Continuous and Discrete Spaces: Interpretable Sentence Representation Learning via Compositional Operations James Y. Huang†, Wenlin Yao‡, Kaiqiang Song‡, Hongming Zhang‡ , Muhao Chen† and Dong Yu‡ †University of Southern California; ‡Tencent AI Lab, Seattle
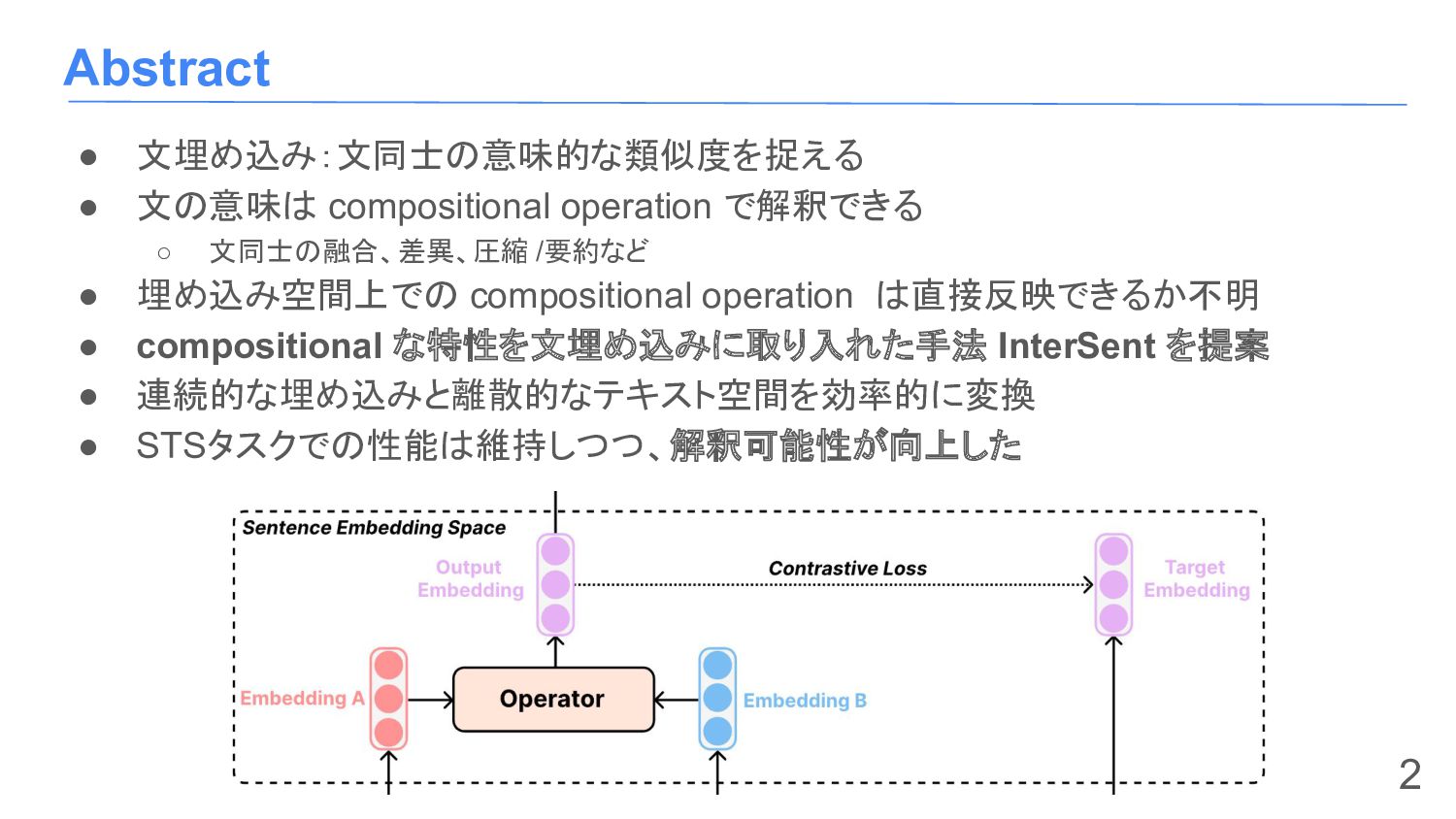
