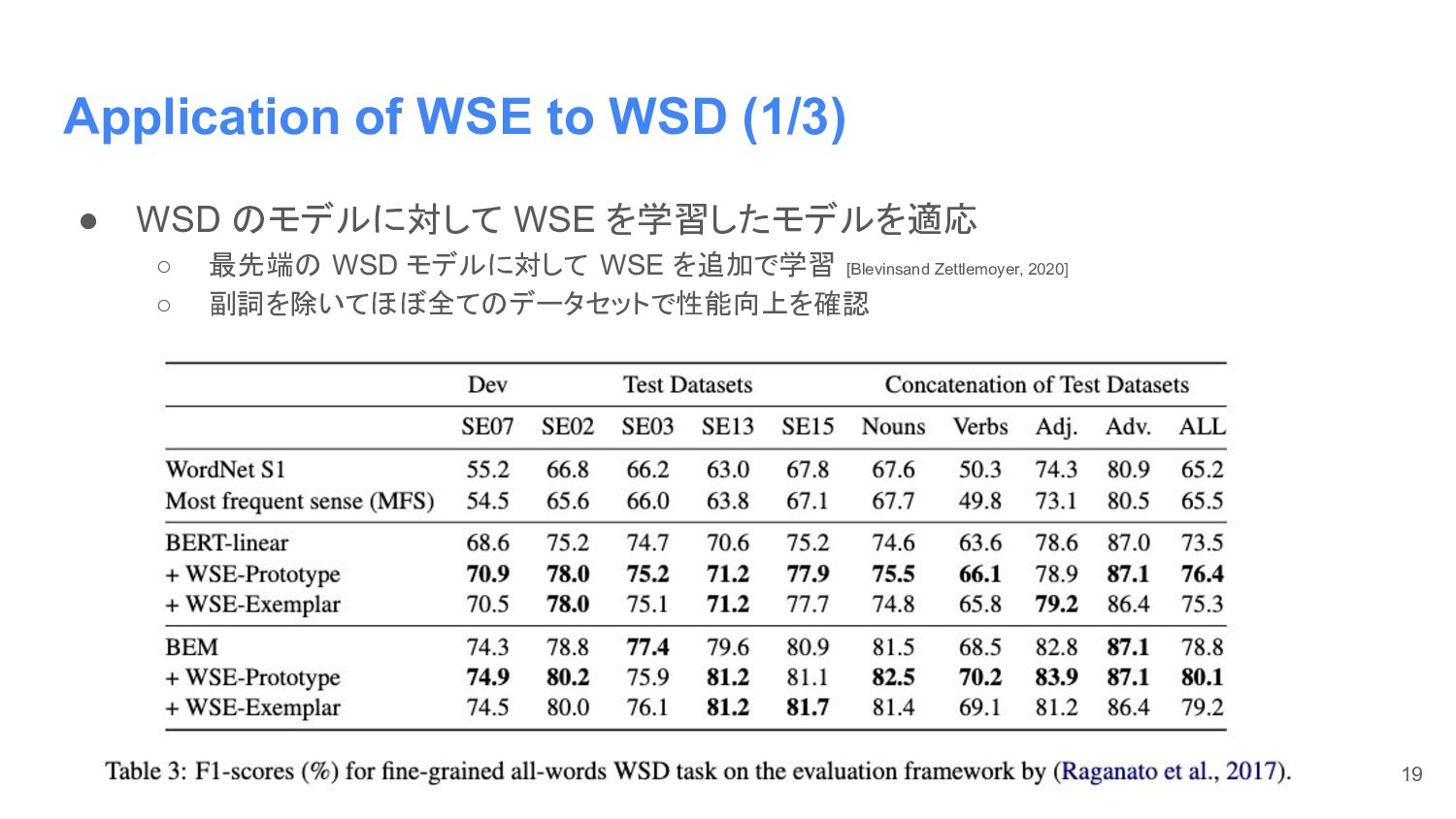
Application of WSE to WSD (1/3) • WSD のモデルに対して WSE
を学習したモデルを適応 ◦ 最先端の WSD モデルに対して WSE を追加で学習 [Blevinsand Zettlemoyer, 2020] ◦ 副詞を除いてほぼ全てのデータセットで性能向上を確認 19
Application of WSE to WSD (2/3) • 頻度ごとに分析 ◦ rare
word に対する性能が高くなっている ◦ BERT-linear だと高くなっていない気がするが … 20
Application of WSE to WSD (3/3) • 具体例 ◦ WSE
の有無で向上した例 ◦ 従来の意味と新しい意味の関係を捉えられている 21
Conclusion まとめ • WSE のタスク、フレームワークを提案 • Chaining をもとにした学習により、WSE の性能が向上 •
WSE の学習を追加することで WSD の(rare word に対する?)精度向上も確認 今後の展望 • より良い WSE モデルのためのフレームワークの拡張 • 時間や言語の違いを考慮したモデル化 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data • Dataset:Wikitext-103 [Merityet al., 2016] ◦ SpaCy を用いて文を抽出しレンマタイズ ◦](https://files.speakerdeck.com/presentations/ffeb11a93d98481487b1c634b0e58bab/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}