a. 文1と文2の情報を持つ文から文 2を引いたときに文1が出てくる b. sentence fusion の逆演算に限り今回は定義 3. sentence compression a. 文/文章を圧縮/要約した文 4. sentence reconstruction a. Encoderに通したベクトル表現を、 Decoderに通した際に元の文に戻る 6
{kind=link}
{kind=link}
![Related work • Sentence Embedding ◦ 分布仮説 [Harris, 1954] ◦](https://files.speakerdeck.com/presentations/418cc625b2cb4226a8b384b056a81699/slide_2.jpg){kind=link}
![SimCSE [Gao+, 2021] • 対照学習 ◦ 正例を近づけて,負例を遠ざける手法 ◦ どのように正例のペアを見つけるかが重要 ◦](https://files.speakerdeck.com/presentations/418cc625b2cb4226a8b384b056a81699/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Baselines • 従来のモデル ◦ RoBERTa-cls:RoBERTa で [CLS] を文埋め込みとして扱う ◦ RoBERTa-avg:RoBERTa](https://files.speakerdeck.com/presentations/418cc625b2cb4226a8b384b056a81699/slide_12.jpg){kind=link}
{kind=link}
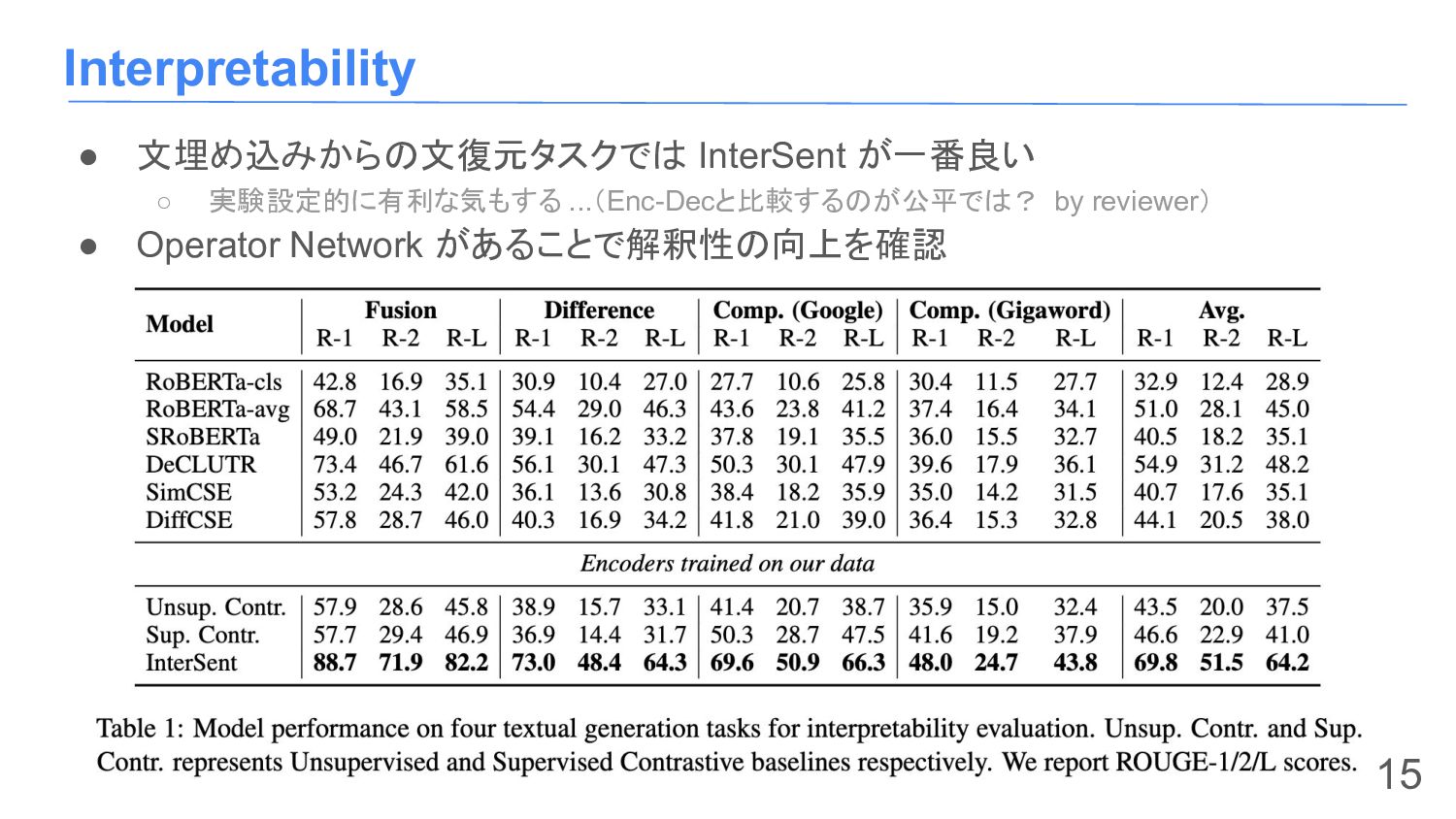{kind=link}
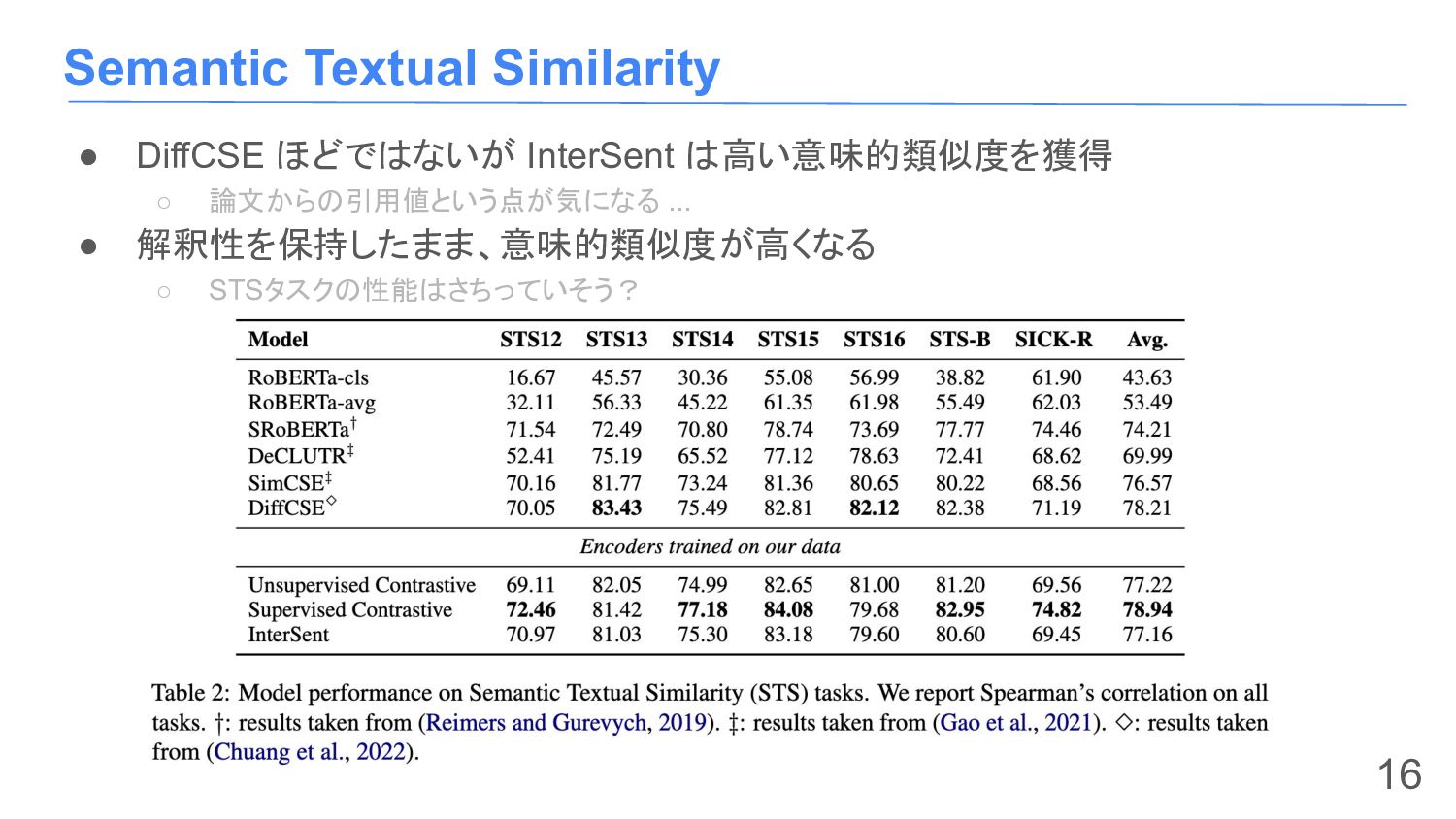{kind=link}
![Sentence Retrieval • 文抽出タスク ◦ Dataset:QQP ◦ BEIR [Thakur+, 2021]](https://files.speakerdeck.com/presentations/418cc625b2cb4226a8b384b056a81699/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
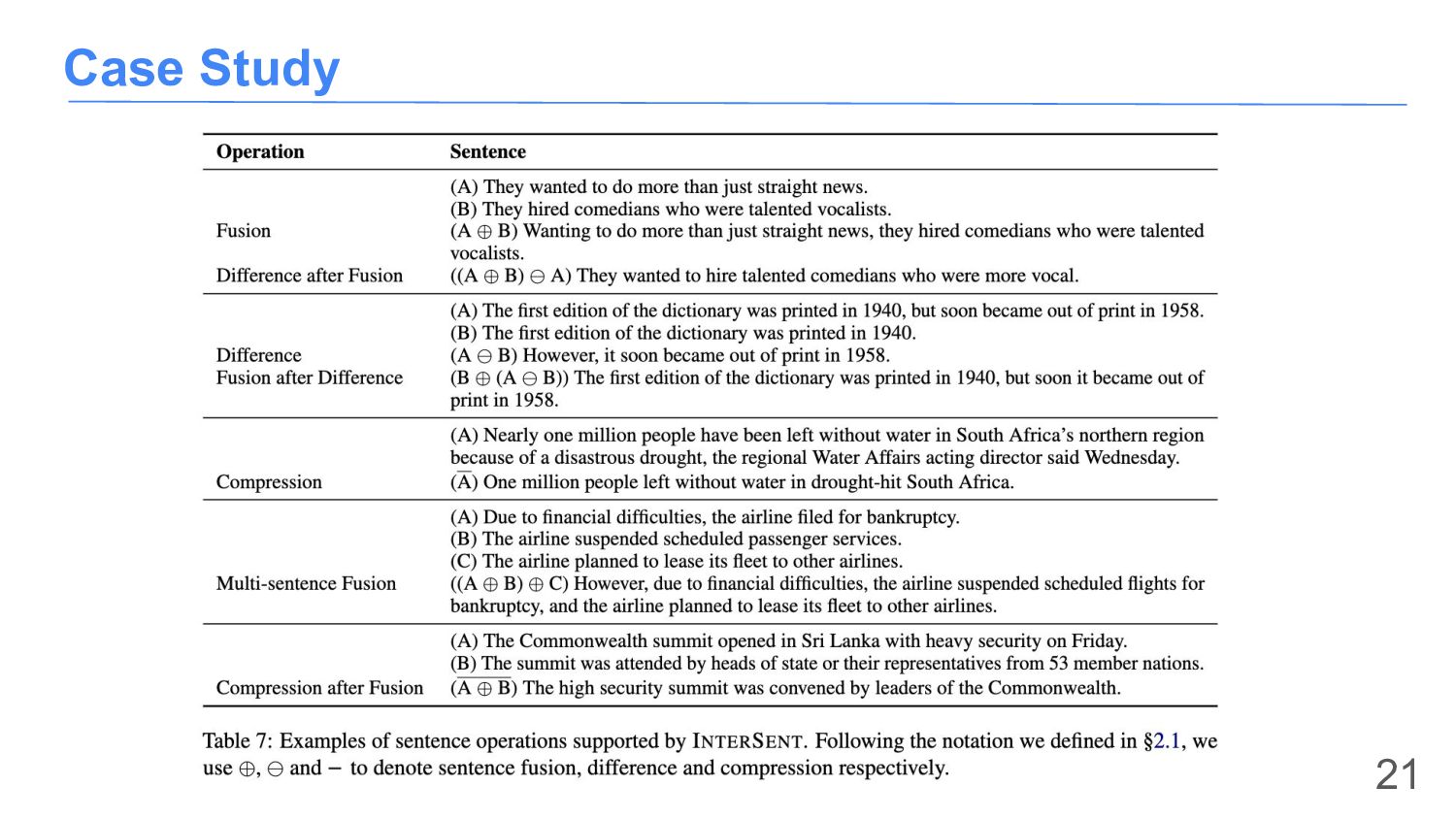{kind=link}
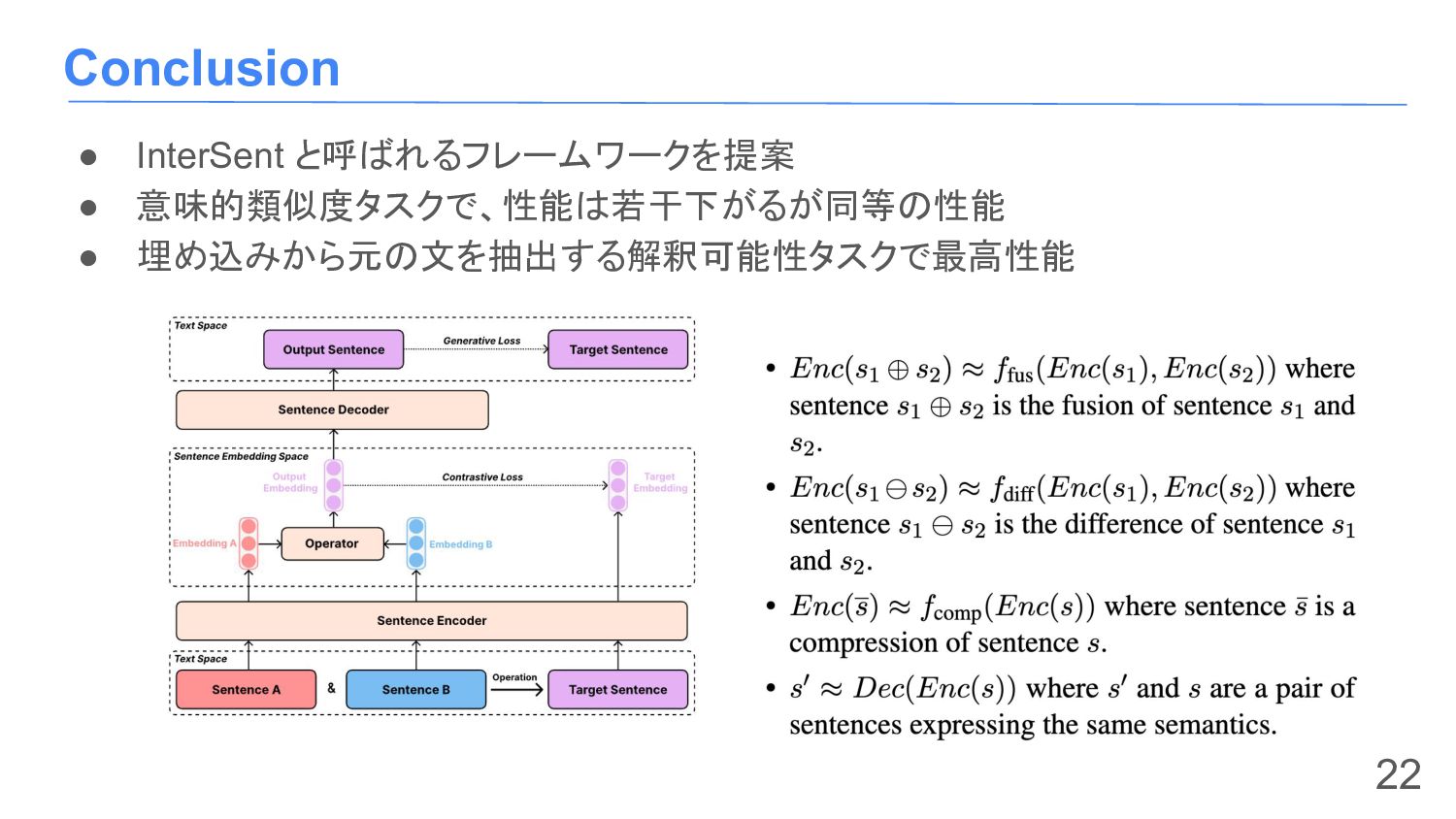{kind=link}
{kind=link}
{kind=link}